


from collections import defaultdict
n, m = map(int, input().split())
# primary记录主件的集合,key为物品id,value为[v, p]
# annex记录附件的集合,key为主件id,value为[v, p]
# defaultdict(lambda: [])默认未定义过的键值为[]
primary = {}
annex = defaultdict(lambda: [])
for i in range(1, m + 1):
value, p, q = map(int, input().split())
# 该物品为主件
if q == 0:
primary[i] = [value, p]
# 该物品为附件
else:
annex[q].append([value, p])
m = len(primary) # 主件个数转化为物品个数
dp = [[0] * (n + 1) for _ in range(m + 1)]
price, value = [[]], [[]]
for key in primary:
price_temp, value_temp = [], []
price_temp.append(primary[key][0]) # 1、主件
value_temp.append(primary[key][0] * primary[key][1])
if key in annex: # 存在附件
price_temp.append(price_temp[0] + annex[key][0][0]) # 2、主件+附件1
value_temp.append(value_temp[0] + annex[key][0][0] * annex[key][0][1])
if len(annex[key]) > 1: # 存在2附件
price_temp.append(price_temp[0] + annex[key][1][0]) # 3、主件+附件2
value_temp.append(value_temp[0] + annex[key][1][0] * annex[key][1][1])
price_temp.append(price_temp[0] + annex[key][0][0] + annex[key][1][0]) # 3、主件+附件1+附件2
value_temp.append(value_temp[0] + annex[key][0][0] * annex[key][0][1] + annex[key][1][0] * annex[key][1][1])
price.append(price_temp)
value.append(value_temp)
# 动态规划
for i in range(1, m + 1):
for j in range(10, n + 1, 10): # 物品的价格是10的整数倍
max_i = dp[i - 1][j]
for k in range(len(price[i])):
if j - price[i][k] >= 0:
max_i = max(max_i, dp[i - 1][j - price[i][k]] + value[i][k])
dp[i][j] = max_i
print(dp[m][n])

import sys
li = input().split(";")
seta = {'A', 'S', 'D', 'W'}
setb = {'1', '2', '3', '4', '5', '6', '7', '8', '9', '0'}
def isvalid(zb):
dic = []
value = []
l = len(zb)
if l > 3 or l < 2:
return False
for i in range(l):
if i == 0:
if zb[i] in seta:
key = zb[i]
else:
return False
else:
if zb[i] in setb:
value.append(zb[i])
else:
return False
if len(value) == 1:
value_ = int(value[0])
else:
value_ = int(value[0]) * 10 + int(value[1])
dic.append(key)
dic.append(value_)
return dic
begin = [0, 0]
for zb in li:
comm = isvalid(zb)
if comm:
if comm[0] == 'A':
begin[0] -= comm[1]
elif comm[0] == 'S':
begin[1] -= comm[1]
elif comm[0] == 'D':
begin[0] += comm[1]
elif comm[0] == 'W':
begin[1] += comm[1]
print(str(begin[0])+','+str(begin[1]))# 大佬的方法
import sys
line=sys.stdin.readline().strip()
orders=line.split(';')
dic={'A':0,'W':0,'S':0,'D':0}
for i in orders :
if len(i)>3 or len(i)<2 or i[0] not in dic:
continue
try:
pos=int(i[1:])
dic[i[0]]+=pos
except :
continue
print str(dic['D']-dic['A'])+','+str(dic['W']-dic['S'])

stra = input()
strb = input()
la = len(stra)
lb = len(strb)
dp = [[0 for _ in range(lb+1)] for _ in range(la+1)]
ans = 0
for i in range(1, la+1):
for j in range(1, lb+1):
if stra[i-1] == strb[j-1]:
dp[i][j] = dp[i-1][j-1]+1
ans = max(ans, dp[i][j])
print(ans)

num = input()
li = input().split()
height = list(map(int, li))
l = len(height)
dp1 = [0 for _ in range(l)]
