Requests模块get请求与实战
前言: 前两章我们介绍了爬虫和HTML的组成,方便我们后续爬虫学习,今天就教大家怎么去爬取一个网站的源代码(后面学习中就能从源码中找到我们想要的数据)。
📝📝此专栏文章是专门针对Python零基础爬虫,欢迎免费订阅!
📝📝第一篇文章获得全站热搜第一,python领域热搜第一,欢迎阅读!
🎈🎈欢迎大家一起学习,一起成长!!
urllib模块:
urllib是python的内置HTTP请求库,包含4个模块
request: http的请求模块,传入UPL及额外的参数,就模拟发送请求
error 异常处理模块,确保程序不会意外终止
parse : 一个工具模块,提供了许多URL处理方法。
robotparser : 用来识别robots.txt文件,判断那些网站可以爬
pycharm外部库的urilib下:
requests是一个Python第三方库,用于发送HTTP请求。它提供了一种简单而优雅的方式来发送HTTP/1.1请求,并且可以自动处理连接池和重定向等问题。requests库可以在Python 2.7和Python 3中使用,支持HTTP和HTTPS请求,支持Cookie、代理、SSL证书验证等功能。
使用requests库可以方便地发送GET、POST、PUT、DELETE等请求,并且支持上传文件和发送JSON数据等操作。通过requests库,我们可以轻松地与Web服务进行交互,获取数据或提交数据。requests库已经成为Python中最常用的HTTP客户端库之一,被广泛应用于Web开发、数据分析、爬虫等领域。
安装requests库:
点击终端,输入pip install requests
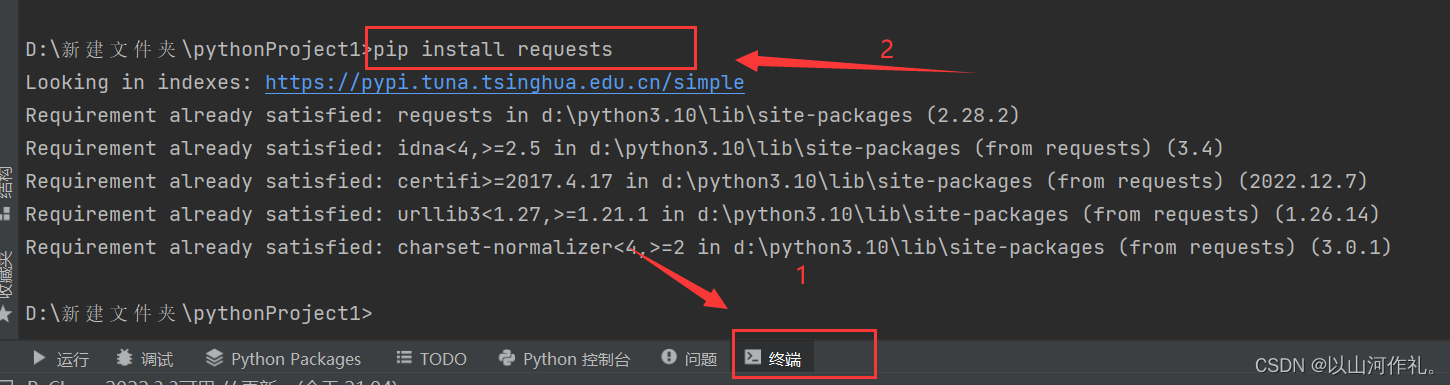
上面这就表示安装成功。
