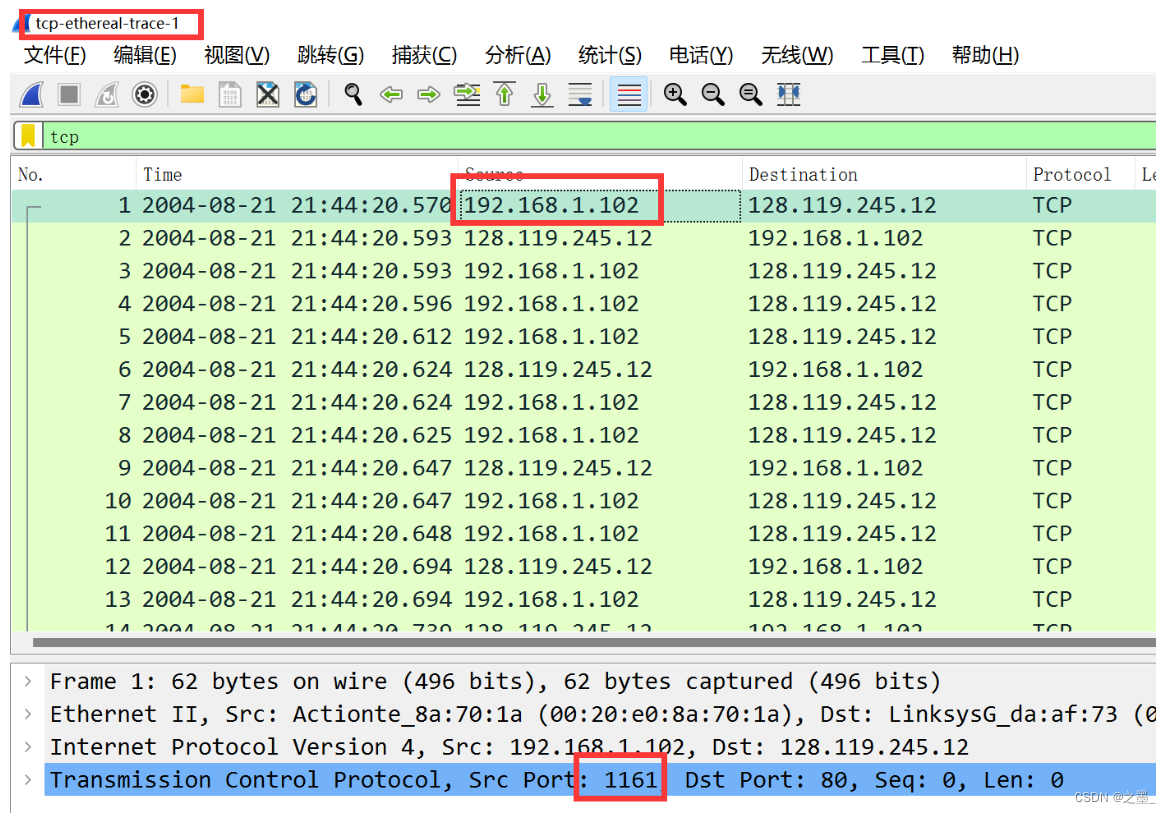
根据数据包中的tcp-ethereal-trace-1,其源IP地址为 192.168.1.102 192.168.1.102 192.168.1.102,端口号为 1162 1162 1162。
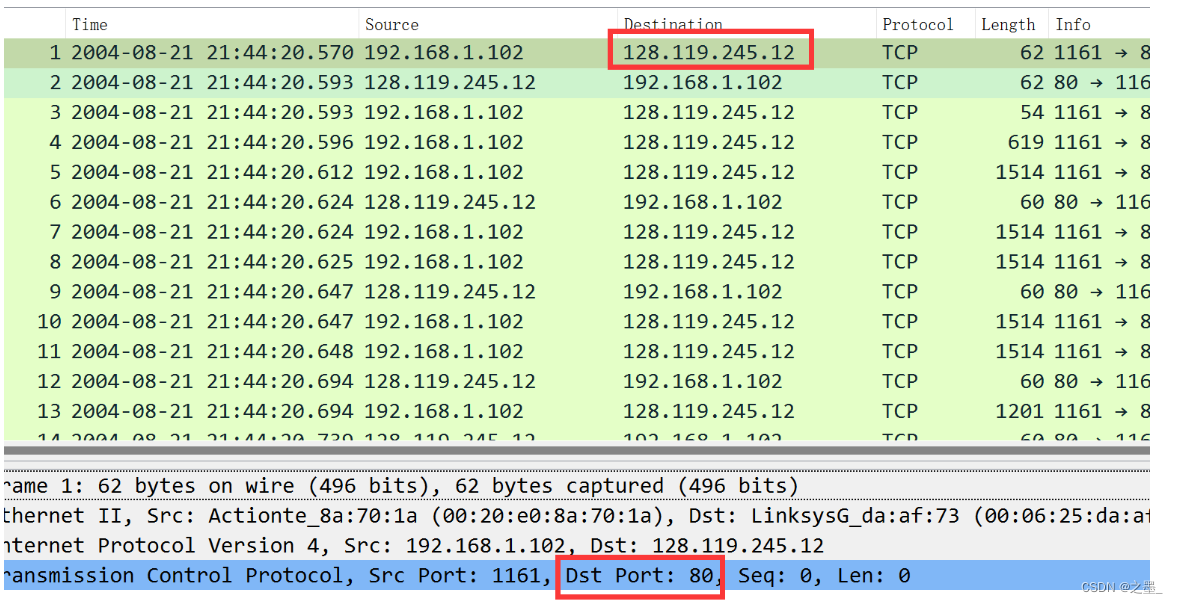
What is the IP address and TCP port number used by your client computer (source) to transfer the file to gaia.cs.umass.edu?
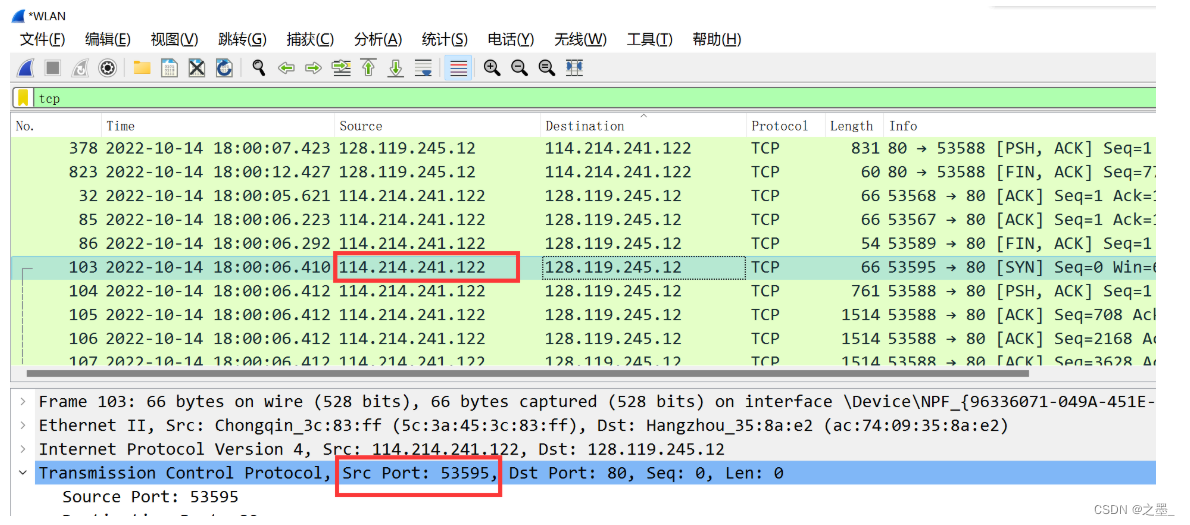
我的客户端IP地址为 114.214.241.122 114.214.241.122 114.214.241.122,端口号为 53595 53595 53595。
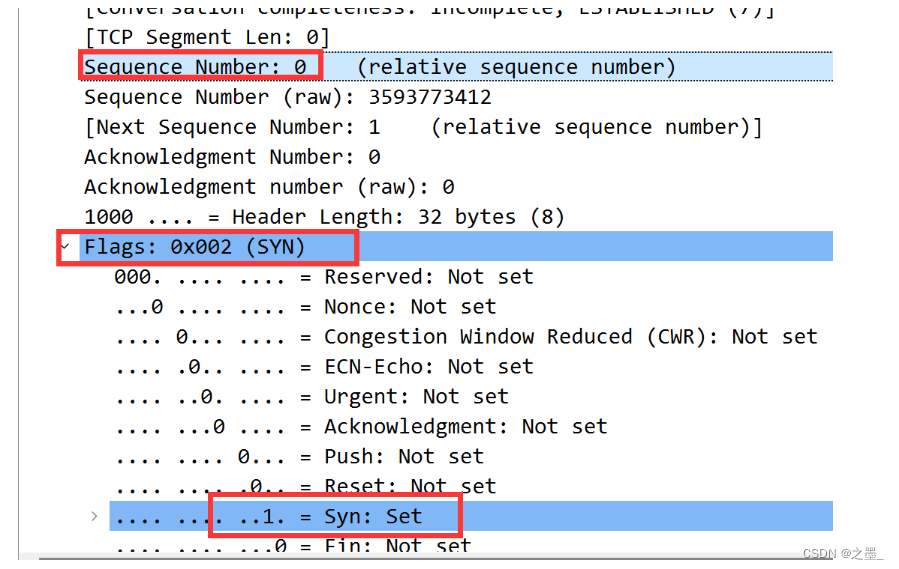
sequence number为 0 0 0,通过设置Flags为 0 0 0x 002 002 002,即Syn位设为 1 1 1。
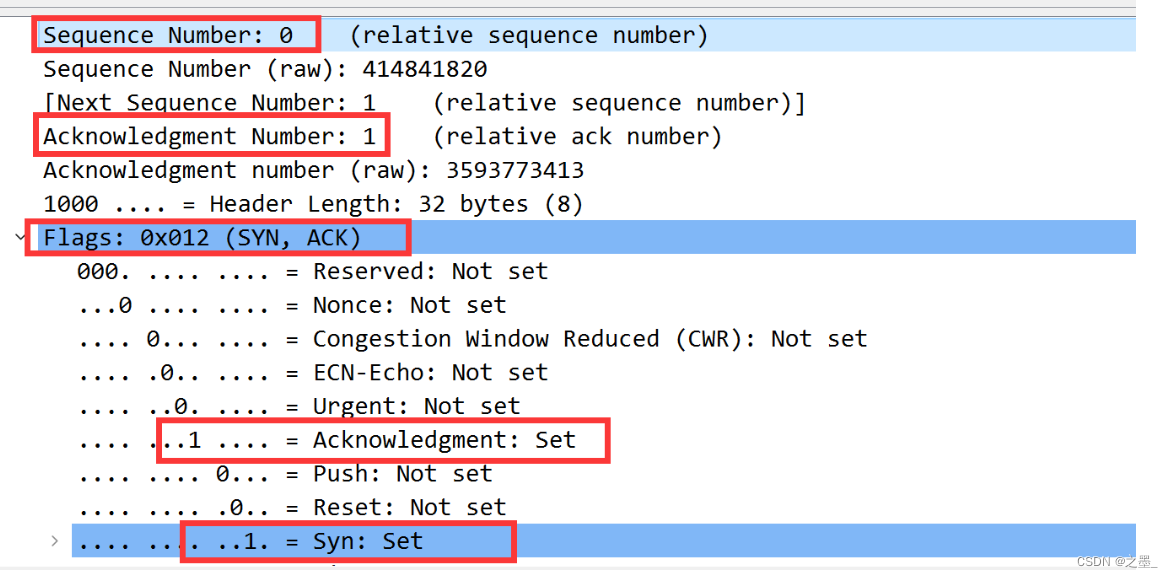
sequence number为
0
0
0,Acknowledgement number为
1
1
1,通过设置Flags为
0
0
0x
012
012
012,即Syn及Acknowledgment位均设为
1
1
1。
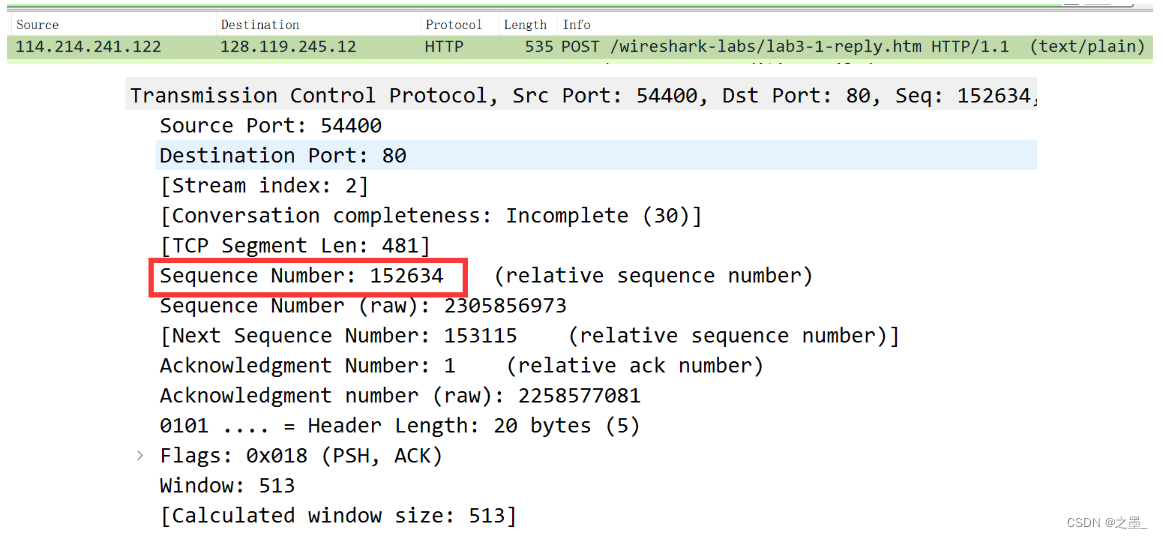
sequence number为 152634 152634 152634。
Consider the TCP segment containing the HTTP POST as the first segment in the TCP connection.
What are the sequence numbers of the first six segments in the TCP connection (including the segment containing the HTTP POST)?
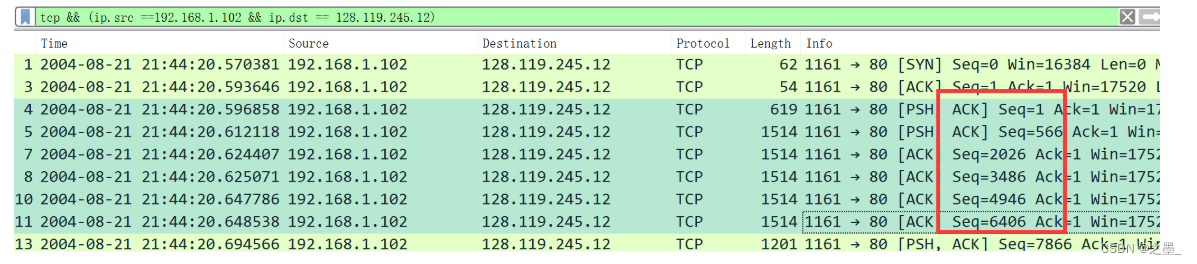
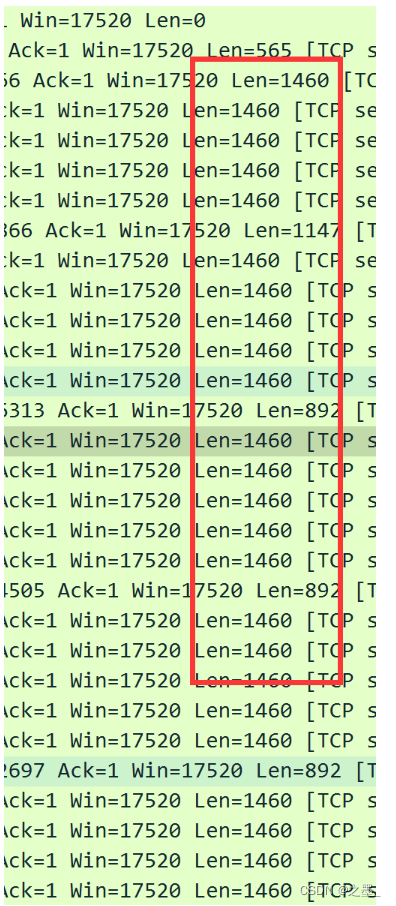
序号分别为 1 、 566 、 2026 、 3486 、 4946 、 6406 1、566、2026、3486、4946、6406 1、566、2026、3486、4946、6406。
At what time was each segment sent?
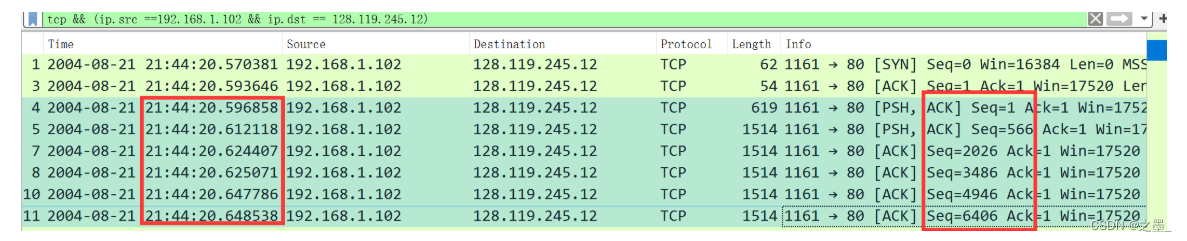
发送时间分别是 0.596858 、 0.612118 、 0.624407 、 0.625071 、 0.647786 、 0.648538 0.596858、0.612118、0.624407、0.625071、0.647786、0.648538 0.596858、0.612118、0.624407、0.625071、0.647786、0.648538.
When was the ACK for each segment received?
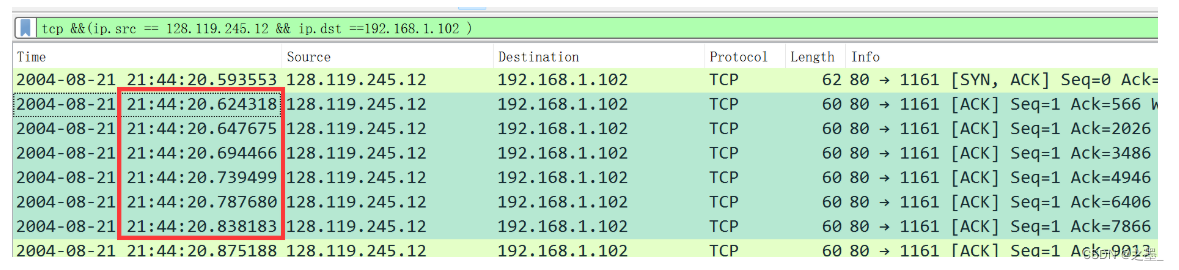
接收时间分别是 0.624318 、 0.647675 、 0.694466 、 0.739499 、 0.787680 、 0.838183 0.624318、0.647675、0.694466、0.739499、0.787680、0.838183 0.624318、0.647675、0.694466、0.739499、0.787680、0.838183.
Given the difference between when each TCP segment was sent, and when its acknowledgement was received, what is the RTT value for each of the six segments?
RTT分别为 0.027460 、 0.035557 、 0.070059 、 0.114428 、 0.139894 、 0.189645 0.027460、0.035557 、0.070059、0.114428、0.1 39894、0.1 89645 0.027460、0.035557、0.070059、0.114428、0.139894、0.189645。
What is the EstimatedRTT value (see Section 3.5.3, page 242 in text) after the receipt of each ACK?
根据公式 E s t i m a t e d R T T = ( 1 − a ) × E s t i m a t e d R T T + a × S a m p l e R T T , a = 0.125 EstimatedRTT = (1 - a) × EstimatedRTT + a × SampleRTT,a=0.125 EstimatedRTT=(1−a)×EstimatedRTT+a×SampleRTT,a=0.125
EstimatedRTT分别为
0.027460
0.028472125
=
0.875
∗
0.027460
+
0.125
∗
0.035557
0.033670484
=
0.875
∗
0.028472125
+
0.125
∗
0.070059
0.043765174
=
0.875
∗
0.033670484
+
0.125
∗
0.114428
0.055781277
=
0.875
∗
0.043765174
+
0.125
∗
0.139894
0.072514242
=
0.875
∗
0.055781277
+
0.125
∗
0.189645
\begin{aligned} &0.027460\\ &0.028472125=0.875 * 0.027460 + 0.125 * 0.035557\\ &0.033670484=0.875 * 0.028472125 + 0.125 * 0.070059 \\ &0.043765174=0.875 * 0.033670484 + 0.125 * 0.114428\\ &0.055781277=0.875 * 0.043765174 + 0.125 * 0.139894\\ &0.072514242=0.875 * 0.055781277 + 0.125 * 0.189645 \end{aligned}
0.0274600.028472125=0.875∗0.027460+0.125∗0.0355570.033670484=0.875∗0.028472125+0.125∗0.0700590.043765174=0.875∗0.033670484+0.125∗0.1144280.055781277=0.875∗0.043765174+0.125∗0.1398940.072514242=0.875∗0.055781277+0.125∗0.189645
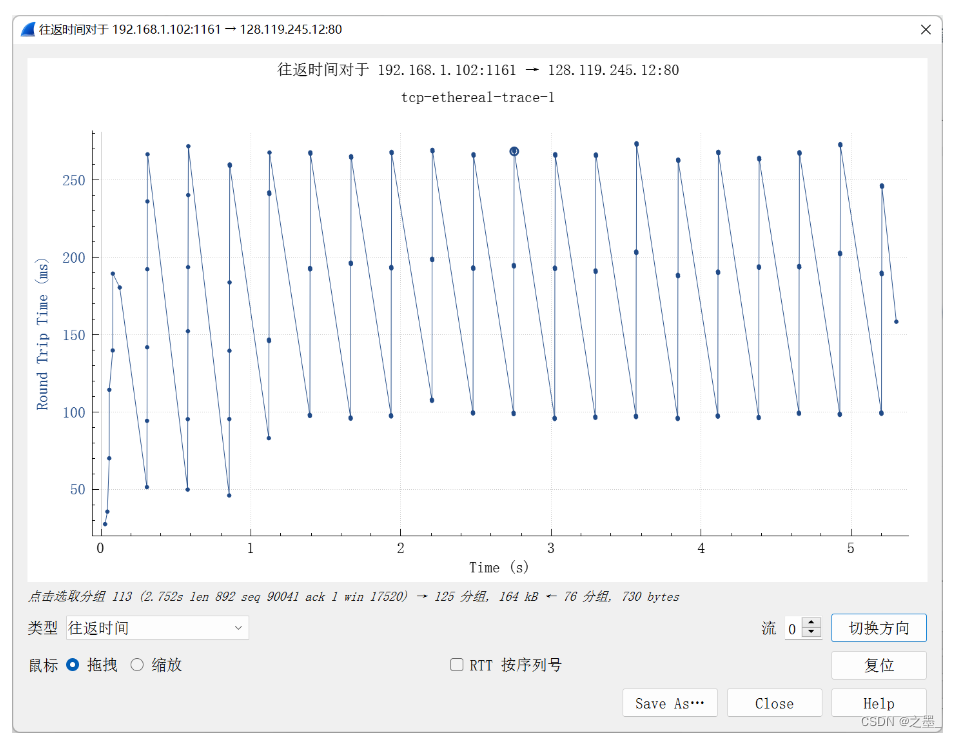
Assume that the value of the EstimatedRTT is equal to the measured RTT for the first segment, and then is computed using the EstimatedRTT equation on page 242 for all subsequent segments.
Note: Wireshark has a nice feature that allows you to plot the RTT for each of the TCP segments sent. Select a TCP segment in the “listing of captured packets” window that is being sent from the client to the gaia.cs.umass.edu server. Then select: Statistics->TCP Stream Graph->Round Trip Time Graph.

长度分别为 565 、 1460 、 1460 、 1460 、 1460 、 1460 565、1460、1460、1460、1460、1460 565、1460、1460、1460、1460、1460。
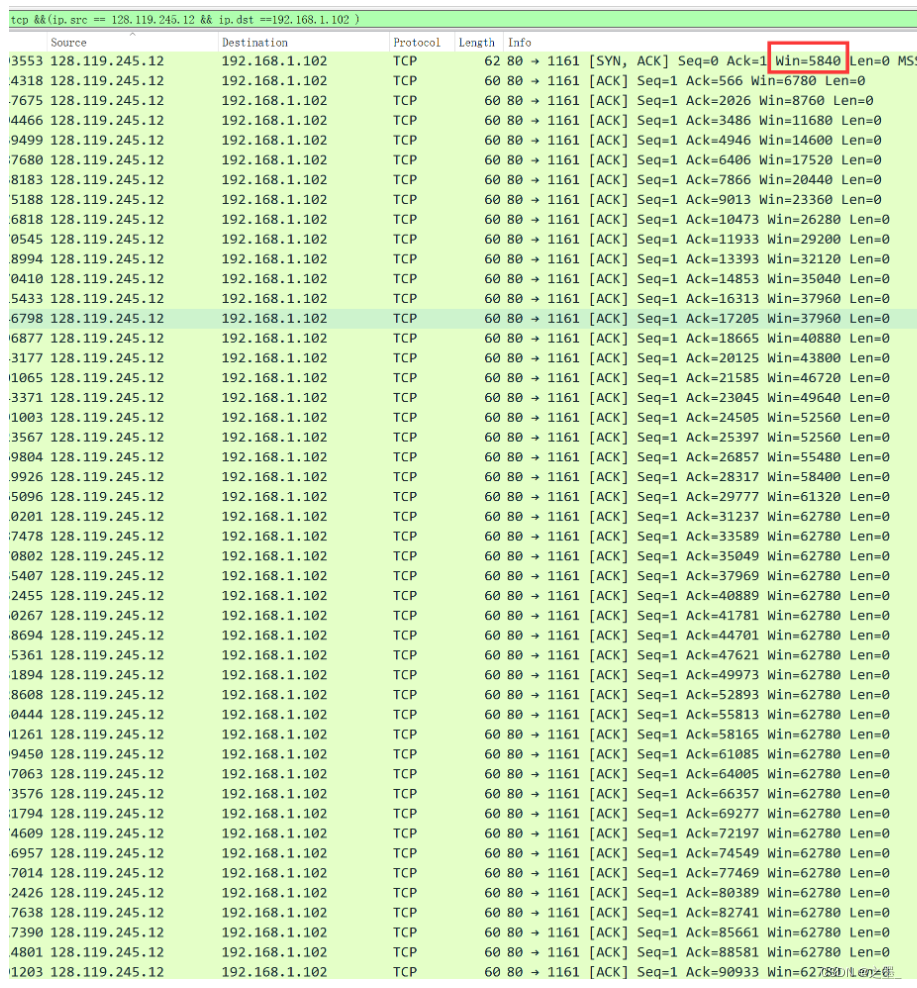
最小为 5840 5840 5840,后随时间呈增大趋势,缓存空间充足,不会使发送方受限制。
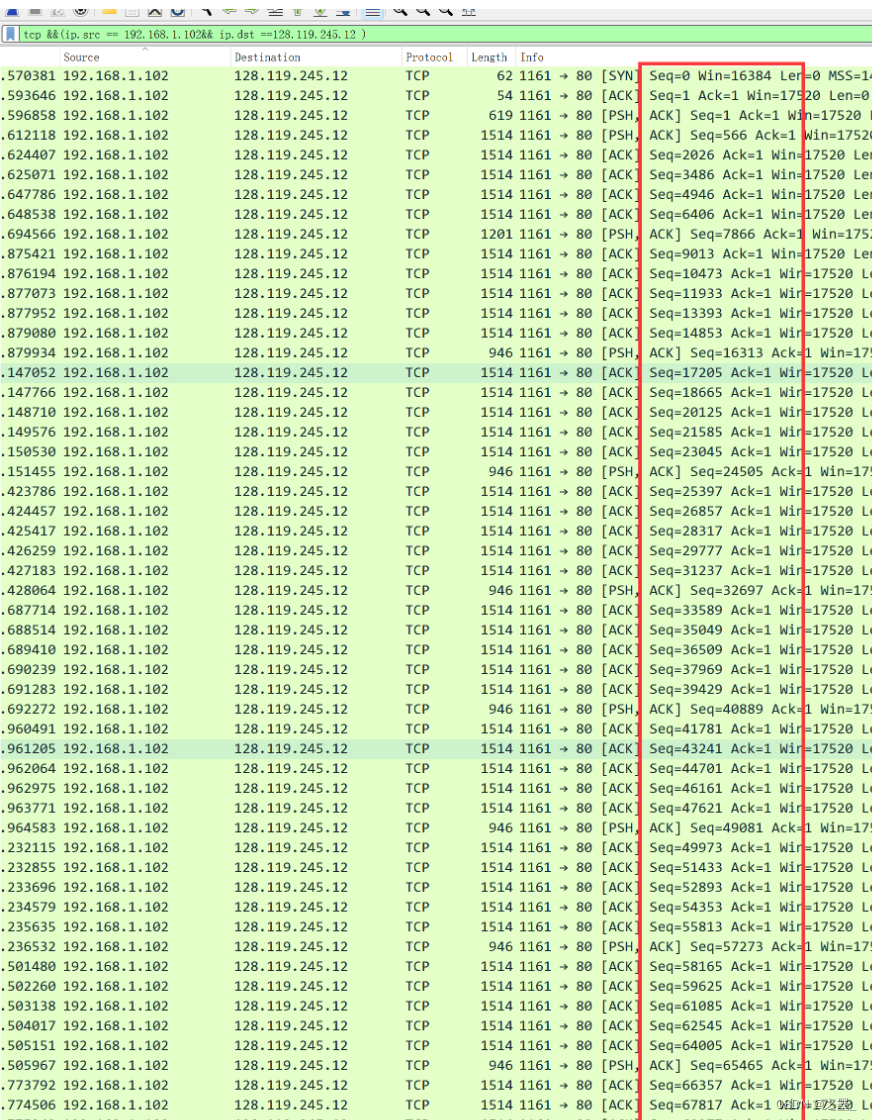
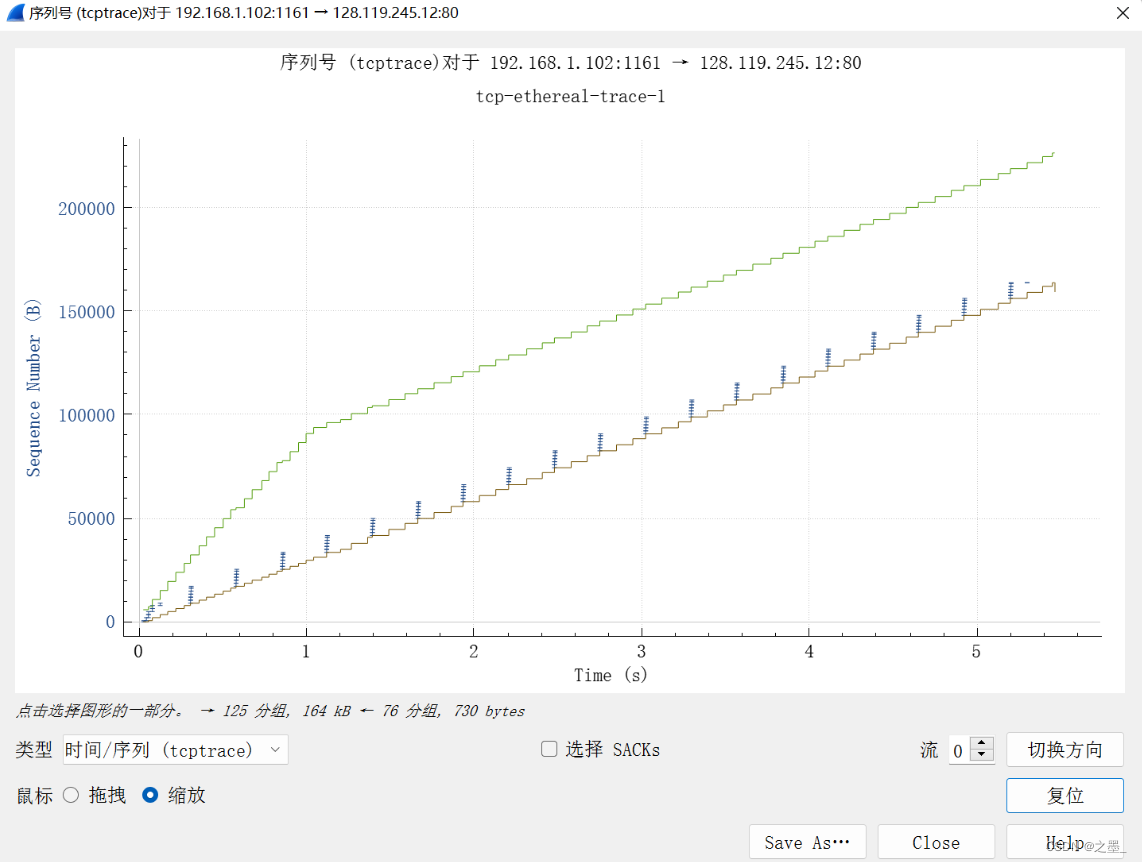
没有出现重传的分组,因为序列号一直是增大的,并且没有出现重复的序列号。
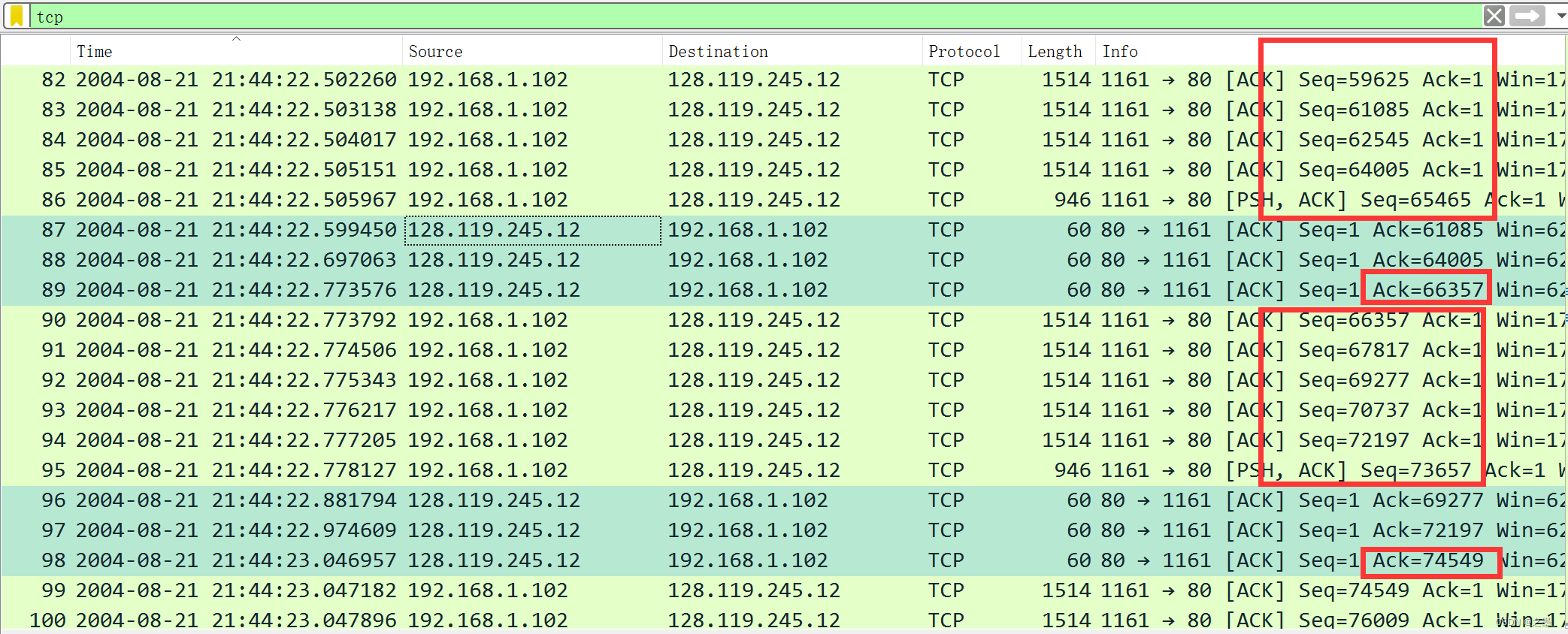


总耗时为最后一个数据包发送时间减去第一个数据包发送时间
吞吐量大约为
164091
∗
8
26.221522
−
20.596858
≈
233387.81
b
p
s
\cfrac{164091*8}{26.221522-20.596858}≈233387.81bps
26.221522−20.596858164091∗8≈233387.81bps
Use the Time-Sequence-Graph(Stevens) plotting tool to view the sequence number versus time plot of segments being sent from the client to the gaia.cs.umass.edu server. Can you identify where TCP’s slowstart phase begins and ends, and where congestion avoidance takes over? Comment on ways in which the measured data differs from the idealized behavior of TCP that we’ve studied in the text.
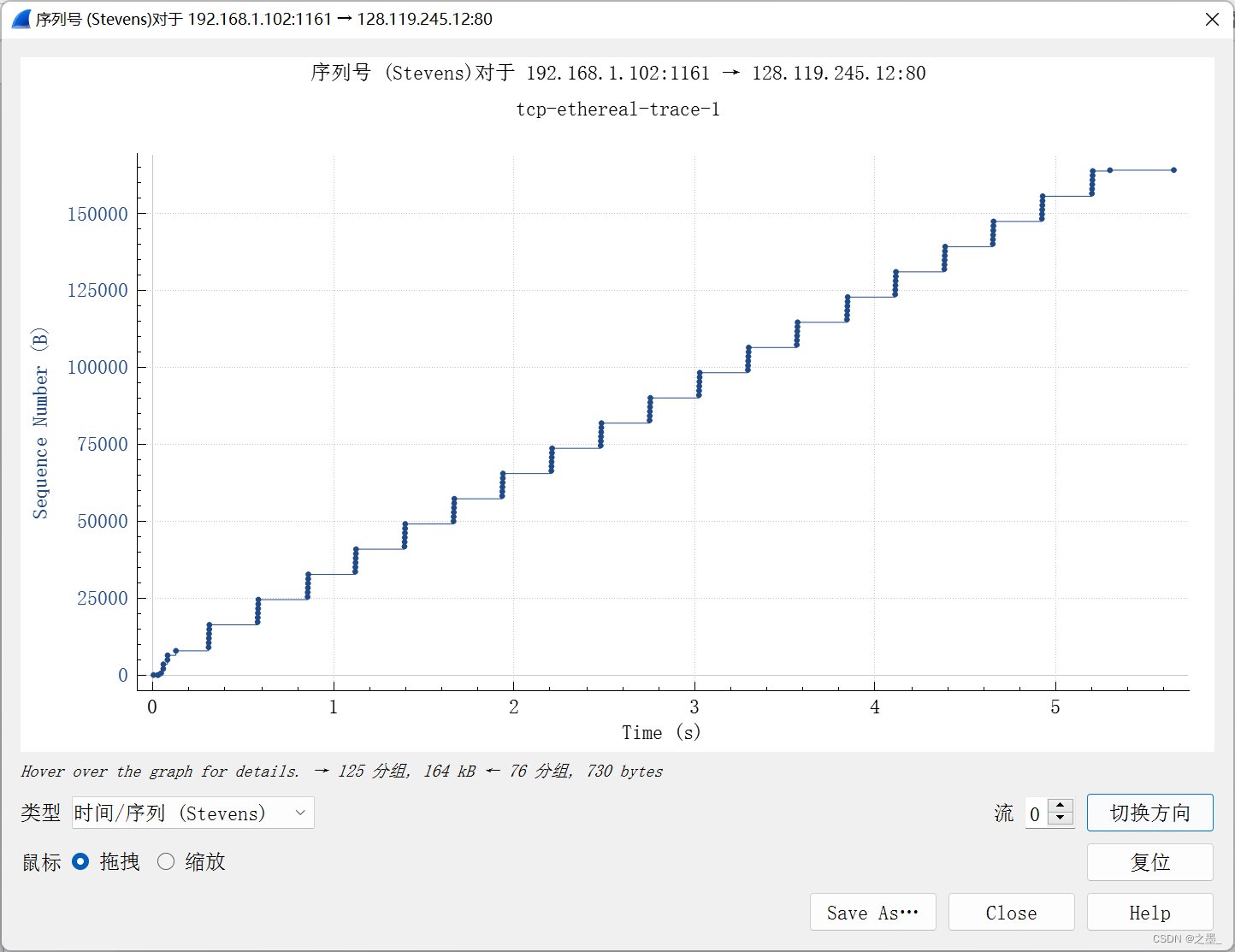
慢启动从发出了HTTP POST报文段后开始,但从图中并不能看出慢启动什么时候结束,拥塞避免是什么时候开始的
TCP 采用慢启动的目的是进行拥塞控制,但是在实际的网络通信中,对于一些数据量较小的小文件,在网络畅通的情况下发送非常快,甚至可能在慢启动结束之前就已经发送完毕。而这种情况下,采用慢启动方式反而来制约了文件的快速发送,从而影响通信的效率。


吞吐量大约为
153029
∗
8
3.541317
−
2.495695
≈
1.171
M
b
p
s
\cfrac{153029*8}{3.541317-2.495695}≈1.171Mbps
3.541317−2.495695153029∗8≈1.171Mbps
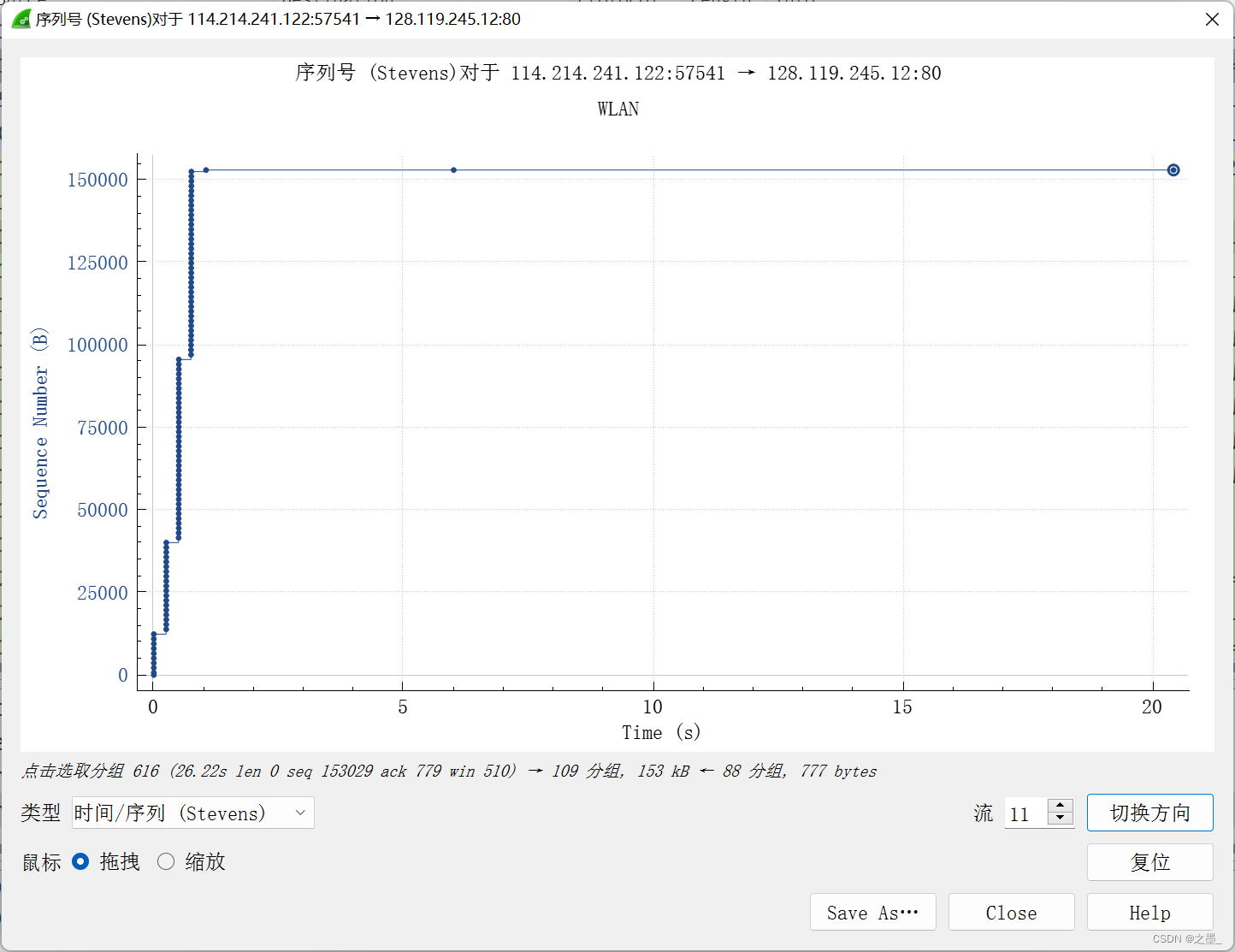
从最开始时刻是慢启动开始的时间,但无法看出慢启动结束和拥塞避免开始的情况。
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
项目介绍随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱小学生兴趣延时班预约小程序的设计与开发被用户普遍使用,为方便用户能够可以随时进行小学生兴趣延时班预约小程序的设计与开发的数据信息管理,特开发了小程序的设计与开发的管理系统。小学生兴趣延时班预约小程序的设计与开发的开发利用现有的成熟技术参考,以源代码为模板,分析功能调整与小学生兴趣延时班预约小程序的设计与开发的实际需求相结合,讨论了小学生兴趣延时班预约小程序的设计与开发的使用。开发环境开发说明:前端使用微信微信小程序开发工具:后端使用ssm:VU
我对如何计算通过{%assignvar=0%}赋值的变量加一完全感到困惑。这应该是最简单的任务。到目前为止,这是我尝试过的:{%assignamount=0%}{%forvariantinproduct.variants%}{%assignamount=amount+1%}{%endfor%}Amount:{{amount}}结果总是0。也许我忽略了一些明显的东西。也许有更好的方法。我想要存档的只是获取运行的迭代次数。 最佳答案 因为{{incrementamount}}将输出您的变量值并且不会影响{%assign%}定义的变量,我
给定一个nxmbool数组:[[true,true,false],[false,true,true],[false,true,true]]有什么简单的方法可以返回“该列中有多少个true?”结果应该是[1,3,2] 最佳答案 使用转置得到一个数组,其中每个子数组代表一列,然后将每一列映射到其中的true数:arr.transpose.map{|subarr|subarr.count(true)}这是一个带有inject的版本,应该在1.8.6上运行,没有任何依赖:arr.transpose.map{|subarr|subarr.in
给定两个大小相等的数组,如何找到不考虑位置的匹配元素的数量?例如:[0,0,5]和[0,5,5]将返回2的匹配项,因为有一个0和一个5共同;[1,0,0,3]和[0,0,1,4]将返回3的匹配项,因为0有两场,1有一场;[1,2,2,3]和[1,2,3,4]将返回3的匹配项。我尝试了很多想法,但它们都变得相当粗糙和令人费解。我猜想有一些不错的Ruby习惯用法,或者可能是一个正则表达式,可以很好地回答这个解决方案。 最佳答案 您可以使用count完成它:a.count{|e|index=b.index(e)andb.delete_at
Ruby中如何“一般地”计算以下格式(有根、无根)的JSON对象的数量?一般来说,我的意思是元素可能不同(例如“标题”被称为其他东西)。没有根:{[{"title":"Post1","body":"Hello!"},{"title":"Post2","body":"Goodbye!"}]}根包裹:{"posts":[{"title":"Post1","body":"Hello!"},{"title":"Post2","body":"Goodbye!"}]} 最佳答案 首先,withoutroot代码不是有效的json格式。它将没有包
目标我正在尝试计算自给定日期以来周的距离,而无需跳过任何步骤。我更喜欢用普通的Ruby来做,但ActiveSupport无疑是一个可以接受的选择。我的代码我写了以下内容,这似乎可行,但对我来说似乎还有很长的路要走。require'date'DAYS_IN_WEEK=7.0defweeks_sincedate_stringdate=Date.parsedate_stringdays=Date.today-dateweeks=days/DAYS_IN_WEEKweeks.round2endweeks_since'2015-06-15'#=>32.57ActiveSupport的#weeks
技术选型1,前端小程序原生MINA框架cssJavaScriptWxml2,管理后台云开发Cms内容管理系统web网页3,数据后台小程序云开发云函数云开发数据库(基于MongoDB)云存储4,人脸识别算法基于百度智能云实现人脸识别一,用户端效果图预览老规矩我们先来看效果图,如果效果图符合你的需求,就继续往下看,如果不符合你的需求,可以跳过。1-1,登录注册页可以看到登录页有注册入口,注册页如下我们的注册,需要管理员审核,审核通过后才可以正常登录使用小程序1-2,个人中心页登录成功以后,我们会进入个人中心页我们在个人中心页可以注册人脸,因为我们做人脸识别签到,需要先注册人脸才可以进行人脸比对,进
如何计算两个字符串之间的字符交集?例如(假设我们有一个名为String.intersection的方法):"abc".intersection("ab")=2"hello".intersection("hallo")=4好的,男孩女孩们,感谢你们的大量反馈。更多示例:"aaa".intersection("a")=1"foo".intersection("bar")=0"abc".intersection("bc")=2"abc".intersection("ac")=2"abba".intersection("aa")=2一些补充说明:维基百科定义intersection如下:Int
给定一个包含各种语言字符的UTF-8文件,我如何计算它包含的唯一字符的数量,同时排除选定数量的符号(例如:“!”、“@”、"#",".")从这个算起? 最佳答案 这是一个bash解决方案。:)bash$perl-CSD-ne'BEGIN{$s{$_}++forsplit//,q(!@#.)}$s{$_}++||$c++forsplit//;END{print"$c\n"}'*.utf8 关于python-如何计算文件中唯一字符的数量?,我们在StackOverflow上找到一个类似的问题