【联邦学习】联邦学习算法分类总结
联邦学习作为目前研究的热点,各种算法层出不穷,不管是纵向横向,还是什么FedAvg、FedProx,总之就是分类很乱,今天来系统总结一下联邦学习的分类方式以及对应的内容介绍。
我们都听过联邦学习分类方法中有:纵向横向和迁移,这是杨强大佬的分类方法,是根据样本重合程度来划分的。
机器学习中,特征、标签和样本是最基本的概念,下图展示了特征样本标签之间的关系
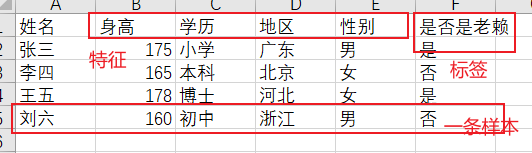
横向联邦学习,就是指两个样本集合中样本的特征重合较高,但是样本来源不一样。就比如图中,两个样本集合分别是两家银行的客户。一般银行管理的数据特征都是相似的,但是客户是不同的,这样我们就可以采用横向联邦学习的方式训练模型。
纵向联邦学习是指两个数据集id重合较高(比如上图的姓名,都是一样的人),但是特征不一样,比如一座城市只有一家银行和一家医院,那么银行和医院的样本大概率人员重合度很高,但是特征不一样,银行数据集属性可能是存款、贷款等信息,医院可能是生理指标等。此时如果使用银行和医院的数据集训练模型,我们称之为纵向联邦学习。
如果id和特征重合程度都很少怎么办?此时只能采用联邦迁移学习的办法。联邦迁移学习重点在“迁移学习”。迁移学习,是指利用数据、任务、或模型之间的相似性,将在源领域学习过的模型,应用于目标领域的一种学习过程。这里对迁移学习不做展开。
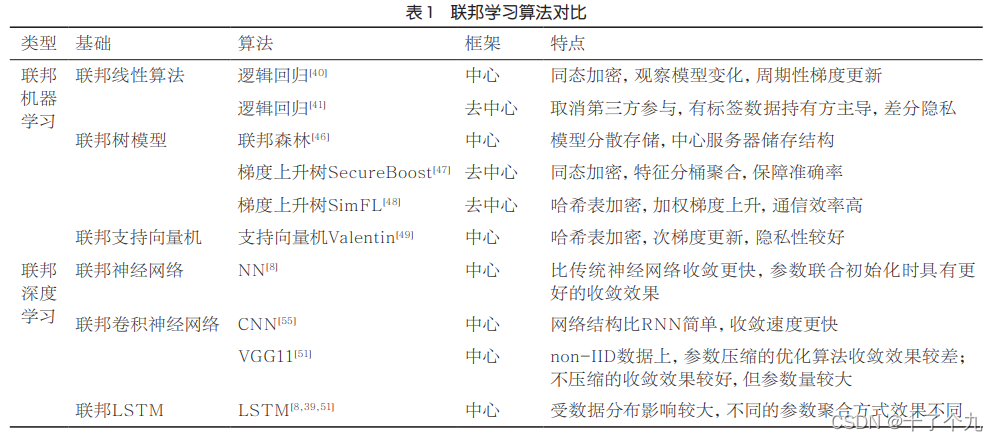
常见的机器学习算法诸如回归、随机森林、支持向量机等,这些算法都可以用在联邦学习中。目前在联邦学习中已经研究的传统机器学习算法有以下几种
Yang K等人提出了一种中心联邦学习框架下的纵向联邦逻辑回归实现方法,这种方法实现了纵向联邦学习中的逻辑回归,其目标函数是:

论文传送门:https://arxiv.org/abs/1812.11750
Liu Y等人提出了一种基于中心纵向联邦学习框架的随机森林实现方法——联邦森林。在建模过程中,每棵树都实行联合建模。
论文传送门:https://arxiv.org/abs/1905.10053
Hartmann V等人提出了一种将支持向量机(support vector machine,SVM安全部署在联邦学习中的方法,主要通过特征哈希、更新分块等方式对数据隐私性进行保障。其目标函数如下:
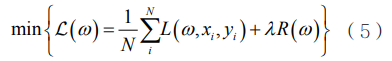
论文传送门:https://arxiv.org/abs/1907.03373v1
深度学习诸如CNN、LSTM等也可以用联邦学习的方式来实现
我们都知道,联邦学习的主要问题集中在一下三个方面
● 联邦学习的通信是比较慢速且不稳定的;
● 联邦学习的参与方设备异构,不同设备有不同的运算能力;
● 联邦学习更关注隐私和安全,目前大部分的研究假设参与方和服务器方是可信的,然而在现实生活中,其可能是不可信的。
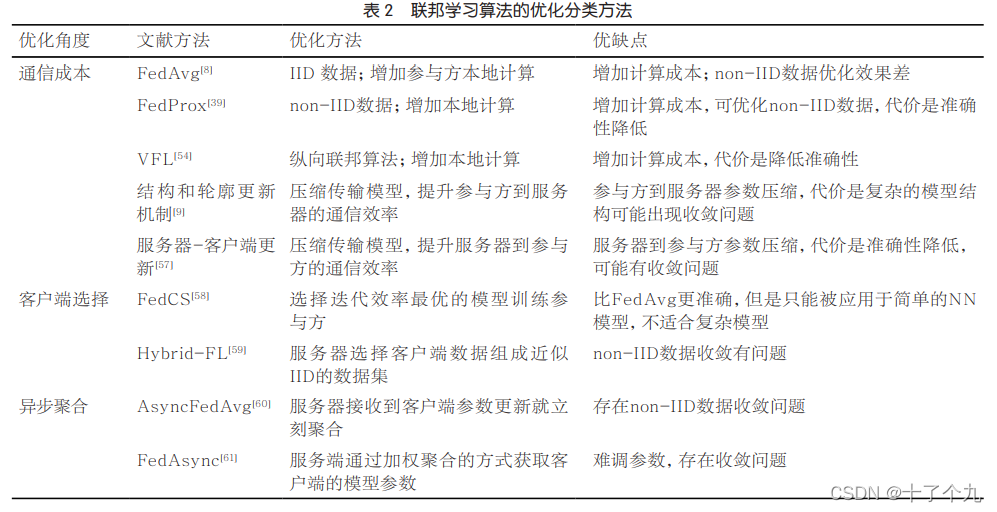
通俗的讲就三点:通信、数据和设备异质以及加密保护。
那么,我们可以根据这三点来提出不同的联邦学习算法,以解决对应的问题,比如某种算法侧重于解决通信瓶颈问题,而另一种方法则侧重于解决加密问题。
最经典的联邦学习算法当属FedAvg(https://arxiv.org/pdf/1602.05629.pdf),该算法在Non-iid数据上的收敛性也得到了数学上的证明(https://arxiv.org/abs/1907.02189v3)。
模型通常很大,如果频繁的通信势必会对通信造成压力,因此我们必须想办法减小通信压力,常用的方法有增加客户端训练轮数、模型压缩等。
