接上一篇文章《UG/NX二次开发环境配置方法(nx1980+vs2019)》,这一篇文章我们将详细讲述,如何开发一个具体的功能——根据用户输入的数据,在原点处创建一个指定大小的立方体。
由于本功能还涉及到nx的一些基本操作,所以这里先讲一下nx的基本操作。
1.打开nx1980。windows开始→Siemens NX→NX。
此时可能会遇到一个无法修改属性值的问题,忽略即可,如果没有遇到错误则不必理会。

选项值错误
2.新建模型文件,方便后续测试。
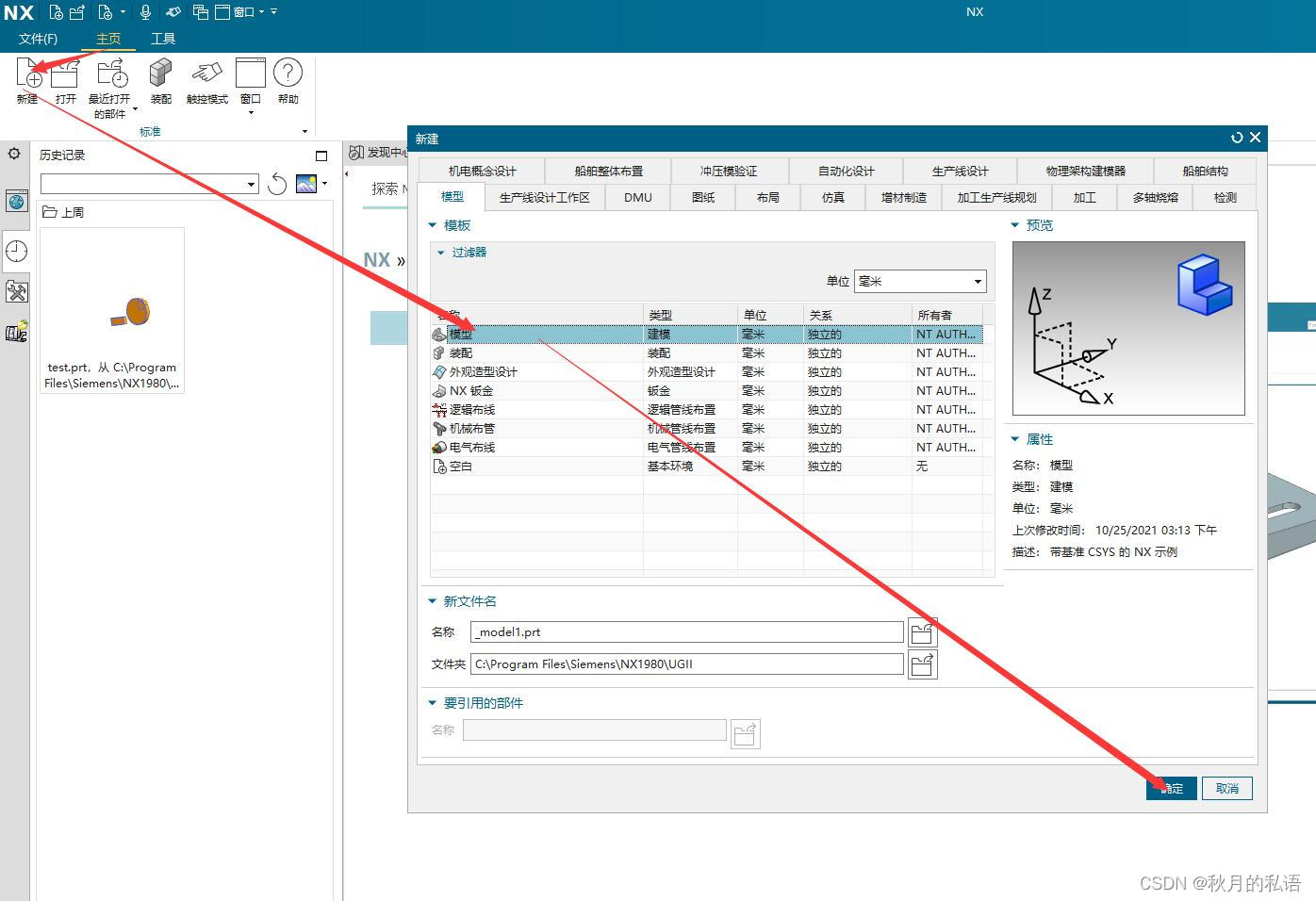
3.确认新建完成。
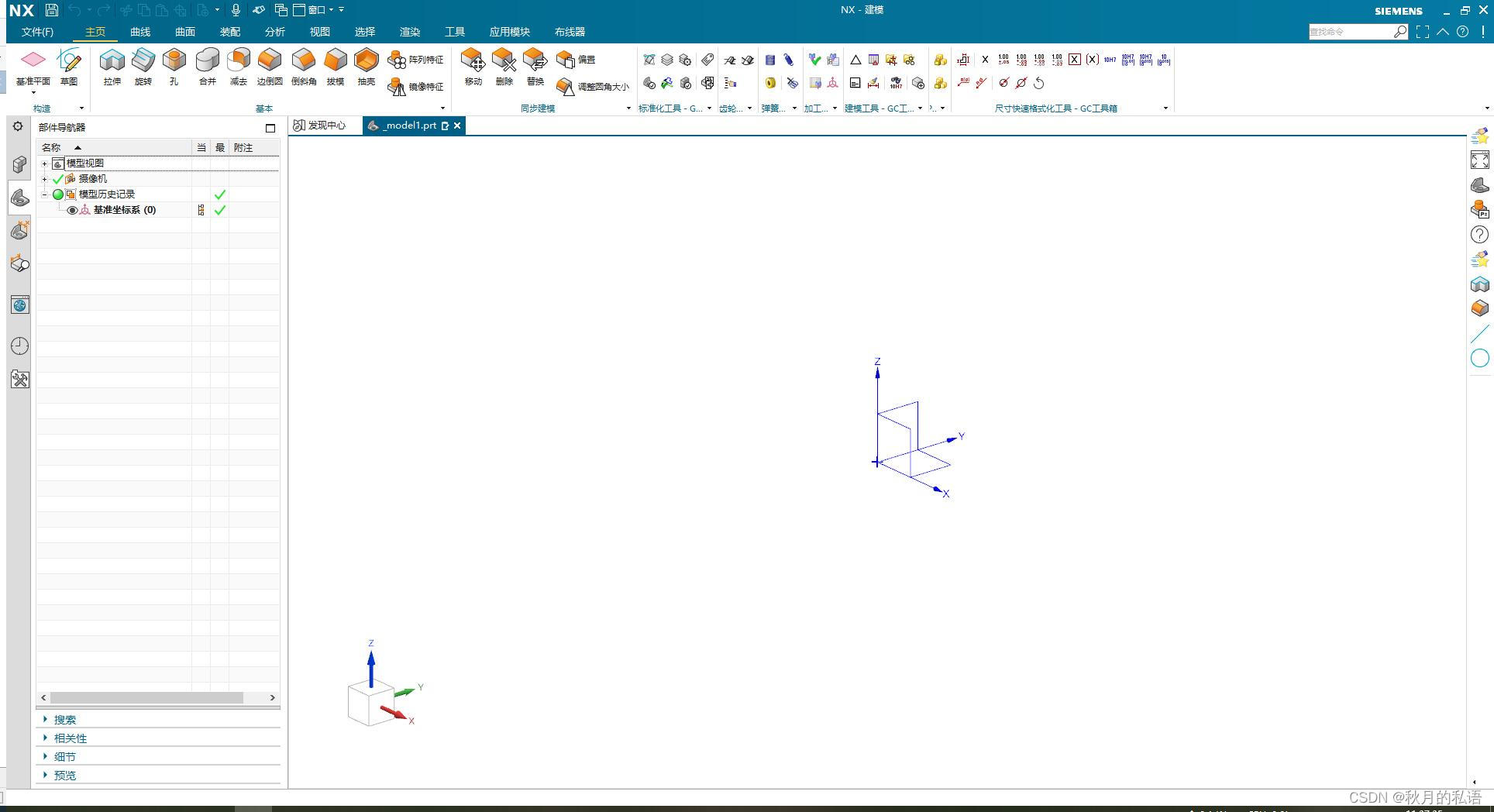
以上就是基本操作了,下面进入界面开发流程,nx1980的界面开发操作,也需要在块UI界面编辑器中操作,很多教程都没有讲解这一点,尤其是如何进入块UI界面编辑器,那么我在这里详细说明一下步骤。
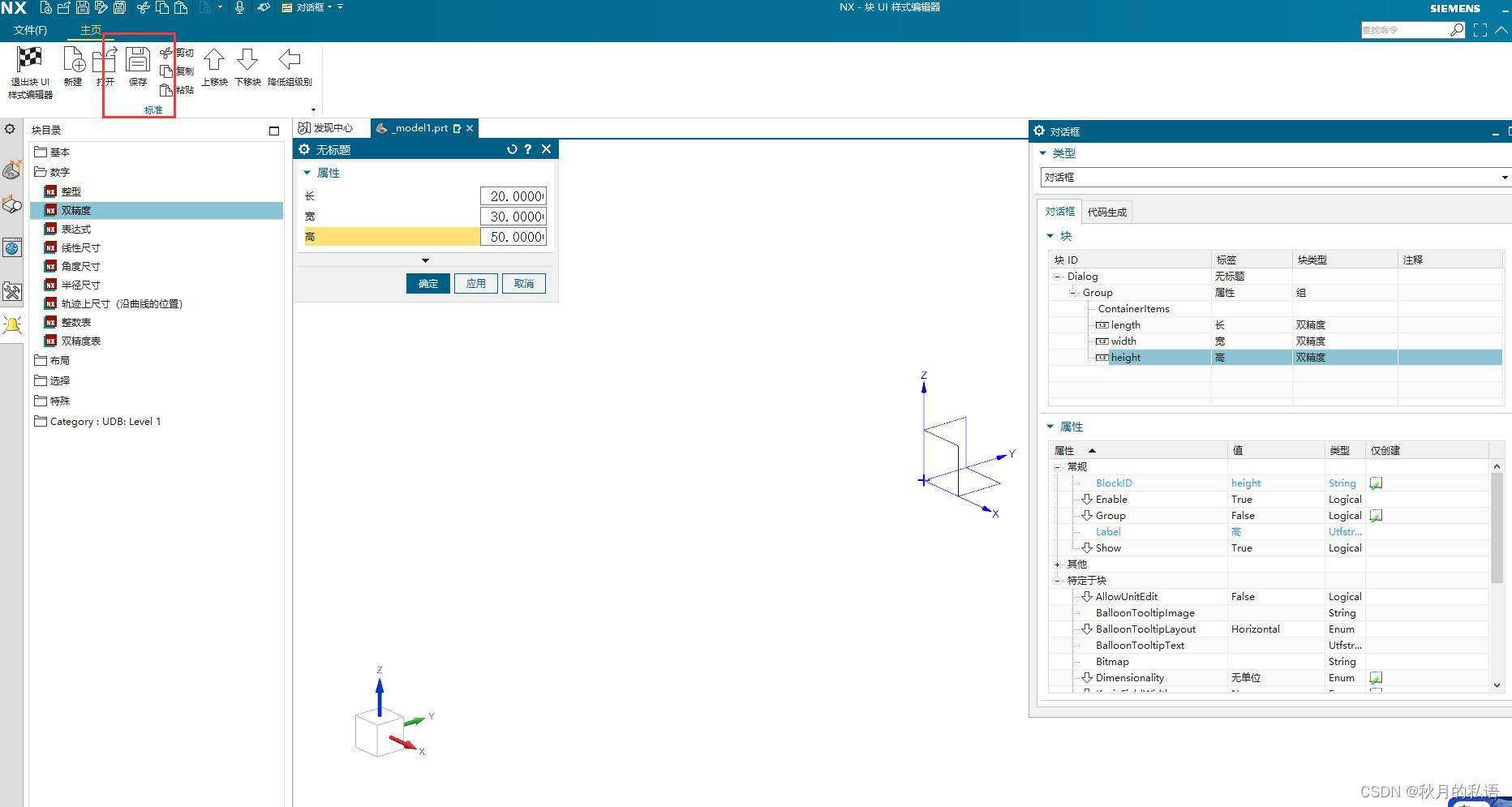
4.在新建模型完成后,我们准备创建交互UI,按照下图所示的顺序,找到块UI界面编辑器,。

如下图所示:
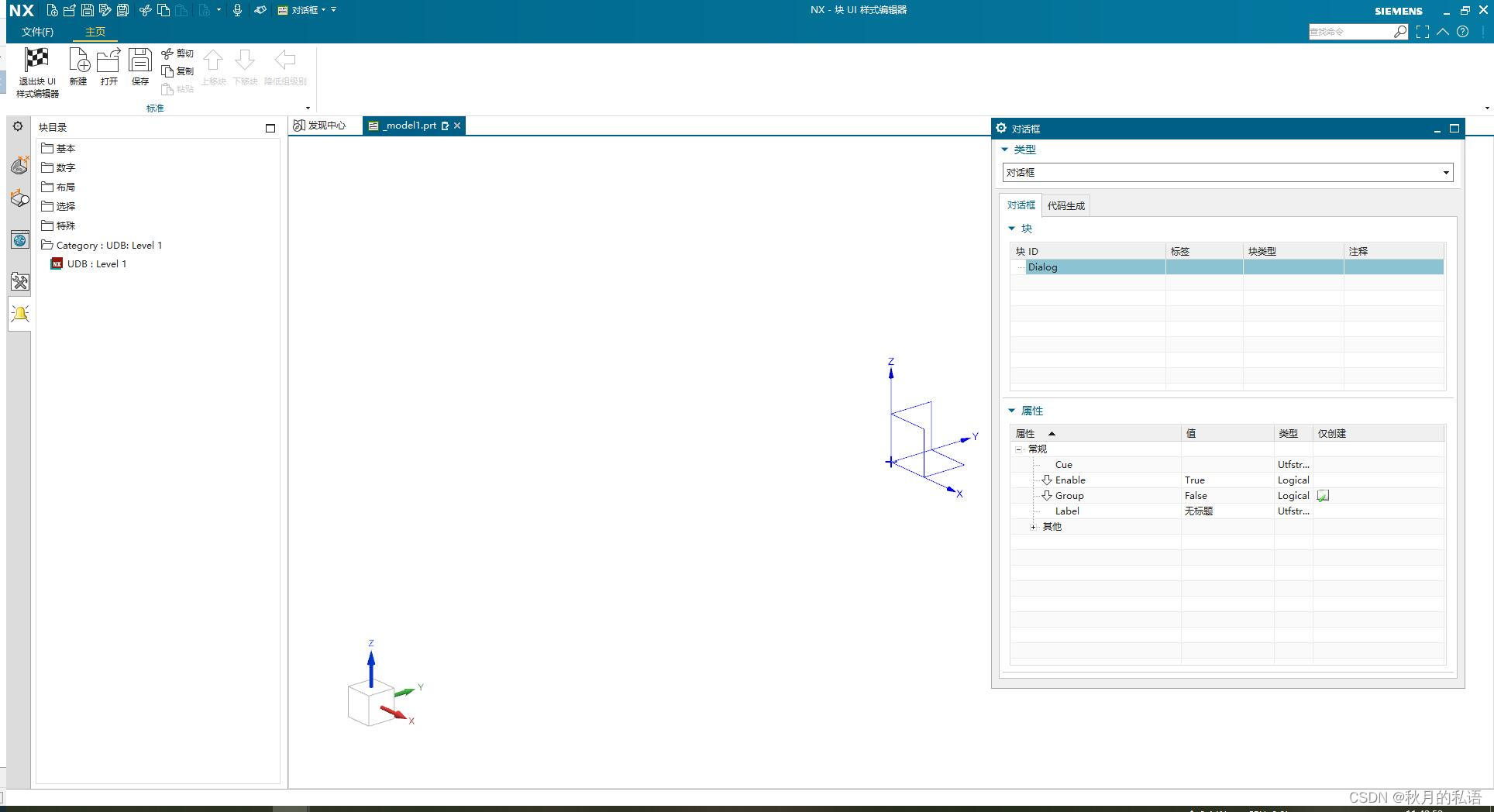
5.点击左侧的 数字→双精度,点击三次,这样就会出现如下界面。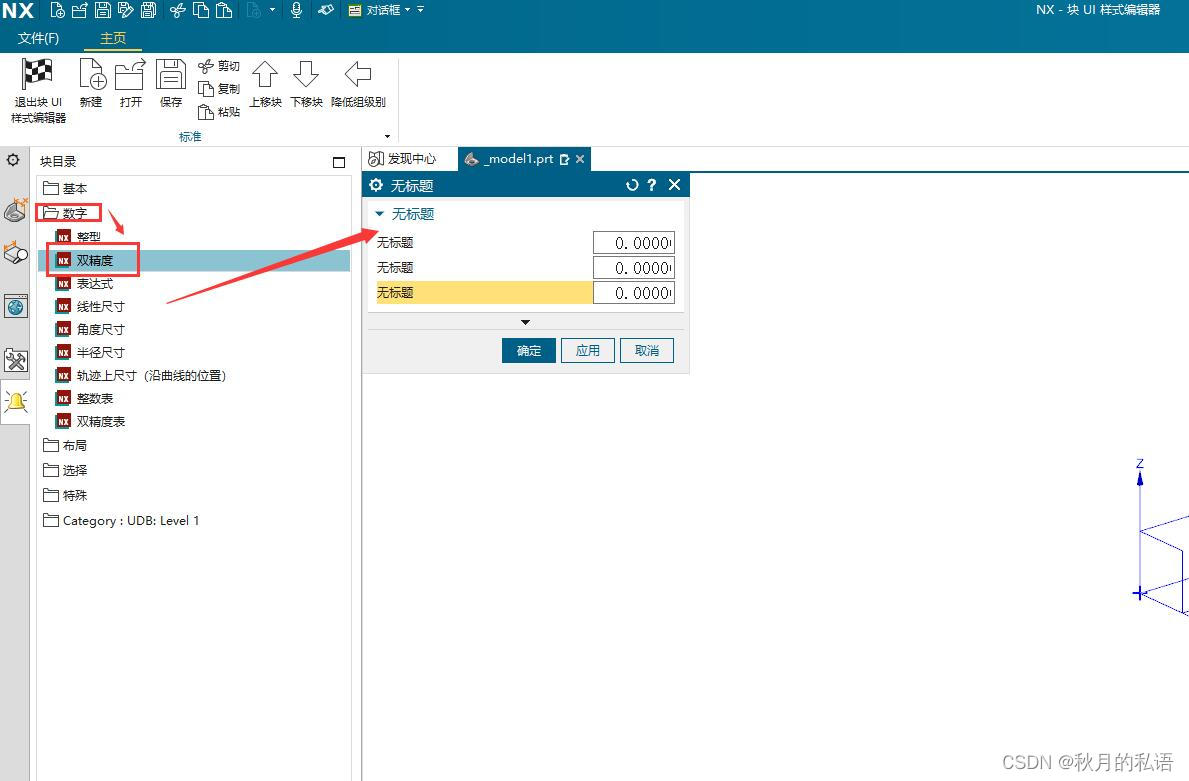
此时,查看右侧的对话框属性,我们需要修改如下属性值。

将double0更改为length,将No Title更改为 长,则会发现左侧的界面已经发生了对应的变化。
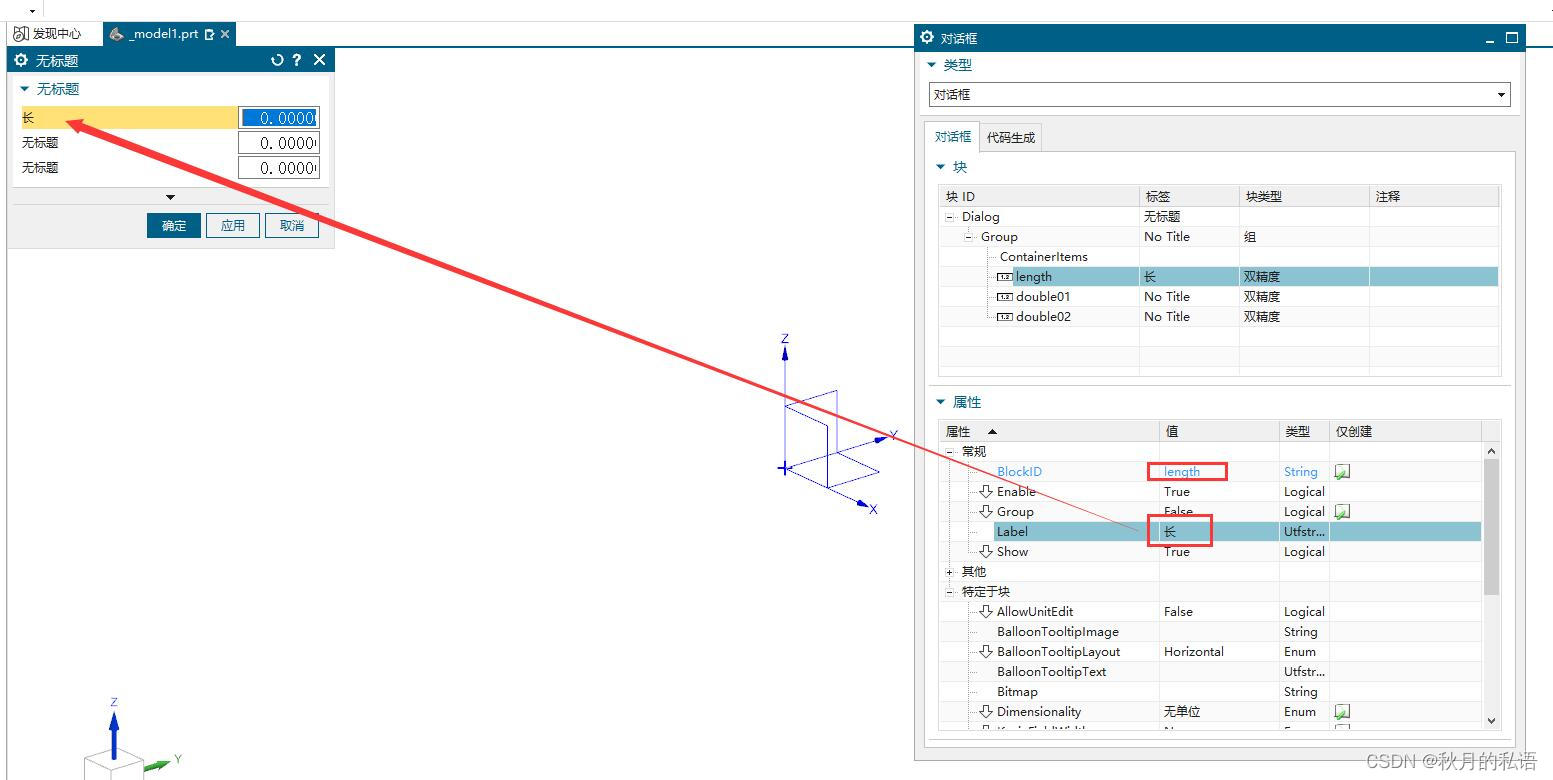
用同样的方法,更改double1和double2,分别对应宽和高。

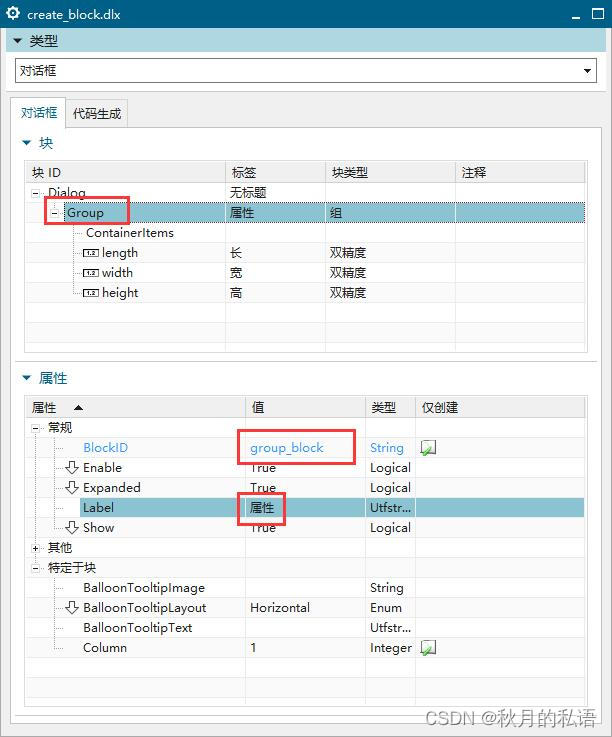
修改group的属性值为group_block,对应的标签为“属性”,然后直接在左侧的界面中,将长宽高的数值更改为20.0、30.0、50.0,作为默认值,如下图所示:
属性
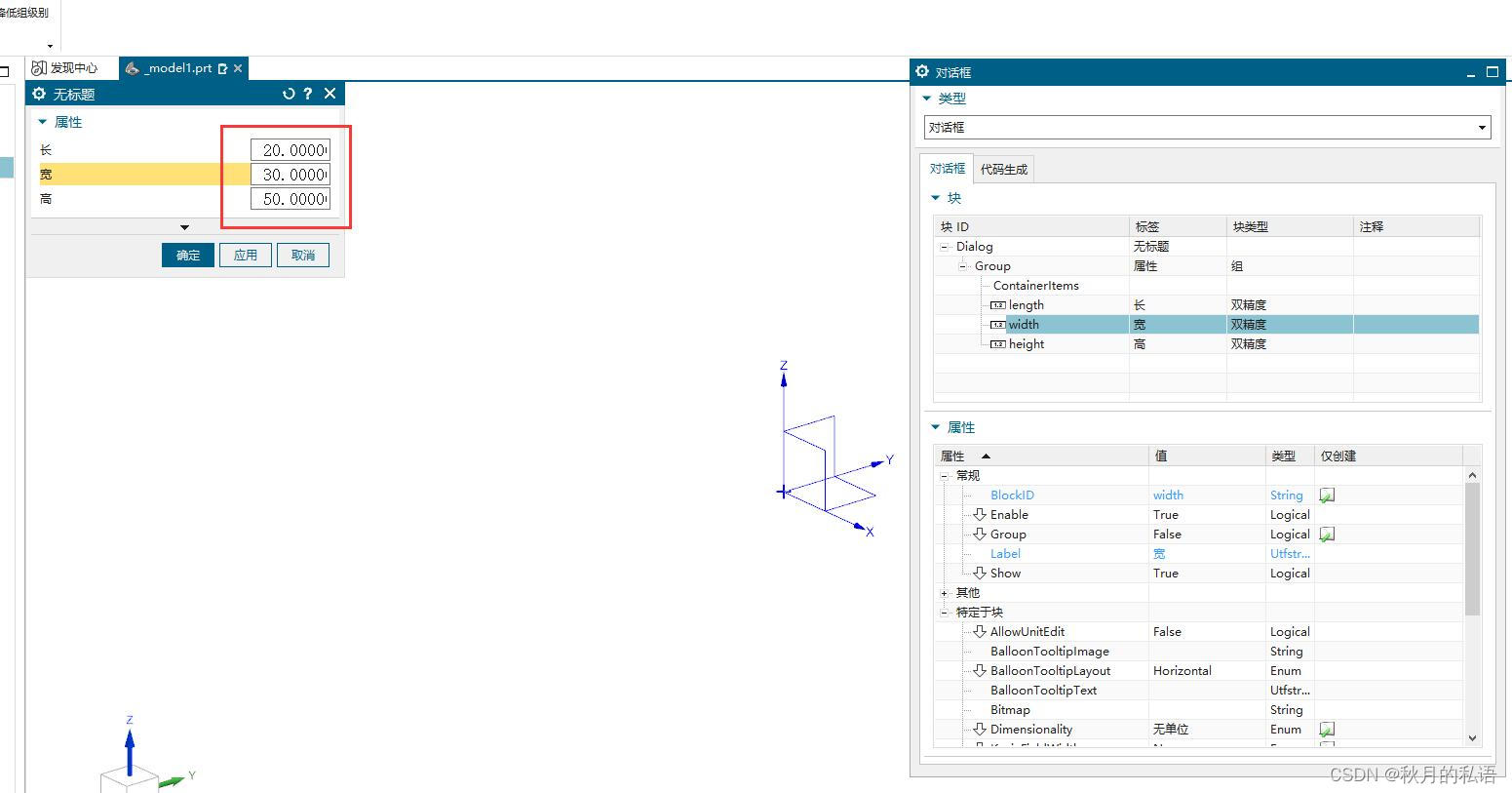
默认值
在对话框中,点击代码生成,然后在c#上点击右键,选择c++,如下图所示: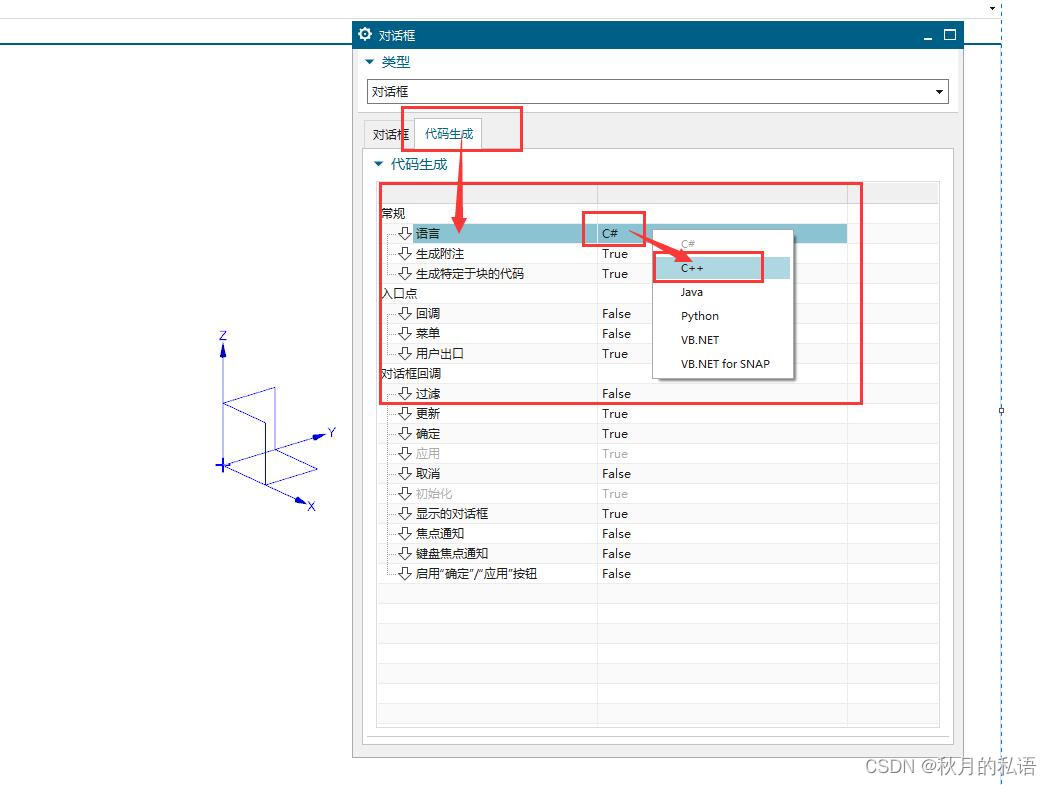
选择之后,如下图所示:
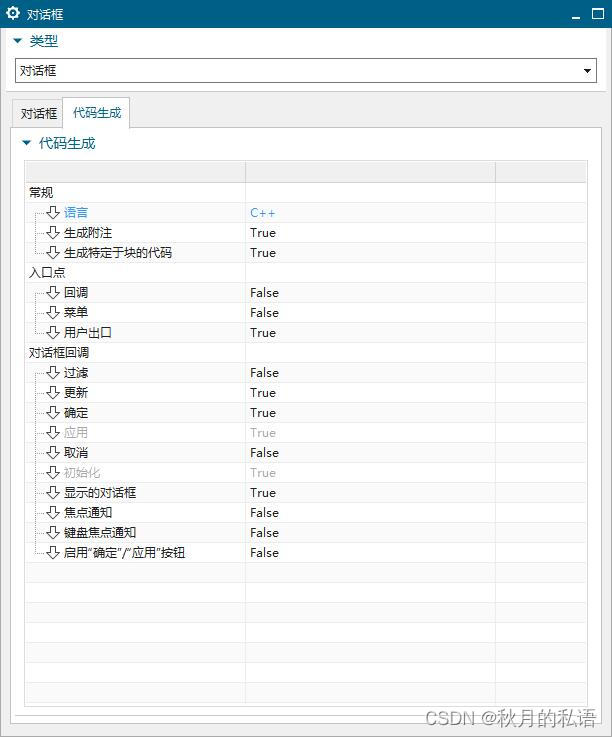
然后点击块UI界面编辑器主界面左上角的保存按钮 ,如下图所示。
可以将文件保存当桌面,笔者保存在桌面的create_block目录中了,如下图所示,可以发现生成了三个文件。

至此开发的准备工作已经全部完成了,下面进入vs2019进行功能开发。
5.打开vs,新建项目,创建新项目,在搜索模板(下图中红色标记区域)输入框中输入“nx”,选择 “NXOpenc C++ Wizard”,如下图所示:
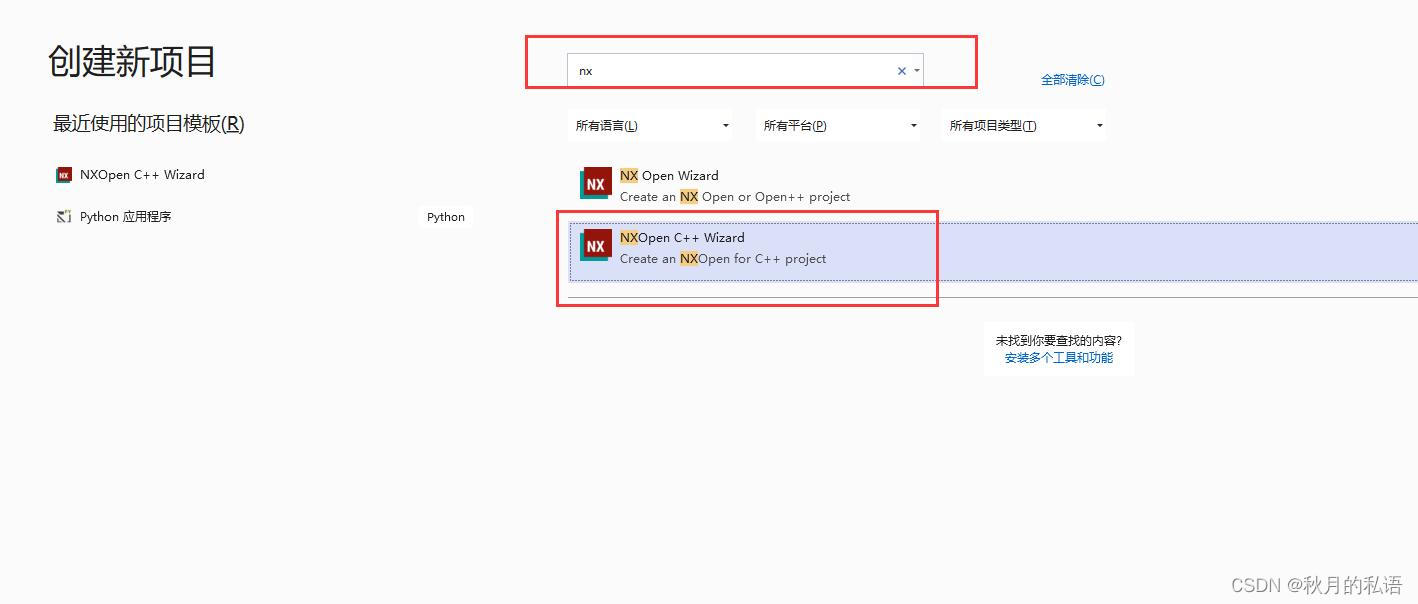
6.选择项目保存位置,笔者未更改,默认 C:\Users\Administrator\source\repos,命名为create_block。

7.点击创建,出现向导。

8.上图中可以直接点击Finish完成,但是我们可以先看看选项内容,后续需要的时候可以修改。
笔者全部使用默认设置,点击下一步,直到结束。
9.此时vs默认打开工程,但是实际上我们并不需要生成的cpp文件。
