本文以CBAM和SE注意力机制的添加过程为例,主要介绍了向YOLOv5中添加注意力机制的具体步骤
本文在此篇博客的基础上向YOLOv5-5.0版本代码中添加注意力机制
yolov5模型训练———使用yolov5训练自己的数据集
本文主要包括以下内容
YOLOv5加入注意力机制可分为以下三个步骤:
1.common.py中加入注意力模块
2.yolo.py中增加判断条件
3.yaml文件中添加相应模块
1.打开models文件夹中的common.py文件
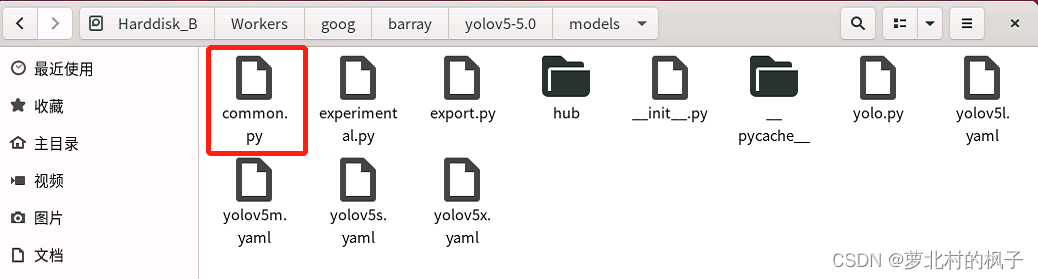
2.将下面的CBAMC3代码复制粘贴到common.py文件中
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.f1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.relu = nn.ReLU()
self.f2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