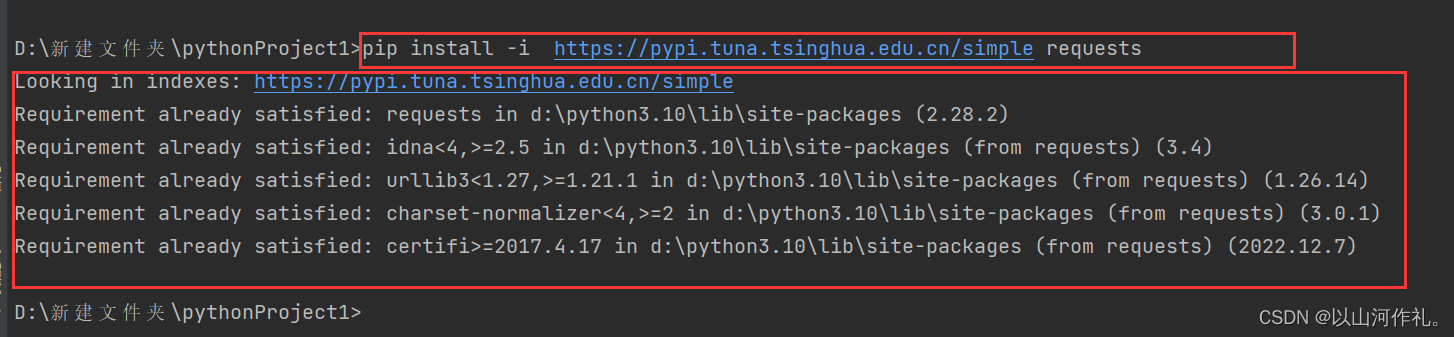
然后接下来安装requests镜像源:
如图所示,在终端输入代码,出现下面情况就代表安装完成。
检查数据是否在链接里
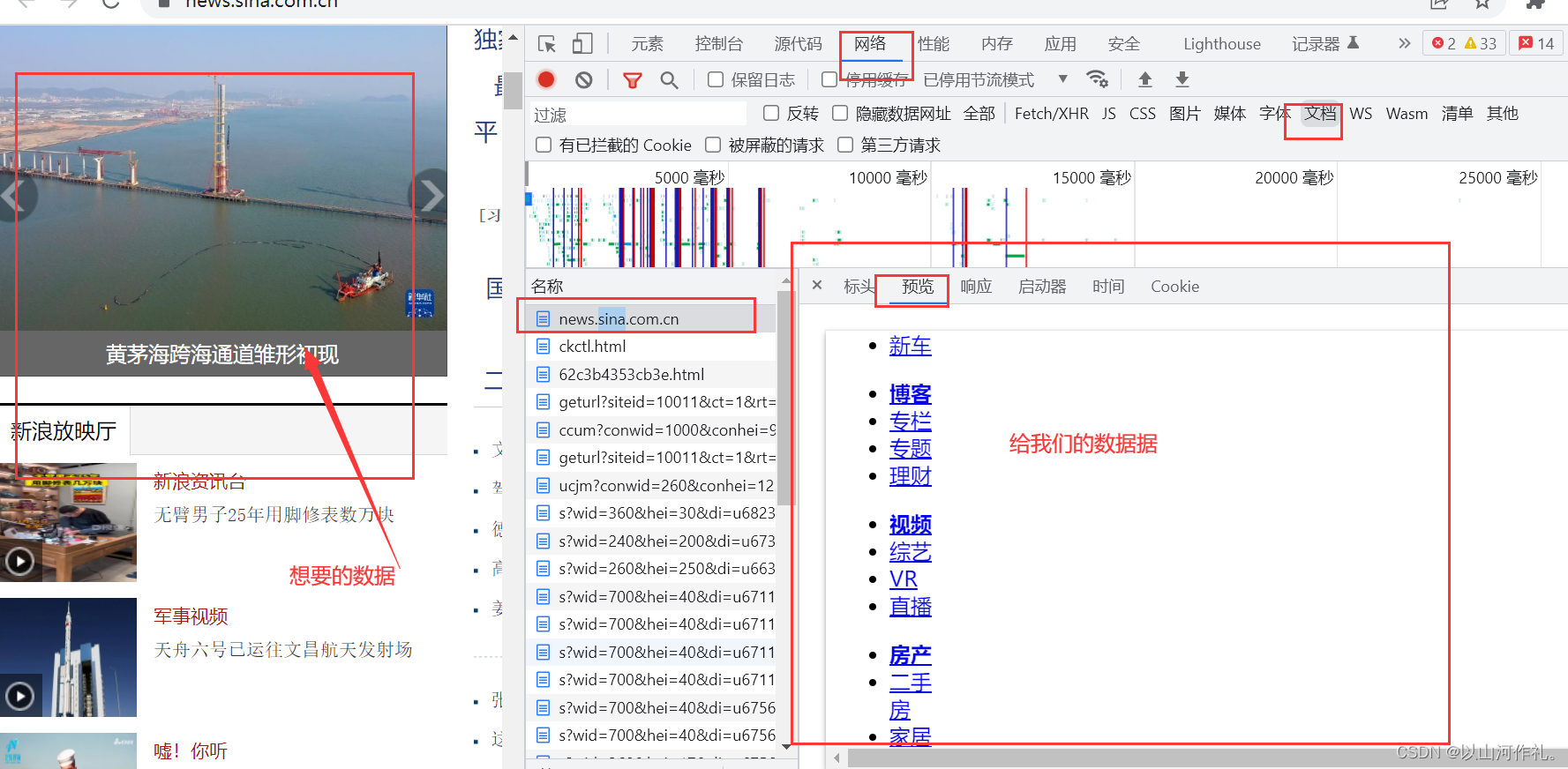
1.数据不在链接中:
打开网页,右键点击检查,然后点击网络,刷新,接着选择第一个文档,点击预览,这个时候我们发现,左边的照片或者其他信息不在预览里面,这个时候我们就无法获得想要的数据了。这种数据就属于客户端渲染,
2.数据在链接中:
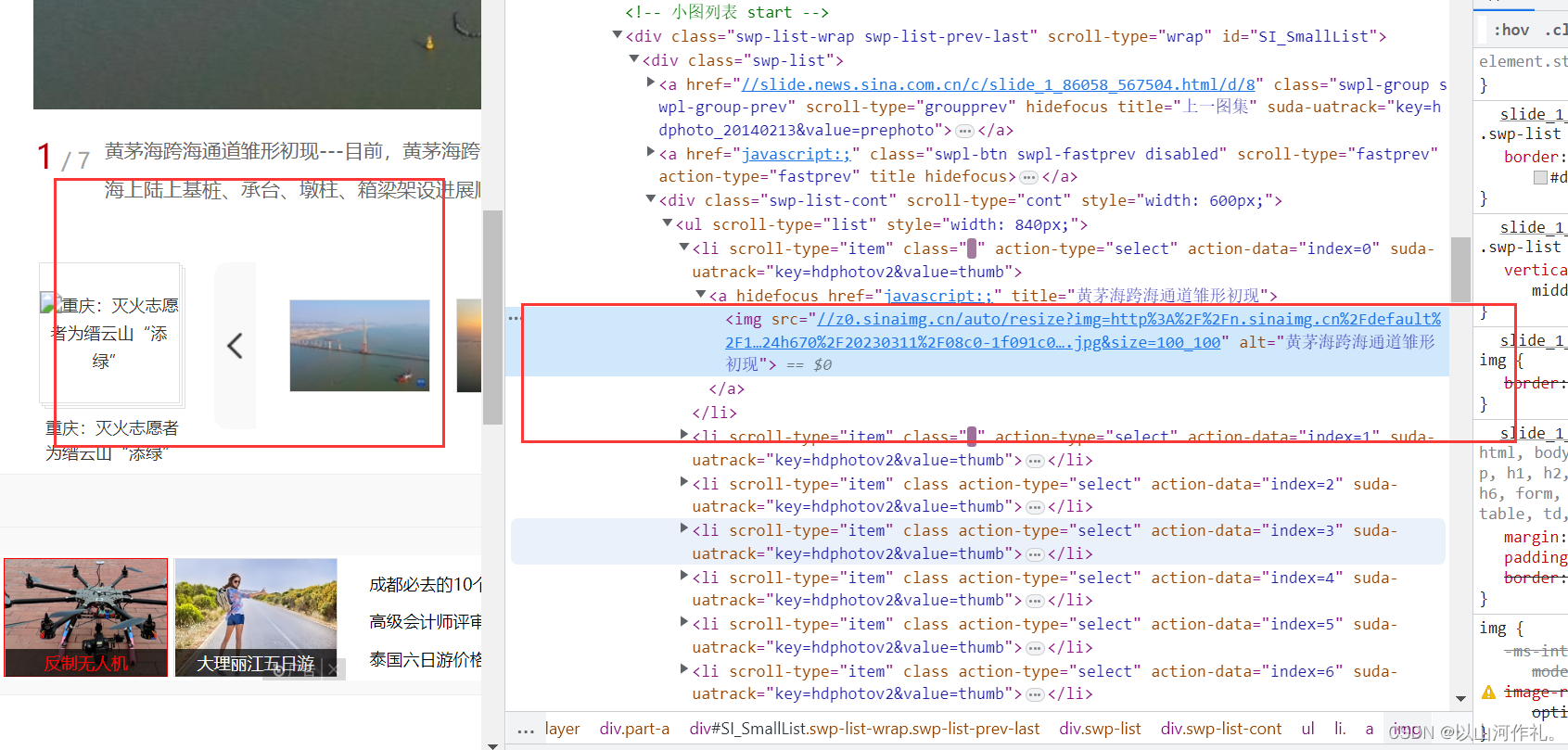
打开网页,点击右键,点击检查,然后点击左上角的小箭头,移动到左边我们需要的数据上面,如果右边代码中出现相应的代码,就说明数据就在代码中,接着我们就开始后面的操作,方便获取我们需要的数据。
浏览器页面的网址一定是qet请求
举个栗子:(如何查看请求头,请求体,以及响应体,在第二节里面有详细介绍,此处以及后面就不在过多介绍,以免让文章太繁琐)
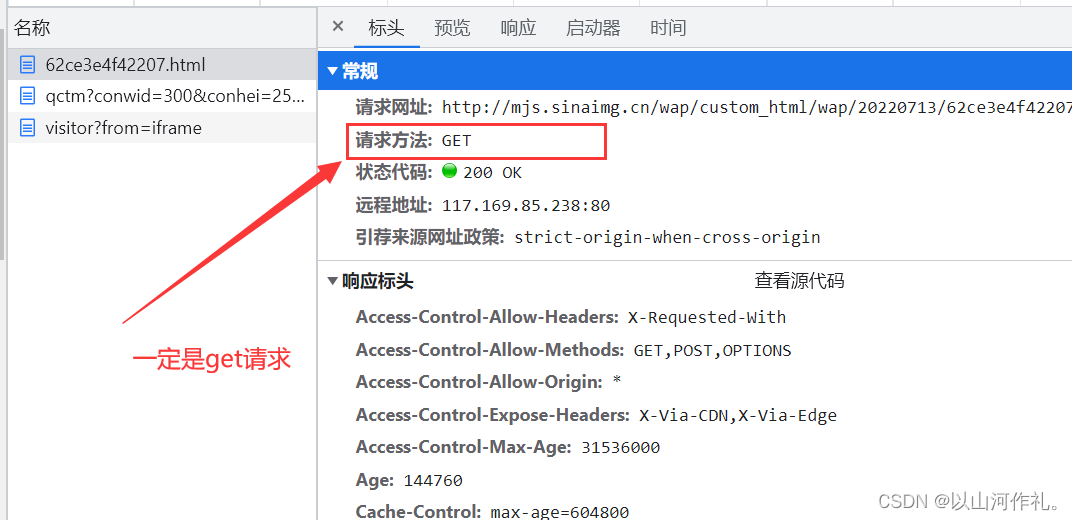
现在我们知道数据在链接中,我们就要通过链接去获取他:
import requests
url = 'http://slide.news.sina.com.cn' # 我们需要数据的链接(就是我们需要爬取的链接,因为数据就在链接里面)
# 确认请求,get请求
html = requests.get(url)
print(html.text) # 打印网页源代码
print(html.status_code) # 状态码
if html.status_code == 200:
print('数据访问成功')
else:
print('请求失败了')
