
目录



代码如下:
#include<iostream>
#include<algorithm>
using namespace std;
const int N=1010;
int v[N],w[N]; //v[N]是物品体积 w[N]是物品的价值
int f[N][N]; //f[i][j]在体积不超j的前提下,从i个物品中选择最大值
int main()
{
int n,m;
cin>>n>>m;
for(int i=1;i<=n;i++)
{
cin>>v[i]>>w[i];
}
for(int i=1;i<=n;i++)
{
for(int j=1;j<=m;j++)
{
f[i][j]=f[i-1][j];
if(j>=v[i])//如果我们的背包容量j大于第i个物品的体积,我们在进行决策是否加入第i个物品
f[i][j]=max(f[i][j],f[i-1][j-v[i]]+w[i]);
}
}
cout<<f[n][m]<<endl;
return 0;
}
为什么可以使用一维数组?
我们先来看一看01背包问题的状态转移方程,我们可以发现 f[i]只用到了f[i-1],其他的是没有用到的,我们可以用滚动数组来做。
还有一个原因就是我们在计算f[i] [j]的时候我们只用到了f[i-1] [j]和f[i-1] [j-v[i]],其中j和j-v[i]都是小于等于j的,在j的同一侧,所以我们综合以上两点原因就可以将二维优化到一维,即完成空间优化。

我们先来将二维和优化后的一维在关键算法代码上进行一下对比:
for(int i = 1; i <= n; i++)
for(int j = m; j >= 0; j--)
{
if(j < v[i])
f[i][j] = f[i - 1][j]; // 优化前
f[j] = f[j]; // 优化后,该行自动成立,可省略。
else
f[i][j] = max(f[i - 1][j], f[i - 1][j - v[i]] + w[i]); // 优化前
f[j] = max(f[j], f[j - v[i]] + w[i]); // 优化后
}
实际上,只有当枚举的背包容量 >= v[i] 时才会更新状态,因此我们可以修改循环终止条件进一步优化。
for(int i=1;j<=n;i++)
{
for(int j=m;j>=v[i];j--)
{
f[j]=max(f[j],f[j-v[i]]+w[i]);
}
}

#include <iostream>
#include <algorithm>
using namespace std;
const int N = 1010;
int n, m;
int v[N], w[N];
int f[N];
int main()
{
cin >> n >> m;
for (int i = 1; i <= n; i ++ ) cin >> v[i] >> w[i];
for (int i = 1; i <= n; i ++ )
for (int j = m; j >= v[i]; j -- )
f[j] = max(f[j], f[j - v[i]] + w[i]);
cout << f[m] << endl;
return 0;
}
我们注意到在处理数据时,我们是一个物品一个物品,一个一个体积的枚举。因此我们可以不必开两个数组记录体积和价值,而是边输入边处理。
#include<bits/stdc++.h>
using namespace std;
const int MAXN = 1005;
int f[MAXN]; //
int main()
{
int n, m;
