这就是NoSql
NoSQL:即 Not-Only SQL( 泛指非关系型的数据库),作为关系型数据库的补充。 作用:应对基于海量用户和海量数据前提下的数据处理问题。
特征
常见NoSql数据库
1.数据间没有必然的关联关系
2.内部采用单线程机制进行工作
3.高性能。官方提供测试数据,50个并发执行100000 个请求,读的速度是110000 次/s,写的速度是81000次/s。
4.多数据类型支持
字符串类型,string list
列表类型,hash set
散列类型,zset/sorted_set
集合类型
有序集合类型
5.支持持久化,可以进行数据灾难恢复
#启动服务器,默认启动端口为6379
redis-server
#启动服务器,指定6380端口启动
redis-server --port 6380
#启动客户端,默认连接6379端口 redis-cli [-h host] [-p port]
redis-cli
#启动客户端,指定6380端口连接
redis-cli -p 6380
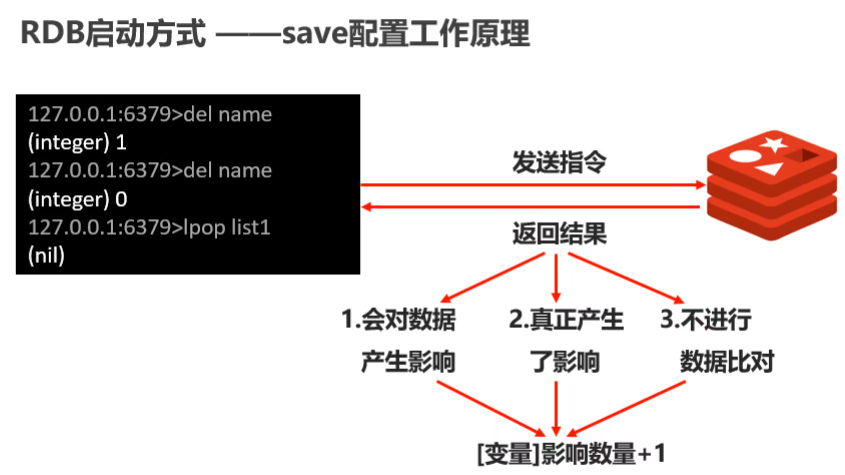
sava指令
bgsave指令
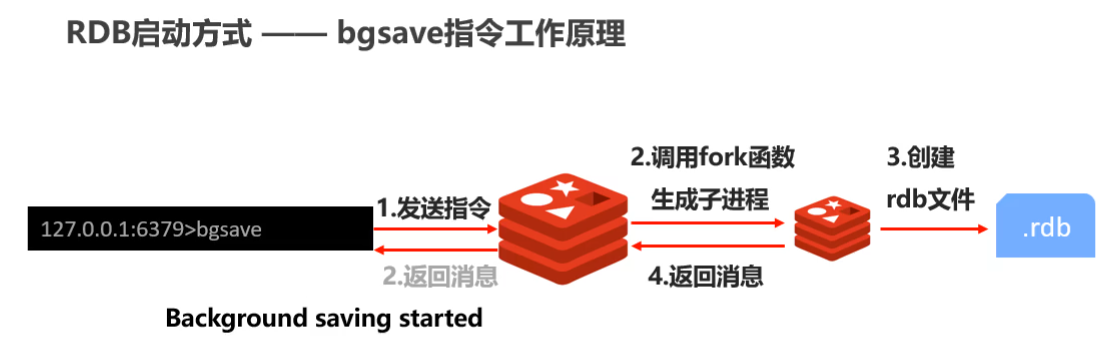
#second:监控时间范围 changes:监控key的变化量
save second changes
save 10 2
RDB特殊启动形式
debug reload