dp2 = [0 for _ in range(l)]
# 从左向右统计每个人的左边有多少个可以成为序列的
for i in range(1, l):
for j in range(i):
if height[i] > height[j] and dp1[i] < dp1[j]+1:
dp1[i] = dp1[j] + 1
# 从右向左统计每个人的右边有多少个可以成为序列的
for i in range(l - 2, -1, -1):
for j in range(i, l):
if height[i] > height[j] and dp2[i] < dp2[j] + 1:
dp2[i] = dp2[j] + 1
# 每个人可以成为序列的个数为两个dp之和加上自己
ans = l
for i in range(l):
ans = min(l - (dp1[i] + dp2[i] + 1), ans)
print(ans)
s = input()
l = len(s)
max_l = 0
for i in range(l):
ans = 1
# 长度为奇数
left = i-1
right = i+1
while left >= 0 and right <= l-1 and s[left] == s[right]:
ans += 2
left -= 1
right += 1
max_l = max(max_l, ans)
ans = 0
# 长度为偶数,i为中心前一个
left = i
right = i + 1
while left >= 0 and right <= l-1 and s[left] == s[right]:
ans += 2
left -= 1
right += 1
max_l = max(max_l, ans)
print(max_l)

num_li = input().split()
num_li = list(map(int, num_li))
# item记录
def dfs(nums):
if not nums:
return False
if len(nums) == 1:
return abs(nums[0] - 24) < 1e-6
for i, a in enumerate(nums): # 获取第一个数字
for j, b in enumerate(nums): # 获取第二个数字
if i != j:
new_nums = []
for k, c in enumerate(nums): # 获取第三个数字
if k != i and k != j:
new_nums.append(c)
for k in range(4): # 获取四则运算中的哪一个
if k < 2 and i > j: # 如果是加法乘法不需要考虑顺序
continue # 舍去i,j互换的那一种情况
if k == 0: new_nums.append(a+b)
if k == 1: new_nums.append(a*b)
if k == 2: new_nums.append(a-b)
if k == 3:
if abs(b) < 1e-6: continue
new_nums.append(a/b)
if dfs(new_nums): return True
new_nums.pop()
return False
if dfs(num_li): print("true")
else: print("false")num_li = input().split()
num_li = list(map(int, num_li))
def dfs(s, res):
if len(s) == 1:
return s[0] == res
for i in range(len(s)):
mid = s[i]
rest = s[:i] + s[i+1:]
if dfs(rest, res+mid) or dfs(rest, res-mid) or dfs(rest, res/mid) or dfs(rest, res*mid):
return True
return False
print(f'{dfs(num_li, 24)}'.lower())
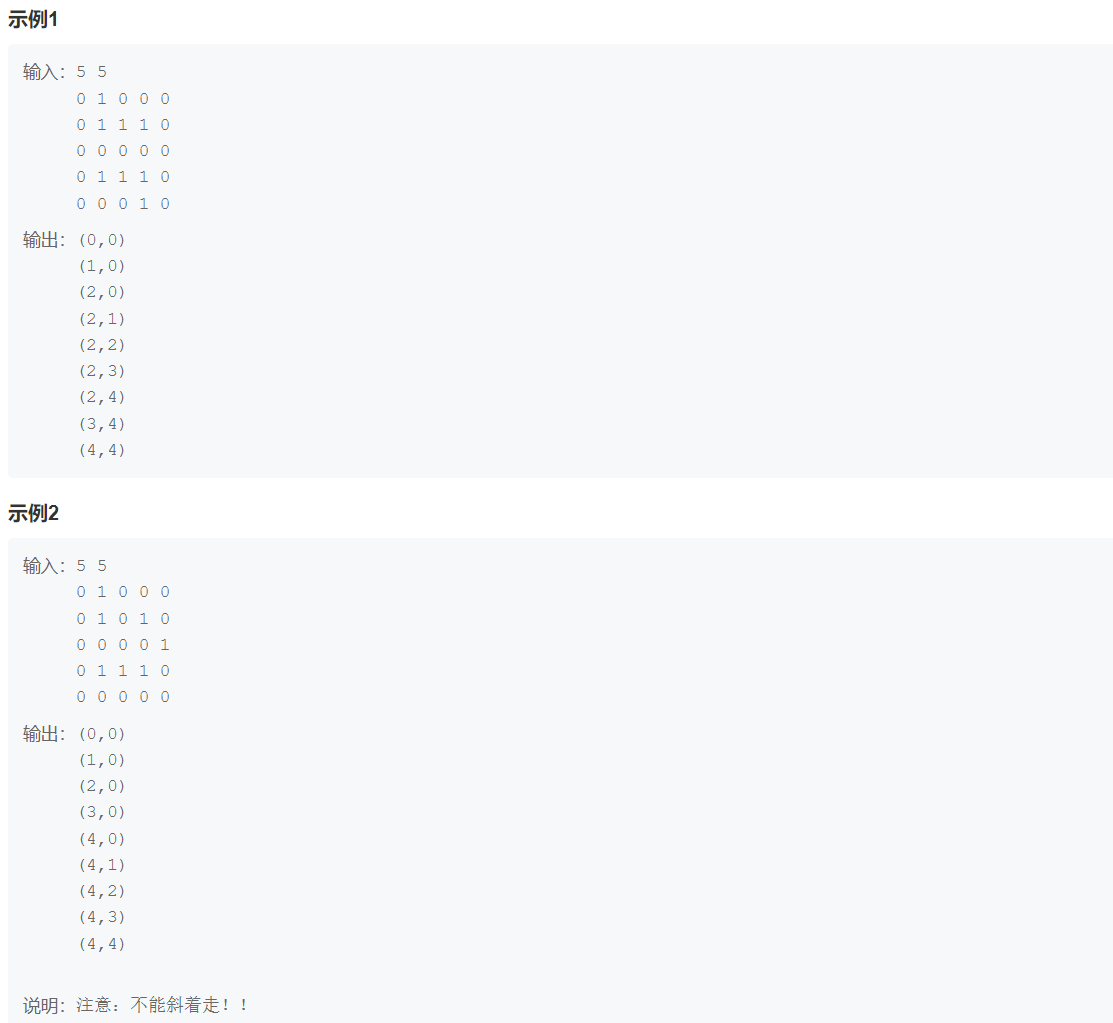
row, col = map(int, input().split())
li = []
for _ in range(row):
line = list(map(int, input().split()))
li.append(line)
dirs = [[-1, 0], [1, 0], [0, -1], [0, 1]]
def dfs(cur_row, cur_col, used, ans):
if cur_row == row-1 and cur_col == col-1:
return ans
for d in dirs:
new_row = cur_row + d[0]
new_col = cur_col + d[1]
if (new_row < 0) or (new_row >= row) or (new_col < 0) or (new_col >= col) or (li[new_row][new_col] == 1) or ([new_row, new_col] in used):
continue
else:
ans0 = dfs(new_row, new_col, used + [[new_row, new_col]], ans + [[new_row, new_col]])
if ans0: return ans0
ans = dfs(0, 0, [[0, 0]], [[0, 0]])
for a in ans:
print("({a1},{a2})".format(a1=a[0], a2=a[1]))

s1 = input()
s2 = input()
l1 = len(s1)
l2 = len(s2)
dp = [[0 for _ in range(l2)] for _ in range(l1)]
# 填充dp[i][0]
for i in range(l1):
if i == 0:
if s1[i] != s2[0]:
dp[i][0] = 1
else:
if s1[i] == s2[0]:
dp[i][0] = i
else:
dp[i][0] = dp[i-1][0] + 1
# 填充dp[0][j]
for j in range(1, l2):
if s1[0] == s2[j]:
dp[0][j] = j
else:
dp[0][j] = dp[0][j-1] + 1
for i in range(1, l1):
for j in range(1, l2):
if s1[i] == s2[j]:
dp[i][j] = dp[i-1][j-1]
else:
dp[i][j] = min(dp[i-1][j]+1, dp[i][j-1]+1, dp[i-1][j-1]+1)
print(dp[-1][-1])
判断是否有重复子串可以用split(),切成两段说明没有重复,两段以上说明有重复
import sys
def solve(s):
if len(s)<8:
return False
flag = [0, 0, 0, 0] # 分别标记大写字母,小写字母,数字,其他符号
for s0 in s:
if s0.isupper():
flag[0] = 1
elif s0.islower():
flag[1] = 1
elif s0.isdigit():
flag[2] = 1
elif s0.isspace():
continue
else:
flag[3] = 1
if sum(flag) < 3:
return False
for i in range(len(s)-3):
if len(s.split(s[i:i+3])) >= 3:
return False
return True
for line in sys.stdin:
if solve(line):
print("OK")
else:
print("NG")
s = input()
a = ''
for s0 in s:
if s0.isalpha():
a += s0
b = sorted(a, key=str.upper)
index = 0
d = ''
for i in range(len(s)):
if s[i].isalpha():
d += b[index]
index += 1
else:
d += s[i]
print(d)sorted(a, key=str.upper) 按照字母排序
def check(a,b):
L1 = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789"
L2 = "BCDEFGHIJKLMNOPQRSTUVWXYZAbcdefghijklmnopqrstuvwxyza1234567890"
result = ""
if b == 1:
for i in a:
result += L2[L1.index(i)]
elif b == -1:
for i in a:
result += L1[L2.index(i)]
return result
while True:
try:
print(check(input(),1))
print(check(input(), -1))
except:
break
while True:
try:
a = input()
a = list(a) #需要加密的字符串
b = input()
b = list(b) #需要解密的字符串
for i in range(len(a)):#加密过程
if(a[i].isupper()): #如果字符是大写字母
if(a[i] == 'Z'): #首先如果是Z的话变为a,若z的ascll+1的值是‘{’
a[i] = 'a'
else:
a[i] = a[i].lower() #先变为小写
c = ord(a[i]) + 1 #ascll码+1
a[i] = chr(c) #转为字符
elif(a[i].islower()): #小写同理
if(a[i] == 'z'):
a[i] = 'A'
else:
a[i] = a[i].upper()
c = ord(a[i]) + 1
a[i] = chr(c)
elif(a[i].isdigit()): #若是数字则+1,9需要单独处理
if(a[i] == '9'):
a[i] = '0'
else:
a[i] = int(a[i]) + 1
a[i] = str(a[i])
else: #若是其他字符则保持不变
a[i] = a[i]
for i in range(len(b)): #解密过程
if(b[i].isupper()): #若为大写则先变为小写,再ascll减一,A要单独处理
if(b[i] == 'A'):
b[i] = 'z'
else:
b[i] = b[i].lower()
c = ord(b[i]) - 1
b[i] = chr(c)
elif(b[i].islower()): #若是小写要先变为大写,再ascll减一,a要单独处理
if(b[i] == 'a'):
b[i] = 'Z'
else:
b[i] = b[i].upper()
c = ord(b[i]) - 1
b[i] = chr(c)
elif(b[i].isdigit()):#若是数字需要减一,0要单独处理
if(b[i] == '0'):
b[i] = '9'
else:
b[i] = int(b[i]) - 1
b[i] = str(b[i])
else:
b[i] = b[i]
print(''.join(a)) #按要求输出
print(''.join(b))
except:
break
字符串按照字典排序:sorted(s)

十进制换二进制:num2 = bin(num10)[2:]
s1 = list(map(int, input().split(".")))
num2 = []
for num in s1:
a = str(bin(num)[2:])
for _ in range(8-len(a)):
a = '0' + a
num2.append(a)
num2 = ''.join(num2)
ans = 0
for i in range(31, -1, -1):
ans += int(num2[i])*(2**(31-i))
print(ans)
s2 = int(input())
num2 = str(bin(s2)[2:])
for _ in range(32-len(num2)):
num2 = '0' + num2
ans = ''
li = []
for i in range(32):
li.append(num2[i])
if i == 7 or i == 15 or i == 23 or i == 31:
num10 = 0
for j in range(7, -1, -1):
num10 += int(li[j])*(2**(7-j))
ans += str(num10) + '.'