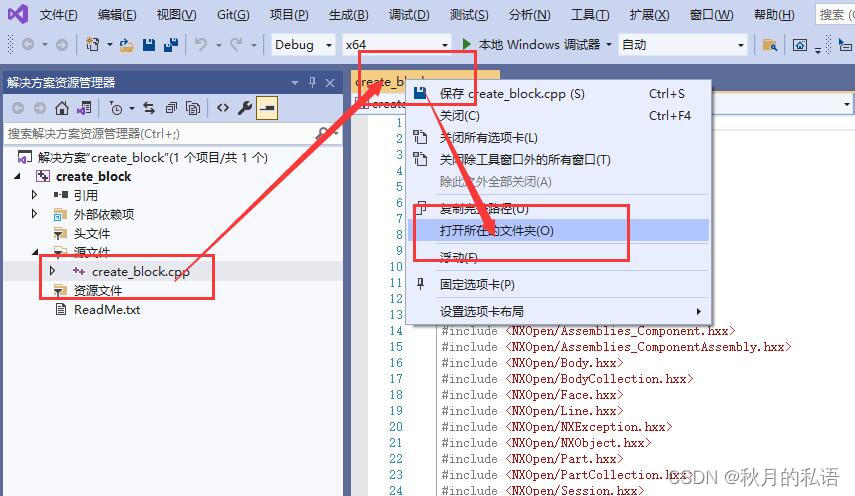
按照下图中的顺序,找到源文件位置。
然后将步骤4中生成的界面文件(三个文件)全部拷贝到上述目录中,替换即可。
如下图所示:
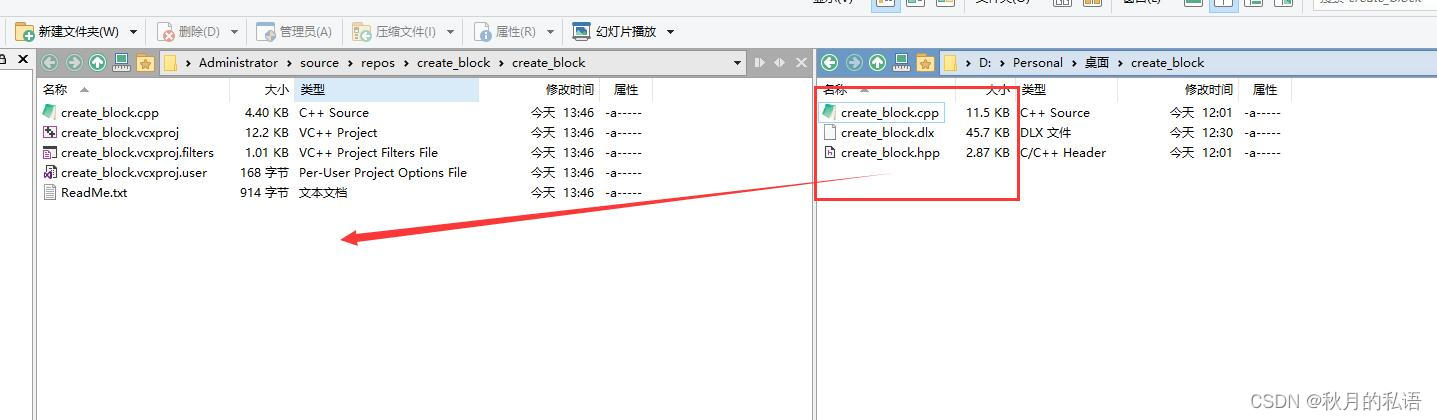

然后再次回到vs,会发现头文件和变量似乎不识别的问题(但是实际上没问题,代码可以直接编译运行,生成dll),如下图所示:
10.在create_block.cpp中找到如下函数int create_block::apply_cb();修改内容如下:
(1)添加头文件:
#include <uf.h>
#include <uf_modl_primitives.h>
(2)修改int create_block::apply_cb()函数:
//------------------------------------------------------------------------------
//Callback Name: apply_cb
//------------------------------------------------------------------------------
int create_block::apply_cb()
{
int errorCode = 0;
try
{
//---- Enter your callback code here -----
UF_initialize();
char szLength[MAX_TEXT_LENGTH];
char szWidth[MAX_TEXT_LENGTH];
char szHeight[MAX_TEXT_LENGTH];