shutdown save
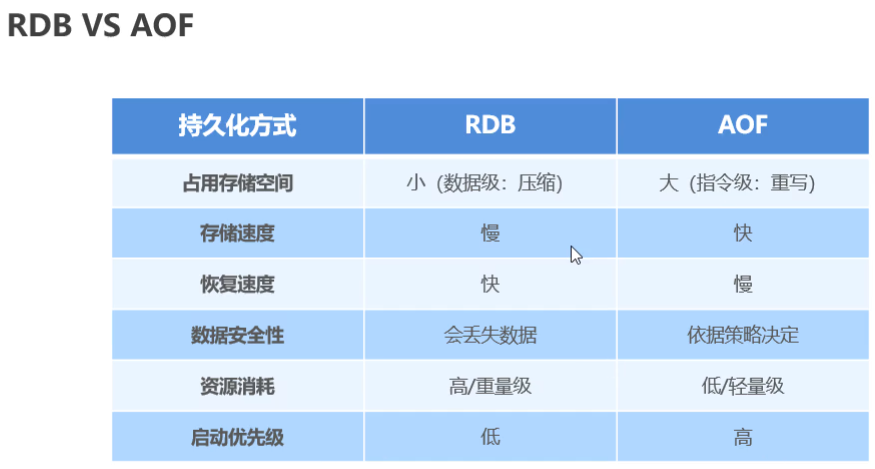
RDB优点
RDB缺点
RDB存储的弊端
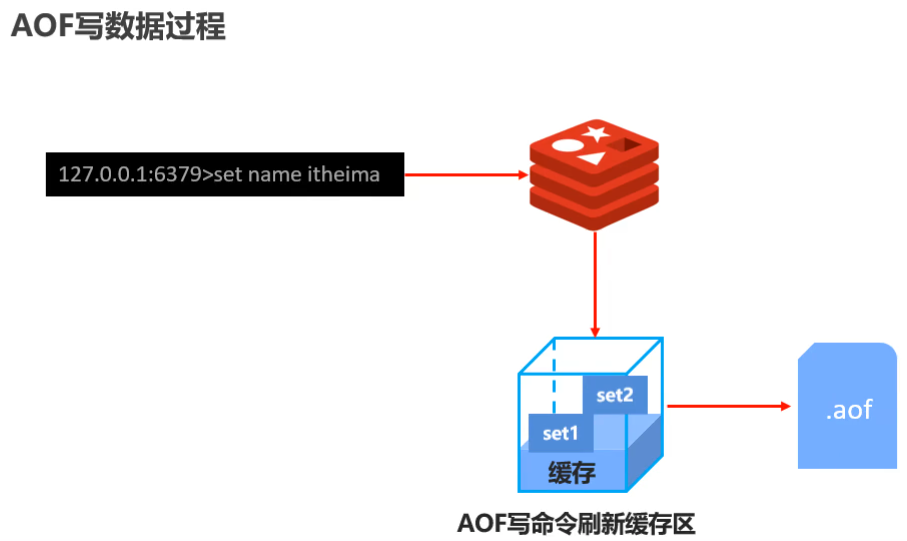
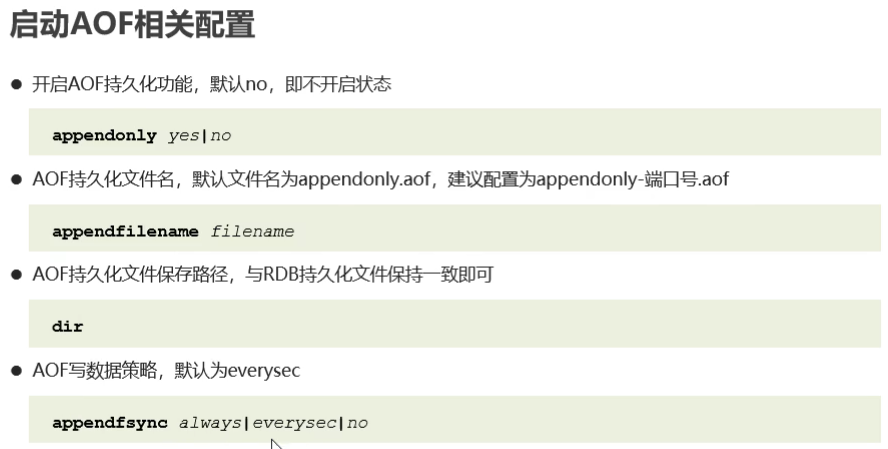


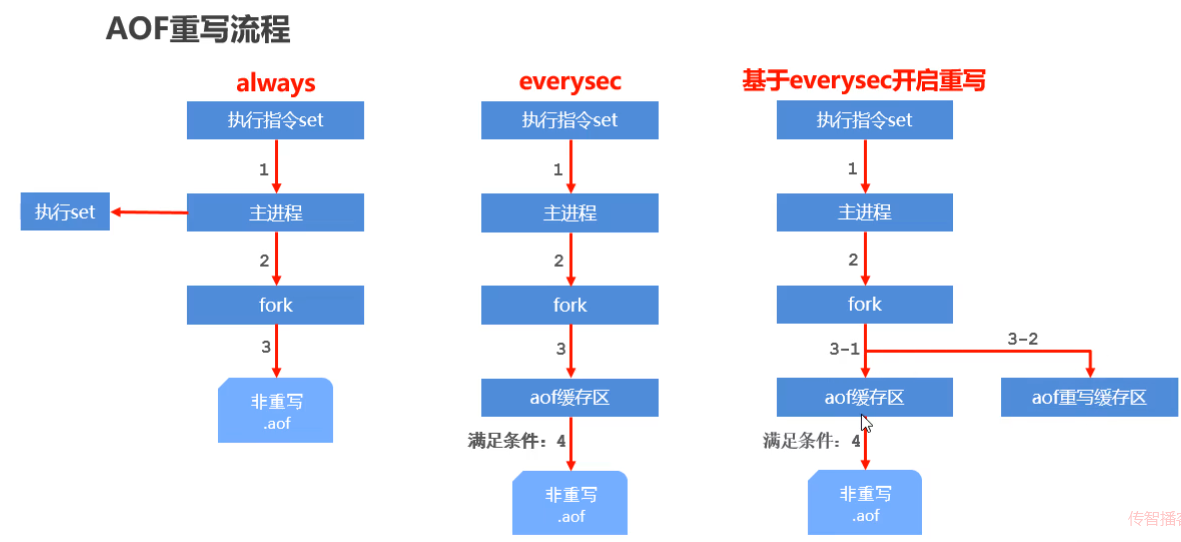
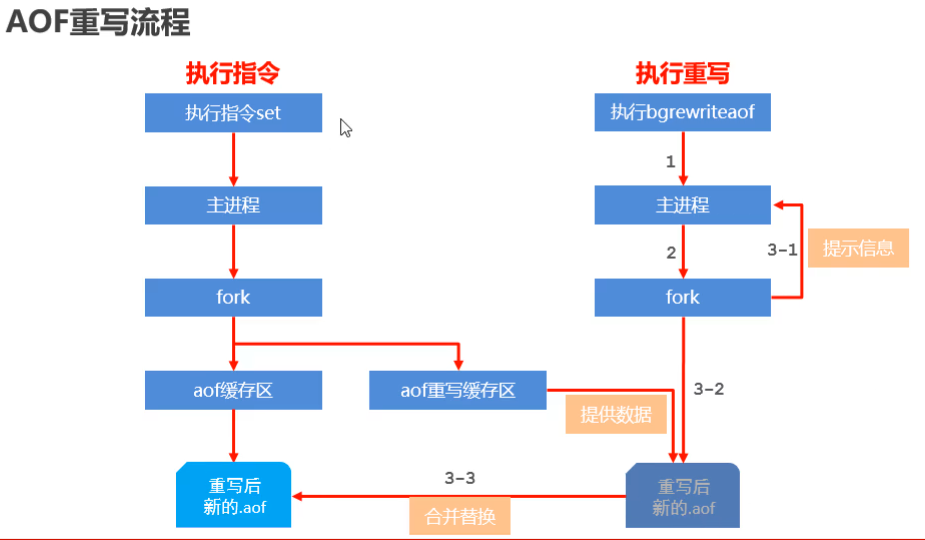
bgrewriteaof


数据到达过期时间,不做处理。等下次访问该数据时,我们需要判断
定时删除和惰性删除这两种方案都是走的极端,那有没有折中方案?
