以这种形式给出矩阵的值
| g t c l a s s 1 gt_{class1} gtclass1 | g t c l a s s 2 gt_{class2} gtclass2 | g t c l a s s 3 gt_{class3} gtclass3 | background FP | |
|---|---|---|---|---|
| p r e d c l a s s 1 pred_{class1} predclass1 | ||||
| p r e d c l a s s 2 pred_{class2} predclass2 | ||||
| p r e d c l a s s 3 pred_{class3} predclass3 | ||||
| background FN |
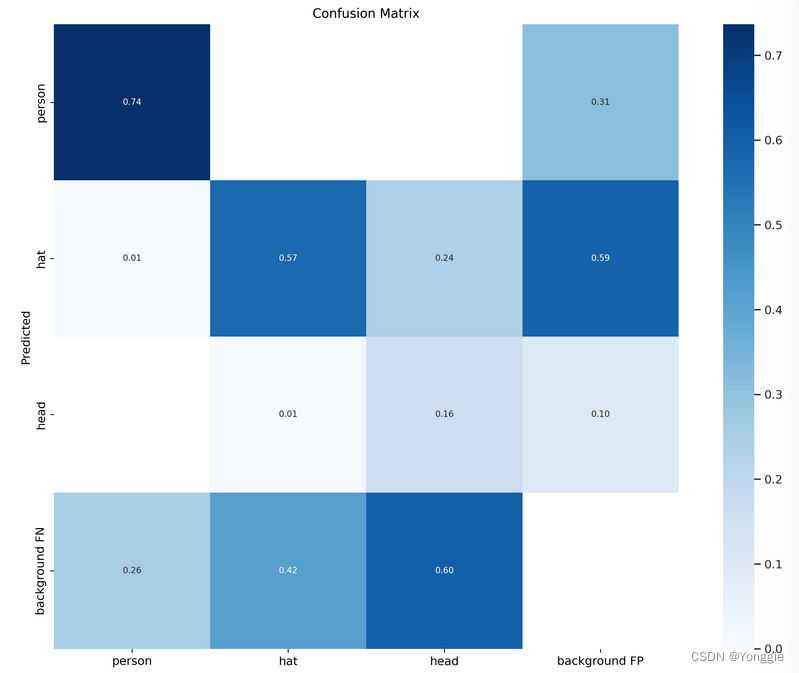 若是分类的完美,则应当只有对角线是高峰,其余都是0(除了最后一行和最后一列).
若是分类的完美,则应当只有对角线是高峰,其余都是0(除了最后一行和最后一列).
根据GitHub上的讨论,background也被列成单独一类,所以也有他的TP、FP、TN、FN等。
最后一列和最后一行都是以background的类别pos的prediction的FN和FP。所以最右下角是没有意义的,没有值。
