GWR本质上是一种局部加权回归模型,GWR根据每个空间对象的周围信息,逐个对象建立起回归方程,即每个对象都有自己的回归方程,可用于归因或者对未来的预测。GWR最大的优势是考虑了空间对象的局部效应
本实验基于GWR官网提供的Georgia数据,美国佐治亚州受教育程度及各因素的空间差异性进行分析
数据下载地址: https://sgsup.asu.edu/sparc/mgwr
author:jiangroubao
date:2021-5-21
import numpy as np
import libpysal as ps
from mgwr.gwr import GWR, MGWR
from mgwr.sel_bw import Sel_BW
import geopandas as gp
import matplotlib.pyplot as plt
import matplotlib as mpl
import pandas as pd
data_dir="/home/lighthouse/Learning/pysal/data/"
georgia_data = pd.read_csv(data_dir+"GData_utm.csv")
georgia_shp = gp.read_file(data_dir+'G_utm.shp')
数据共有13个字段,其含义分别是:
georgia_data.head()
ax = georgia_shp.plot(edgecolor='white',column="AreaKey",cmap='GnBu',figsize=(6,6))
georgia_shp.centroid.plot(ax=ax, color='r',marker='o')
ax.set_axis_off()
# 因变量
g_y = georgia_data['PctBach'].values.reshape((-1,1))
# 自变量
g_X = georgia_data[['TotPop90','PctRural','PctEld','PctFB','PctPov','PctBlack']].values
# 坐标信息Latitude Longitud
u = georgia_data['Longitud']
v = georgia_data['Latitude']
g_coords = list(zip(u,v))
# z标准化
# g_X = (g_X - g_X.mean(axis=0)) / g_X.std(axis=0)
# g_y = g_y.reshape((-1,1))
# g_y = (g_y - g_y.mean(axis=0)) / g_y.std(axis=0)
# 带宽选择函数
gwr_selector = Sel_BW(g_coords, g_y, g_X)
gwr_bw = gwr_selector.search(search_method='golden_section',criterion='AICc')
print('最佳带宽大小为:',gwr_bw)
最佳带宽大小为: 151.0
# GWR拟合
gwr_results = GWR(g_coords, g_y, g_X, gwr_bw, fixed=False, kernel='bisquare', constant=True, spherical=True).fit()
gwr_results.summary()
===========================================================================
Model type Gaussian
Number of observations: 159
Number of covariates: 7
Global Regression Results
---------------------------------------------------------------------------
Residual sum of squares: 1816.164
Log-likelihood: -419.240
AIC: 852.479
AICc: 855.439
BIC: 1045.690
R2: 0.646
Adj. R2: 0.632
Variable Est. SE t(Est/SE) p-value
------------------------------- ---------- ---------- ---------- ----------
X0 14.777 1.706 8.663 0.000
X1 0.000 0.000 4.964 0.000
X2 -0.044 0.014 -3.197 0.001
X3 -0.062 0.121 -0.510 0.610
X4 1.256 0.310 4.055 0.000
