Kafka 是由 LinkedIn 公司开发的,它是一个分布式的,支持多分区、多副本,基于 Zookeeper 的分布式消息流平台,它同时也是一款开源的基于发布订阅模式的消息引擎系统。
副本(Replica),副本的数量是可以配置的,Kafka 定义了两类副本,领导者副本(Leader Replica) 和 追随者副本(Follower Replica),前者对外提供服务,后者只是被动跟随;高吞吐、低延迟:kakfa 最大的特点就是收发消息非常快,kafka 每秒可以处理几十万条消息,它的最低延迟只有几毫秒;高伸缩性: 每个主题(topic) 包含多个分区(partition),主题中的分区可以分布在不同的主机(broker)中;持久性、可靠性: Kafka 能够允许数据的持久化存储,消息被持久化到磁盘,并支持数据备份防止数据丢失,Kafka 底层的数据存储是基于 Zookeeper 存储的,Zookeeper 的数据能够持久存储;容错性: 允许集群中的节点失败,某个节点宕机,Kafka 集群能够正常工作;高并发: 支持数千个客户端同时读写。跟踪用户行为,比如你经常回去App购物,你打开App的那一刻,你的登陆信息,登陆次数都会作为消息传输到 Kafka ,当你浏览购物的时候,你的浏览信息,你的搜索指数,你的购物爱好都会作为一个个消息传递给 Kafka ,这样就可以生成报告,可以做智能推荐,购买喜好等;传递消息,应用程序向用户发送通知就是通过传递消息来实现的,这些应用组件可以生成消息,而不需要关心消息的格式,也不需要关心消息是如何发送的;用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告;以上介绍参考Kafka官方文档。
Kafka有4个核心API
1个或多个Topics中;1个或多个Topics,并处理产生的消息;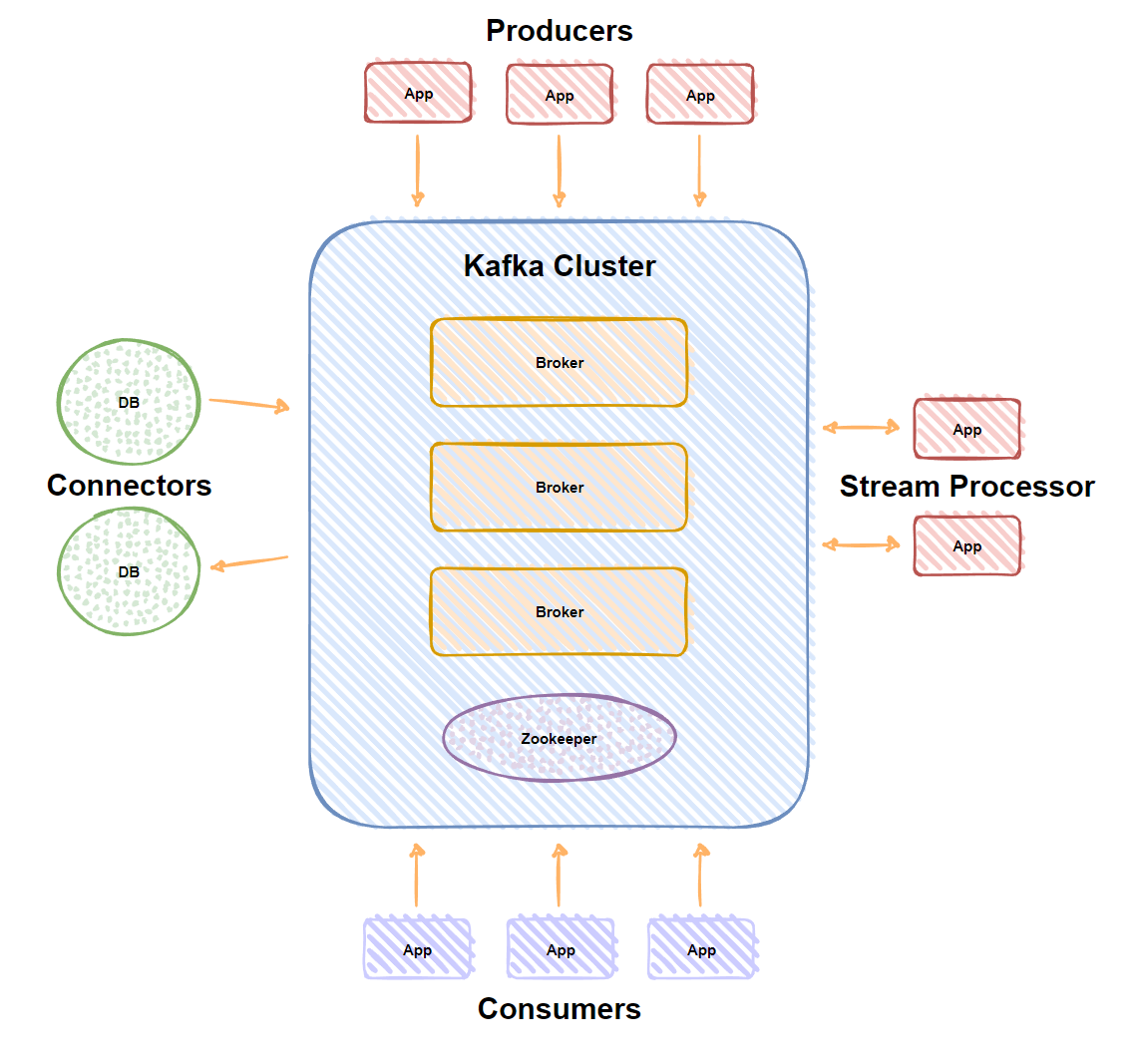
Kafka 实现了零拷贝原理来快速移动数据,避免了内核之间的切换。Kafka 可以将数据记录分批发送,从生产者到文件系统(Kafka 主题日志)到消费者,可以端到端的查看这些批次的数据。批处理能够进行更有效的数据压缩并减少 I/O 延迟,Kafka 采取顺序写入磁盘的方式,避免了随机磁盘寻址的浪费。
总结一下其实就是四个要点:
项目创建:
dependencies:

构建工具为Maven,Maven的依赖如下:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.12</artifactId>
<version>1.0.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>1.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>1.0.0</version>
</dependency>
package cn.com.codingce.module;
import java.util.Properties;
import java.util.Random;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
public class Producer {
// 定义主题
public static String topic = "codingce_test";
public static void main(String[] args) throws InterruptedException {
Properties p = new Properties();
// bootstrap.servers: kafka的地址, 多个地址用逗号分割
p.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.31.150:9092");
// acks:消息的确认机制,默认值是0. acks=0: 如果设置为0,生产者不会等待kafka的响应; acks=1: 这个配置意味着kafka会把这条消息写到本地日志文件中,但是不会等待集群中其他机器的成功响应
// acks=all: 这个配置意味着leader会等待所有的follower同步完成. 这个确保消息不会丢失, 除非kafka集群中所有机器挂掉. 这是最强的可用性保证.
p.put("acks", "all");
// retries: 配置为大于0的值的话, 客户端会在消息发送失败时重新发送.
p.put("retries", 0);
// batch.size: 当多条消息需要发送到同一个分区时,生产者会尝试合并网络请求. 这会提高client和生产者的效率.