# 写法二,亦可使用顺序容器
# self.sharedMLP = nn.Sequential(
# nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False), nn.ReLU(),
# nn.Conv2d(in_planes // rotio, in_planes, 1, bias=False))
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.f2(self.relu(self.f1(self.avg_pool(x))))
max_out = self.f2(self.relu(self.f1(self.max_pool(x))))
out = self.sigmoid(avg_out + max_out)
return torch.mul(x, out)
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
out = torch.cat([avg_out, max_out], dim=1)
out = self.sigmoid(self.conv(out))
return torch.mul(x, out)
class CBAMC3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(CBAMC3, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1)
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
self.channel_attention = ChannelAttention(c2, 16)
self.spatial_attention = SpatialAttention(7)
# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
def forward(self, x):
# 将最后的标准卷积模块改为了注意力机制提取特征
return self.spatial_attention(
self.channel_attention(self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))))
如下图所示,本文这里是将其粘贴到了common.py的末尾
(图片长度过长,所以截取了两张,以及记得点击保存)
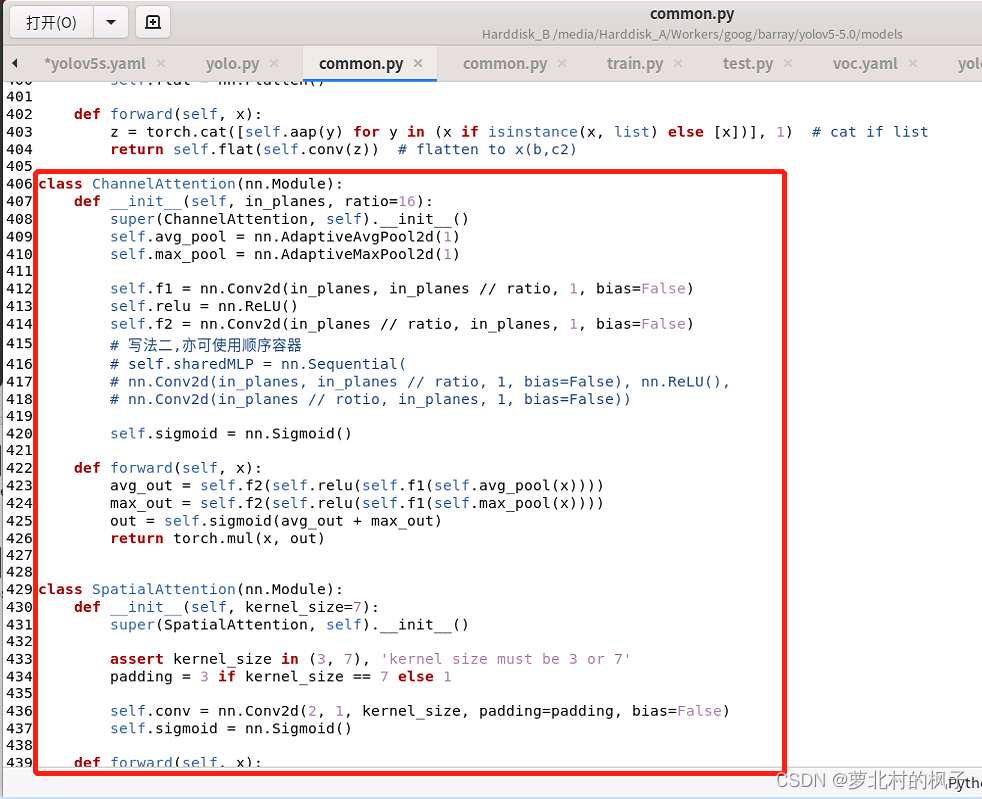
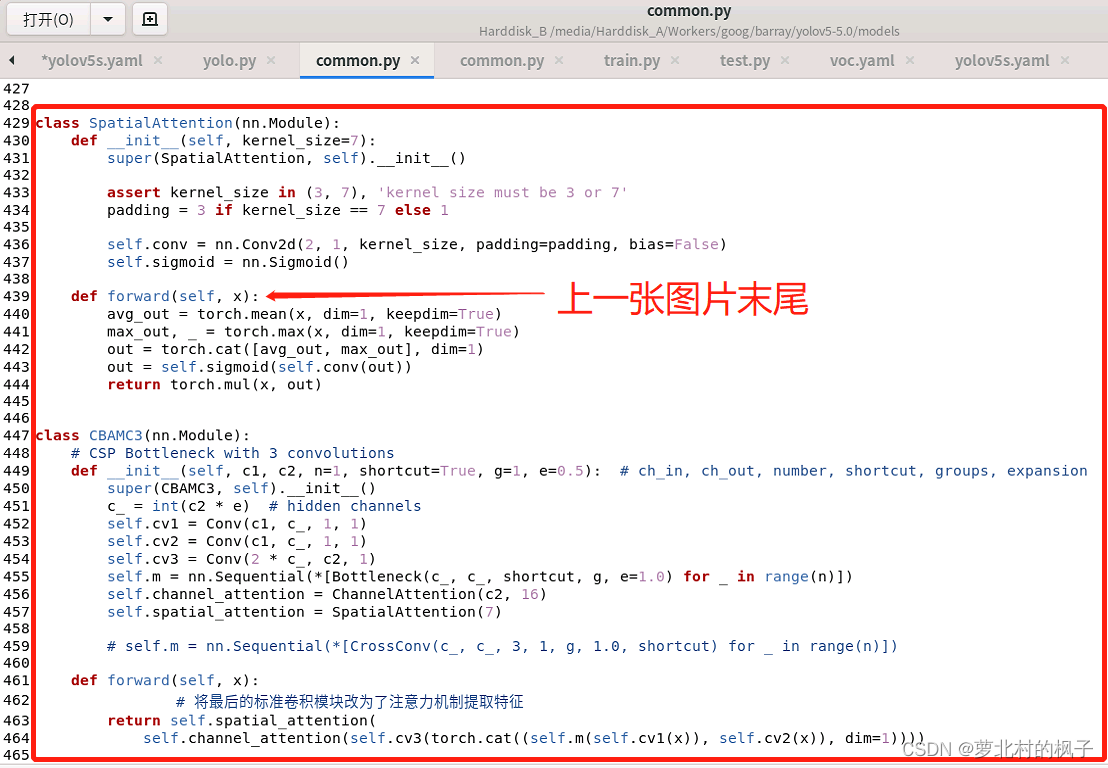
1.打开models文件夹中的yolo.py文件
