
我们在使用kubernetes的客户端k8s.io/client-go 进行开发的时候,比如写个CRD的operator, 经常会用到队列这种数据结构。并且很多时候,我们在做服务器端后台开发的时候,需要用到任务队列,进行任务的异步处理与任务管理。k8s.io/client-go中的workqueue包里面提供了三种常用的队列。今天给大家演示下三种队列的使用方法与相应的使用场景,大家在工作中可以直接copy这些代码,加速自己项目的开发。这三个队列的关系如下图所示:
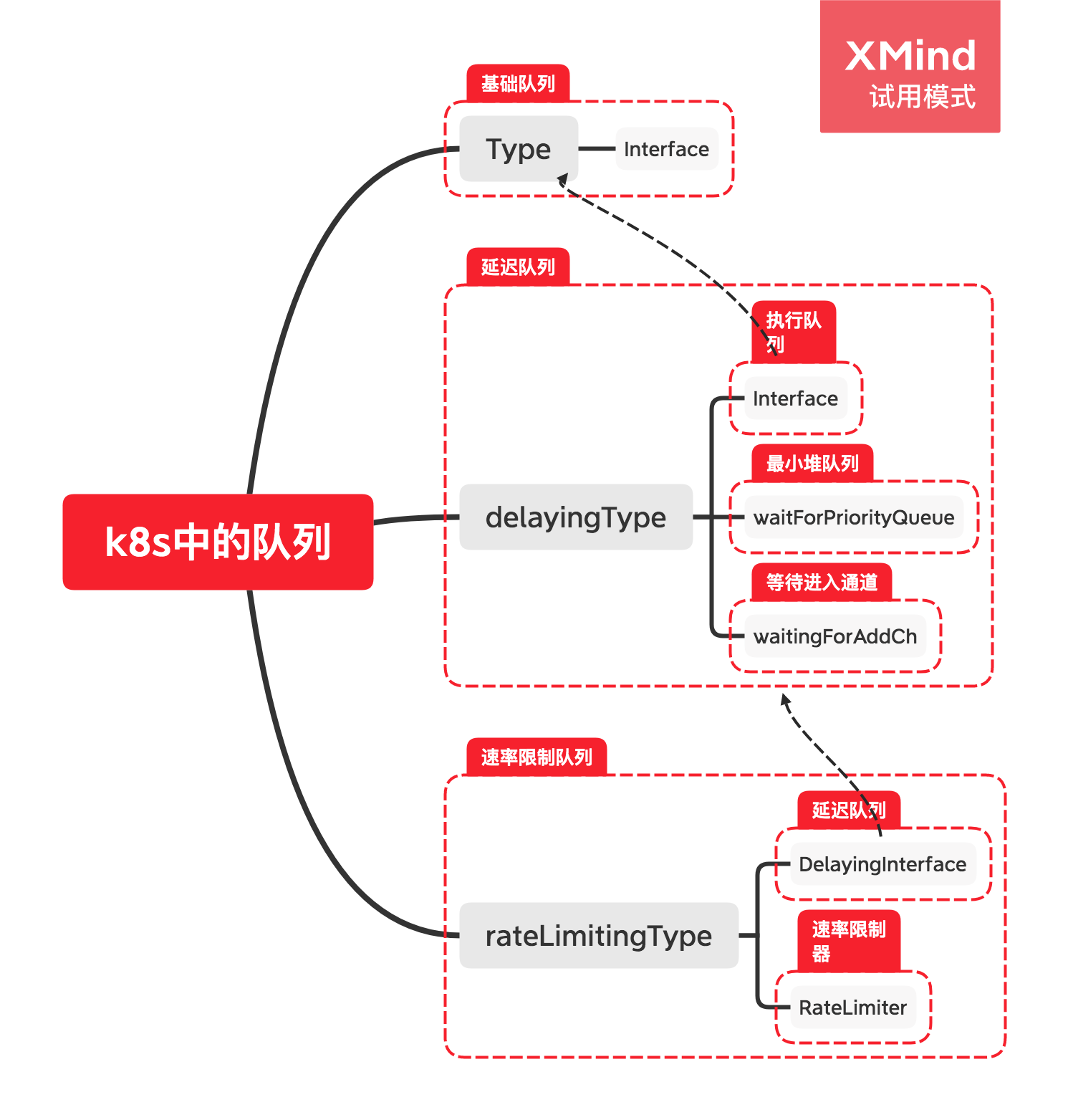
k8s队列关系
type (基础队列)
下面给出了数据结构,其中dirty,processing两个集合分别存储的是需要处理的任务和正在处理的任务,queue[]t按序存放的是所有添加的任务。这三个属性的关系很有意思,dirty用于快速判断queue中是否存在相应的任务,这样有以下两个用处:
1. 在Add的时候,可以防止重复添加。(代码查看:https://github.com/kubernetes/client-go/blob/master/util/workqueue/queue.go#L120)。
2.由于在任务完成后要调用Done方法,把任务从processing集合中删除掉,那么如果在完成前(即调用Done方法之前),把任务再次添加进dirty集合,那么在完成调用Done方法的时候,会再次把任务重新添加进queue队列,进行处理(代码查看:https://github.com/kubernetes/client-go/blob/master/util/workqueue/queue.go#L180)。
而processing集合存放的是当前正在执行的任务,它的作用有以下几点。
1.在Add的时候,如果任务正在处理,就直接返回。这样在任务调用Done的时候,由于dirty集合中有,会把这个任务再次放在队列的尾部。(代码查看:https://github.com/kubernetes/client-go/blob/master/util/workqueue/queue.go#L120)。
2.用于判断队列中是否还有任务正在执行,这样在shutdown的时候,可以有的放矢。(代码查看:https://github.com/kubernetes/client-go/blob/master/util/workqueue/queue.go#L221)。
整个queue队列工作模式是,你的工作线程通过Get方法从队列中获取任务(如果队列长度为0,需要q.cond.Wait()),然后处理任务(你自己的业务逻辑),处理完后调用Done方法,表明任务完成了,同时调用q.cond.Signal(),唤醒等待的工作线程。
type Type struct {
// queue defines the order in which we will work on items. Every
// element of queue should be in the dirty set and not in the
// processing set.
queue []t
// dirty defines all of the items that need to be processed.
dirty set
// Things that are currently being processed are in the processing set.
// These things may be simultaneously in the dirty set. When we finish
// processing something and remove it from this set, we'll check if
// it's in the dirty set, and if so, add it to the queue.
processing set
cond *sync.Cond
shuttingDown bool
drain bool
metrics queueMetrics
unfinishedWorkUpdatePeriod time.Duration
clock clock.WithTicker
}这个延迟队列继承了上面的基础队列,同时提供了addAfter函数,实现根据延迟时间把元素增加进延迟队列。其中的waitForPriorityQueue实现了一个用于waitFor元素的优先级队列,其实就是一个最小堆。
func (q *delayingType) AddAfter(item interface{}, duration time.Duration)这个函数(代码https://github.com/kubernetes/client-go/blob/master/util/workqueue/delaying_queue.go#L162)。
当duration为0,就直接通过q.add放到它继承的基础执行队列里面,如果有延迟值,就放在q.waitingForAddCh通道里面,等待readyAt时机成熟,再放到队列中。那这个通道里面的元素当readyAt后,如何加入到基础执行队列?下面的截图给出了答案,便是启动的ret.waitingLoop协程。这个方法的具体代码(https://github.com/kubernetes/client-go/blob/master/util/workqueue/delaying_queue.go#L189),具体思路就是利用了上面的waitForPriorityQueue最小堆,还有等待加入队列通道q.waitingForAddCh,大家可以看看给出的具体代码,大致的思想就会了解。
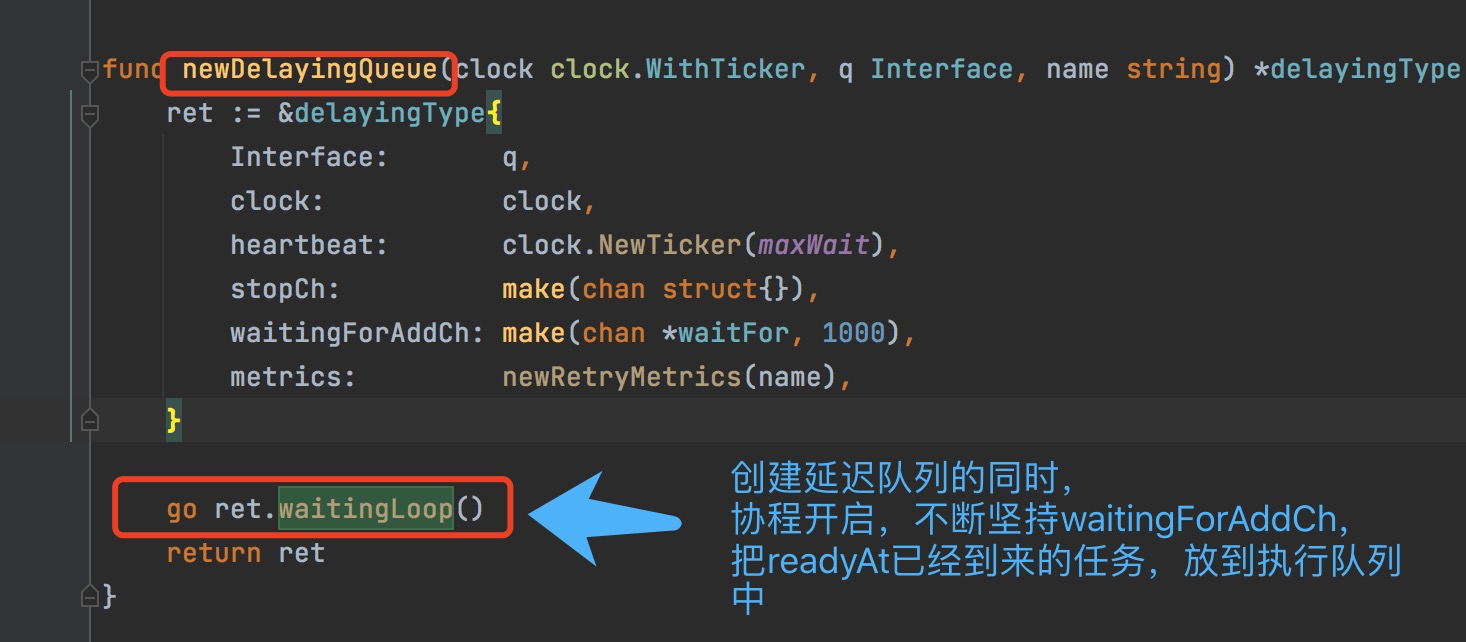
创建延迟队列
// delayingType wraps an Interface and provides delayed re-enquing
type delayingType struct {
Interface
// clock tracks time for delayed firing
clock clock.Clock
// stopCh lets us signal a shutdown to the waiting loop
stopCh chan struct{}
// stopOnce guarantees we only signal shutdown a single time
stopOnce sync.Once
// heartbeat ensures we wait no more than maxWait before firing
heartbeat clock.Ticker
// waitingForAddCh is a buffered channel that feeds waitingForAdd
waitingForAddCh chan *waitFor
// metrics counts the number of retries
metrics retryMetrics
}
// waitFor holds the data to add and the time it should be added
type waitFor struct {
data t
readyAt time.Time
// index in the priority queue (heap)
index int
}
type waitForPriorityQueue []*waitFor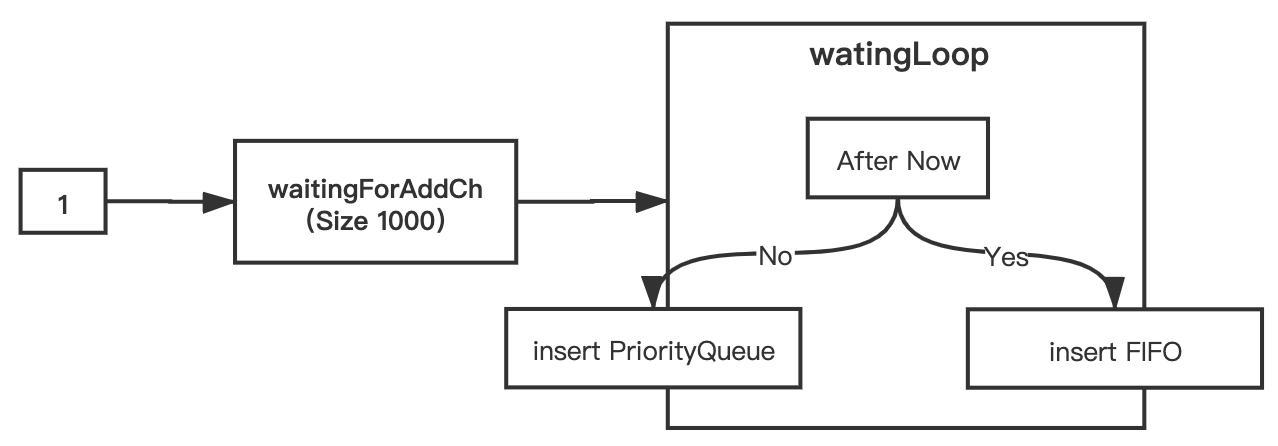
元素添加逻辑
下面是测试代码,大家可以看看如何创建延迟队列,还有添加任务。
下面的代码,在延迟队列里面增加了一个字符串"foo",延迟执行的时间是50毫秒。然后差不多50毫秒后,延迟队列长度为0
fakeClock := testingclock.NewFakeClock(time.Now())
q := NewDelayingQueueWithCustomClock(fakeClock, "")
first := "foo"
q.AddAfter(first, 50*time.Millisecond)
if err := waitForWaitingQueueToFill(q); err != nil {
t.Fatalf("unexpected err: %v", err)
}
if q.Len() != 0 {
t.Errorf("should not have added")
}
fakeClock.Step(60 * time.Millisecond)
if err := waitForAdded(q, 1); err != nil {
t.Errorf("should have added")
}
item, _ := q.Get()
q.Done(item)
// step past the next heartbeat
fakeClock.Step(10 * time.Second)
err := wait.Poll(1*time.Millisecond, 30*time.Millisecond, func() (done bool, err error) {
if q.Len() > 0 {
return false, fmt.Errorf("added to queue")
}
return false, nil
})
if err != wait.ErrWaitTimeout {
t.Errorf("expected timeout, got: %v", err)
}
if q.Len() != 0 {
t.Errorf("should not have added")
}
func waitForAdded(q DelayingInterface, depth int) error {
return wait.Poll(1*time.Millisecond, 10*time.Second, func() (done bool, err error) {
if q.Len() == depth {
return true, nil
}
return false, nil
})
}
func waitForWaitingQueueToFill(q DelayingInterface) error {
return wait.Poll(1*time.Millisecond, 10*time.Second, func() (done bool, err error) {
if len(q.(*delayingType).waitingForAddCh) == 0 {
return true, nil
}
return false, nil
})
}限速队列是利用延迟队列的延迟特性,延迟某个元素的插入FIFO队列的时间,达到限速的目的
workqueue包下面的rateLimiter有多种,下面的代码显示的是
ItemExponentialFailureRateLimiter(排队指数算法)。
type ItemExponentialFailureRateLimiter struct {
failuresLock sync.Mutex
failures map[interface{}]int
baseDelay time.Duration
maxDelay time.Duration
}它有个基础延迟时间,加入到延迟队列后,被执行的延迟时间的计算公式是如下所示。另外它还有个最大延迟时间的参数。
func (r *ItemExponentialFailureRateLimiter) When(item interface{}) time.Duration {
r.failuresLock.Lock()
defer r.failuresLock.Unlock()
exp := r.failures[item]
r.failures[item] = r.failures[item] + 1
// The backoff is capped such that 'calculated' value never overflows.
backoff := float64(r.baseDelay.Nanoseconds()) * math.Pow(2, float64(exp))
if backoff > math.MaxInt64 {
return r.maxDelay
}
calculated := time.Duration(backoff)
if calculated > r.maxDelay {
return r.maxDelay
}
return calculated
}下面的测试代码,显示的是创建了一个1毫秒基础延迟,最大1秒的延迟队列。它在延迟队列中增加了
一个"one"字符串,由于是第一次添加,所以基于上面的公式它的延迟时间是1毫秒,再次增加"one"
后,它的延迟时间是2*1毫秒,即2毫秒,对于增加的字符串"two"也是一样,当我们调用forget
方法后ItemExponentialFailureRateLimiter中的计数器会重置,再次增加"one"字符串后,
它的延迟时间又变成了1毫秒
limiter := NewItemExponentialFailureRateLimiter(1*time.Millisecond, 1*time.Second)
queue := NewRateLimitingQueue(limiter).(*rateLimitingType)
fakeClock := testingclock.NewFakeClock(time.Now())
delayingQueue := &delayingType{
Interface: New(),
clock: fakeClock,
heartbeat: fakeClock.NewTicker(maxWait),
stopCh: make(chan struct{}),
waitingForAddCh: make(chan *waitFor, 1000),
metrics: newRetryMetrics(""),
}
queue.DelayingInterface = delayingQueue
queue.AddRateLimited("one")
waitEntry := <-delayingQueue.waitingForAddCh
if e, a := 1*time.Millisecond, waitEntry.readyAt.Sub(fakeClock.Now()); e != a {
t.Errorf("expected %v, got %v", e, a)
}
queue.AddRateLimited("one")
waitEntry = <-delayingQueue.waitingForAddCh
if e, a := 2*time.Millisecond, waitEntry.readyAt.Sub(fakeClock.Now()); e != a {
t.Errorf("expected %v, got %v", e, a)
}
if e, a := 2, queue.NumRequeues("one"); e != a {
t.Errorf("expected %v, got %v", e, a)
}
queue.AddRateLimited("two")
waitEntry = <-delayingQueue.waitingForAddCh
if e, a := 1*time.Millisecond, waitEntry.readyAt.Sub(fakeClock.Now()); e != a {
t.Errorf("expected %v, got %v", e, a)
}
queue.AddRateLimited("two")
waitEntry = <-delayingQueue.waitingForAddCh
if e, a := 2*time.Millisecond, waitEntry.readyAt.Sub(fakeClock.Now()); e != a {
t.Errorf("expected %v, got %v", e, a)
}
queue.Forget("one")
if e, a := 0, queue.NumRequeues("one"); e != a {
t.Errorf("expected %v, got %v", e, a)
}
queue.AddRateLimited("one")
waitEntry = <-delayingQueue.waitingForAddCh
if e, a := 1*time.Millisecond, waitEntry.readyAt.Sub(fakeClock.Now()); e != a {
t.Errorf("expected %v, got %v", e, a)
}此外这个包下面还有ItemFastSlowRateLimiter,BucketRateLimiter等。具体的大家可以查看default_rate_limiters.go(代码:https://github.com/kubernetes/client-go/blob/master/util/workqueue/default_rate_limiters.go)。