混淆矩阵最后一行和一列是背景类。上面我们知道列是模型预测的结果,行是标签的真实结果。而FP则是表示真实为假预测为真,FN表示真实为真预测为假。可以看到最后一行即backgroundFN出现数值,表示出现了漏检;最后一列即background FP出现数值,则表示出现了虚检
来自 https://blog.csdn.net/m0_66447617/article/details/124180032,
另外可参考github上的讨论,background也被单独划分成了一个类别。
https://github.com/kaanakan/object_detection_confusion_matrix/issues/12
以上面的图为例子的话,可以看到background FN各类都比较高,虚检了很多物体;background FP- hat的相对较高,漏检了很多head类别的物体。而在非背景的类别中,可以看到对角线的值相对大,可见模型能够很好的分清楚这三类谁是谁。
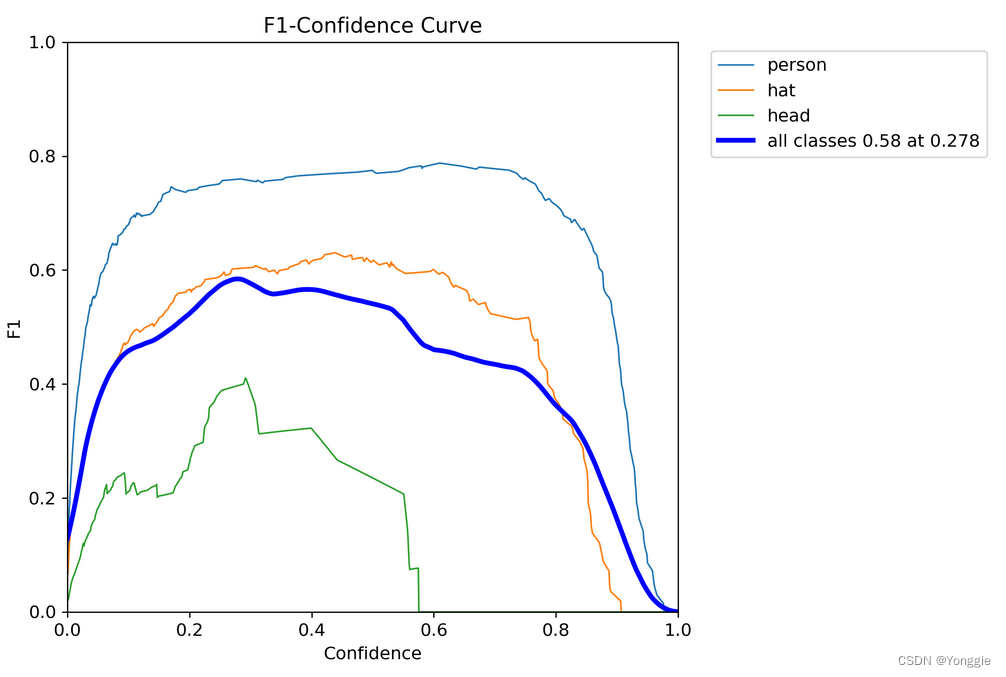 横坐标是置信阈值。
横坐标是置信阈值。
F
1
=
2
∗
1
1
p
r
e
c
i
s
i
o
n
+
1
r
e
c
a
l
l
F1=2*\frac1{\frac1{precision}+\frac1{recall}}
F1=2∗precision1+recall11