X5 -0.155 0.070 -2.208 0.027
X6 0.022 0.025 0.867 0.386
Geographically Weighted Regression (GWR) Results
---------------------------------------------------------------------------
Spatial kernel: Adaptive bisquare
Bandwidth used: 151.000
Diagnostic information
---------------------------------------------------------------------------
Residual sum of squares: 1499.592
Effective number of parameters (trace(S)): 13.483
Degree of freedom (n - trace(S)): 145.517
Sigma estimate: 3.210
Log-likelihood: -404.013
AIC: 836.992
AICc: 840.117
BIC: 881.440
R2: 0.708
Adjusted R2: 0.680
Adj. alpha (95%): 0.026
Adj. critical t value (95%): 2.248
Summary Statistics For GWR Parameter Estimates
---------------------------------------------------------------------------
Variable Mean STD Min Median Max
-------------------- ---------- ---------- ---------- ---------- ----------
X0 15.043 1.455 12.234 15.907 16.532
X1 0.000 0.000 0.000 0.000 0.000
X2 -0.041 0.011 -0.062 -0.039 -0.025
X3 -0.174 0.046 -0.275 -0.171 -0.082
X4 1.466 0.703 0.489 1.495 2.445
X5 -0.095 0.069 -0.206 -0.094 0.001
X6 0.010 0.033 -0.039 0.002 0.076
===========================================================================
# 回归参数
var_names=['cof_Intercept','cof_TotPop90','cof_PctRural','cof_PctEld','cof_PctFB','cof_PctPov','cof_PctBlack']
gwr_coefficent=pd.DataFrame(gwr_results.params,columns=var_names)
# 回归参数显著性
gwr_flter_t=pd.DataFrame(gwr_results.filter_tvals())
# 将点数据回归结果放到面上展示
# 主要是由于两个文件中的记录数不同,矢量面中的记录比csv中多几条,因此需要将没有参加gwr的区域去掉
georgia_data_geo=gp.GeoDataFrame(georgia_data,geometry=gp.points_from_xy(georgia_data.X, georgia_data.Y))
georgia_data_geo=georgia_data_geo.join(gwr_coefficent)
# 将回归参数与面数据结合
georgia_shp_geo=gp.sjoin(georgia_shp,georgia_data_geo, how="inner", op='intersects').reset_index()
fig,ax = plt.subplots(nrows=2, ncols=4,figsize=(20,10))
axes = ax.flatten()
for i in range(0,len(axes)-1):
ax=axes[i]
ax.set_title(var_names[i])
georgia_shp_geo.plot(ax=ax,column=var_names[i],edgecolor='white',cmap='Blues',legend=True)
if (gwr_flter_t[i] == 0).any():