cin >> n >> m;
for(int i = 1; i <= n; i++) {
int v, w;
cin >> v >> w; // 边输入边处理
for(int j = m; j >= v; j--)
f[j] = max(f[j], f[j - v] + w);
}
cout << f[m] << endl;
return 0;
}


#include<iostream>
using namespace std;
const int N=1010;
int f[N][N];
int n,m;
int v[N],w[N];
int main()
{
cin>>n>>m;
for(int i=1;i<=n;i++) cin>>v[i]>>w[i];
for(int i=1;i<=n;i++)
{
for(int j=0;j<=m;j++)
{
for(int k=0;k*v[i]<=j;k++)
{
f[i][j]=max(f[i][j],f[i-1][j-k*v[i]]+k*w[i]);
}
}
}
cout<<f[n][m]<<endl;
return 0;
}
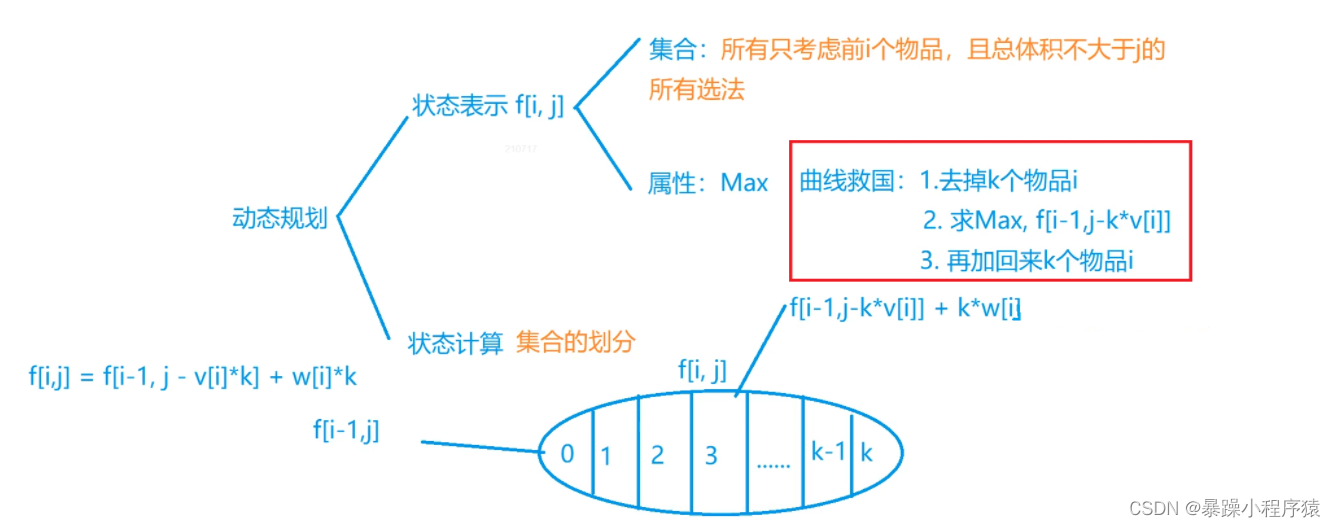
上述朴素算法和01背包问题的朴素算法非常相似,但是会超时。所以我们接下来就会对这个算法进行优化处理。

我们先来分析一下状态转移方程,我们发现方程一和方程二有一定的联系,我们先不看方程一红色圈出来的部分,我们比较方程一黄色的部分和方程二的内容,我们发现方程一就是比方程二每一项多了一个w,那么我们黄色圈出来的部分的最大值也就比方程二的最大值多w,那么我们其实就可以将方程一圈出来黄色的部分进行等价替换,替换成红色方框黄色字体的内容,我们最终得出最下方的结论,其实我们要求得最大值之和两个状态有关,比较它们的最大值即可。
我们发现好像最后的状态转移方程和k并没有关系了,那么我们就干脆去掉k的那次循环
所以我们对核心代码进行了优化:
for(int i = 1 ; i <=n ;i++)
for(int j = 0 ; j <=m ;j++)
{
f[i][j] = f[i-1][j];//状态一,即不取第i个物品
if(j-v[i]>=0)//判断是否可以加入第i个物品
f[i][j]=max(f[i][j],f[i][j-v[i]]+w[i]);//状态二
}
完整代码如下:
#include<iostream>
using namespace std;
const int N=1010;
int f[N][N];
int n,m;
int v[N],w[N];
int main()
{
cin>>n>>m;
for(int i=1;i<=n;i++) cin>>v[i]>>w[i];
for(int i=1;i<=n;i++)
{
for(int j=0;j<=m;j++)
{
f[i][j]=f[i-1][j];
if(j>=v[i])
{
f[i][j]=max(f[i][j],f[i][j-v[i]]+w[i]);
}
}
}
cout<<f[n][m]<<endl;
return 0;
}
我们来比较一个完全背包的核心代码和01背包核心代码的区别:
//01背包问题核心优化后代码
for(int i=1;i<=n;i++)
{
for(int j=m;j>=v[i];j--)
{ f[i][j]=f[i-1][j];
if(j>=v[i])
{
f[i][j]=max(f[i][j],f[i-1][j-v[i]]+w[i]);
}
}
}
//完全背包问题核心优化后代码
for(int i = 1 ; i <=n ;i++)