length->Value();
sprintf(szLength, "%lf", length->Value());
sprintf(szWidth, "%lf", width->Value());
sprintf(szHeight, "%lf", height->Value());
double origin[3] = { 0.0, 0.0, 0.0 };
char* edge_len[3] = { szLength, szWidth, szHeight};
tag_t blk_obj_id = NULL_TAG;
UF_MODL_create_block1(UF_NULLSIGN, origin, edge_len, &blk_obj_id);
UF_terminate();
}
catch(exception& ex)
{
//---- Enter your exception handling code here -----
errorCode = 1;
create_block::theUI->NXMessageBox()->Show("Block Styler", NXOpen::NXMessageBox::DialogTypeError, ex.what());
}
return errorCode;
}如下图所示:

11.create_block.cpp修改完成后,切换到Release模式,编译生成对应的dll。
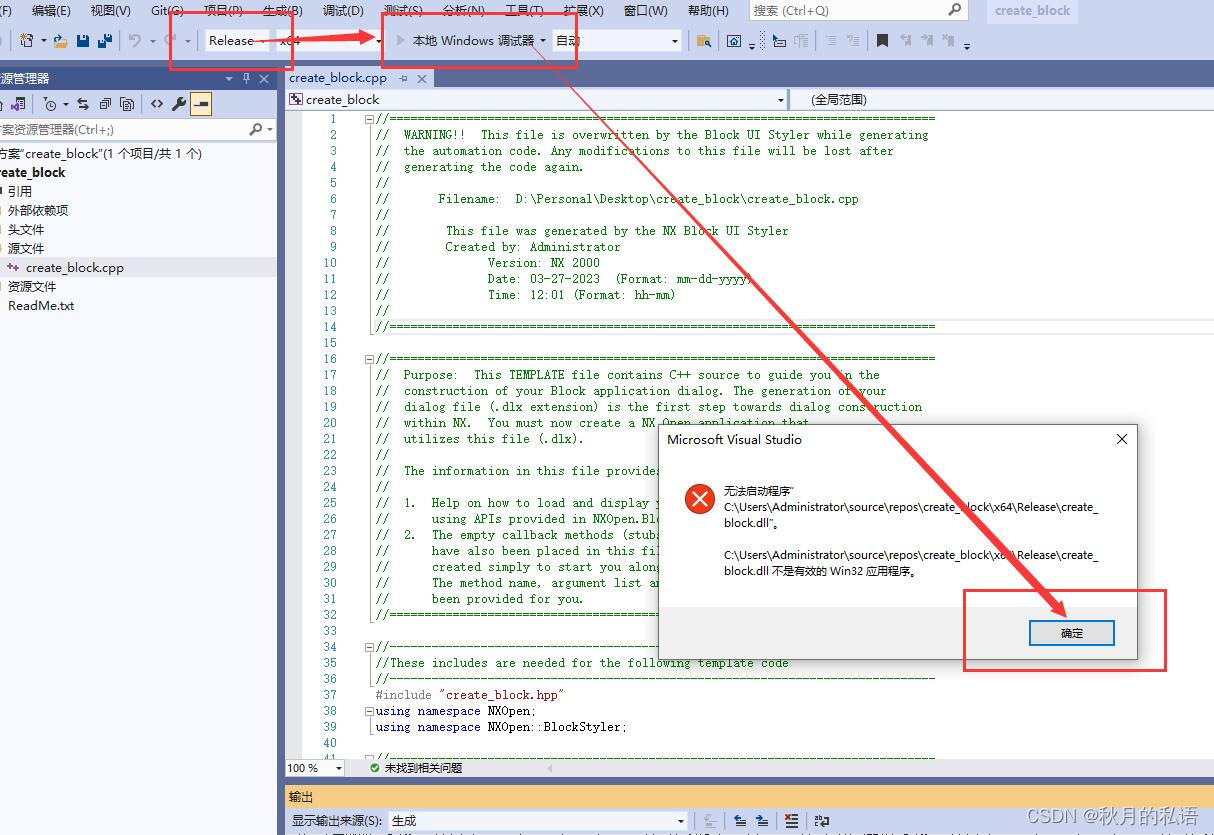
12.将生成的dll文件以及对应的dlx文件拷贝到D:\NXOPEN\application目录。
笔者的这2个文件分别在如下位置:
C:\Users\Administrator\source\repos\create_block\x64\Release\create_block.dll
D:\Personal\Desktop\create_block\create_block.dlx
拷贝完成后,如下图所示:
13.重新打开nx,重复本文的1、2、3步骤,进入模型界面。
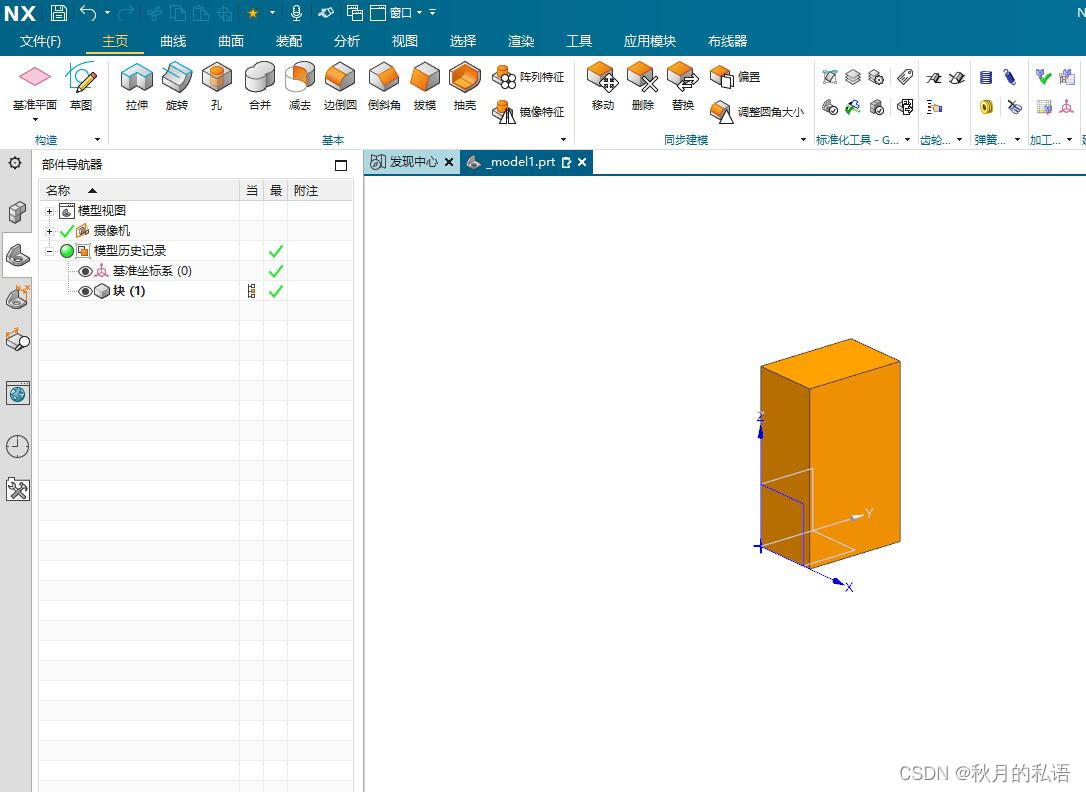
14.点击 文件→执行→NXOpen... (快捷键Ctrl+U),选择D:\NXOPEN\application\create_block.dll文件,成功出现交互界面。

15.点击确定按钮,生成了对应的立方体。
至此,一个基本的二次开发流程全部结束。
欢迎交流与讨论。
在railstutorial中,作者为什么选择使用这个(代码list10.25):http://ruby.railstutorial.org/chapters/updating-showing-and-deleting-usersnamespace:dbdodesc"Filldatabasewithsampledata"task:populate=>:environmentdoRake::Task['db:reset'].invokeUser.create!(:name=>"ExampleUser",:email=>"example@railstutorial.org",:passwo
我有一个数组数组,想将元素附加到子数组。+=做我想做的,但我想了解为什么push不做。