我们来讲redis的定期删除方案:
如果key超时,删除key
如果一轮中删除的key的数量>W*25%,循环该过程
如果一轮中删除的key的数量≤W*25%,检查下一个expires[*],0-15循环
W取值=ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP属性值
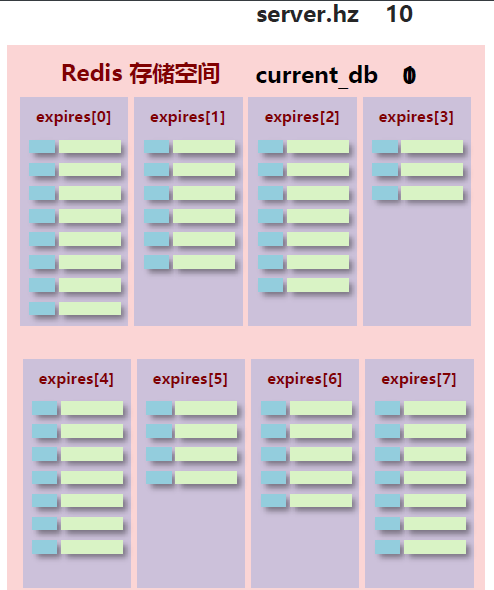
总的来说:定期删除就是周期性轮询redis库中的时效性数据,采用随机抽取的策略,利用过期数据占比的方式控制删除频度

什么叫数据淘汰策略?什么样的应用场景需要用到数据淘汰策略?
当新数据进入redis时,如果内存不足怎么办?在执行每一个命令前,会调用freeMemoryIfNeeded()检测内存是否充足。如果内存不满足新 加入数据的最低存储要求,redis要临时删除一些数据为当前指令清理存储空间。清理数据的策略称为逐出算法。
注意:逐出数据的过程不是100%能够清理出足够的可使用的内存空间,如果不成功则反复执行。当对所有数据尝试完毕, 如不能达到内存清理的要求,将出现错误信息如下
(error) OOM command not allowed when used memory >'maxmemory'
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
1.postman介绍Postman一款非常流行的API调试工具。其实,开发人员用的更多。因为测试人员做接口测试会有更多选择,例如Jmeter、soapUI等。不过,对于开发过程中去调试接口,Postman确实足够的简单方便,而且功能强大。2.下载安装官网地址:https://www.postman.com/下载完成后双击安装吧,安装过程极其简单,无需任何操作3.使用教程这里以百度为例,工具使用简单,填写URL地址即可发送请求,在下方查看响应结果和响应状态码常用方法都有支持请求方法:getpostputdeleteGet、Post、Put与Delete的作用get:请求方法一般是用于数据查询,
Ⅰ软件测试基础一、软件测试基础理论1、软件测试的必要性所有的产品或者服务上线都需要测试2、测试的发展过程3、什么是软件测试找bug,发现缺陷4、测试的定义使用人工或自动的手段来运行或者测试某个系统的过程。目的在于检测它是否满足规定的需求。弄清预期结果和实际结果的差别。5、测试的目的以最小的人力、物力和时间找出软件中潜在的错误和缺陷6、测试的原则28原则:20%的主要功能要重点测(eg:支付宝的支付功能,其他功能都是次要的)80%的错误存在于20%的代码中7、测试标准8、测试的基本要求功能测试性能测试安全性测试兼容性测试易用性测试外观界面测试可靠性测试二、质量模型衡量一个优秀软件的维度①功能性功
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visitthehelpcenter指导。关闭9年前。我最近开始学习Ruby,这是我的第一门编程语言。我对语法感到满意,并且我已经完成了许多只教授相同基础知识的教程。我已经写了一些小程序(包括我自己的数组排序方法,在有人告诉我谷歌“冒泡排序”之前我认为它非常聪明),但我觉得我需要尝试更大更难的东西来理解更多关于Ruby.关于如何执行此操作的任何想法?