georgia_shp_geo[gwr_flter_t[i] == 0].plot(color='lightgrey', ax=ax, edgecolor='white') # 灰色部分表示该系数不显著
ax.set_axis_off()
if i+1==7:
axes[7].axis('off')
plt.show()
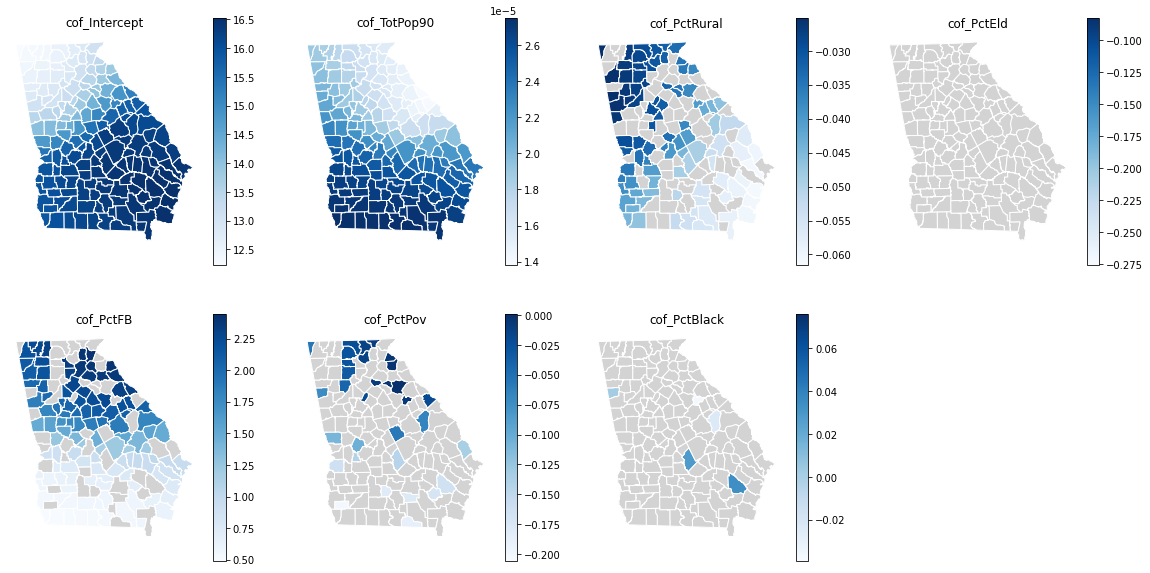
因此,从系数的分布就可以看出各个因素在每个州对于受教育程度的影响大小是不同的,并且有的因素的影响可能并不显著
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
在控制台中反复尝试之后,我想到了这种方法,可以按发生日期对类似activerecord的(Mongoid)对象进行分组。我不确定这是完成此任务的最佳方法,但它确实有效。有没有人有更好的建议,或者这是一个很好的方法?#eventsisanarrayofactiverecord-likeobjectsthatincludeatimeattributeevents.map{|event|#converteventsarrayintoanarrayofhasheswiththedayofthemonthandtheevent{:number=>event.time.day,:event=>ev
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
这是一道面试题,我没有答对,但还是很好奇怎么解。你有N个人的大家庭,分别是1,2,3,...,N岁。你想给你的大家庭拍张照片。所有的家庭成员都排成一排。“我是家里的friend,建议家庭成员安排如下:”1岁的家庭成员坐在这一排的最左边。每两个坐在一起的家庭成员的年龄相差不得超过2岁。输入:整数N,1≤N≤55。输出:摄影师可以拍摄的照片数量。示例->输入:4,输出:4符合条件的数组:[1,2,3,4][1,2,4,3][1,3,2,4][1,3,4,2]另一个例子:输入:5输出:6符合条件的数组:[1,2,3,4,5][1,2,3,5,4][1,2,4,3,5][1,2,4,5,3][
我已经构建了一些serverspec代码来在多个主机上运行一组测试。问题是当任何测试失败时,测试会在当前主机停止。即使测试失败,我也希望它继续在所有主机上运行。Rakefile:namespace:specdotask:all=>hosts.map{|h|'spec:'+h.split('.')[0]}hosts.eachdo|host|begindesc"Runserverspecto#{host}"RSpec::Core::RakeTask.new(host)do|t|ENV['TARGET_HOST']=hostt.pattern="spec/cfengine3/*_spec.r
我们的git存储库中目前有一个Gemfile。但是,有一个gem我只在我的环境中本地使用(我的团队不使用它)。为了使用它,我必须将它添加到我们的Gemfile中,但每次我checkout到我们的master/dev主分支时,由于与跟踪的gemfile冲突,我必须删除它。我想要的是类似Gemfile.local的东西,它将继承从Gemfile导入的gems,但也允许在那里导入新的gems以供使用只有我的机器。此文件将在.gitignore中被忽略。这可能吗? 最佳答案 设置BUNDLE_GEMFILE环境变量:BUNDLE_GEMFI
这似乎非常适得其反,因为太多的gem会在window上破裂。我一直在处理很多mysql和ruby-mysqlgem问题(gem本身发生段错误,一个名为UnixSocket的类显然在Windows机器上不能正常工作,等等)。我只是在浪费时间吗?我应该转向不同的脚本语言吗? 最佳答案 我在Windows上使用Ruby的经验很少,但是当我开始使用Ruby时,我是在Windows上,我的总体印象是它不是Windows原生系统。因此,在主要使用Windows多年之后,开始使用Ruby促使我切换回原来的系统Unix,这次是Linux。Rub
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:Pythonconditionalassignmentoperator对于这样一个简单的问题表示歉意,但是谷歌搜索||=并不是很有帮助;)Python中是否有与Ruby和Perl中的||=语句等效的语句?例如:foo="hey"foo||="what"#assignfooifit'sundefined#fooisstill"hey"bar||="yeah"#baris"yeah"另外,类似这样的东西的通用术语是什么?条件分配是我的第一个猜测,但Wikipediapage跟我想的不太一样。
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht