Kafka是最初由Linkedin公司开发,是一个分布式、分区的、多副本的、多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx日志、访问日志,消息服务等等,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
主要应用场景是:日志收集系统和消息系统。
Kafka主要设计目标如下:
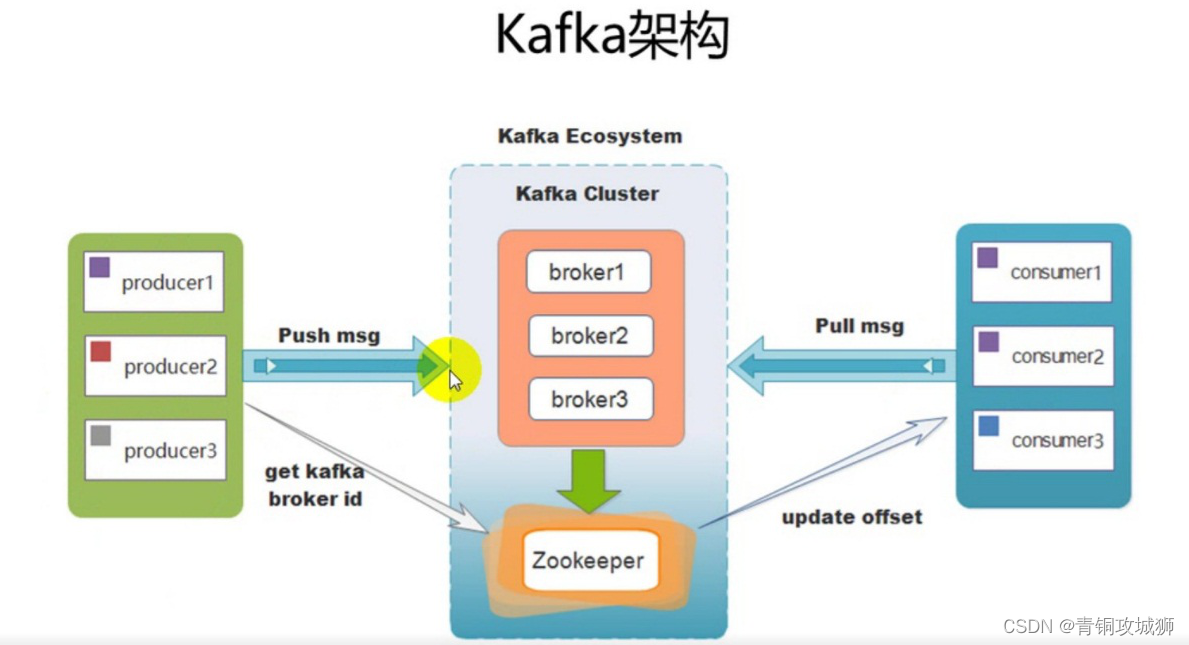
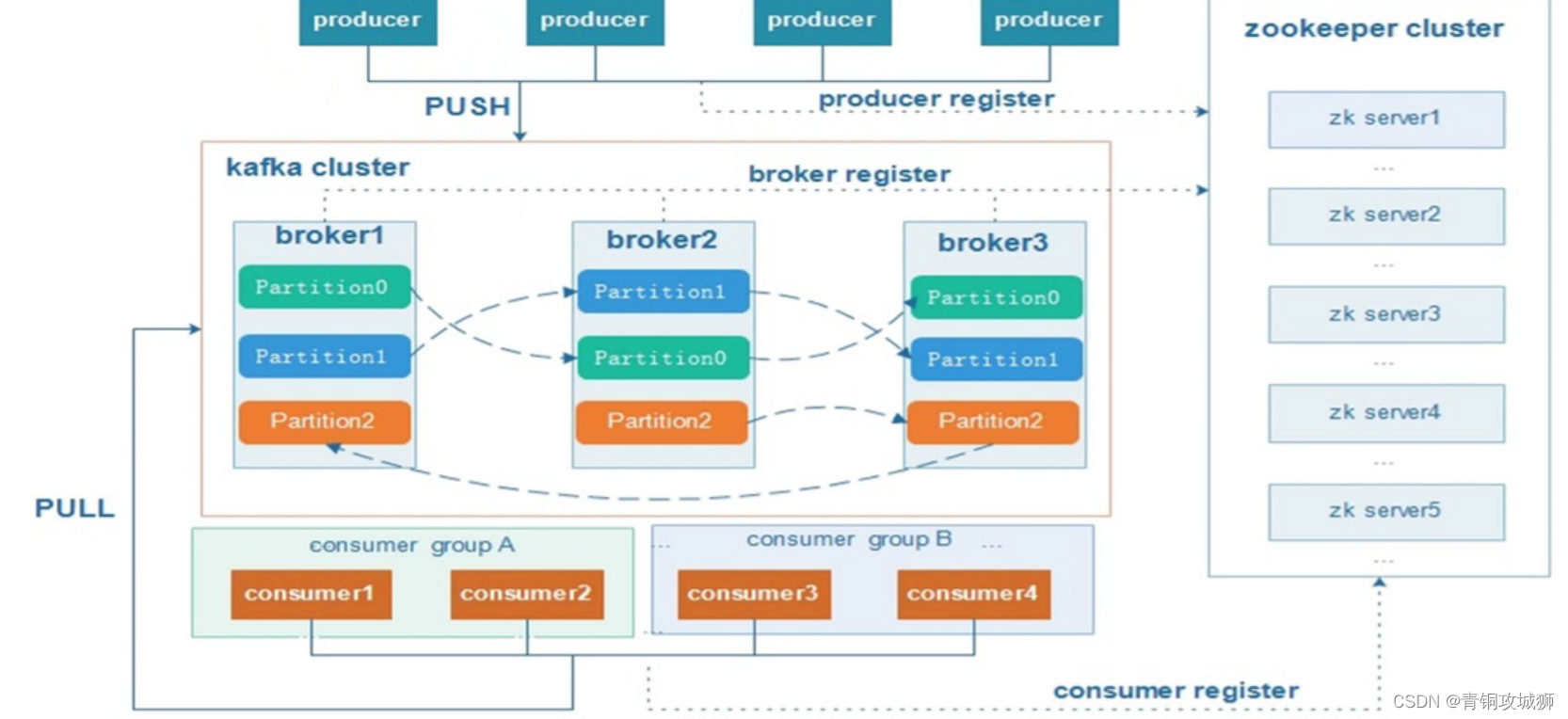
注意:Kafka的元数据都是存放在zookeeper中。kafka支持消息持久化,消费端为拉模型来拉取数据,消费状态和订阅关系有客户端负责维护,消息消费完后,不会立即删除,会保留历史消息。因此支持多订阅时,消息只会存储一份就可以了。