延迟队列场景:
常见的打车软件都会有匹配司机,这个可以用延迟队列来实现;处理已提交订单超过30分钟未付款失效的订单,延迟队列可以很好的解决;又或者注册了超过30天的用户,发短信撩动等。
比如使用DelayQueue保存当天将会执行的任务和执行时间,或是需要设置一个倒计时,倒计时结束后更新数据库中某个表状态
限速队列场景:
比如限制数据队列的写入速度。
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
我想用ruby编写一个小的命令行实用程序并将其作为gem分发。我知道安装后,Guard、Sass和Thor等某些gem可以从命令行自行运行。为了让gem像二进制文件一样可用,我需要在我的gemspec中指定什么。 最佳答案 Gem::Specification.newdo|s|...s.executable='name_of_executable'...endhttp://docs.rubygems.org/read/chapter/20 关于ruby-在Ruby中编写命令行实用程序
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
我有一个涉及多台机器、消息队列和事务的问题。因此,例如用户点击网页,点击将消息发送到另一台机器,该机器将付款添加到用户的帐户。每秒可能有数千次点击。事务的所有方面都应该是容错的。我以前从未遇到过这样的事情,但一些阅读表明这是一个众所周知的问题。所以我的问题。我假设安全的方法是使用两阶段提交,但协议(protocol)是阻塞的,所以我不会获得所需的性能,我是否正确?我通常写Ruby,但似乎Redis之类的数据库和Rescue、RabbitMQ等消息队列系统对我的帮助不大——即使我实现某种两阶段提交,如果Redis崩溃,数据也会丢失,因为它本质上只是内存。所有这些让我开始关注erlang和
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
嗨~大家好,这里是可莉!今天给大家带来的是7个C语言的经典基础代码~那一起往下看下去把【程序一】打印100到200之间的素数#includeintmain(){ inti; for(i=100;i 【程序二】输出乘法口诀表#includeintmain(){inti;for(i=1;i 【程序三】判断1000年---2000年之间的闰年#includeintmain(){intyear;for(year=1000;year 【程序四】给定两个整形变量的值,将两个值的内容进行交换。这里提供两种方法来进行交换,第一种为创建临时变量来进行交换,第二种是不创建临时变量而直接进行交换。1.创建临时变量来
是否可以让这段代码更紧凑?我在这里错过了什么吗?ifvaluemax_ratemax_rateelsevalueend 最佳答案 这里有一些完全不同的东西:[min_rate,value,max_rate].sort[1] 关于ruby-如何更优雅地记下这三种情况?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/13309740/
是否有self验证的问题列表。看着那个,我可以确定我知道。我应该复习一下。在学习的过程中,我列了一个这样的list,但它只包含我在某处听说过的项目。我需要一段时间才能找到新的东西。 最佳答案 以下是针对ruby和Rails的一些测试列表。证书名称:RubyonRails谁提供:oDeskIncorporation认证费用:免费网站:https://www.odesk.com/tests/985?pos=0证书名称:RubyonRails提供者:Techgig.com(TimesBusinessSolutionsLimited(T
我有一个将某些事件写入队列的Rails3应用。现在我想在服务器上创建一个服务,每x秒轮询一次队列,并按计划执行其他任务。除了创建ruby脚本并通过cron作业运行它之外,还有其他稳定的替代方案吗? 最佳答案 尽管启动基于Rails的持久任务是一种选择,但您可能希望查看更有序的系统,例如delayed_job或Starling管理您的工作量。我建议不要在cron中运行某些东西,因为启动整个Rails堆栈的开销可能很大。每隔几秒运行一次它是不切实际的,因为Rails上的启动时间通常为5-15秒,具体取决于您的硬件。不过,每天这样做几
关闭。这个问题是off-topic.它目前不接受答案。想改进这个问题吗?Updatethequestion所以它是on-topic用于堆栈溢出。关闭11年前。Improvethisquestion我不经常使用ruby-通常它加起来相当于每两个月或更长时间编写一次脚本。我的大部分编程都是使用C++进行的,这与ruby有很大不同。由于我与ruby之间的差距如此之大,我总是忘记语言的基本方面(比如解析文本文件和其他简单的东西)。我想每天练习一些基本的东西,我想知道是否有一些我可以订阅的网站,并且会向我发送当天的Ruby问题或类似的东西。有人知道这样的站点/Internet服务吗?