for(int j = 0 ; j <=m ;j++)
{
f[i][j] = f[i-1][j];//状态一,即不取第i个物品
if(j-v[i]>=0)//判断是否可以加入第i个物品
f[i][j]=max(f[i][j],f[i][j-v[i]]+w[i]);//状态二
}
我们发现其实本质也就是一句不同:注意i的下标

我们这个i的下标是根据两个不同的背包问题的状态转移方程得出来的,我们01背包问题因为要使用第i-1层的数据,所以我们枚举j的时候只能从后往前枚举,这样做是因为j-v[i]小于j,那么f[j-v[i]]的数据就会被改,那么我们使用的数据其实就是第i层的数据了,不满足状态转移方程,所以我们要从后往前枚举,但是完全背包问题使用的就是第i层的数据,所以不存在从前往后枚举就会在使用前数据就发生意外改变的这种情况,所以就在这个地方这两个核心算法略有差别。
这个和01背包问题的优化方法是一样的,就不多赘述了。
核心代码如下:
for(int i = 1 ; i<=n ;i++)
for(int j = v[i] ; j<=m ;j++)//注意了,这里的j是从小到大枚举,和01背包不一样
{
f[j] = max(f[j],f[j-v[i]]+w[i]);
}
完整代码如下:
#include<iostream>
using namespace std;
const int N = 1010;
int f[N];
int v[N],w[N];
int main()
{
int n,m;
cin>>n>>m;
for(int i = 1 ; i <= n ;i ++)
{
cin>>v[i]>>w[i];
}
for(int i = 1 ; i<=n ;i++)
for(int j = v[i] ; j<=m ;j++)
{
f[j] = max(f[j],f[j-v[i]]+w[i]);
}
cout<<f[m]<<endl;
}
本篇博客主要涉及动态规划背包问题的01背包问题和完全背包问题,给大家分享了实现的思路和代码模板,大家也可以看看yxc的背包九讲,图片转载于yxc,希望对大家有所帮助,后面会持续更新~
我打算为ruby脚本创建一个安装程序,但我希望能够确保机器安装了RVM。有没有一种方法可以完全离线安装RVM并且不引人注目(通过不引人注目,就像创建一个可以做所有事情的脚本而不是要求用户向他们的bash_profile或bashrc添加一些东西)我不是要脚本本身,只是一个关于如何走这条路的快速指针(如果可能的话)。我们还研究了这个很有帮助的问题:RVM-isthereawayforsimpleofflineinstall?但有点误导,因为答案只向我们展示了如何离线在RVM中安装ruby。我们需要能够离线安装RVM本身,并查看脚本https://raw.github.com/wayn
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
有没有办法在Ruby中动态创建数组?例如,假设我想遍历用户输入的书籍数组:books=gets.chomp用户输入:"TheGreatGatsby,CrimeandPunishment,Dracula,Fahrenheit451,PrideandPrejudice,SenseandSensibility,Slaughterhouse-Five,TheAdventuresofHuckleberryFinn"我把它变成一个数组:books_array=books.split(",")现在,对于用户输入的每一本书,我想用Ruby创建一个数组。伪代码来做到这一点:x=0books_array.
