模型压缩方法主要4种:
本文主要来研究知识蒸馏的相关知识,并尝试用知识蒸馏的方法对YOLOv5进行改进。
知识蒸馏(Knowledge Distillation)由深度学习三巨头Hinton在2015年提出。
论文标题:Distilling the knowledge in a neural network
论文地址:https://arxiv.org/pdf/1503.02531.pdf
“蒸馏”是个化工学科中的术语,本身指的是将液体混合物加热沸腾,使其中沸点较低的组分首先变成蒸气,再冷凝成液体,用来分离混合物。而知识蒸馏的含义和蒸馏本身相似但并不完全相同,知识蒸馏指的是同时训练两个网络,一个较复杂的网络作为教师网络,另一个较简单的网络作为学生网络,将教师网络训练得到的结果提炼出来,用来引导学生网络的结果,从而让学生网络学习得更好。
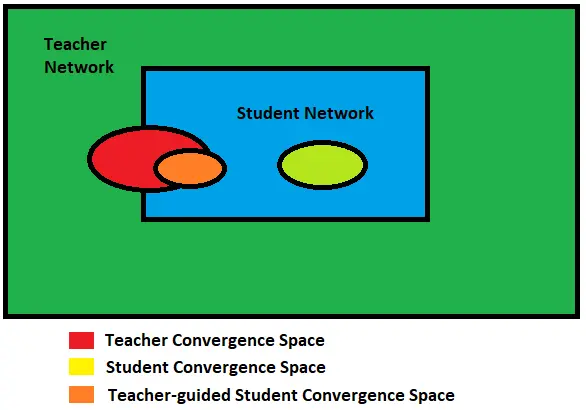
一个公认前提是小模型相比于大模型更容易陷入局部最优,下图[1]中,中间绿色的椭圆表示小网络模型的收敛空间,红色的椭圆表示大网络模型的收敛空间;如果不用知识蒸馏,直接训练小网络,它只会在绿色椭圆区域收敛,而使用知识蒸馏之后,小网络可以收敛到橙色椭圆区域,收敛到更小的最优点。
有了上面的概念,自然而然想到的一个问题就是,教师模型如何引导学生模型进行学习。这就涉及到论文中提及的一个概念——软标签(Soft target)

如上图[1]所示,以手写数字识别为例,这是一个10分类任务,左边这幅图是采用硬标签(Hard target),输出独热向量,概率最高的类别为1,其它类别为0;右边这幅图采用的是软标签(Soft target),通过softmax层输出的各类别概率,这样的输出具有更高的信息熵,即包含更多信息量。