这段代码使用了Python第三方库requests,发送了一个HTTP GET请求,并获取了HTTP响应的正文和状态码,并根据状态码判断请求是否成功。其中,url是一个字符串类型的参数,表示要发送HTTP请求的URL地址。
使用requests.get()函数发送HTTP GET请求,并将HTTP响应对象赋值给变量html。
使用text属性获取HTTP响应正文,并将其打印出来。此外,使用status_code属性获取HTTP响应状态码,并将其打印出来。
根据HTTP响应状态码判断请求是否成功,如果状态码为200,则表示请求成功,否则表示请求失败。(状态码详情可查阅第二节,html页面组成)
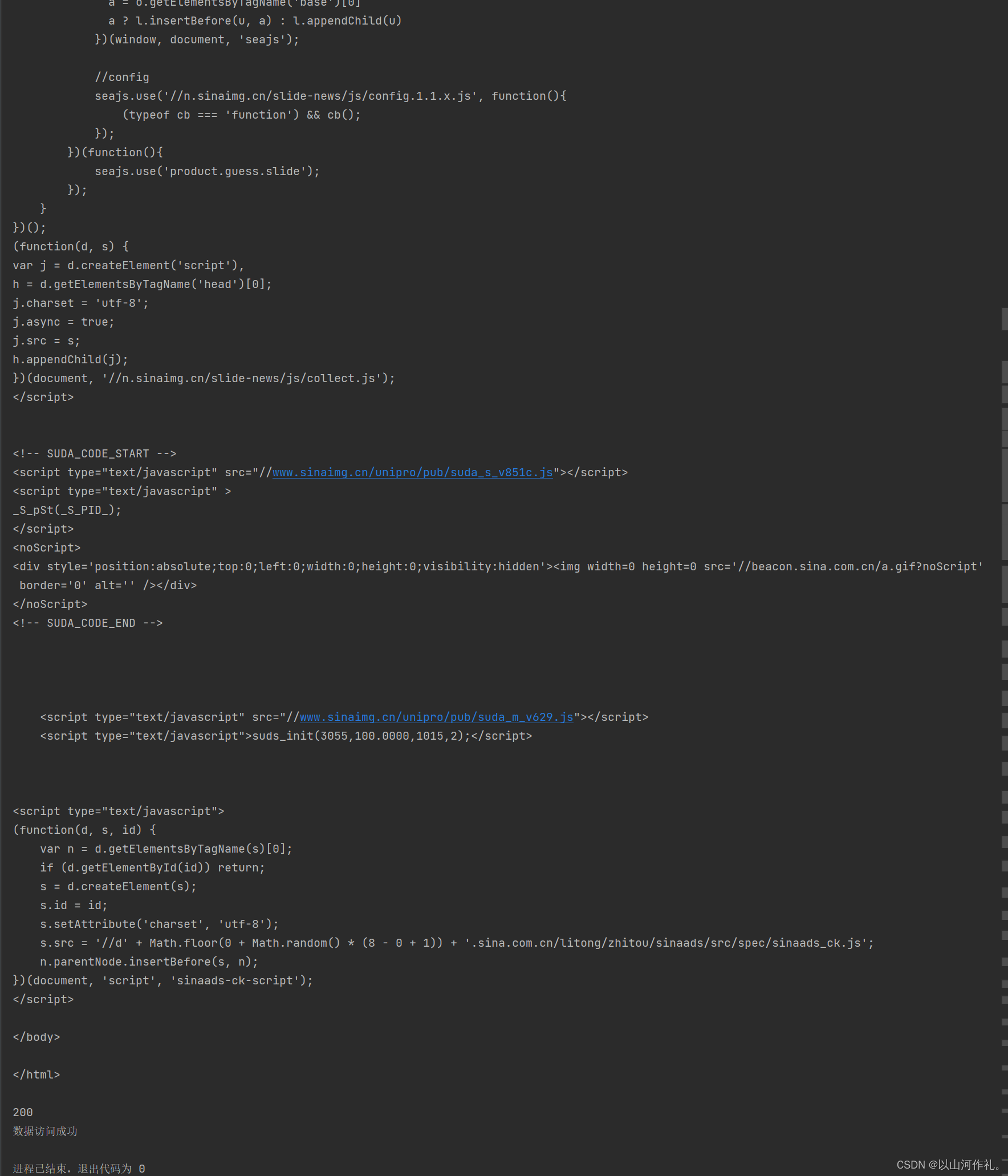
import requests
url = 'http://slide.news.sina.com.cn' # 我们需要数据的链接(就是我们需要爬取的链接,因为数据就在链接里面)
# 确认请求,get请求
html = requests.get(url)
print(html.text) # 打印网页源代码
print(html.status_code) # 状态码
if html.status_code == 200:
print('数据访问成功')
else:
print('请求失败了')
print(html.url) # 访问的网址
print(html.request.headers) # 输出请求头信息
使用url属性获取HTTP请求的URL地址,并将其打印出来。
然后,使用request.headers属性获取HTTP请求的请求头信息,并将其打印出来。request属性是HTTP响应对象的一个属性,表示该HTTP响应对象对应的HTTP请求对象。因此,html.request.headers表示HTTP请求的请求头信息。

在网页源代码中也能查看请求头,但是没有代码运行来的方便快捷。