我想在IRB中浏览文件系统并让提示更改以反射(reflect)当前工作目录,但我不知道如何在每个命令后进行提示更新。最终,我想在日常工作中更多地使用IRB,让bash溜走。我在我的.irbrc中试过这个:require'fileutils'includeFileUtilsIRB.conf[:PROMPT][:CUSTOM]={:PROMPT_N=>"\e[1m:\e[m",:PROMPT_I=>"\e[1m#{pwd}>\e[m",:PROMPT_S=>"FOO",:PROMPT_C=>"\e[1m#{pwd}>\e[m",:RETURN=>""}IRB.conf[:PROMPT_MO
背景here.在上面的链接中,给出了以下示例:classauthor.id)endend除了这种语法对于像我这样的初学者来说很陌生——我一直认为类方法是用defself.my_class_method定义的——我在哪里可以找到关于类的文档RubyonRails中的方法?据我所知,类方法总是在类本身(MyClass.my_class_method)上调用,但如果Rails中的类方法是可链接的,似乎必须进行其他操作在这里!编辑:我想我通过对类方法的语法发表评论有点被骗了。我真的想问Rails如何使类方法可链接—我了解方法链接的工作原理,但不知道Rails如何允许您链接类方法而无需实际返
首先,我使用的是rails3.1.3和来自master的carrierwavegithub仓库的分支。我使用after_init钩子(Hook)来确定基于属性的字段页面模型实例并为这些字段定义属性访问器将值存储在序列化哈希中(希望它清楚我是什么谈论)。这是我正在做的事情的精简版:classPage省略mount_uploader命令让我可以访问我想要的属性。但是当我安装uploader时出现错误消息说“nil类的未定义新方法”我在源代码中读到有方法read_uploader和扩展模块中的write_uploader。我如何必须覆盖这些来制作mount_uploader命令使用我的“虚拟
我正在尝试动态构建一个多维数组。我想要的基本上是这样的(为简单起见写出来):b=0test=[[]]test[b]这给了我错误:NoMethodError:undefinedmethod`test=[[],[],[]]而且它工作正常,但在我的实际使用中,我不会事先知道需要多少个数组。有一个更好的方法吗?谢谢 最佳答案 不需要像您正在使用的索引变量。只需将每个数组附加到您的test数组:irb>test=[]=>[]irb>test[["a","b","c"]]irb>test[["a","b","c"],["d","e","f"]]
如何只加载map边界内的标记gmaps4rails?当然,在平移和/或缩放后加载新的。与此直接相关的是,如何获取map的当前边界和缩放级别? 最佳答案 我是这样做的,我只在用户完成平移或缩放后替换标记,如果您需要不同的行为,请使用不同的事件监听器:在你看来(index.html.erb):{"zoom"=>15,"auto_adjust"=>false,"detect_location"=>true,"center_on_user"=>true}},false,true)%>在View的底部添加:functiongmaps4rail
首先,关于我们系统的一些信息,它基本上是建筑行业的电子招标解决方案。所以:列表项我们的系统有多家公司每个公司都有多个用户每家公司可以创建多个拍卖然后其他公司可以为可用的拍卖提交他们的出价。一个出价包含数百或数千个单独的项目,我们只需要加密这些记录的“价格”部分。我们面临的问题是,我们的大客户不希望我们知道投标价格,至少在投标过程中是这样,这是完全可以理解的。现在,我们只是通过对称加密对价格进行加密,因此即使价格在数据库中有效加密,他们担心的是我们拥有解密价格的key。因此,我们正在研究某种形式的公钥加密系统。以下是我们对解决方案的初步想法:当一家公司注册时,我们会使用OpenSSL为其
如何在对象上调用方法名称的嵌套哈希?例如,给定以下哈希:hash={:a=>{:b=>{:c=>:d}}}我想创建一个方法,给定上面的散列,执行以下操作:object.send(:a).send(:b).send(:c).send(:d)我的想法是我需要从一个未知的关联中获取一个特定的属性(这个方法不知道,但程序员知道)。我希望能够指定一个方法链来以嵌套哈希的形式检索该属性。例如:hash={:manufacturer=>{:addresses=>{:first=>:postal_code}}}car.execute_method_hash(hash)=>90210