我期望的行为(并与+=一起工作):b=Array.new(3,[])b[0]+=["apple"]b[1]+=["orange"]b[2]+=["frog"]b=>[["苹果"],["橙子"],["Frog"]]通过推送,我将推送的元素附加到每个子数组(为什么?):a=Array.new(3,[])a[0].push("apple")a[1].push("orange")a[2].push("frog")a=>[[“苹果”、“橙子”、“Frog”]、[“苹果”、“橙子”、“Frog”]、[“苹果”、“
给定一个元素和一个数组,Ruby#index方法返回元素在数组中的位置。我使用二进制搜索实现了我自己的索引方法,期望我的方法会优于内置方法。令我惊讶的是,内置的在实验中的运行速度大约是我的三倍。有Rubyist知道原因吗? 最佳答案 内置#indexisnotabinarysearch,这只是一个简单的迭代搜索。但是,它是用C而不是Ruby实现的,因此自然可以快几个数量级。 关于Ruby#index方法VS二进制搜索,我们在StackOverflow上找到一个类似的问题:
随着ruby被引入为新的编程救世主,我想知道是否有人基于易用性、运行所需的资源、可用性和易定制性而有偏好。两者有更好的吗? 最佳答案 好吧,任何基于Rails的社交网络应用程序的比较都应该包括insoshi(http://portal.insoshi.com/)。话虽这么说,这三个都非常相似,区别在于实现细节。Lovd和Insoshi都是完整的Rails应用程序;它旨在供您将它们用作入门工具包,并使用您自己的自定义功能对其进行扩展。另一方面,CommunityEngine是一个Rails插件。这意味着您可以更轻松地向现有Rail
