直方图是用面积而不是用高度来表示数,所以其不同于条形图
左边的刻度表示该块每单位所占总面积的百分比,可以称其为密度尺度。
例如以每50元为一个单位,200-400 就有四个单位。
每一块所拥有的单位数 \(\times\) 左边每单位所占百分数 = 该块所占总百分比
直方图的总面积 = 总单位数 \(\times\) 每单位对应密度尺度 = 1
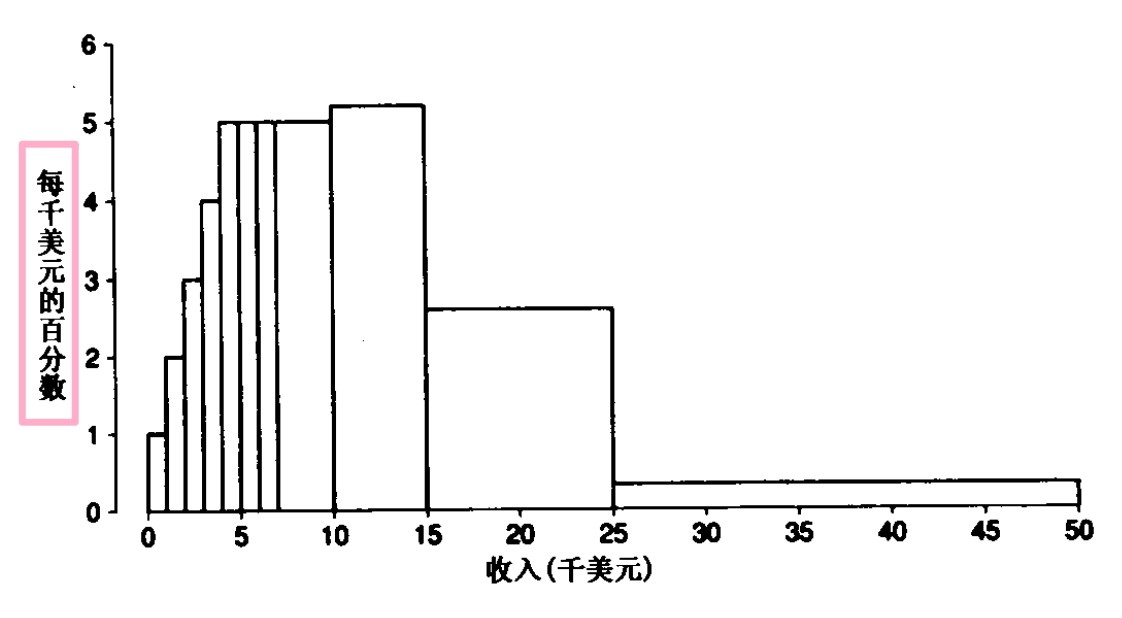
直方图的绘制是根据百分表来绘制的,即统计的变量的每个子区间内的实例占总实例的百分比数。
在绘制时需要注意边界处理(终点约定):即位于子区间边界的值该划分到哪个子区间中。
直方图的高度表示什么呢?高度表示拥挤程度(单位区间的密度),也就是堆积在该区间的实例数
直方图以面积表示百分数
采用密度尺度,每一个块形的高度等于相应小组区间中事例的百分数除以该区间的长度
采用密度尺度,面积呈现为百分数,总面积是 100%
变量是研究中对象的特征,它可以是定性的,也可以是定量的。而如果是定量的,则要么是离散的,要么是连续的
混杂因素有时候用交叉列表(可以看成透视表)加以控制
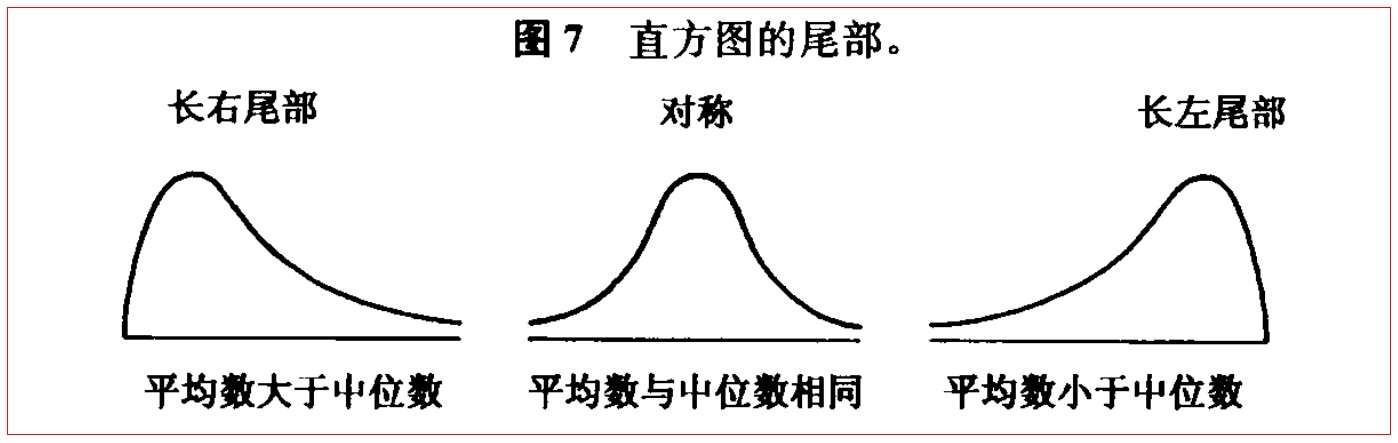