kafka有三层结构:kafka有多个主题,每个主题有多个分区,每个分区又有多条消息。
分区机制:主要解决了单台服务器存储容量有限和单台服务器并发数限制的问题 ,一个分片的不同副本不能放到同一个broker上。当主题数据量非常大的时候,一个服务器存放不了,就将数据分成两个或者多个部分,存放在多台服务器上。每个服务器上的数据,叫做一个分片
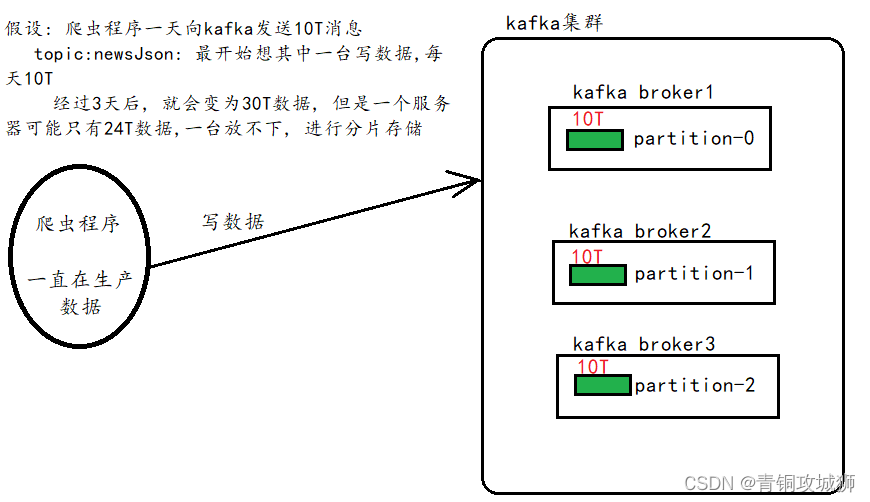
副本:副本备份机制解决了数据存储的高可用问题,当数据只保存一份的时候,有丢失的风险。为了更好的容错和容灾,将数据拷贝几份,保存到不同的机器上。
面试问题:
1. kafka的副本都有哪些作用?
2. follower副本为什么不对外提供服务?
从Kafka的大体角度上可以分为数据生产者,Kafka集群,还有就是消费者,而要保证数据的不丢失也要从这三个角度去考虑。
消息生产者保证数据不丢失:消息确认机制(ACK机制),参考值有三个:
0:无需等待来自broker的确认而继续发送下一批消息,效率最高,可靠性最低
1:收到Leader副本成功写入通知,就认为推送消息成功
-1:只有收到分区内所有副本的成功写入的通知才认为推送消息成功,效率最低,可靠性最高
//producer无需等待来自broker的确认而继续发送下一批消息。
//这种情况下数据传输效率最高,但是数据可靠性确是最低的。
properties.put(ProducerConfig.ACKS_CONFIG,"0");
//producer只要收到一个分区副本成功写入的通知就认为推送消息成功了。
//这里有一个地方需要注意,这个副本必须是leader副本。
//只有leader副本成功写入了,producer才会认为消息发送成功。
properties.put(ProducerConfig.ACKS_CONFIG,"1");
//ack=-1,简单来说就是,producer只有收到分区内所有副本的成功写入的通知才认为推送消息成功了。
properties.put(ProducerConfig.ACKS_CONFIG,"-1");
为什么消费者丢失数据?
解决方案:
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"false");
kafka在数据生产的时候,有一个数据分发策略。默认的情况使用DefaultPartitioner.class类。
public interface Partitioner extends Configurable, Closeable {
/**
* Compute the partition for the given record.
*
* @param topic The topic name
* @param key The key to partition on (or null if no key)
* @param keyBytes The serialized key to partition on( or null if no key)
* @param value The value to partition on or null
* @param valueBytes The serialized value to partition on or null
* @param cluster The current cluster metadata
*/
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster);
/**
* This is called when partitioner is closed.
*/
public void close();
}
/**
* Creates a record to be sent to a specified topic and partition
*
* @param topic The topic the record will be appended to
* @param partition The partition to which the record should be sent
* @param key The key that will be included in the record
* @param value The record contents
*/
public ProducerRecord(String topic, Integer partition, K key, V value) {
this(topic, partition, null, key, value, null);
}
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
//获取该topic的分区列表
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
//获得分区的个数
int numPartitions = partitions.size();
//如果key值为null
if (keyBytes == null) {
//如果没有指定key,那么就是轮询
// 维护一个key为topic的ConcurrentHashMap,并通过CAS操作的方式对value值执行递增+1操作
int nextValue = nextValue(topic);
//获取该topic的可用分区列表
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
if (availablePartitions.size() > 0) {
//如果可用分区大于0
// 执行求余操作,保证消息落在可用分区上
int part = Utils.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
}
else {
// 没有可用分区的话,就给出一个不可用分区
return Utils.toPositive(nextValue) % numPartitions;
}
}
else {
//不过指定了key,key肯定就不为null
// 通过计算key的hash,确定消息分区
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}
同一个分区中的数据,只能被一个消费者组中的一个消费者所消费。例如 P0分区中的数据不能被Consumer Group A中C1与C2同时消费。
消费组:一个消费组中可以包含多个消费者,properties.put(ConsumerConfig.GROUP_ID_CONFIG,“groupName”);
如果该消费组有四个消费者,主题有四个分区,那么每人一个。多个消费组可以重复消费消息。 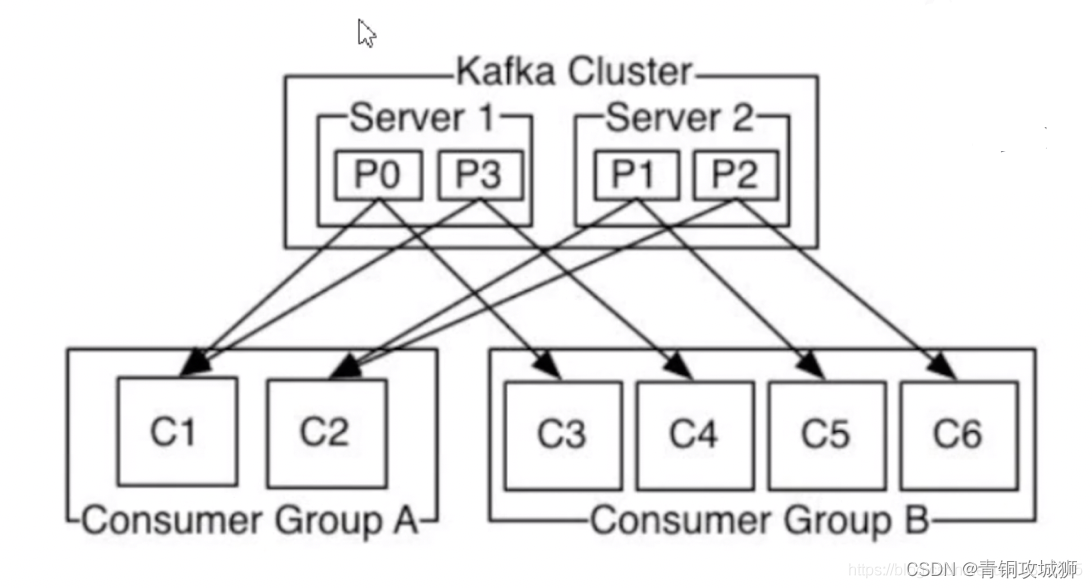
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>1.0.0</version>
</dependency>
public class ProducerDemo {
public static String topic = "test";//定义主题
public static void main(String[] args) throws Exception {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.200.20:9092,192.168.200.20:9093,192.168.200.20:9094");
//网络传输,对key和value进行序列化
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
//创建消息生产对象,需要从properties对象或者从properties文件中加载信息
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);
try {
while (true) {
//设置消息内容
String msg = "Hello," + new Random().nextInt(100);
//将消息内容封装到ProducerRecord中
ProducerRecord<String, String> record = new ProducerRecord<String, String>(topic, msg);
kafkaProducer.send(record);
System.out.println("消息发送成功:" + msg);
Thread.sleep(500);
}
}
finally {
kafkaProducer.close();
}
}
}
public class ProducerDemo {
public static String topic = "lagou";//定义主题
public static void main(String[] args) throws Exception {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.200.20:9092,192.168.200.20:9093,192.168.200.20:9094");
//网络传输,对key和value进行序列化
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
//指定组名
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test");
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<String, String>(properties);
kafkaConsumer.subscribe(Collections.singletonList(ProducerDemo.topic));// 订阅消息
while (true) {
ConsumerRecords<String, String> records = kafkaConsumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.println(String.format("topic:%s,offset:%d,消息:%s",
record.topic(), record.offset(), record.value()));
}
}
}
}
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
目录H2数据库入门以及实际开发时的使用1.H2数据库的初识1.1H2数据库介绍1.2为什么要使用嵌入式数据库?1.3嵌入式数据库对比1.3.1性能对比1.4技术选型思考2.H2数据库实战2.1H2数据库下载搭建以及部署2.1.1H2数据库的下载2.1.2数据库启动2.1.2.1windows系统可以在bin目录下执行h2.bat2.1.2.2同理可以通过cmd直接使用命令进行启动:2.1.2.3启动后控制台页面:2.1.3spring整合H2数据库2.1.3.1引入依赖文件2.1.4数据库通过file模式实际保存数据的位置2.2H2数据库操作2.2.1Mysql兼容模式2.2.2Mysql模式