此图能够看到什么阈值下什么类别能够达到最好的F1 score,比如绿线在0.27左右,海蓝色在0.8左右。
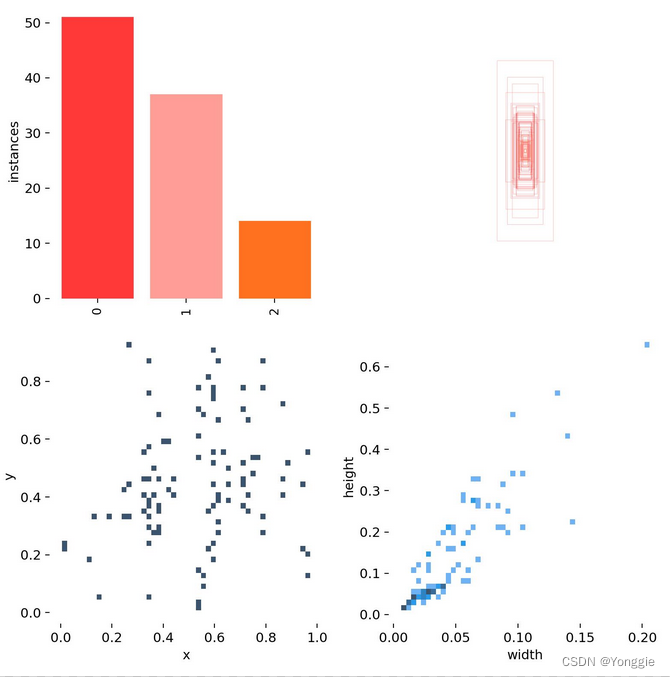
给所提供的label数据进行统计,是4个图,左上是各个物体的数量直方图,右上是中心对齐后各个物体的bounding box,左下角是中心点统计,右下角是方框长、宽统计
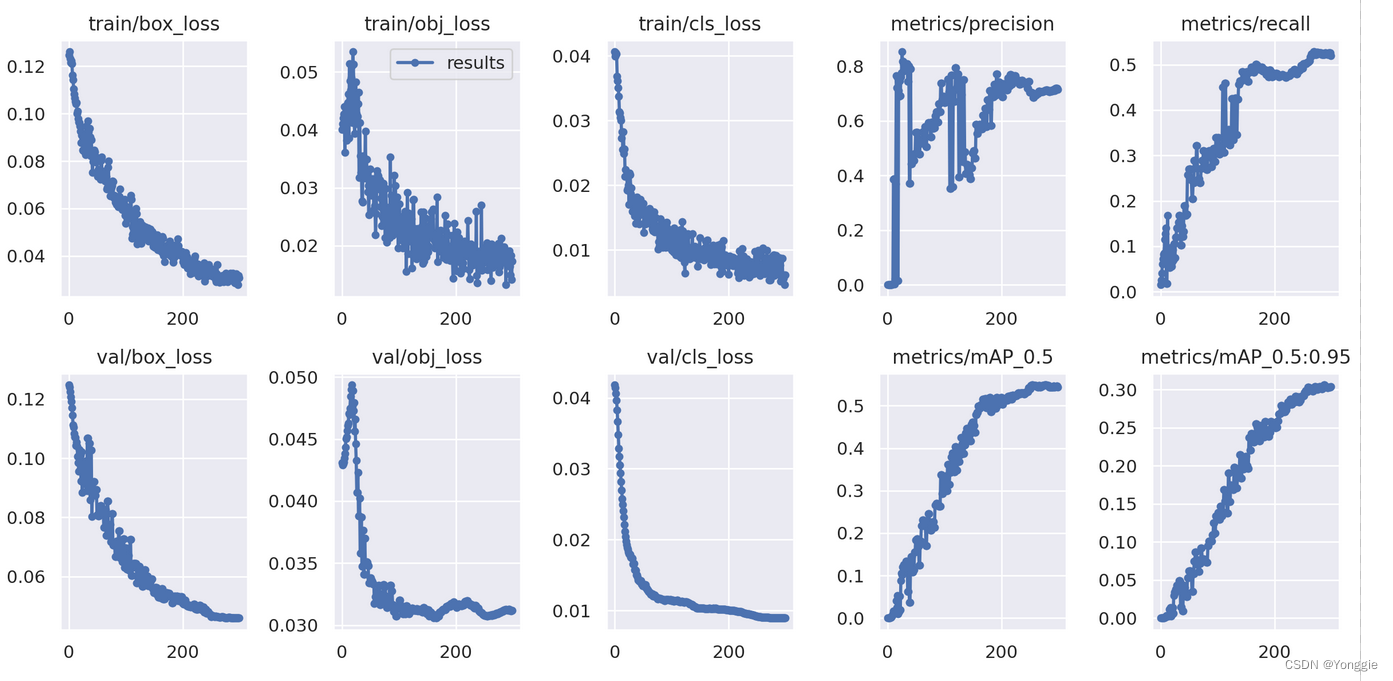 横坐标是epoch,标题比较直观的说了每个图的意思
横坐标是epoch,标题比较直观的说了每个图的意思
P-R curve
P curve
R curve
这些就是抽取个例查看。
我有一个字符串input="maybe(thisis|thatwas)some((nice|ugly)(day|night)|(strange(weather|time)))"Ruby中解析该字符串的最佳方法是什么?我的意思是脚本应该能够像这样构建句子:maybethisissomeuglynightmaybethatwassomenicenightmaybethiswassomestrangetime等等,你明白了......我应该一个字符一个字符地读取字符串并构建一个带有堆栈的状态机来存储括号值以供以后计算,还是有更好的方法?也许为此目的准备了一个开箱即用的库?