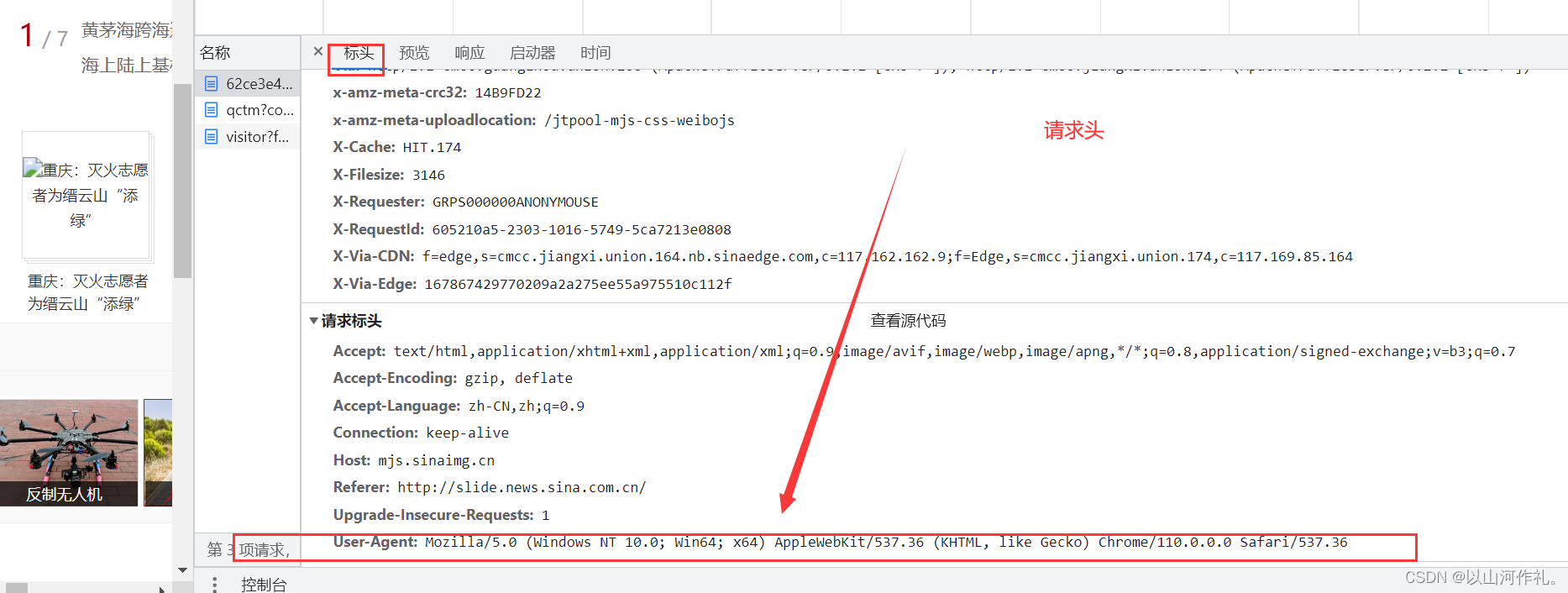
请求头的作用
请求头是HTTP协议中的一个重要部分,它包含了HTTP请求的一些元信息,比如请求方法、请求地址、协议版本、请求头、请求体等。请求头可以帮助服务器理解客户端发送的HTTP请求,以便正确处理HTTP请求。
请求头的作用主要有以下几点:
指定请求方法和请求地址:请求头中包含了HTTP请求的方法(GET、POST、PUT、DELETE等)和请求地址,告诉服务器要执行哪种操作。
指定请求体和请求参数:请求头中还可以包含请求体和请求参数,用于向服务器传递数据。
指定请求头信息:请求头中还包含了一些元信息,比如用户代理、Cookie、Referer等,用于告诉服务器一些附加信息,以便服务器做出更好的响应。
安全性:请求头中可以包含一些安全相关的信息,比如身份验证、防止跨站点请求伪造(CSRF)等。
请求头对爬虫来说,就好像一个面具,去模仿人去浏览网站,就不会被网站发现,也可以理解为打开网站的钥匙,上面我们知道,数据在链接中,但是我们申请后,返回状态码是418,请求失败,所有我们现在戴上面具,或者说,拿着钥匙再去申请,看看能不能成功打开。
import requests
import chardet
url = 'http://slide.news.sina.com.cn/c/slide_1_86058_567500.html#p=1'
headers = {
'User-Agent': 'python-requests/2.28.2',
'Accept-Encoding': 'gzip, deflate',
'Accept': '*/*',
'Connection': 'keep-alive'
}
html = requests.get(url, headers=headers).content