p.put("batch.size", 16384);
// key.serializer: 键序列化,默认org.apache.kafka.common.serialization.StringDeserializer.
p.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
// value.deserializer:值序列化,默认org.apache.kafka.common.serialization.StringDeserializer.
p.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(p);
try {
do {
String msg = "后端码匠, " + new Random().nextInt(100);
ProducerRecord<String, String> record = new ProducerRecord<>(topic, msg);
kafkaProducer.send(record);
System.out.println("======消息发送成功: " + msg + " ======");
Thread.sleep(1000L);
} while (true);
} finally {
kafkaProducer.close();
}
}
}
output
======消息发送成功: 后端码匠, 97 ======
======消息发送成功: 后端码匠, 35 ======
======消息发送成功: 后端码匠, 81 ======
======消息发送成功: 后端码匠, 46 ======
======消息发送成功: 后端码匠, 62 ======
======消息发送成功: 后端码匠, 53 ======
======消息发送成功: 后端码匠, 42 ======
======消息发送成功: 后端码匠, 56 ======
======消息发送成功: 后端码匠, 99 ======
======消息发送成功: 后端码匠, 46 ======
======消息发送成功: 后端码匠, 49 ======
======消息发送成功: 后端码匠, 35 ======
======消息发送成功: 后端码匠, 17 ======
======消息发送成功: 后端码匠, 78 ======
======消息发送成功: 后端码匠, 66 ======
======消息发送成功: 后端码匠, 4 ======
======消息发送成功: 后端码匠, 9 ======
======消息发送成功: 后端码匠, 69 ======
======消息发送成功: 后端码匠, 52 ======
======消息发送成功: 后端码匠, 2 ======
======消息发送成功: 后端码匠, 8 ======
======消息发送成功: 后端码匠, 86 ======
======消息发送成功: 后端码匠, 12 ======
======消息发送成功: 后端码匠, 67 ======
======消息发送成功: 后端码匠, 91 ======
======消息发送成功: 后端码匠, 8 ======
======消息发送成功: 后端码匠, 56 ======
======消息发送成功: 后端码匠, 89 ======
======消息发送成功: 后端码匠, 37 ======
======消息发送成功: 后端码匠, 39 ======
======消息发送成功: 后端码匠, 71 ======
package cn.com.codingce.module;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.util.Collections;
import java.util.Properties;
public class Consumer {
private static final String GROUPID = "codingce_consumer_a";
public static void main(String[] args) {
Properties p = new Properties();
// bootstrap.servers: kafka的地址, 多个地址用逗号分割
p.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.31.150:9092");
// 消费者所属的分组id, 组名 不同组名可以重复消费.例如你先使用了组名A消费了Kafka的1000条数据, 但是你还想再次进行消费这1000条数据,
// 并且不想重新去产生, 那么这里你只需要更改组名就可以重复消费了.