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在使用ruby1.9解析以下带有MacRoman字符的csv文件#encoding:ISO-8859-1#csv_parse.csvName,main-dialogue"Marceu","Giveittohimóhe,hiswife."我做了以下解析。require'csv'input_string=File.read("../csv_parse.rb").force_encoding("ISO-8859-1").encode("UTF-8")#=>"Name,main-dialogue\r\n\"Marceu\",\"Giveittohim\x97he,hiswife.\"\
简而言之错误:NOTE:Gem::SourceIndex#add_specisdeprecated,useSpecification.add_spec.Itwillberemovedonorafter2011-11-01.Gem::SourceIndex#add_speccalledfrom/opt/local/lib/ruby/site_ruby/1.8/rubygems/source_index.rb:91./opt/local/lib/ruby/gems/1.8/gems/rails-2.3.8/lib/rails/gem_dependency.rb:275:in`==':und
导读语言模型给我们的生产生活带来了极大便利,但同时不少人也利用他们从事作弊工作。如何规避这些难辨真伪的文字所产生的负面影响也成为一大难题。在3月9日智源Live第33期活动「DetectGPT:判断文本是否为机器生成的工具」中,主讲人Eric为我们讲解了DetectGPT工作背后的思路——一种基于概率曲率检测的用于检测模型生成文本的工具,它可以帮助我们更好地分辨文章的来源和可信度,对保护信息真实、防止欺诈等方面具有重要意义。本次报告主要围绕其功能,实现和效果等展开。(文末点击“阅读原文”,查看活动回放。)Ericmitchell斯坦福大学计算机系四年级博士生,由ChelseaFinn和Chri
我正在使用ruby2.1.0我有一个json文件。例如:test.json{"item":[{"apple":1},{"banana":2}]}用YAML.load加载这个文件安全吗?YAML.load(File.read('test.json'))我正在尝试加载一个json或yaml格式的文件。 最佳答案 YAML可以加载JSONYAML.load('{"something":"test","other":4}')=>{"something"=>"test","other"=>4}JSON将无法加载YAML。JSON.load("
我想用Nokogiri解析HTML页面。页面的一部分有一个表,它没有使用任何特定的ID。是否可以提取如下内容:Today,3,455,34Today,1,1300,3664Today,10,100000,3444,Yesterday,3454,5656,3Yesterday,3545,1000,10Yesterday,3411,36223,15来自这个HTML:TodayYesterdayQntySizeLengthLengthSizeQnty345534345456563113003664354510001010100000344434113622315
我使用的第一个解析器生成器是Parse::RecDescent,它的指南/教程很棒,但它最有用的功能是它的调试工具,特别是tracing功能(通过将$RD_TRACE设置为1来激活)。我正在寻找可以帮助您调试其规则的解析器生成器。问题是,它必须用python或ruby编写,并且具有详细模式/跟踪模式或非常有用的调试技术。有人知道这样的解析器生成器吗?编辑:当我说调试时,我并不是指调试python或ruby。我指的是调试解析器生成器,查看它在每一步都在做什么,查看它正在读取的每个字符,它试图匹配的规则。希望你明白这一点。赏金编辑:要赢得赏金,请展示一个解析器生成器框架,并说明它的
我有这样的HTML代码:Label1Value1Label2Value2...我的代码不起作用。doc.css("first").eachdo|item|label=item.css("dt")value=item.css("dd")end显示所有首先标记,然后标记标签,我需要“标签:值” 最佳答案 首先,您的HTML应该有和中的元素:Label1Value1Label2Value2...但这不会改变您解析它的方式。你想找到s并遍历它们,然后在每个你可以使用next_element得到;像这样:doc=Nokogiri::HTML(
我想禁用HTTP参数的自动XML解析。但我发现命令仅适用于Rails2.x,它们都不适用于3.0:config.action_controller.param_parsers.deleteMime::XML(application.rb)ActionController::Base.param_parsers.deleteMime::XMLRails3.0中的等价物是什么? 最佳答案 根据CVE-2013-0156的最新安全公告你可以将它用于Rails3.0。3.1和3.2ActionDispatch::ParamsParser::