encoding = chardet.detect(html)['encoding']
html = html.decode(encoding)
# 将网页内容写入文件中
with open('example.html', 'w', encoding='utf-8') as f:
f.write(html)
现在就好比我们成功的进入到别人家里面,然后我们将要拿数据,现在先看一下代码里面的东西。
运行成功后,我们大概看一下,数据较多,不做过多展示,截取部分内容:
接着我们在里搜索我们想要的数据,例如:
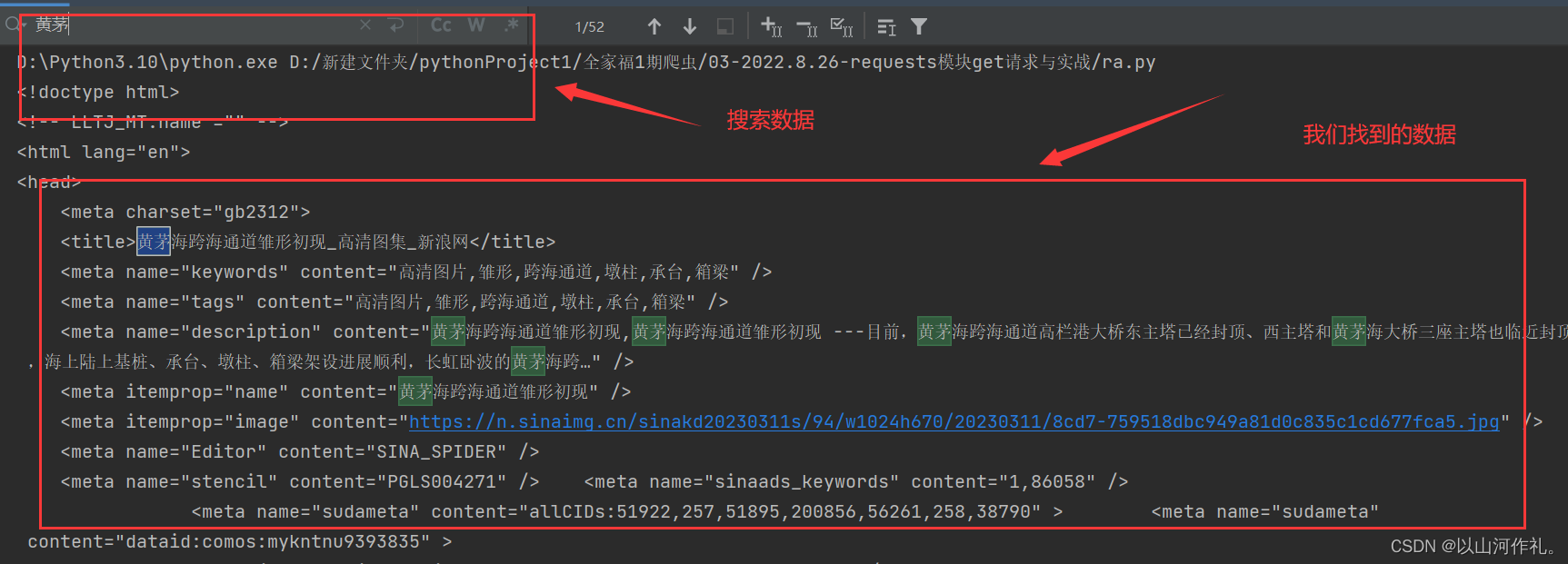
红色方框里面就是我们需要的东西,我们可以点击查看一下:

现在我们找到了我们需要的数据,因为我们还没有学会数据解析,暂时不能提取,无法精确的获取想要的东西,今天就不在这里讲解,后面章节会讲怎么精确的拿取我们想要的数据
输入文件保存的代码:
import requests
import chardet
url = 'http://slide.news.sina.com.cn/c/slide_1_86058_567500.html#p=1'
headers = {
'User-Agent': 'python-requests/2.28.2',
'Accept-Encoding': 'gzip, deflate',
'Accept': '*/*',
'Connection': 'keep-alive'
}
html = requests.get(url, headers=headers).content
encoding = chardet.detect(html)['encoding']
html = html.decode(encoding)
print(html)