我看到有两种写作风格:deffind_nest(animal)returnunlessanimal.bird?GPS.find_nest(animal.do_crazy_stuff)end对比deffind_nest(animal)ifanimal.bird?GPS.find_nest(animal.do_crazy_stuff)endend哪个更正确/更可取/遵循最佳实践?还是无所谓? 最佳答案 根据Rubystyleguide,Preferaguardclausewhenyoucanassertinvaliddata.Aguar
您可能知道,从Rails2.2开始,Rails附带了一个简单的本地化和国际化后端。默认情况下,您可以将需要翻译的字符串存储在config文件夹中的本地化文件中。config/locales/en.ymlconfig/locales/it.yml但是Rails也提供了本地化模板和局部的能力。例如,MainController#index操作可以根据模板文件名和当前区域设置选择本地化模板。apps/views/main/index.it.html.erbapps/views/main/index.en.html.erb当您需要翻译单个字符串或短段落时,第一个功能很有用。当同一Action根
我正在对用户的提要进行分页,并想模拟我正在使用的API的响应。API可以返回奇怪的结果,所以我想确保如果API返回我已经看到的项目,请停止分页。我使用minitest在第一次调用方法get_next_page时stub,但我想在第二次和第三次用不同的值调用它时stub。我应该只使用rSpec吗?ruby新手...这是片段test"crawlerdoesnotpaginateifnonewitemsinnextpage"do#1:A,B#2:B,D=>D#3:A=>stopcrawler=CrawlJob.newfirst_page=[{"id"=>"item-A"},{"id"=>"i
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭9年前。Improvethisquestion我目前正在使用guard来监视我的.coffee和.scss文件的变化并适本地编译它们。现在,gruntjs和yeoman提供了类似的功能。从guard转向gruntjs或yeoman的动机是什么?使用yeoman和gruntjs有什么好处,反之亦然?谢谢!
我读到最新版本的Ruby解释器(YARV)将由于字节码编译而有实质性的性能改进。我的问题是有人试过对JRuby运行这个吗?在Windows上执行时有什么明显的不同吗?此链接有一些很好的指标,但大多数是在Linux上运行的...http://antoniocangiano.com/2007/02/19/ruby-implementations-shootout-ruby-vs-yarv-vs-jruby-vs-gardens-point-ruby-net-vs-rubinius-vs-cardinal/提前致谢!托德 最佳答案 该fi
在联想中,我们通常做a:b(belongs_to:something)。当我们使用符号键创建散列时,我们通常会执行a:b。话虽如此,我的问题是这两种语法之间有什么区别。还有什么逻辑可以记住什么时候使用哪个约定? 最佳答案 这与约定无关,与语法有关。:something是Symbol.belongs_to:something是一种被发送到隐式self的方法,同时也省略了括号。我们可以将其写成如下所示:self.belongs_to(:something):something因此只是传递给方法belongs_to的参数。在Hash中,我