2.分别在218行和224行添加CBAMC3,如下图所示
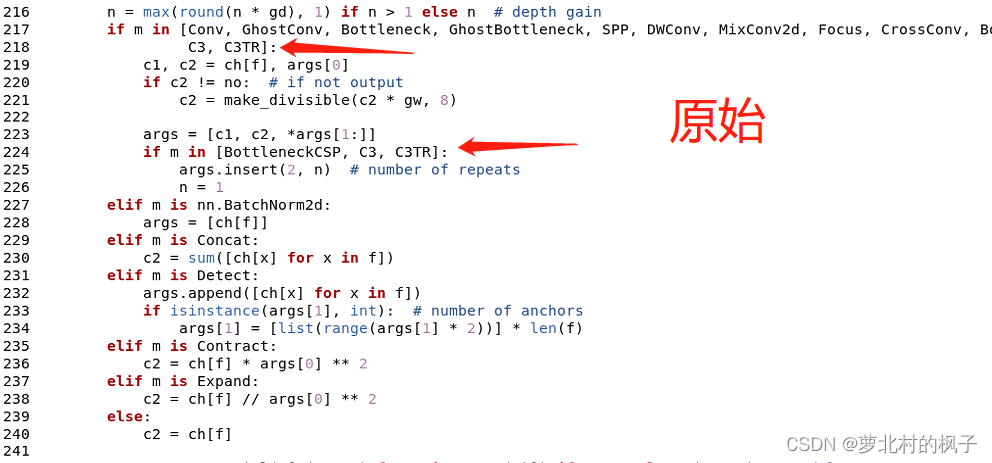
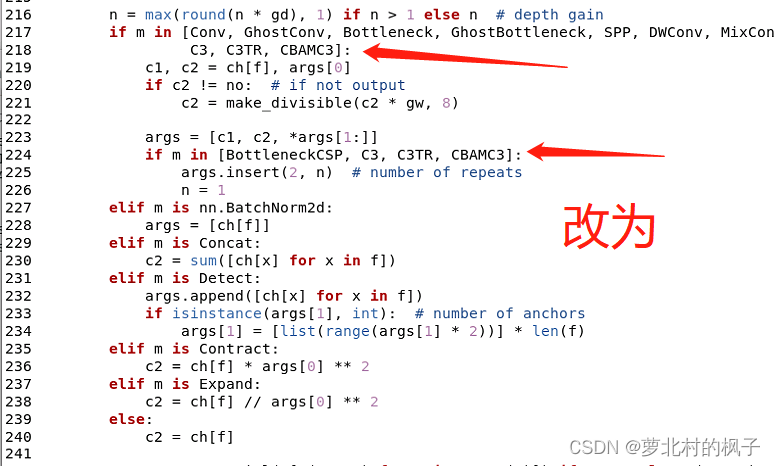
同样改完之后记得点保存
注意力机制可以添加在backbone,Neck,Head等部分,大家可以在yaml文件中修改网络的结构、添加其他模块等等,接下来本文将以向主干网络(backbone)添加CBAM模块为例,本文介绍的只是其中一种添加方式
1.在yolov5-5.0工程文件夹下,找到models文件夹下的yolov5s.yaml文件
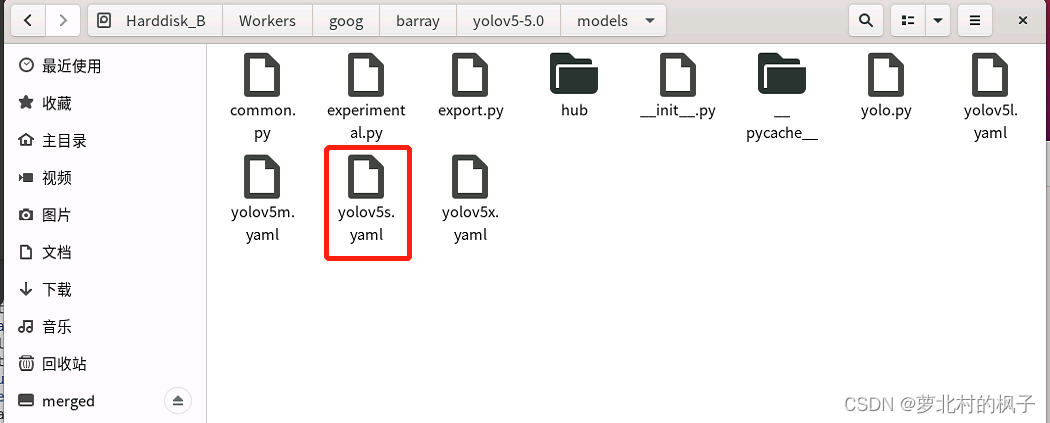
2.backbone主干网络中的4个C3模块改为CBAMC3,如下图所示:


这样我们就在yolov5s主干网络中添加了CBAM注意力机制
(在服务器上跑代码修改后,记得点击文本编辑器右上角的保存)
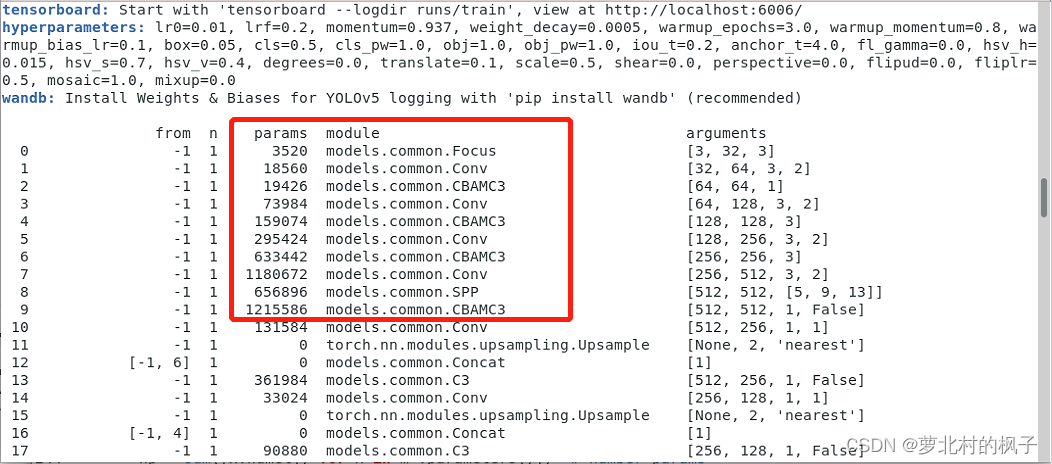
接下来开始训练模型,我们就可以看到CBAMC3模块已经成功添加到主干网络中了
(步骤和CBAM相似)
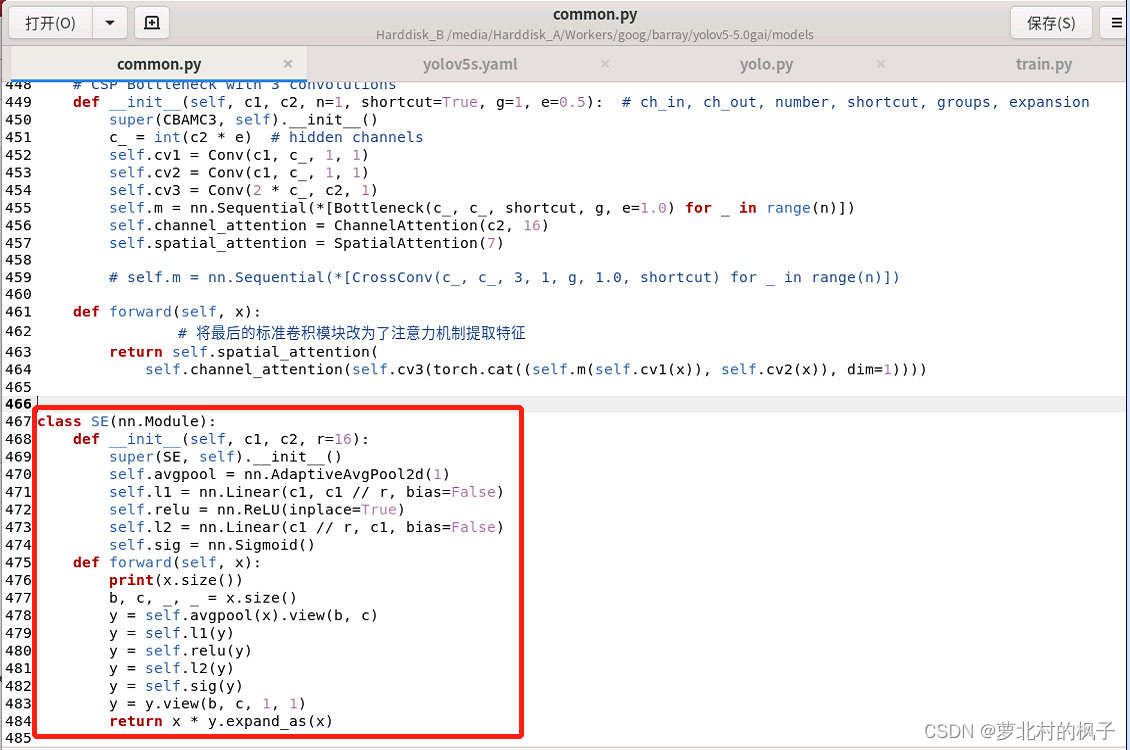
1.打开models文件夹中的common.py文件