# 将网页内容写入文件中
with open('example.html', 'w', encoding='utf-8') as f:
f.write(html)
这段代码可以将
html变量中的网页内容写入到名为example.html的文件中。具体来说,open()函数用于打开文件,'w'参数表示以写入模式打开文件,encoding='utf-8'参数表示指定编码格式为 UTF-8。然后使用write()方法将网页内容写入文件中。with语句用于自动关闭文件。
需要注意的是,如果该文件不存在,则会自动创建该文件;如果该文件已经存在,则会覆盖原文件中的内容。如果要在已经存在的文件中追加内容,可以将
'w'参数改为'a'。
我们的文件就会保存到文件中(仅展示部分代码):

今天知识分享就到此结束,欲知后续如何,请听下回分析。

悲索之人烈焰加身,堕落者不可饶恕。永恒燃烧的羽翼,带我脱离凡间的沉沦。
假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
我正在尝试设置一个puppet节点,但rubygems似乎不正常。如果我通过它自己的二进制文件(/usr/lib/ruby/gems/1.8/gems/facter-1.5.8/bin/facter)在cli上运行facter,它工作正常,但如果我通过由rubygems(/usr/bin/facter)安装的二进制文件,它抛出:/usr/lib/ruby/1.8/facter/uptime.rb:11:undefinedmethod`get_uptime'forFacter::Util::Uptime:Module(NoMethodError)from/usr/lib/ruby