教师模型输出软标签,从而指导学生模型学习。
softmax的原始公式是这样:
q i = exp ( z i ) ∑ j exp ( z j ) q_{i}=\frac{\exp \left(z_{i}\right)}{\sum_{j} \exp \left(z_{j}\right)} qi=∑jexp(zj)exp(zi)
在论文中,作者对这个公式又加以改进,引入了一个新的温度变量T,公式如下:
q i = exp ( z i / T ) ∑ j exp ( z j / T ) q_{i}=\frac{\exp \left(z_{i} / T\right)}{\sum_{j} \exp \left(z_{j} / T\right)} qi=∑jexp(zj/T)exp(zi/T)
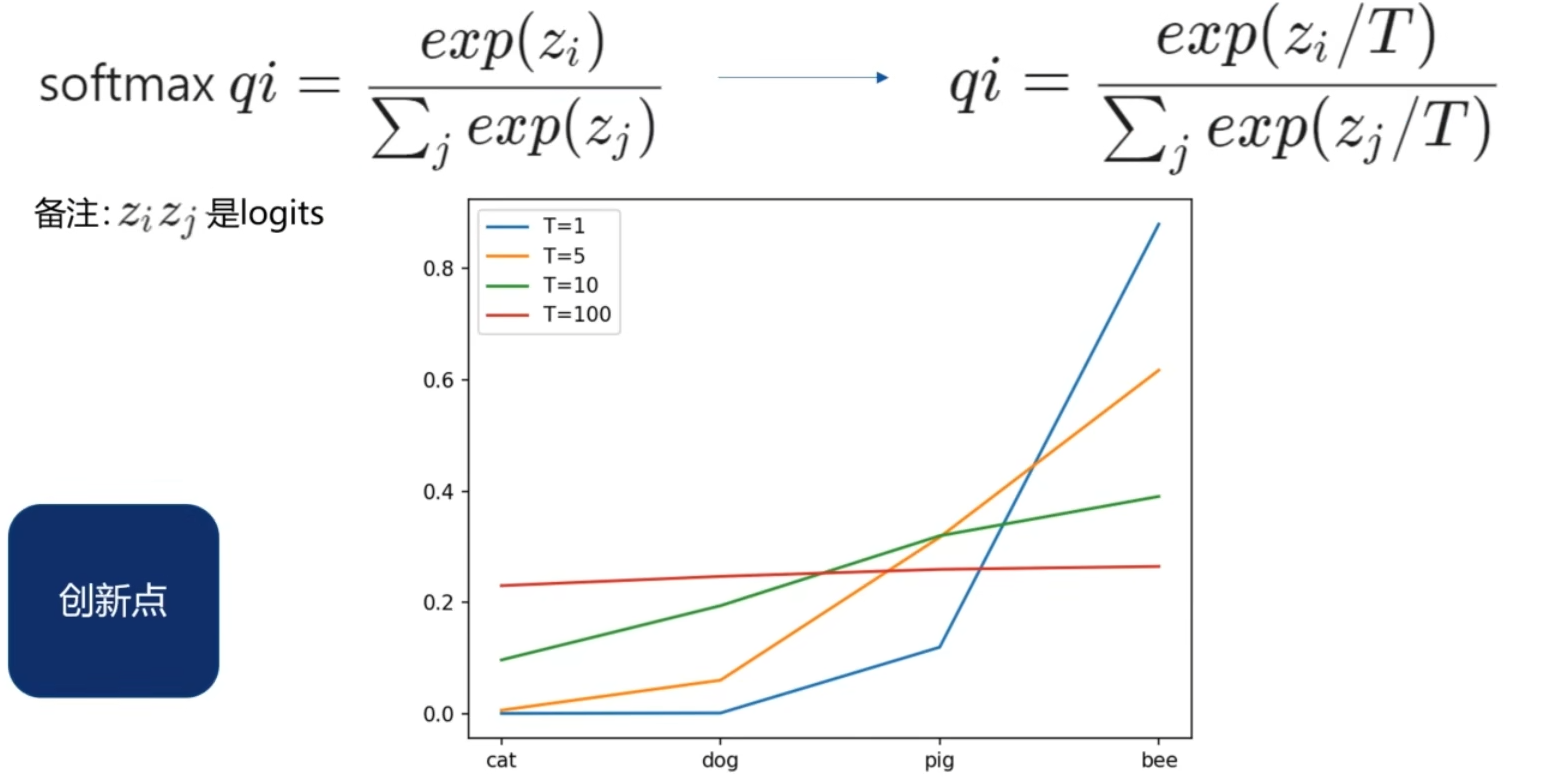
加入这个变量,能使各类别之间的输出更均衡,如下图[2]所示,T=1为softmax,但是当T过大时,会发现输出向量会趋于一条直线,因此,T通常取中间较小值。
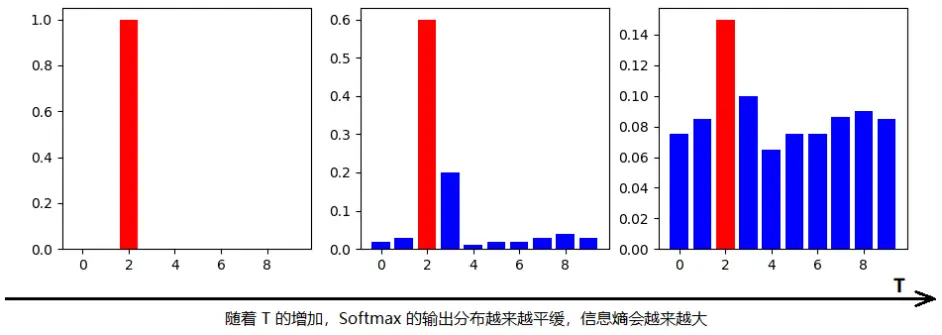
上面引入了一个新的变量温度T,这个T也可以称为蒸馏温度,原论文中给出了关于T的进一步讨论,随着T的增加,信息熵会越来越大,如下图[1]所示:
实际上,温度的高低改变的是Student模型训练过程中对负标签的关注程度。当温度较低时,对负标签的关注,尤其是那些显著低于平均值的负标签的关注较少;而温度较高时,负标签相关的值会相对增大,Student模型会相对更多地关注到负标签[1]。
因此,T的取值可以遵循如下策略:
需要注意的是,这个T只作用于教师网络和学生网络的蒸馏过程,学生网络正常输出仍使用softmax,即T取值为1,就像蒸馏过程一样,需要先进行升温,将知识蒸馏出来,然后输出的时候要冷却降温(T=1)
从原理上来讲,知识蒸馏没有想象中那么复杂,其流程如下图[1]所示:
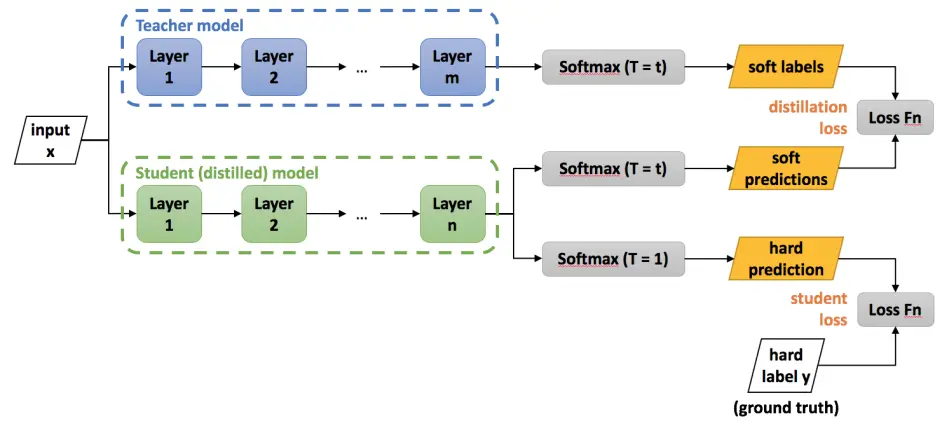
soft targets1soft targets2soft targets1 和 soft targets2 得到 distillation losssoft targets3soft targets3 和 ground truth 得到 student loss通过这五个步骤,就得到了两个损失值 distillation loss 和 student loss,那么训练的整体损失,就是这两个损失值的加权和,公式[2]如下:
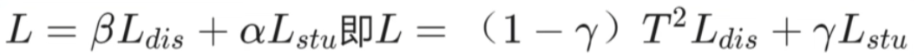
注:
后面,论文作者分别做了手写数字识别和声音识别实验,这里主要来看作者在MNIST数据集上的实验结果,结果如下表所示:
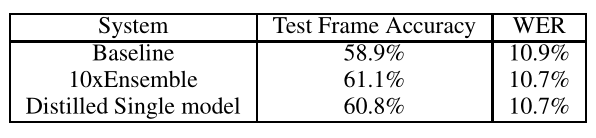
10xEnsemble是10个教师模型的平均值,Distilled Single model是Baseline模型经过蒸馏之后的结果,可以看到蒸馏出来的准确率提升了1.9%.