在联邦学习体系中,有时终端节点只会在有Wi-Fi时参与联邦学习训练,或者有时网络状况不佳,在这些情况下,更多的计算可以在本地进行,从而减少通信的次数。很多算法是从这个角度来优化通信成本的。比如Konečný J考虑了优化FedAvg算法,增加每一轮迭代在每个客户端的本地更新参数的计算次数。
论文传送门:https://arxiv.org/abs/1707.01155
Sahu A K等人提出了一种更通用的FedProx算法,这种算法在数据为non-IID时优化效果更明显。FedProx算法可以动态地更新不同客户端每一轮需要本地计算的次数,使得算法更适合非独立同分布的联合建模场景。
论文传送门:https://openreview.net/pdf?id=SkgwE5Ss3N
有的优化算法目的是减少每一轮通信的参数量,例如通过模型压缩的技术(比如量化、二次抽样的方式)来减少每一次参数更新要传递的参数总量。Konečný J等人提出了一种结构化的模型更新方式来更新服务器参数,在每一轮的参数通信过程中,减小参与方传递给服务器的模型更新参数的大小,从而减少通信。
论文传送门:https://arxiv.org/abs/1610.05492v2
Caldas S等人考虑的是从服务器到参 与 方的模型参 数传 递优化,通 过有损压缩以及联邦参数筛选(federated dropout)的方式来减少从服务器到客户端需要传递的参数数量,降低通信成本的代价是在一定程度上降低模型的准确率。
论文传送门:https://arxiv.org/abs/1812.07210
不同的客户端的网络速度、运算能力等不同,每个客户端拥有的数据分布也是不平衡的,如果让所有的客户端都参与联邦学习的训练过程,将会有迭代落后的参与方出现,某些客户端长时间没有响应可能会导致整个系统无法完成联合训练。因此,需要考虑如何选择参与训练的客户端。
最经典的FedAvg算法中客户端的选择是随机的。随机选择嘛emmmm很显然不是很合理,毕竟设备跟设备之间差异太大。
Nishio T等人提出了一种FedCS算法,设计了一种贪心算法的协议机制,以达到在联合训练的每一次更新中都选择模型迭代效率最高的客户端进行聚合更新的目的,从而优化整个联邦学习算法的收敛效率。
论文传送门:https://arxiv.org/abs/1804.08333
Yoshida N等人[59]提出了一种HybridFL的协议算法,该协议可以处理数据集为non-IID的客户端数据,解决基于non-IID数据在FedAvg算法上性能不好的问题。Hybrid-FL协议使得服务器通过资源请求
的步骤来选择部分客户端,从而在本地建立一种近似独立同分布的数据集用于联邦学习的训练和迭
代。
论文传送门:https://arxiv.org/abs/1905.07210
我们都知道,在FedAvg的算法中,聚合是与模型的更新保持同步的。每一次更新,服务器都同步聚合模型参数,然后将聚合参数发送给每一个客户端。在同步聚合中,服务器需要在接收到所有参与训练的客户端的参数之后才可以开始聚合,但是有的客户端运算传输快,有的客户端运算传输慢,为了避免出现通信迟滞现象,有研究者考虑用异步的方式进行聚合,从而优化联邦学习算法。
论文传送门:Asynchronous Federated Optimization
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