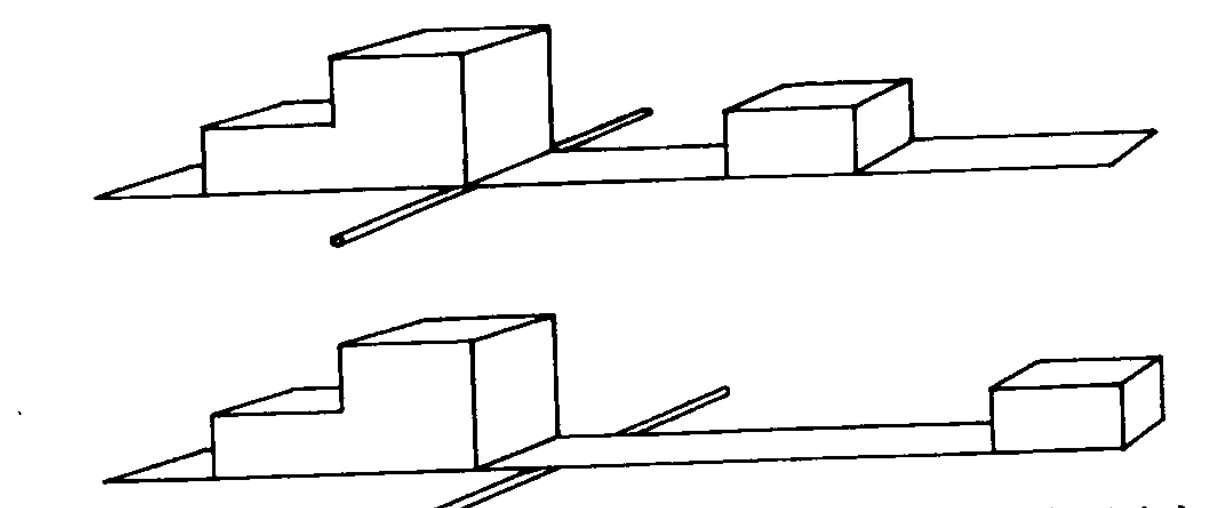
平均数受到离中心越远的数据的影响越大,可以看成同样 50% 的体积的数据,越远的数据给其占比进行了更大的加权,如下图所示
标准差的意义:SD指出了数列中的数离他们的平均数有多远。数列中大多数项离开平均数大约 1 个 SD 左右。极少数项将离开 2 个或 3 个 SD 以上。
更加具体和数量化的表述:
粗略的,数列中 68% (三分之二)的项在离平均数 1 SD 范围内,其余的 32% 离得较远。
粗略的,95%(20分之19)的项在距平均数 2 个 SD 范围内,其余 5% 则远离之。
我想这可能就是显著值 p = 0.05 的原因之一
对许多数列如此,但不是所有数列都这样
应该是对正态分布或近似正态分布如此
我们要分清楚不同组的数据是
从同一时刻的不同对象横向截面获得
一直跟踪同一个对象至多个时刻获得
这两种数据能得到的结论是完全不同的
在横向截面统计得到的数据中,我们是无法得到一个指标随着时间而变化的结论,因为其统计的只是对象在某一刻的数据,不具有时间上的变化性。
随时间而变化的变化规律只能是针对同一个对象在时间上的迁移所产生的变化进行统计。
例如:想追踪是否随着年龄老化,许多人从左撇子改为右撇子?