下面就将知识蒸馏融入到YOLOv5目标检测任务中,使用的是YOLOv5-6.0版本。
相关代码参考自:https://github.com/Adlik/yolov5
其实知识蒸馏的想法很简单,在仓库作者的代码版本中,修改的内容也并不多,主要是模型加载和损失计算部分。
下面按照顺序来解读一下修改内容。
首先是train_distillation.py这个文件,通过修改train.py得到。
新增四个参数:
parser.add_argument('--t_weights', type=str, default='./weights/yolov5s.pt',
help='initial teacher model weights path')
parser.add_argument('--t_cfg', type=str, default='models/yolov5s.yaml', help='teacher model.yaml path')
parser.add_argument('--d_output', action='store_true', default=False,
help='if true, only distill outputs')
parser.add_argument('--d_feature', action='store_true', default=False,
help='if true, distill both feature and output layers')
t_weights
教师模型权重,和学生模型加载类似
t_cfg
教师模型配置,和学生模型配置类似
d_output
这个参数写在这里但不起作用,应该是作者调试时用到的参数,默认是只蒸馏结果
d_feature
这个参数默认是关闭,如果开启,蒸馏损失计算将不仅仅是计算两个模型输出的结果,并且中间特征层也会参与计算(不过这个作者没写完整,可能写到一半弃坑了)
模型加载:
这部分需要多加载一个教师模型,相关代码如下:
# Model
check_suffix(weights, '.pt') # check weights
pretrained = weights.endswith('.pt')
if pretrained:
with torch_distributed_zero_first(LOCAL_RANK):
weights = attempt_download(weights) # download if not found locally
ckpt = torch.load(weights, map_location=device) # load checkpoint
model = Model(cfg or ckpt['model'].yaml, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
exclude = ['anchor'] if (cfg or hyp.get('anchors')) and not resume else [] # exclude keys
csd = ckpt['model'].float().state_dict() # checkpoint state_dict as FP32
csd = intersect_dicts(csd, model.state_dict(), exclude=exclude) # intersect
model.load_state_dict(csd, strict=False) # load
LOGGER.info(f'Transferred {len(csd)}/{len(model.state_dict())} items from {weights}') # report
# 这里添加加载教师模型
# Teacher model
LOGGER.info(f'Loaded teacher model {t_cfg}') # report
t_ckpt = torch.load(t_weights, map_location=device) # load checkpoint
t_model = Model(t_cfg or t_ckpt['model'].yaml, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device)
exclude = ['anchor'] if (t_cfg or hyp.get('anchors')) and not resume else [] # exclude keys
csd = t_ckpt['model'].float().state_dict() # checkpoint state_dict as FP32
csd = intersect_dicts(csd, t_model.state_dict(), exclude=exclude) # intersect
t_model.load_state_dict(csd, strict=False) # load
损失计算:
这里多了一个d_outputs_loss,也就是计算蒸馏损失
s_loss, loss_items = compute_loss(pred, targets.to(device)) # loss scaled by batch_size
d_outputs_loss = compute_distillation_output_loss(pred, t_pred, model, d_weight=10)
loss = d_outputs_loss + s_loss
蒸馏损失在loss.py中进行定义:
def compute_distillation_output_loss(p, t_p, model, d_weight=1):
t_ft = torch.cuda.FloatTensor if t_p[0].is_cuda else torch.Tensor
t_lcls, t_lbox, t_lobj = t_ft([0]), t_ft([0]), t_ft([0])
h = model.hyp # hyperparameters
red = 'mean' # Loss reduction (sum or mean)
if red != "mean":
raise NotImplementedError("reduction must be mean in distillation mode!")
DboxLoss = nn.MSELoss(reduction="none")
DclsLoss = nn.MSELoss(reduction="none")
DobjLoss = nn.MSELoss(reduction="none")
# per output
for i, pi in enumerate(p): # layer index, layer predictions
t_pi = t_p[i]
t_obj_scale = t_pi[..., 4].sigmoid()
# BBox
b_obj_scale = t_obj_scale.unsqueeze(-1).repeat(1, 1, 1, 1, 4)
t_lbox += torch.mean(DboxLoss(pi[..., :4], t_pi[..., :4]) * b_obj_scale)
# Class
if model.nc > 1: # cls loss (only if multiple classes)
c_obj_scale = t_obj_scale.unsqueeze(-1).repeat(1, 1, 1, 1, model.nc)
# t_lcls += torch.mean(c_obj_scale * (pi[..., 5:] - t_pi[..., 5:]) ** 2)
t_lcls += torch.mean(DclsLoss(pi[..., 5:], t_pi[..., 5:]) * c_obj_scale)
# t_lobj += torch.mean(t_obj_scale * (pi[..., 4] - t_pi[..., 4]) ** 2)
t_lobj += torch.mean(DobjLoss(pi[..., 4], t_pi[..., 4]) * t_obj_scale)
t_lbox *= h['box']
t_lobj *= h['obj']
t_lcls *= h['cls']
# bs = p[0].shape[0] # batch size
loss = (t_lobj + t_lbox + t_lcls) * d_weight
return loss
因为目标检测和原论文中的分类问题有所区别,并不能直接简单套用原论文提出的soft-target,那么这里的处理方式就是将三个损失(位置损失、目标损失、类别损失)简单粗暴地用MSELoss进行计算,然后蒸馏损失就是这三部分之和。
值得注意的是,理论部分我们提到过,蒸馏损失需要比学生损失的权重更大,因此,这里在计算蒸馏损失中,加入了一个权重d_weight,权重计算时取10.
下面是代码作者给出的一个实验结果:
| Model | Compression strategy | Input size [h, w] | mAPval 0.5:0.95 | Pretrain weight |
|---|---|---|---|---|
| yolov5s | baseline | [640, 640] | 37.2 | pth | onnx |
| yolov5s | distillation | [640, 640] | 39.3 | pth | onnx |
| yolov5s | quantization | [640, 640] | 36.5 | xml | bin |
| yolov5s | distillation + quantization | [640, 640] | 38.6 | xml | bin |
他采用的是coco数据集,用yolov5m作为教师模型,yolov5s作为学生模型,表格第二行展示了蒸馏之后的效果,mAP提升了2.1.
为了验证蒸馏是否有效,我在VisDrone数据集上进行了实验,训练了100epoch,实验结果如下表所示:
| Student Model | Teacher Model | Input size [h, w] | mAPtest 0.5 | mAPtest 0.5:0.95 |
|---|---|---|---|---|
| yolov5m | - | [640, 640] | 0.32 | 0.181 |
| yolov5m | yolov5m | [640, 640] | 0.305 | 0.163 |
| yolov5m | yolov5x | [640, 640] | 0.302 | 0.161 |
| yolov5m | - | [1280, 1280] | 0.448 | 0.261 |
| yolov5m | yolov5x | [1280, 1280] | 0.401 | 0.23 |
结果挺意外的,使用蒸馏训练之后,mAP反而下降了,严重怀疑蒸馏出来的是糟粕😵
知识蒸馏理论上并不复杂,但经过实验,基本判断这玩意理论价值大于应用价值,用来讲故事可以,实际上提升效果非常有限。当然这是我做了有限实验得出的初步结论,如果读者有更好的思路,可以在评论区留言和我讨论。
[1]【论文泛读】 知识蒸馏:Distilling the knowledge in a neural network:https://www.bilibili.com/read/cv16841475
[2]【论文精讲|无废话版】知识蒸馏:https://www.bilibili.com/video/BV1h8411t7SA
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
我想知道我的代码是否在rspec下运行。这可能吗?原因是我正在加载一些错误记录器,这些记录器在测试期间会被故意错误(expect{x}.toraise_error)弄得乱七八糟。我查看了我的ENV变量,没有(明显的)测试环境变量的迹象。 最佳答案 在spec_helper.rb的开头添加:ENV['RACK_ENV']='test'现在您可以在代码中检查RACK_ENV是否经过测试。 关于ruby-检测由RSpec、Ruby运行的代码,我们在StackOverflow上找到一个类似的问题
我正在使用rubydaemongem。想知道如何向停止操作添加一些额外的步骤?希望我能检测到停止被调用,并向其添加一些额外的代码。任何人都知道我如何才能做到这一点? 最佳答案 查看守护程序gem代码,它似乎没有用于此目的的明显扩展点。但是,我想知道(在守护进程中)您是否可以捕获守护进程在发生“停止”时发送的KILL/TERM信号...?trap("TERM")do#executeyourextracodehereend或者你可以安装一个at_exit钩子(Hook):-at_exitdo#executeyourextracodehe
按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visitthehelpcenter指导。关闭9年前。我最近开始学习Ruby,这是我的第一门编程语言。我对语法感到满意,并且我已经完成了许多只教授相同基础知识的教程。我已经写了一些小程序(包括我自己的数组排序方法,在有人告诉我谷歌“冒泡排序”之前我认为它非常聪明),但我觉得我需要尝试更大更难的东西来理解更多关于Ruby.关于如何执行此操作的任何想法?
我有一个定义类的Ruby脚本。我希望脚本执行语句BoolParser.generate:file_base=>'bool_parser'仅当脚本作为可执行文件被调用时,而不是当它被irbrequire(或通过-r在命令行上传递)时。我可以用什么来包装上面的语句,以防止它在我的Ruby文件加载时执行? 最佳答案 条件$0==__FILE__...!/usr/bin/ruby1.8classBoolParserdefself.generate(args)p['BoolParser.generate',args]endendif$0==_
我有以下字符串,我想检测那里的换行符。但是Ruby的字符串方法include?检测不到它。我正在运行Ruby1.9.2p290。我哪里出错了?"/'ædres/\nYour".include?('\n')=>false 最佳答案 \n需要在双引号内,否则无法转义。>>"\n".include?'\n'=>false>>"\n".include?"\n"=>true 关于Ruby无法检测字符串中的换行符,我们在StackOverflow上找到一个类似的问题: h
文章目录1.自动驾驶实战:基于Paddle3D的点云障碍物检测1.1环境信息1.2准备点云数据1.3安装Paddle3D1.4模型训练1.5模型评估1.6模型导出1.7模型部署效果附录show_lidar_pred_on_image.py1.自动驾驶实战:基于Paddle3D的点云障碍物检测项目地址——自动驾驶实战:基于Paddle3D的点云障碍物检测课程地址——自动驾驶感知系统揭秘1.1环境信息硬件信息CPU:2核AI加速卡:v100总显存:16GB总内存:16GB总硬盘:100GB环境配置Python:3.7.4框架信息框架版本:PaddlePaddle2.4.0(项目默认框架版本为2.3
我有一个连接到服务器的rubytcpsocket客户端。在发送数据之前如何检查套接字是否已连接?我是否尝试“拯救”断开连接的tcpsocket,重新连接然后重新发送?如果是这样,有没有人有一个简单的代码示例,因为我不知道从哪里开始:(我很自豪我设法在rails中获得了一个持久连接的客户端tcpsocket。然后服务器决定杀死客户端,一切都崩溃了;)编辑我已经使用此代码解决了一些问题-如果未连接,它将尝试重新连接,但如果服务器已关闭则不会处理这种情况(它将继续重试)。这是正确方法的开始吗?谢谢defself.write(data)begin@@my_connection.write(
我在一台Windows764位机器上使用Sass和Ruby(最新版本),我正在我的家庭服务器上处理一个共享文件夹。(但是,我不得不承认问题本身也出现在服务器上,因为我试图安装Ruby并直接-watch服务器上的文件)。问题如下:如果我第一次保存,检测到变化,我的style.css被直接覆盖。之后,我总是需要保存多达7次才能覆盖style.css。每次都会检测到更改,但不会编译任何内容。这是一个屏幕:>>>Sassiswatchingforchanges.PressCtrl-Ctostop.overwritestyle.css>>>Changedetectedto:E:/Websites
我所在的团队负责管理公司面向公众的云平台。我们拥有大量运行面向互联网的VM的用户群。我想对我们的地址空间进行自动扫描,看看是否有人在运行Rails应用程序,这样我就可以通知他们升级他们的Rails版本,以避免本周出现的严重安全漏洞。我注意到在某些Apache部署中,有一个有用的PassengerHeader:X-Powered-By:PhusionPassenger(mod_rails/mod_rack)2.0.3然而,这并不可靠。我想知道是否有一种可靠的方法来检测在Web服务器后面运行的Rails,无论是使用响应header还是某种可以确定的GET/POST。谢谢!