p.put(ConsumerConfig.GROUP_ID_CONFIG, GROUPID);
// 是否自动提交, 默认为true.
p.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
// 从poll(拉)的回话处理时长
p.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
// 超时时间
p.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, "30000");
// 一次最大拉取的条数
p.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 1000);
// 消费规则, 默认earliest
p.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
// key.serializer: 键序列化, 默认org.apache.kafka.common.serialization.StringDeserializer.
p.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
// value.deserializer:值序列化, 默认org.apache.kafka.common.serialization.StringDeserializer.
p.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(p);
// 订阅消息
kafkaConsumer.subscribe(Collections.singletonList(Producer.topic));
do {
// 订阅之后, 再从kafka中拉取数据
ConsumerRecords<String, String> records = kafkaConsumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("-----topic:%s, offset:%d, 消息:%s-----\n", record.topic(), record.offset(), record.value());
}
} while (true);
}
}
output
-----topic:codingce_test, offset:289, 消息:后端码匠, 97-----
-----topic:codingce_test, offset:290, 消息:后端码匠, 35-----
-----topic:codingce_test, offset:291, 消息:后端码匠, 81-----
-----topic:codingce_test, offset:292, 消息:后端码匠, 46-----
-----topic:codingce_test, offset:293, 消息:后端码匠, 62-----
-----topic:codingce_test, offset:294, 消息:后端码匠, 53-----
-----topic:codingce_test, offset:295, 消息:后端码匠, 42-----
-----topic:codingce_test, offset:296, 消息:后端码匠, 56-----
-----topic:codingce_test, offset:297, 消息:后端码匠, 99-----
-----topic:codingce_test, offset:298, 消息:后端码匠, 46-----
-----topic:codingce_test, offset:299, 消息:后端码匠, 49-----
-----topic:codingce_test, offset:300, 消息:后端码匠, 35-----
-----topic:codingce_test, offset:301, 消息:后端码匠, 17-----
-----topic:codingce_test, offset:302, 消息:后端码匠, 78-----
-----topic:codingce_test, offset:303, 消息:后端码匠, 66-----
-----topic:codingce_test, offset:304, 消息:后端码匠, 4-----
-----topic:codingce_test, offset:305, 消息:后端码匠, 9-----
-----topic:codingce_test, offset:306, 消息:后端码匠, 69-----
-----topic:codingce_test, offset:307, 消息:后端码匠, 52-----
-----topic:codingce_test, offset:308, 消息:后端码匠, 2-----
-----topic:codingce_test, offset:309, 消息:后端码匠, 8-----
-----topic:codingce_test, offset:310, 消息:后端码匠, 86-----
-----topic:codingce_test, offset:311, 消息:后端码匠, 12-----
-----topic:codingce_test, offset:312, 消息:后端码匠, 67-----
-----topic:codingce_test, offset:313, 消息:后端码匠, 91-----
-----topic:codingce_test, offset:314, 消息:后端码匠, 8-----
-----topic:codingce_test, offset:315, 消息:后端码匠, 56-----
-----topic:codingce_test, offset:316, 消息:后端码匠, 89-----
-----topic:codingce_test, offset:317, 消息:后端码匠, 37-----
-----topic:codingce_test, offset:318, 消息:后端码匠, 39-----
-----topic:codingce_test, offset:319, 消息:后端码匠, 71-----
本次采用Docker 搭建的单机 Kafka、Zookeeper,Kafka介绍参考官方文档:http://kafka.apache.org/intro
项目地址:https://gitee.com/codingce/codingce-leetcode
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
您如何在Rails中的实时服务器上进行有效调试,无论是在测试版/生产服务器上?我试过直接在服务器上修改文件,然后重启应用,但是修改好像没有生效,或者需要很长时间(缓存?)我也试过在本地做“脚本/服务器生产”,但是那很慢另一种选择是编码和部署,但效率很低。有人对他们如何有效地做到这一点有任何见解吗? 最佳答案 我会回答你的问题,即使我不同意这种热修补服务器代码的方式:)首先,你真的确定你已经重启了服务器吗?您可以通过跟踪日志文件来检查它。您更改的代码显示的View可能会被缓存。缓存页面位于tmp/cache文件夹下。您可以尝试手动删除
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我只想对我一直在思考的这个问题有其他意见,例如我有classuser_controller和classuserclassUserattr_accessor:name,:usernameendclassUserController//dosomethingaboutanythingaboutusersend问题是我的User类中是否应该有逻辑user=User.newuser.do_something(user1)oritshouldbeuser_controller=UserController.newuser_controller.do_something(user1,user2)我
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_