SPI接收数据左移一位问题目录SPI接收数据左移一位问题一、问题描述二、问题分析三、探究原理四、经验总结最近在工作在学习调试SPI的过程中遇到一个问题——接收数据整体向左移了一位(1bit)。SPI数据收发是数据交换,因此接收数据时从第二个字节开始才是有效数据,也就是数据整体向右移一个字节(1byte)。请教前辈之后也没有得到解决,通过在网上查阅前人经验终于解决问题,所以写一个避坑经验总结。实际背景:MCU与一款芯片使用spi通信,MCU作为主机,芯片作为从机。这款芯片采用的是它规定的六线SPI,多了两根线:RDY和INT,这样从机就可以主动请求主机给主机发送数据了。一、问题描述根据从机芯片手
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
我完全不是程序员,正在学习使用Ruby和Rails框架进行编程。我目前正在使用Ruby1.8.7和Rails3.0.3,但我想知道我是否应该升级到Ruby1.9,因为我真的没有任何升级的“遗留”成本。缺点是什么?我是否会遇到与普通gem的兼容性问题,或者甚至其他我不太了解甚至无法预料的问题? 最佳答案 你应该升级。不要坚持从1.8.7开始。如果您发现不支持1.9.2的gem,请避免使用它们(因为它们很可能不被维护)。如果您对gem是否兼容1.9.2有任何疑问,您可以在以下位置查看:http://www.railsplugins.or
如何学习ruby的正则表达式?(对于假人) 最佳答案 http://www.rubular.com/在Ruby中使用正则表达式时是一个很棒的工具,因为它可以立即将结果可视化。 关于ruby-我如何学习ruby的正则表达式?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/1881231/
深度学习12.CNN经典网络VGG16一、简介1.VGG来源2.VGG分类3.不同模型的参数数量4.3x3卷积核的好处5.关于学习率调度6.批归一化二、VGG16层分析1.层划分2.参数展开过程图解3.参数传递示例4.VGG16各层参数数量三、代码分析1.VGG16模型定义2.训练3.测试一、简介1.VGG来源VGG(VisualGeometryGroup)是一个视觉几何组在2014年提出的深度卷积神经网络架构。VGG在2014年ImageNet图像分类竞赛亚军,定位竞赛冠军;VGG网络采用连续的小卷积核(3x3)和池化层构建深度神经网络,网络深度可以达到16层或19层,其中VGG16和VGG
文章目录1、自相关函数ACF2、偏自相关函数PACF3、ARIMA(p,d,q)的阶数判断4、代码实现1、引入所需依赖2、数据读取与处理3、一阶差分与绘图4、ACF5、PACF1、自相关函数ACF自相关函数反映了同一序列在不同时序的取值之间的相关性。公式:ACF(k)=ρk=Cov(yt,yt−k)Var(yt)ACF(k)=\rho_{k}=\frac{Cov(y_{t},y_{t-k})}{Var(y_{t})}ACF(k)=ρk=Var(yt)Cov(yt,yt−k)其中分子用于求协方差矩阵,分母用于计算样本方差。求出的ACF值为[-1,1]。但对于一个平稳的AR模型,求出其滞
1.问题描述使用Python的turtle(海龟绘图)模块提供的函数绘制直线。2.问题分析一幅复杂的图形通常都可以由点、直线、三角形、矩形、平行四边形、圆、椭圆和圆弧等基本图形组成。其中的三角形、矩形、平行四边形又可以由直线组成,而直线又是由两个点确定的。我们使用Python的turtle模块所提供的函数来绘制直线。在使用之前我们先介绍一下turtle模块的相关知识点。turtle模块提供面向对象和面向过程两种形式的海龟绘图基本组件。面向对象的接口类如下:1)TurtleScreen类:定义图形窗口作为绘图海龟的运动场。它的构造器需要一个tkinter.Canvas或ScrolledCanva