2.将下面的SE代码复制粘贴到common.py文件中
class SE(nn.Module):
def __init__(self, c1, c2, r=16):
super(SE, self).__init__()
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.l1 = nn.Linear(c1, c1 // r, bias=False)
self.relu = nn.ReLU(inplace=True)
self.l2 = nn.Linear(c1 // r, c1, bias=False)
self.sig = nn.Sigmoid()
def forward(self, x):
print(x.size())
b, c, _, _ = x.size()
y = self.avgpool(x).view(b, c)
y = self.l1(y)
y = self.relu(y)
y = self.l2(y)
y = self.sig(y)
y = y.view(b, c, 1, 1)
return x * y.expand_as(x)
如下图所示,本文这里是将其粘贴到了common.py的末尾
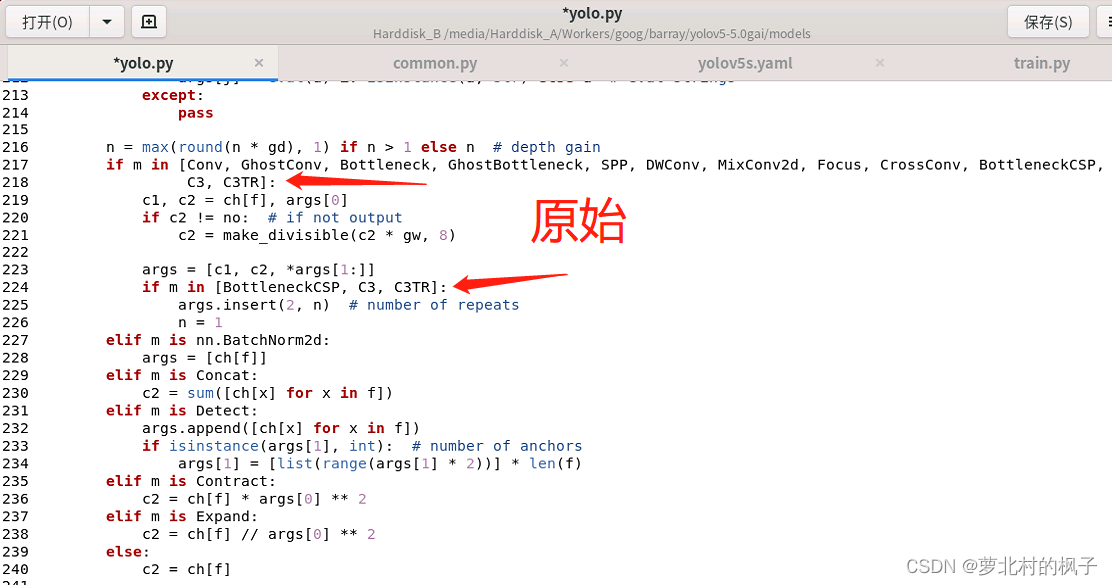