一、解决痛点使用spring-kafka客户端,每次新增topic主题,都需要硬编码客户端并重新发布服务,操作麻烦耗时长。kafkaListener虽可以支持通配符消费topic,缺点是并发数需要手动改并且重启服务。对于业务逻辑相似场景,创建新主题动态监听可以用kafka-batch-starter组件二、组件能力1、新增topic名称为:auto.topic1(由于配置spring.kafka.consumer.prefix为auto,因此只有auto前缀的topic,才会被组件动态监听。)2、应用输出日志,监听到新增auto.topic1,并初始化客户端(主题刷新间隔为10s)3、发新的消
为什么需要服务网关传统的单体架构中只需要开放一个服务给客户端调用,但是微服务架构中是将一个系统拆分成多个微服务,如果没有网关,客户端只能在本地记录每个微服务的调用地址,当需要调用的微服务数量很多时,它需要了解每个服务的接口,这个工作量很大。有了网关之后,网关作为系统的唯一流量入口,封装内部系统的架构,所有请求都先经过网关,由网关将请求路由到合适的微服务。使用网关的好处1)简化客户端的工作。网关将微服务封装起来后,客户端只需同网关交互,而不必调用各个不同服务;(2)降低函数间的耦合度。一旦服务接口修改,只需修改网关的路由策略,不必修改每个调用该函数的客户端,从而减少了程序间的耦合性(3)解放开发
我发现python的细节自动完成很好RubyonRails有类似的方法描述吗? 最佳答案 有篇不错的文章"UsingVIMasacompleteRubyonRailsIDE"其中引用rails.vim.这似乎是RailsforVIM的实际标准。(不过,我还没有使用过它,但很快就会尝试。)这允许你做很多与Rails相关的任务,但对自动完成没有帮助。还有一篇"RubyAutocompleteinVim"(遗憾的是不再可用)这就是您要搜索的内容。我不知道,理解Rails的所有插件魔法和元编程的东西是否足够聪明。它至少在vim的配置中提到了
防火墙防火墙分类第一代防火墙:包过滤防火墙包过滤防火墙的缺点第二代防火墙:代理防火墙第三代防火墙:状态防火墙第四代防火墙:UTM防火墙第五代防火墙:下一代防火墙华为防火墙介绍安全策略防火墙的会话表防火墙分类第一代防火墙:包过滤防火墙属于第一代防火墙技术,在没有专用防火墙设备时,一般由路由器实现该功能。将网络上传送数据包的IP首部以及TCP/UDP首部,获取发送源的IP地址和端口号,以及目的地的IP地址和端口号,并将这些信息作为过滤条件,决定是否将该分组转发至目的地网络分组过滤的执行需要设置访问控制列表。访问控制列表也可以称为安全策略(简称策略)或安全规则(简称规则)。类似于进站检票的做法,符合
内容来自Qt样式表之QSS语法介绍-3YL的博客Qt样式表是一个可以自定义部件外观的十分强大的机制,可以用来美化部件。Qt样式表的概念、术语和语法都受到了HTML的层叠样式表(CascadingStyleSheets, CSS教程)的启发,不过与CSS不同的是,Qt样式表应用于部件的世界。类型选择器QPushButton匹配QPushButton及其子类的实例ID选择器QPushButton#okButton匹配所有objectName为okButton的QPushButton实例。 CSS常用样式1CSS文字属性注:px:相对长度单位,像素(Pixel)。pt:绝对长度单位,点(Point
简介:我们都知道在Android开发中,当我们的程序在与用户交互时,用户会得到一定的反馈,其中以对话框的形式的反馈还是比较常见的,接下来我们来介绍几种常见的对话框的基本使用。前置准备:(文章最后附有所有代码)我们首先先写一个简单的页面用于测试这几种Dialog(对话框)代码如下,比较简单,就不做解释了一、提示对话框(即最普通的对话框)首先我们给普通对话框的按钮设置一个点击事件,然后通过AlertDialog.Builder来构造一个对象,为什么不直接Dialog一个对象,是因为Dialog是一个基类,我们尽量要使用它的子类来进行实例化对象,在实例化对象的时候,需要将当前的上下文传过去,因为我这
作者:郭斌斌爱可生DBA团队成员,负责项目日常问题处理及公司平台问题排查。本文来源:原创投稿*爱可生开源社区出品,原创内容未经授权不得随意使用,转载请联系小编并注明来源。OceanBase集群界面会展示Observer的资源水位,今天简单了解一下资源水位的数值代表的含义以及关联参数现有test_1集群,只有一个sys租户Sys租户的资源配置:Cpu:2.5-5Memory:3G-3GUnit:1集群的资源水位信息以10.186.63.198为例,浅看一下cpu、内存、磁盘的含义以及相关联参数cpu:2.5/17核2.5代表observer上已经分配给租户的cpu核数,该数值是租户的MinCPU
快捷目录前言一、涉及到的相关技术简介二、具体实现过程及踩坑杂谈1.安卓手机改造成linux系统实现方案2.改造后的手机Linux中软件的安装3.手机Linux中安装MySQL5.7踩坑实录4.手机Linux中安装软件的正确方法三、Linux服务器部署前后端分离项目流程1.前提准备(安装必要软件,搭建环境):2.前后端分离项目的详细部署过程:总结前言总体概述:本篇文章隶属于“手机改造服务器部署前后端分离项目”系列专栏,该专栏将分多个板块,每个板块独立成篇来详细记录:手机(安卓)改造成个人服务器(Linux)、Linux中安装软件、配置开发环境、部署JAVA+VUE+MySQL5.7前后端分离项目