li = []
print(ans[:-1])
pas = input()
pre = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z']
new = []
for p in pas:
if p.upper() not in new:
new.append(p.upper())
for p in pre:
if p not in new:
new.append(p)
s = input()
ans = ''
for s0 in s:
if s0.isupper():
ans += new[pre.index(s0)]
else:
ans += new[pre.index(s0.upper())].lower()
print(ans)
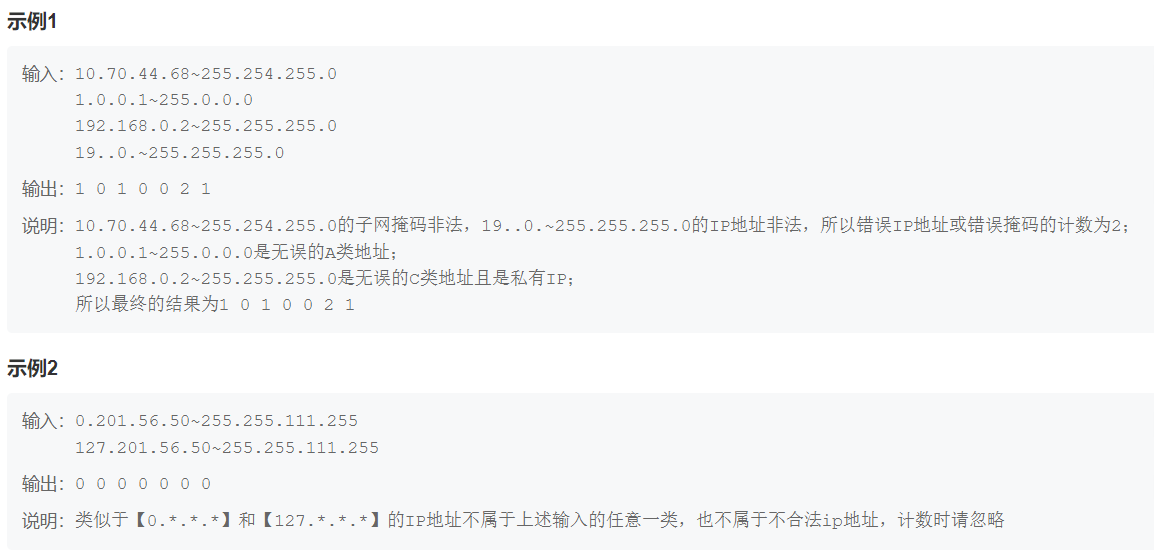
import sys
res = [0,0,0,0,0,0,0]
def puip(ip):
if 1 <= ip[0] <= 126: # A类地址判断条件
res[0] += 1
elif 128 <= ip[0] <= 191: # B类地址判断条件
res[1] += 1
elif 192 <= ip[0] <= 223: # C类地址判断条件
res[2] += 1
elif 224 <= ip[0] <= 239: # D类地址判断条件
res[3] += 1
elif 240 <= ip[0] <= 255: # E类地址判断条件
res[4] += 1
return
def prip(ip): # 私有IP地址判断条件
if (ip[0] == 10) or (ip[0] == 172 and 16 <= ip[1] <= 32) or (ip[0] == 192 and ip[1] == 168):
res[6] += 1
return
def ym(msk): # 判断掩码合法性
val = (msk[0] << 24) + (msk[1] << 16) + (msk[2] << 8) + msk[3] # 转换成32位
if val == 0: # 排除全0的情况
return False
if (val+1) == (1<<32): # 排除全1的情况
return False
flag = 0
while(val):
digit = val & 1 # 逐位判断
if digit == 1:
flag = 1
if flag == 1 and digit == 0: # flag=1表示已经不允许再出现0
return False
val >>= 1
return True
def judge(line):
ip, msk = line.strip().split('~')
ips = [int(x) for x in filter(None, ip.split('.'))] # 获得表示IP的列表,理论上应该包含四个元素
msks = [int(x) for x in filter(None, msk.split('.'))] # 获得表示掩码的列表,理论上应该包含四个元素
if ips[0] == 0 or ips[0] == 127: # 排除非法IP不计数
return
if len(ips) < 4 or len(msks) < 4: # 判断错误掩码或错误IP
res[5] += 1
return
if ym(msks) == True: # 通过掩码判断的可以进行IP判断
puip(ips)
prip(ips)
else:
res[5] += 1
return
for line in sys.stdin:
judge(line)
# judge("192.168.0.2~255.255.255.0")
res = [str(x) for x in res]
print(" ".join(res))

num = int(input())
li = list(map(int, input().split()))
li1 = [] # 5
li2 = [] # 3
li0 = []
for i in range(num):
if li[i] % 5 == 0:
li1.append(li[i])
elif li[i] % 3 == 0:
li2.append(li[i])
else:
li0.append(li[i])
l = len(li0)
def dfs(index, ans1, ans2):
if index == l:
if sum(ans1) == sum(ans2):
return True
else:
return False
return dfs(index+1, ans1+[li0[index]], ans2) or dfs(index+1, ans1, ans2+[li0[index]])
if dfs(0, li1, li2):
print("true")
else:
print("false")

s = list(input().split())
dic = {'3':3, '4':4, '5':5, '6':6, '7':7, '8':8, '9':9, '10':10, 'J':11, 'Q':12, 'K':13, 'A':1, '2':2, 'joker':0, 'JOKER':0}
dic0 = {0:'+', 1:'-', 2:'*', 3:'/'}
def dfs(li, index, used, ans, res):
if index == 4:
res.append(ans)
return
for i in range(4):
if i in used:
continue
else:
dfs(li, index+1, used+[i], ans+[li[i]], res)
def dfs0(index, ans, res):
if index == 3:
res.append(ans)
return
for i in range(4):
dfs0(index+1, ans+[i], res)
def solve(s):
li = []
for s0 in s:
li.append(dic[s0])
if 0 in li:
return 0, 0
# 数字位排列
resnum = []
dfs(li, 0, [], [], resnum)
# 运算符排列
resope = []
dfs0(0, [], resope)
for rnum in resnum:
for rope in resope:
count = 0
ans = rnum[0]
while count < 3:
if rope[count] == 0: # 加法