1.打开models文件夹中的yolo.py文件
2.分别在218行和224行添加SE,如下图所示
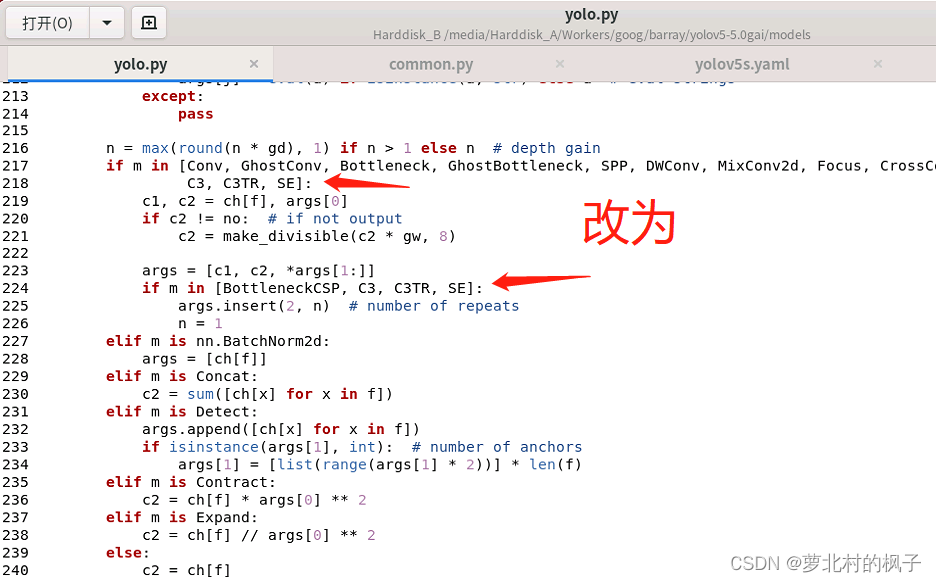
同样改完之后记得点保存
注意力机制可以添加在backbone,Neck,Head等部分,大家可以在yaml文件中修改网络的结构、添加其他模块等等。与CBAM的添加过程一样,接下来本文将以向主干网络(backbone)添加SE模块为例,本文介绍的只是其中一种添加方式
1.在yolov5-5.0工程文件夹下,找到models文件夹下的yolov5s.yaml文件
2.backbone主干网络末尾添加下面的代码,如下图所示:
(注意逗号是英文,以及注意对齐)
[-1, 1, SE, [1024, 4]],

这样我们就在yolov5s主干网络中添加了SE注意力机制
(在服务器上跑代码修改后,记得点击文本编辑器右上角的保存)
接下来开始训练模型,我们就可以看到SE模块已经成功添加到主干网络中了
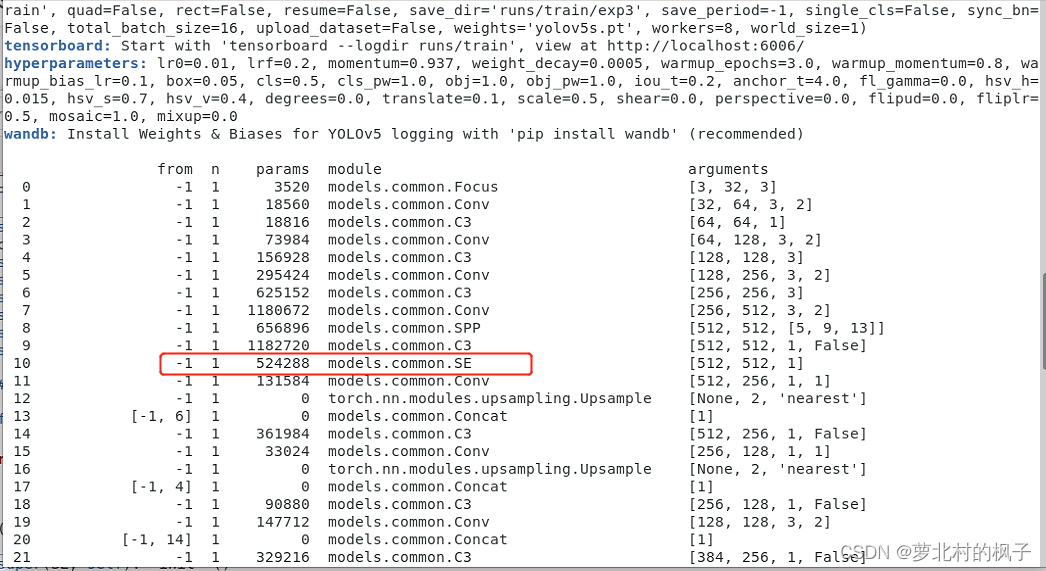
添加过程不再赘述,模仿上方CBAM和SE的添加过程即可
class eca_layer(nn.Module):
"""Constructs a ECA module.
Args:
channel: Number of channels of the input feature map
k_size: Adaptive selection of kernel size
"""
def __init__(self, channel, k_size=3):
super(eca_layer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# feature descriptor on the global spatial information
y = self.avg_pool(x)
# Two different branches of ECA module
y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
# Multi-scale information fusion
y = self.sigmoid(y)
x=x*y.expand_as(x)
return x * y.expand_as(x)
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class CoordAtt(nn.Module):
def __init__(self, inp, oup, reduction=32):
super(CoordAtt, self).__init__()
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
n, c, h, w = x.size()
x_h = self.pool_h(x)
x_w = self.pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
out = identity * a_w * a_h
return out
当我使用Bundler时,是否需要在我的Gemfile中将其列为依赖项?毕竟,我的代码中有些地方需要它。例如,当我进行Bundler设置时:require"bundler/setup" 最佳答案 没有。您可以尝试,但首先您必须用鞋带将自己抬离地面。 关于ruby-我需要将Bundler本身添加到Gemfile中吗?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/4758609/
我有一个ModularSinatra应用程序,我正在尝试将Bootstrap添加到应用程序中。get'/bootstrap/application.css'doless:"bootstrap/bootstrap"end我在views/bootstrap中有所有less文件,包括bootstrap.less。我收到这个错误:Less::ParseErrorat/bootstrap/application.css'reset.less'wasn'tfound.Bootstrap.less的第一行是://CSSReset@import"reset.less";我尝试了所有不同的路径格式,但它
我正在使用Sequel构建一个愿望list系统。我有一个wishlists和itemstable和一个items_wishlists连接表(该名称是续集选择的名称)。items_wishlists表还有一个用于facebookid的额外列(因此我可以存储opengraph操作),这是一个NOTNULL列。我还有Wishlist和Item具有续集many_to_many关联的模型已建立。Wishlist类也有:selectmany_to_many关联的选项设置为select:[:items.*,:items_wishlists__facebook_action_id].有没有一种方法可以
当谈到运行时自省(introspection)和动态代码生成时,我认为ruby没有任何竞争对手,可能除了一些lisp方言。前几天,我正在做一些代码练习来探索ruby的动态功能,我开始想知道如何向现有对象添加方法。以下是我能想到的3种方法:obj=Object.new#addamethoddirectlydefobj.new_method...end#addamethodindirectlywiththesingletonclassclass这只是冰山一角,因为我还没有探索instance_eval、module_eval和define_method的各种组合。是否有在线/离线资
我注意到类定义,如果我打开classMyClass,并在不覆盖的情况下添加一些东西我仍然得到了之前定义的原始方法。添加的新语句扩充了现有语句。但是对于方法定义,我仍然想要与类定义相同的行为,但是当我打开defmy_method时似乎,def中的现有语句和end被覆盖了,我需要重写一遍。那么有什么方法可以使方法定义的行为与定义相同,类似于super,但不一定是子类? 最佳答案 我想您正在寻找alias_method:classAalias_method:old_func,:funcdeffuncold_func#similartoca
我有带有Logo图像的公司模型has_attached_file:logo我用他们的Logo创建了许多公司。现在,我需要添加新样式has_attached_file:logo,:styles=>{:small=>"30x15>",:medium=>"155x85>"}我是否应该重新上传所有旧数据以重新生成新样式?我不这么认为……或者有什么rake任务可以重新生成样式吗? 最佳答案 参见Thumbnail-Generation.如果rake任务不适合你,你应该能够在控制台中使用一个片段来调用重新处理!关于相关公司
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_
作为新的阿里云用户,您可以50免费试用多种优惠,价值高达1,700美元(或8,500美元)。这将让您了解和体验阿里云平台上提供的一系列产品和服务。如果您以个人身份注册免费试用,您将获得价值1,700美元的优惠。但是,如果您是注册公司,您可以选择企业免费试用,提交基本信息通过企业实名注册验证,即可开始价值$8,500的免费试用!本教程介绍了如何设置您的帐户并使用您的免费试用版。关于免费试用在我们开始此试用之前,您还必须遵守以下条款和条件才能访问您的免费试用:只有在一年内创建的账户才有资格获得阿里云免费试用。通过此免费试用优惠,用户可以免费试用免费试用活动页面上列出的每种产品一次。如果您有多个帐
我正在开发一个创建网络博客的RubyonRails项目。我希望将一个名为featured的boolean数据库字段添加到Post模型中。该字段应该可以通过我添加的事件管理界面进行编辑。我使用了以下代码,但我什至没有在网站上显示另一列。$railsgeneratemigrationaddFeaturedfeatured:boolean$rakedb:migrate我是RubyonRails的新手,非常感谢任何帮助。我的index.html.erb文件中的相关代码(views):FeaturedPost架构.rb:ActiveRecord::Schema.define(:version=>
假设我有一个这样的单例类:classSettingsincludeSingletondeftimeout#lazy-loadtimeoutfromconfigfile,orwhateverendend现在,如果我想知道使用什么超时,我需要编写如下内容:Settings.instance.timeout但我宁愿将其缩短为Settings.timeout使这项工作有效的一个明显方法是将设置的实现修改为:classSettingsincludeSingletondefself.timeoutinstance.timeoutenddeftimeout#lazy-loadtimeoutfromc