我有一个包含模块的模型。我想在模块中覆盖模型的访问器方法。例如:classBlah这显然行不通。有什么想法可以实现吗? 最佳答案 您的代码看起来是正确的。我们正在毫无困难地使用这个确切的模式。如果我没记错的话,Rails使用#method_missing作为属性setter,因此您的模块将优先,阻止ActiveRecord的setter。如果您正在使用ActiveSupport::Concern(参见thisblogpost),那么您的实例方法需要进入一个特殊的模块:classBlah
在我的Controller中,我通过以下方式在我的index方法中支持HTML和JSON:respond_todo|format|format.htmlformat.json{renderjson:@user}end在浏览器中拉起它时,它会自然地以HTML呈现。但是,当我对/user资源进行内容类型为application/json的curl调用时(因为它是索引方法),我仍然将HTML作为响应。如何获取JSON作为响应?我还需要说明什么? 最佳答案 您应该将.json附加到请求的url,提供的格式在routes.rb的路径中定义。这
我刚刚被困在这个问题上一段时间了。以这个基地为例:moduleTopclassTestendmoduleFooendend稍后,我可以通过这样做在Foo中定义扩展Test的类:moduleTopmoduleFooclassSomeTest但是,如果我尝试通过使用::指定模块来最小化缩进:moduleTop::FooclassFailure这失败了:NameError:uninitializedconstantTop::Foo::Test这是一个错误,还是仅仅是Ruby解析变量名的方式的逻辑结果? 最佳答案 Isthisabug,or