ans += rnum[count+1]
elif rope[count] == 1: # 减法
ans -= rnum[count+1]
elif rope[count] == 2: # 乘法
ans *= rnum[count+1]
elif rope[count] == 3: # 除法
ans /= rnum[count+1]
count += 1
if ans == 24:
return rnum, rope
return -1, -1
num, ope = solve(s)
if num == 0:
print('ERROR')
elif num == -1:
print('NONE')
else:
for i in range(4):
if num[i] == 1:
num[i] == 'A'
elif num[i] == 11:
num[i] == 'J'
elif num[i] == 12:
num[i] == 'Q'
elif num[i] == 13:
num[i] == 'K'
else:
num[i] = str(num[i])
anss = []
index = 0
while index < 4:
# 添加数字
num0 = num[index]
if num0 == 1:
anss.append('A')
elif num0 == 11:
anss.append('J')
elif num0 == 12:
anss.append('Q')
elif num0 == 13:
anss.append('K')
else:
anss.append(str(num0))
if index != 3:
anss.append(dic0[ope[index]])
index += 1
print(''.join(anss))


l = [] # 记录文件名和行数
ll = [] # 记录出现次数
while 1:
try:
s = input().split('\\')[-1]
data = s.split(' ')[0][-16:] + ' ' + s.split(' ')[1]
if data not in l:
l.append(data)
ll.append(1)
else:
ll[l.index(data)] += 1
except:
break
for i in range(len(l[-8:])):
print(l[-8:][i], ll[-8:][i])

i = list(map(int, input().split()))
r = list(map(int, input().split()))
i_num = i[0]
i_li = i[1:]
r_num = r[0]
r_li = r[1:]
r_li.sort()
r_li = list(set(r_li))
def help0(i0, r0):
ans = i0.split(r0)
if len(ans) == 1:
return 0
elif len(ans) > 1:
return 1
dic = {}
for r in r_li:
ans = []
for i in range(i_num):
r0 = str(r)
i0 = str(i_li[i])
if help0(i0, r0):
ans.append(str(i))
ans.append(i0)
if not ans:
continue
else:
dic[r] = ans
ans = []
for key in dic:
ans0 = []
ans0.append(str(key))
ans0.append(str(len(dic[key])//2))
for s in dic[key]:
ans0.append(s)
ans.append(ans0)
ans.sort(key=lambda x: int(x[0]))
out = []
for a in ans:
for b in a:
out.append(b)
count = len(out)
out = str(count) +' '+ ' '.join(out)
print(out)
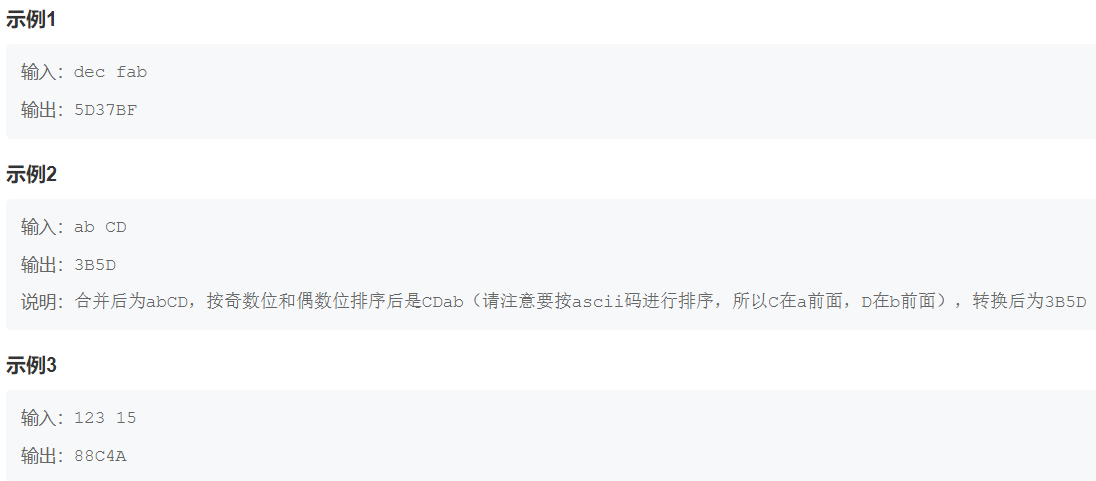
s = list(input().split())
s = ''.join(s)
index = 0
s0 = []
s1 = []
while index < len(s):
if index % 2 == 0:
s0.append(s[index])
else:
s1.append(s[index])
index += 1
s0.sort()
s1.sort()
s = []
index = 0
while index < len(s0):
s.append(s0[index])
if index < len(s1):
s.append(s1[index])
index += 1
seta = {'1', '2', '3', '4', '5', '6', '7', '8', '9', '0'}
setb = {'A', 'a', 'B', 'b', 'C', 'c', 'D', 'd', 'E', 'e', 'F', 'f'}
def helper(s):
if s in seta:
s = int(s)
elif s in setb:
if s == 'A' or s == 'a':
s = 10
elif s == 'B' or s == 'b':
s = 11
elif s == 'C' or s == 'c':
s = 12
elif s == 'D' or s == 'd':
s = 13
elif s == 'E' or s == 'e':
s = 14
elif s == 'F' or s == 'f':
s = 15
else:
return s
sb = str(bin(s)[2:])
for _ in range(4-len(sb)):
sb = '0' + sb
sb_ = ''
for i in range(3, -1, -1):
sb_ += sb[i]
sb = int(sb_, 2)
if sb == 10:
sb = 'A'
elif sb == 11:
sb = 'B'
elif sb == 12:
sb = 'C'
elif sb == 13:
sb = 'D'
elif sb == 14:
sb = 'E'
elif sb == 15:
sb = 'F'
else:
sb = str(sb)
return sb
ans = ''
for s0 in s:
ans += helper(s0)
print(ans)

def ip_to_bi(s):
s = list(s.split('.'))