(本文是网络的宏观的概念铺垫)目录计算机网络背景网络发展认识"协议"网络协议初识协议分层OSI七层模型TCP/IP五层(或四层)模型报头以太网碰撞路由器IP地址和MAC地址IP地址与MAC地址总结IP地址MAC地址计算机网络背景网络发展 是最开始先有的计算机,计算机后来因为多项技术的水平升高,逐渐的计算机变的小型化、高效化。后来因为计算机其本身的计算能力比较的快速:独立模式:计算机之间相互独立。 如:有三个人,每个人做的不同的事物,但是是需要协作的完成。 而这三个人所做的事是需要进行协作的,然而刚开始因为每一台计算机之间都是互相独立的。所以前面的人处理完了就需要将数据
目录H2数据库入门以及实际开发时的使用1.H2数据库的初识1.1H2数据库介绍1.2为什么要使用嵌入式数据库?1.3嵌入式数据库对比1.3.1性能对比1.4技术选型思考2.H2数据库实战2.1H2数据库下载搭建以及部署2.1.1H2数据库的下载2.1.2数据库启动2.1.2.1windows系统可以在bin目录下执行h2.bat2.1.2.2同理可以通过cmd直接使用命令进行启动:2.1.2.3启动后控制台页面:2.1.3spring整合H2数据库2.1.3.1引入依赖文件2.1.4数据库通过file模式实际保存数据的位置2.2H2数据库操作2.2.1Mysql兼容模式2.2.2Mysql模式
文章目录概念索引相关操作创建索引更新副本查看索引删除索引索引的打开与关闭收缩索引索引别名查询索引别名文档相关操作新建文档查询文档更新文档删除文档映射相关操作查询文档映射创建静态映射创建索引并添加映射概念es中有三个概念要清楚,分别为索引、映射和文档(不用死记硬背,大概有个印象就可以)索引可理解为MySQL数据库;映射可理解为MySQL的表结构;文档可理解为MySQL表中的每行数据静态映射和动态映射上面已经介绍了,映射可理解为MySQL的表结构,在MySQL中,向表中插入数据是需要先创建表结构的;但在es中不必这样,可以直接插入文档,es可以根据插入的文档(数据),动态的创建映射(表结构),这就
目录1关系运算符2运算符优先级3关系表达式的书写代码实例:下面是面试中可能遇到的问题:1关系运算符C++中有6个关系运算符,用于比较两个值的大小关系,它们分别是:运算符描述==等于!=不等于小于>大于小于等于>=大于等于这些运算符返回一个布尔值,即true或false。例如,当x等于y时,x==y的结果为true,否则结果为false。2运算符优先级在C++中,关系运算符的优先级高于赋值运算符,但低于算术运算符。以下是关系运算符的优先级,从高到低排列:运算符描述>,,>=,关系运算符==,!=相等性运算符&&逻辑与`如果在表达式中有多个运算符,则按照优先级顺序依次进行运算。3关系表达式的书写在
一.计算机组成原理 这本书利用组合逻辑、同步时序逻辑电路设计的相关知识,从逻辑门开始逐步构建运算器、存储器、数据通路和控制器,最终集成为完整的CU原型系统,使读者从设计者的角度理解计算机部件构成及运行的基本原理,掌握软硬件协同的概念。 全书共9章,主要内容包括计算机系统概述、数据信息的表示、运算方法与运算器、存储系统、指令系统、中央处理器、指令流水线、总线系统、输入输出系统。1.计算机系统概述1.1计算机发展历程 计算机是一种能够按照事先存储的程序,自动、高速、准确地对相关信息进行处理的电子设备。1946年2月,世界上第一台电子数字计算机ENIAC(ElectronicNum