可以对这 1000 个人或者更多人进行追踪调查,然后将这些人在不同年龄段的左右手撇子的分布进行统计,这样才能得到变化规律。
正态图像的特征:
关于 0 点对称
曲线下面的总面积等于 100%(面积按百分数给出,因为纵轴使用了密度尺度)
即纵轴使用的是每标准单位的百分数
标准单位:标准单位个数是指一个数值在平均数之上或之下多少个 SD
一个标准单位就是一个 SD
所有正态分布都可以通过Z-Score公式转换成标准正态分布。
正态曲线与直方图:
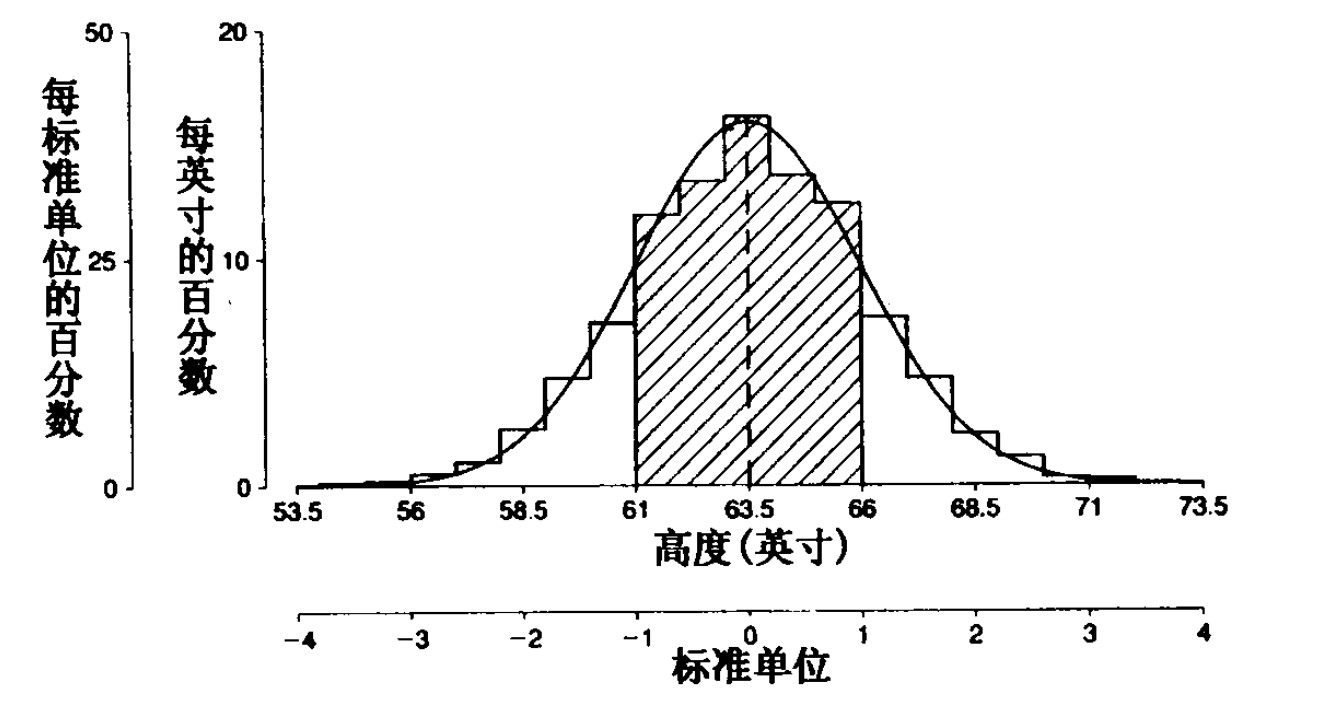
直方图是按照每英寸的百分数绘制
正态曲线是按每标准单位的百分数绘制
可以看到,每标准单位 50% 与每英寸 20% 相配,因为对于每个标准单位(即SD)有 2.5 英寸
该处的标准单位对应特定的一组统计数据计算而出
我们查的表(即对应正态分布的表)都是以 SD 为标准单位的取值。
如果要换成原数据单位的话,需要进行换算,例如 SD = 100 cm,那么 1.65 换算成原单位就要变为 1.65 \(\times\) 100 = 165cm
平均数和 SD 可以用来概括遵循正态曲线的数据,但对于其他类型的数据,它们是不令人满意滴
存在一套数学理论来解释什么时候直方图会遵循正态曲线
对于非正态分布而言,用中心和SD去度量是不准确的,因为其具有偏度,数据在均值两端的分布是不均衡的。
此时使用百分位数来衡量,即不同阶段的人占百分之多少
常用的百分位数有:
25%、50%、75%
其中 75% - 25% 也被称为四分位数间距
对于非正态分布而言,四分位数间距有时候用作散布的度量
即位于中间 50% 的对象数值分布的范围有多大
正态曲线同样可以使用百分位数来描述
百分位数是通用的;
均值和 SD 相对来说更加限于描述正态曲线。
当然,并不是说只有符合正态分布的数据才有均值和 SD,而是说均值和 SD 在描述正态曲线上具有更好的意义。
同时,正态表可以用来估计百分位数
正态表就是以 0 为中心,SD 为标准单位进行计算并得到的数据表。
(1 个 SD(标准差) 算一个标准单位)
在对实际数据使用时,需要将中心换为实际数据的均值,SD 的标准单位换算为原数据的单位
如果一列数遵循正态曲线,落在一个给定的区间内的项的百分数可以通过将区间换算成标准单位,然后求正态曲线下相应的面积而估计。这个过程叫正态近似;
一个遵循正态曲线的直方图可以根据他的平均数和 SD 相当好的重新构建,这种情况下,平均数和 SD 是好的概括统计量;
所有正态分布都可以通过Z-Score公式转换成标准正态分布。
所有直方图,不管它们是否遵循正态曲线,可以使用百分位数来概括。
一系列重复测量的 SD 是单词测量中机会误差可能大小的估计
单独测量值 = 精确值 + 机会误差
极端的测量值被称为离群点 。
有时一些数据本来应该符合正态分布,但由于其离群点的原因,影响了 SD 的值,使得其在 1 SD 范围内的数据量不符合 68% 左右。
此时可能需要进行离群点处理
这里有一段值得深思的话,由美国标准局给出:
在统计方法对于测量数据分析的应用中,一个主要困难是获得合适的数据。问题是比较经常地有意识或者也许无疑是地试图按照人们锁了一地那样构造一个特殊的实施过程,而不是接受真正的事实。给予任意的对实施过程的限制而拒绝数据会严重去接对实际变化的估计。这种做法使得原先计划的目的失效。实际性能参数需要接受全部数据,它们不能由于某种原因而被摒弃。
就例如我们总希望数据符合正态分布,如果不符合总希望通过一些处理手段对数据进行删除或者其他的处理将其转换。在这个过程中,有可能我们就篡改了数据背后的信息,一定程度上是不严谨的。
但是我们通常还是选择对离群点进行抛弃处理,这是理论战胜了经验。
与机会误差对数据的影响是忽高忽低不同,偏性对数据的影响是将他们推向同一方向的。
如果在测量的过程中没有偏性,大量重复测量值的平均数将给出待测物体的精确值,所有机会误差将抵消
单独测量值 = 精确值 + 偏度 + 机会误差
偏性就是 bias
机会误差就是 variance
我知道当我们fork一个进程时,子进程会继承父进程的打开文件描述符和偏移量的副本。根据手册页,这指的是父级使用的相同文件描述符。基于以下程序中的理论puts"Process#{Process.pid}"file=File.open('sample','w')forked_pid=forkdosleep(10)puts"Writingtofilenow..."file.puts("HelloWorld.#{Time.now}")endfile.puts("Welcometowinterofmydiscontent#{Time.now}")file.closefile=nil问题一:当父进
我编写了一个Sinatra应用程序(网站),我想收集网站代码的代码覆盖率信息。我是Ruby的新手,但Google告诉我rcov是一个很好的代码覆盖工具。不幸的是,我在网上可以找到的所有信息只显示了如何获取有关测试用例的代码覆盖率信息-我想要有关我的站点本身的代码覆盖率信息。我想要分析的特定站点文件位于“sdk”和“sdk/vendor”目录中,因此我通常使用“rubysite.rb”运行我的站点的地方我改为尝试以下操作:rcov-Isdk-Isdk/vendorsite.rb它显示了Sinatra启动文本,但随后立即退出,而不是像我的Sinatra应用程序通常那样等待网络请求。有人能告
我正在构建一个网络应用程序自动化框架,旨在允许:当然是自动化任务轻松构建测试场景我正在使用Capybara与浏览器通信,我有一个组件库,其中包含许多辅助函数(login_to_the_back_office、create_customer等)。现在我希望我的组件可以独立使用,也可以在RSpec测试中使用。这意味着我的组件(包含在库中)没有环绕describe...it...默认情况下会阻塞,但在测试使用它们时它们会在某个时候出现,因此它们应该使用expect和friend尽可能多。我关注了rspec's.shouldfails(outsidedescribe/itblock)inRub
我有一个Rails应用程序,用户可以在其中设置他们的域并在其中发布内容。我需要收集公共(public)流量统计信息,例如网页浏览量等。此功能的一个很好的例子是我作为客户可以看到的flickr使用统计信息。问题是收集使用信息的最佳方式是什么。应该通过解析日志文件来完成还是应该在运行时收集并存储在数据库中?是否有任何工具或Rails插件已经提供了此功能?此解决方案应该可以很好地扩展,即使每月有数千个域和数百万次网页浏览。 最佳答案 GoogleAnalytics可能是您最好的选择... 关于
在MacOSXLion上使用Rubyv1.8.7和Daemonsv1.1.8,我试图编写一个消费者进程并让它作为守护进程运行:#config[:name]=>'idx_my_delete_consumer'#config[:daemon]=>{:multiple=>false,#:backtrace=>true,#:dir_mode=>:normal,#:log_dir=>'/Users/pprakash/consumer.log',#:monitor=>true,#:dir=>'/Users/pprakash/pids'}Daemons.run_proc(config[:name],
我正在构建一个需要计算数据集统计信息的网络应用程序。我需要计算数组的百分位数、平均值、众数和其他统计函数。通常在Python中,我只会使用scipy、numpy或nltk,它们有一个巨大的stat数组函数库。我可以利用任何rubygem或库来执行此操作吗?在没有任何现有库的情况下,是否有一种简单的方法可以在Python中进行数据处理,同时将我的应用程序保留在Ruby/Rails中? 最佳答案 如果你真的需要一个完整的统计库,看看statsample.否则你可能会发现descriptive_statistics成为一个不错的、轻量
当一个文件有pragma时:#frozen_string_literal:true默认情况下,该文件中所有作为文字写入的字符串都被卡住。当我希望我的字符串总体上是不可变的,因此我使用pragma,但想要有几个可变字符串时,推荐的编写它们的方法是什么?我能想到的是:String.new("foo") 最佳答案 我错过了。推荐的方法是使用+@方法字符串文字。(+"foo").frozen?#=>false(-"foo").frozen?#=>true"foo".frozen?#=>true
这可能是也可能不是灰色地带主题,尽管我的意图肯定不是,所以我的意图不是激起关于逆向工程主题的道德辩论。我是1型糖尿病患者,目前正在接受泵治疗。我是OmniPod用户,这是一个一次性胶囊,可以粘在我的身上并分配胰岛素3天。它由个人糖尿病管理器[PDM](见下文)控制,该管理器控制进餐期间分配的胰岛素量、血糖读数,并且包含一个用于计算碳水化合物的食物指数。(来源:myomnipod.com)新的PDM有一个用于下载数据的USB端口。该软件对Windows用户免费(名为CoPilot的软件包),但不支持Mac。将PDM插入我的Mac后,它像任何其他USB设备一样安装,并为我提供了一个可读卷,
我正在使用paypalrubysdk以便通过restapi处理信用卡。从信用卡处理的角度来看,一切正常。信用卡处理得当,没有任何问题。不幸的是,当我在沙盒(或实时)商户Paypal账户上执行交易的csv导出时,“项目标题”字段未填充,而且我也看不到任何地方都使用了描述字段。向paypal请求:Request[post]:https://api.sandbox.paypal.com/v1/payments/paymentRequest.body={"intent":"sale","payer":{"payment_method":"credit_card","funding_inst
在rake任务中,如何查询描述?会给出的东西:desc"PopulateDB"taskpopulate::environmentdoputstask.desc#"PopulateDB"end 最佳答案 task必须定义为任务block的参数。desc"PopulateDB"task:populatedo|task|putstask.comment#"PopulateDB"putstask.full_comment#"PopulateDB"putstask.name#"populate"end编辑:此解决方案适用于rake0.8.7。