bi = []
for s0 in s:
if int(s0) > 255 or int(s0) < 0:
return -1
sb = str(bin(int(s0))[2:])
for _ in range(8-len(sb)):
sb = '0' + sb
bi.append(sb)
return ''.join(bi)
def helper(mo, s1, s2):
mo = ip_to_bi(mo)
s1 = ip_to_bi(s1)
s2 = ip_to_bi(s2)
if mo == -1 or s1 == -1 or s2 == -1:
return '1'
flag = 1
for s in mo:
if s == '1' and flag == 1:
continue
elif s == '0' and flag == 1:
flag = 0
elif s == '1' and flag == 0:
return '1'
elif s == '0' and flag == 0:
continue
ans1 = ''
ans2 = ''
for i in range(32):
ans1 += str(int(mo[i]) and int(s1[i]))
ans2 += str(int(mo[i]) and int(s2[i]))
if ans1 == ans2:
return '0'
else:
return '2'
while True:
try:
mo = input()
s1 = input()
s2 = input()
print(helper(mo, s1, s2))
except:
break
s = list(input().split('-'))
s[0] = list(s[0].split())
s[1] = list(s[1].split())
# 1. 个子 1
# 2. 对子 2
# 3. 顺子 5
# 4. 三个 3
# 5. 四个(大于上面所有)4
# 6. 对王(大于上面所有)2
def get_type(s):
l = len(s)
if l == 1:
return 1
elif l == 2:
if s[0] == 'joker' or s[0] == 'JOKER':
return 6
else:
return 2
elif l == 5:
return 3
elif l == 3:
return 4
elif l ==4:
return 5
t1 = get_type(s[0])
t2 = get_type(s[1])
dic = {'A':14, '2':15, 'J':11, 'Q':12, 'K':13, 'joker':16, 'JOKER':17}
if t1 == t2:
s0 = s[0][0]
s1 = s[1][0]
if s0 in dic:
s0 = dic[s0]
if s1 in dic:
s1 = dic[s1]
if int(s0) > int(s1):
print(' '.join(s[0]))
else:
print(' '.join(s[1]))
elif (t1 == 5 and t2 != 6) or (t2 == 5 and t1 != 6):
if t1 == 5:
print(' '.join(s[0]))
else:
print(' '.join(s[1]))
elif t1 == 6 or t2 == 6:
if t1 == 6:
print(' '.join(s[0]))
else:
print(' '.join(s[1]))
else:
print("ERROR")

import math
# 判断是否是素数
def check(num):
# 检验到int(math.sqrt(num)) + 1即可
for i in range(2,int(math.sqrt(num)) + 2):
if(num % i == 0):
return False
return True
# 配对的过程
# 只有奇数和偶数的结合才可能是素数
def find(odd, visited, choose, evens):
for j,even in enumerate(evens):
# 如果即能配对,这两个数之前没有配过
# 即使两个不能配对visit值为0,但是也不能过是否是素数这一关,所以visit就可以看为两个能配对的素数是否能配对
if check(odd+even) and not visited[j]:
visited[j] = True #代表这两个数能配对
# 如果当前奇数没有和任何一个偶数现在已经配对,那么认为找到一组可以连接的
# 如果当前的奇数已经配对,那么就让那个与之配对的偶数断开连接,让他再次寻找能够配对的奇数
if choose[j]==0 or find(choose[j],visited,choose,evens):
choose[j] = odd #当前奇数已经和当前的偶数配对
return True
return False # 如果当前不能配对则返回False
while True:
try:
num = int(input())
a = list(map(int, input().split()))
b = []
count = 0
evens = []
odds = []
for i in a: #将输入的数分为奇数和偶数
if(i % 2 == 0):
odds.append(i)
else:
evens.append(i)
choose = [0]*len(evens) #choose用来存放当前和这个奇数配对的那个偶数
for odd in odds:
visited = [False]*len(evens) #visit用来存放当前奇数和偶数是否已经配过对
if find(odd,visited,choose,evens):
count += 1
print(count)
except:
break






class Solution:
def isValue(self, board, x, y):
# 检查已经填入的坐标是否和列中有的元素相等
for i in range(9):
if i != x and board[i][y] == board[x][y]:
return False
# 检查已经填入的坐标是否和行中有的元素相等
for j in range(9):
if j != y and board[x][j] == board[x][y]:
return False
# 检查每个正方形是否符合(粗线框内只有1~9)
m, n = 3*(x // 3), 3*(y // 3) # 这里求出的是3x3网格的左上角的坐标
for i in range(3):
for j in range(3):
if(i+m != x or j+n != y) and board[i+m][j+n] == board[x][y]:
return False
return True
def dfs(self, board):
for i in range(9):
for j in range(9):
if board[i][j] == 0:
for k in '123456789': # 从里面选择一个
board[i][j] = int(k)
if self.isValue(board, i, j) and self.dfs(board):
return True
board[i][j] = 0 # 回溯
return False # 都不行,说明上次的数字不合理
return True # 全部遍历完,返回True
while True:
try:
board = []
for i in range(9):
row = list(map(int, input().split()))
board.append(row)
s = Solution()
s.dfs(board)
for i in range(9):
board[i] = list(map(str, board[i]))
print(' '.join(board[i]))
except:
break
为了将Cucumber用于命令行脚本,我按照提供的说明安装了arubagem。它在我的Gemfile中,我可以验证是否安装了正确的版本并且我已经包含了require'aruba/cucumber'在'features/env.rb'中为了确保它能正常工作,我写了以下场景:@announceScenario:Testingcucumber/arubaGivenablankslateThentheoutputfrom"ls-la"shouldcontain"drw"假设事情应该失败。它确实失败了,但失败的原因是错误的:@announceScenario:Testingcucumber/ar
我正在使用puppet为ruby程序提供一组常量。我需要提供一组主机名,我的程序将对其进行迭代。在我之前使用的bash脚本中,我只是将它作为一个puppet变量hosts=>"host1,host2"我将其提供给bash脚本作为HOSTS=显然这对ruby不太适用——我需要它的格式hosts=["host1","host2"]自从phosts和putsmy_array.inspect提供输出["host1","host2"]我希望使用其中之一。不幸的是,我终其一生都无法弄清楚如何让它发挥作用。我尝试了以下各项:我发现某处他们指出我需要在函数调用前放置“function_”……这