我想获取模块中定义的所有常量的值:moduleLettersA='apple'.freezeB='boy'.freezeendconstants给了我常量的名字:Letters.constants(false)#=>[:A,:B]如何获取它们的值的数组,即["apple","boy"]? 最佳答案 为了做到这一点,请使用mapLetters.constants(false).map&Letters.method(:const_get)这将返回["a","b"]第二种方式:Letters.constants(false).map{|c
我的假设是moduleAmoduleBendend和moduleA::Bend是一样的。我能够从thisblog找到解决方案,thisSOthread和andthisSOthread.为什么以及什么时候应该更喜欢紧凑语法A::B而不是另一个,因为它显然有一个缺点?我有一种直觉,它可能与性能有关,因为在更多命名空间中查找常量需要更多计算。但是我无法通过对普通类进行基准测试来验证这一点。 最佳答案 这两种写作方法经常被混淆。首先要说的是,据我所知,没有可衡量的性能差异。(在下面的书面示例中不断查找)最明显的区别,可能也是最著名的,是你的
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
rails中是否有任何规定允许站点的所有AJAXPOST请求在没有authenticity_token的情况下通过?我有一个调用Controller方法的JqueryPOSTajax调用,但我没有在其中放置任何真实性代码,但调用成功。我的ApplicationController确实有'request_forgery_protection'并且我已经改变了config.action_controller.consider_all_requests_local在我的environments/development.rb中为false我还搜索了我的代码以确保我没有重载ajaxSend来发送