这是一道面试题,我没有答对,但还是很好奇怎么解。你有N个人的大家庭,分别是1,2,3,...,N岁。你想给你的大家庭拍张照片。所有的家庭成员都排成一排。“我是家里的friend,建议家庭成员安排如下:”1岁的家庭成员坐在这一排的最左边。每两个坐在一起的家庭成员的年龄相差不得超过2岁。输入:整数N,1≤N≤55。输出:摄影师可以拍摄的照片数量。示例->输入:4,输出:4符合条件的数组:[1,2,3,4][1,2,4,3][1,3,2,4][1,3,4,2]另一个例子:输入:5输出:6符合条件的数组:[1,2,3,4,5][1,2,3,5,4][1,2,4,3,5][1,2,4,5,3][
我想使用spawn(针对多个并发子进程)在Ruby中执行一个外部进程,并将标准输出或标准错误收集到一个字符串中,其方式类似于使用Python的子进程Popen.communicate()可以完成的操作。我尝试将:out/:err重定向到一个新的StringIO对象,但这会生成一个ArgumentError,并且临时重新定义$stdxxx会混淆子进程的输出。 最佳答案 如果你不喜欢popen,这是我的方法:r,w=IO.pipepid=Process.spawn(command,:out=>w,:err=>[:child,:out])
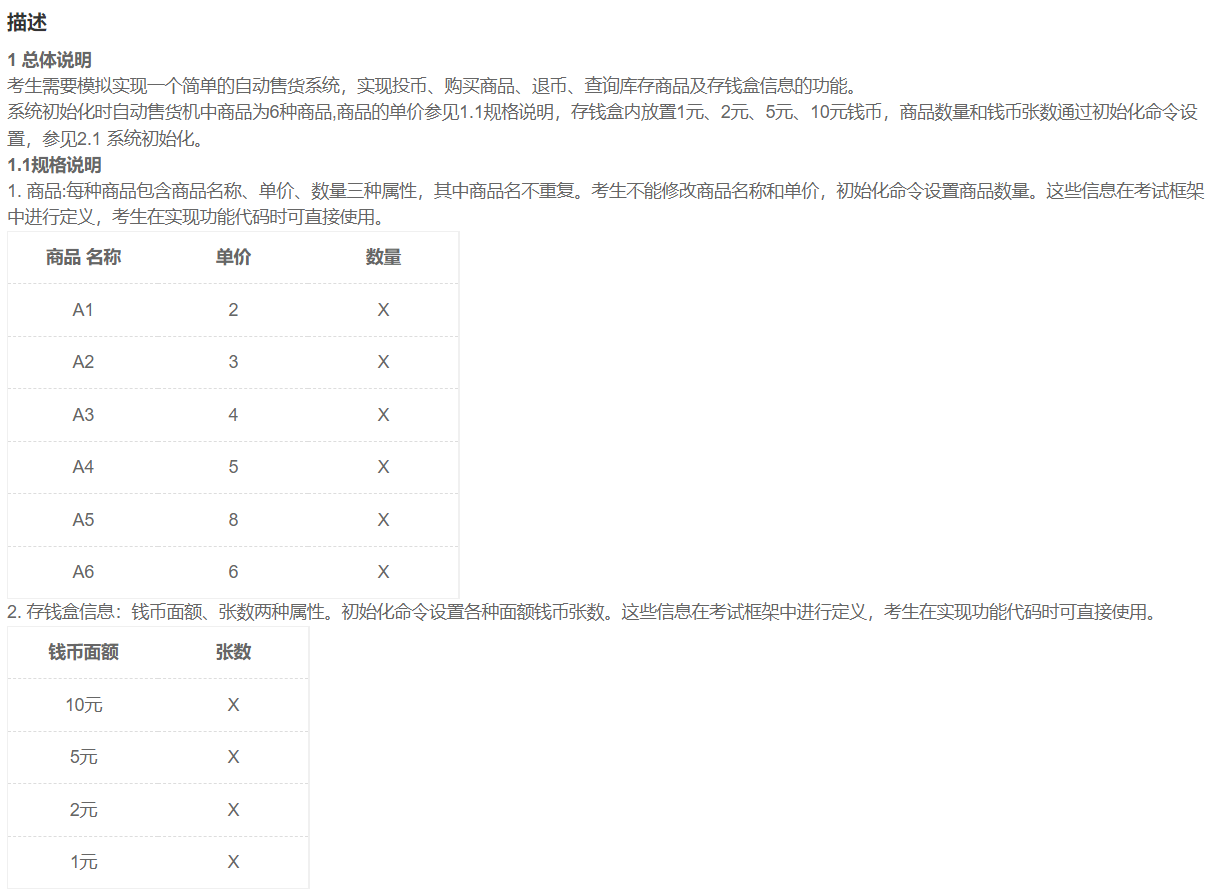
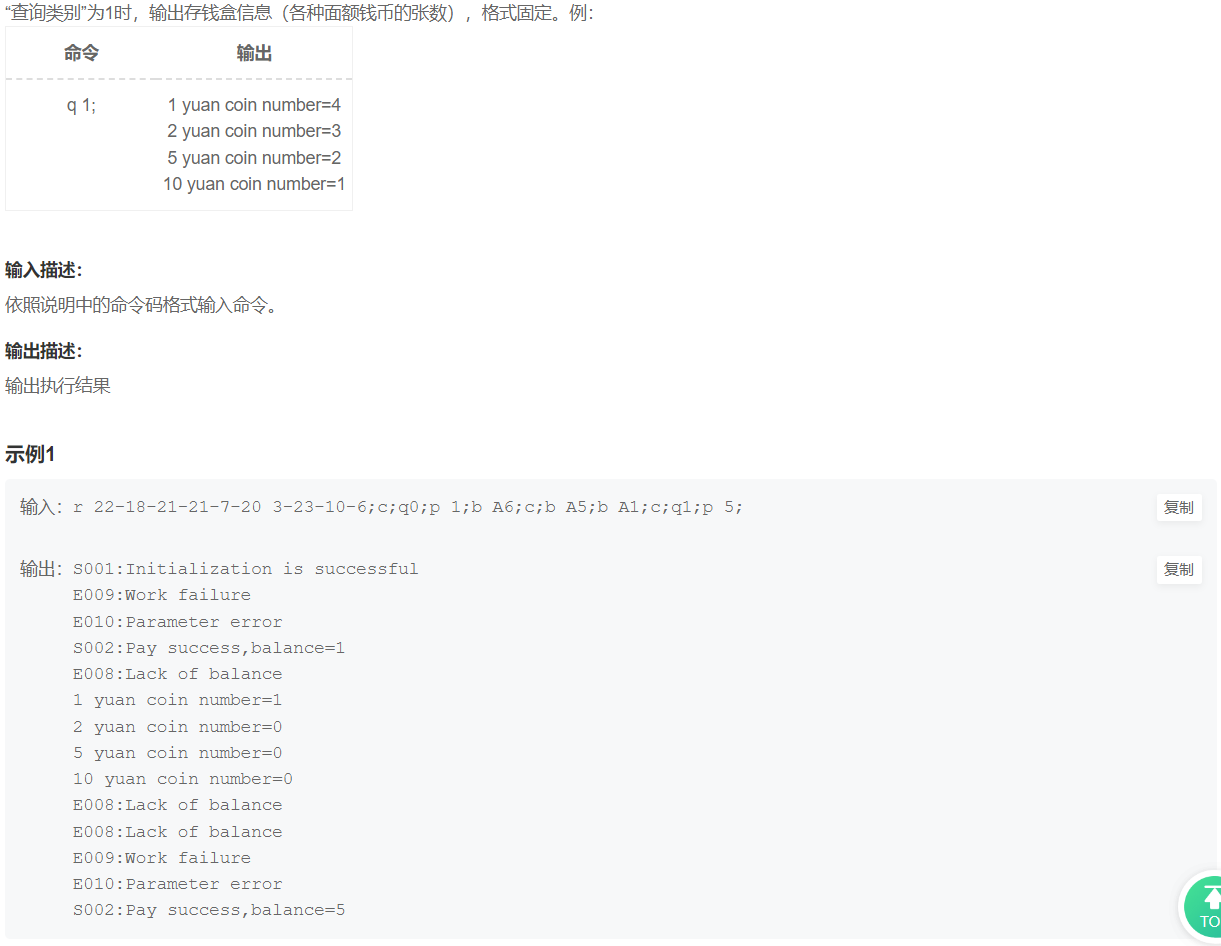
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
system-view进入系统视图quit退到系统视图sysname交换机命名vlan20创建vlan(进入vlan20)displayvlan显示vlanundovlan20删除vlan20displayvlan20显示vlan里的端口20Interfacee1/0/24进入端口24portlink-typeaccessvlan20把当前端口放入vlan20undoporte1/0/10删除当前VLAN端口10displaycurrent-configuration显示当前配置02配置交换机支持TELNETinterfacevlan1进入VLAN1ipaddress192.168.3.100
我想知道Ruby用来在命令行打印这些东西的输出流:irb(main):001:0>a="test"=>"test"irb(main):002:0>putsatest=>nilirb(main):003:0>a=>"test"$stdout是否用于irb(main):002:0>和irb(main):003:0>?而且,在这两次调用之间,$stdout的值是否有任何变化?另外,有人能告诉我打印/写入这些内容的Ruby源代码吗? 最佳答案 是的。而且很容易向自己测试/证明。在命令行试试这个:ruby-e'puts"foo"'>test.
我在使用自定义RailsFormBuilder时遇到了问题,从昨天晚上开始我就发疯了。基本上我想对我的构建器方法之一有一个可选block,以便我可以在我的主要content_tag中显示其他内容。:defform_field(method,&block)content_tag(:div,class:'field')doconcatlabel(method,"Label#{method}")concattext_field(method)capture(&block)ifblock_given?endend当我在我的一个Slim模板中调用该方法时,如下所示:=f.form_field:e
这是针对我无法破坏的现有公共(public)API,但我确实希望对其进行扩展。目前,该方法采用字符串或符号或任何其他在作为第一个参数传递给send时有意义的内容我想添加发送字符串、符号等列表的功能。我可以只使用is_a吗?数组,但还有其他发送列表的方法,这不是很像ruby。我将调用列表中的map,所以第一个倾向是使用respond_to?:map。但是字符串也会响应:map,所以这行不通。 最佳答案 如何将它们全部视为数组?String的行为与仅包含String的Array相同:deffoo(obj,arg)[*arg].eac
考虑一下:现在这些情况:#output:http://domain.com/?foo=1&bar=2#output:http://domain.com/?foo=1&bar=2#output:http://domain.com/?foo=1&bar=2#output:http://domain.com/?foo=1&bar=2我需要用其他字符串输出URL。我如何保证&符号不会被转义?由于我无法控制的原因,我无法发送&。求助!把我的头发拉到这里:\编辑:为了澄清,我实际上有一个像这样的数组:@images=[{:id=>"fooid",:url=>"http://