
负责菜鸟商业中心CRM系统开发已经有1年多时间,过程中发现有一个痛点:业务线特别多,每个业务线对同一个页面都有个性化布局和不同的字段需求,而我所在的团队就3个人,在资源有限的情况下如何支撑好呢?刚开始,我们是为各业务线单独定制页面和业务逻辑,1到2个业务线还能应付过来,目前已经发展有十几业务线,且每个业务线下还有子业务线,这种个性化的开发多了,工作量就大了,系统维护压力就巨大。所以就孕育而生了—— 销售魔方类低代码产品,与其说低代码产品,还不如说是一种解决千人千面的个性化业务搭建的前后端一体的解决方案。
本文就降本的情况下,我是如何低成本构建产品能力去支撑多条业务线、多租户,我先以小实践成果展示,再过度分享我后续升级的设计思路。
低代码开发平台(Low-Code Development Platform)是无需编码(0代码)或通过少量代码就可以快速生成应用程序的开发平台。通过可视化进行应用程序开发的方法(参考可视编程语言),使具有不同经验水平的开发人员可以通过图形化的用户界面,使用拖拽组件和模型驱动的逻辑来创建网页和移动应用程序。低代码开发平台(LCDP)的正式名称直到2014年6月才正式确定,整个低代码开发领域却可以追溯到更早前第四代编程语言和快速应用开发工具。
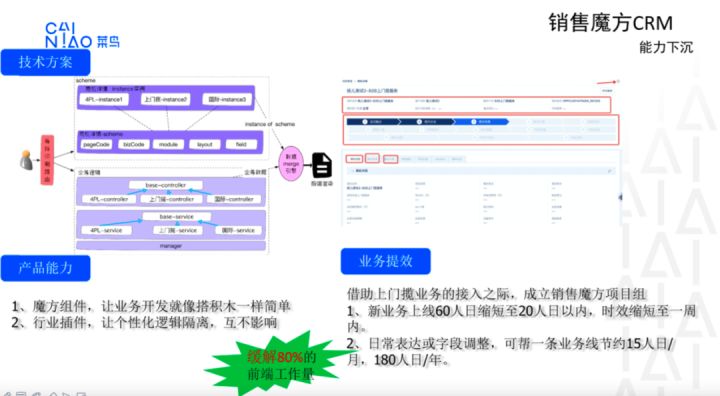
上图是魔方1.0 MVP版本基本运行原理,以及上线后降本增效的数据,业务开发从60人日缩短到20人日,年省成本180人日。
以上版本基本满足了80%以上的业务个性化需求自闭环开发。
还有一些小问题,基于这个版本,我们又不断的升级,提升产品体验、能力提升和业务覆盖。
后续我们可做到新页面上线,只需5分钟,新增字段无需模型变更和无需java代码发布,复杂页面前端也能做到0代码。
基于我们业务的诉求,所以销售魔方需具有以下几个核心能力:
先展现一个实例配置界面,有个体感

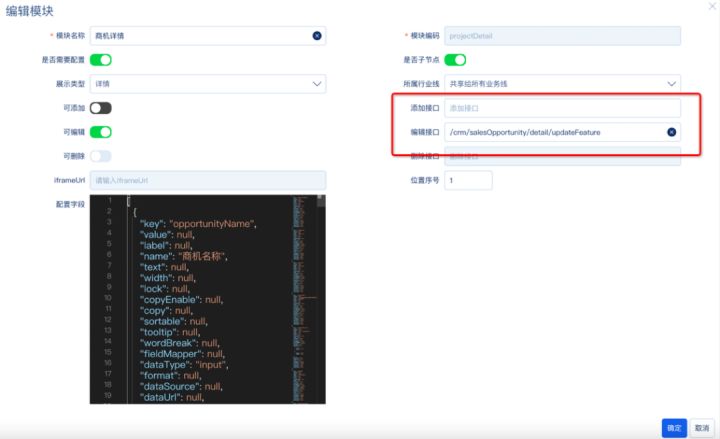
通过以上配置可以个性化配置页面输出的布局和字段,动态输出个性化页面
运营:运营可以根据自己的业务身份,定义独有的page实例,自由选择页面的版块和需要展现和编辑的字段
产品:配置初始化页面,module、以及全量字段池
技术:定义元数据,module,编写module group逻辑执行单元代码
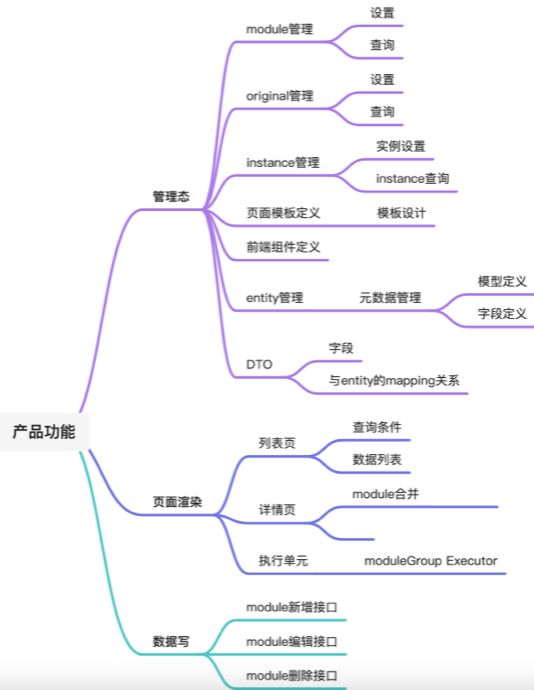
一般低代码平台,主要分为两部分,前端页面的渲染和后端服务接口绑定(服务编排等)。
大的逻辑差不多,因为我这个主要还是具有行业特色的类低代码产品,所以是紧扣行业特殊性构建。
前端渲染
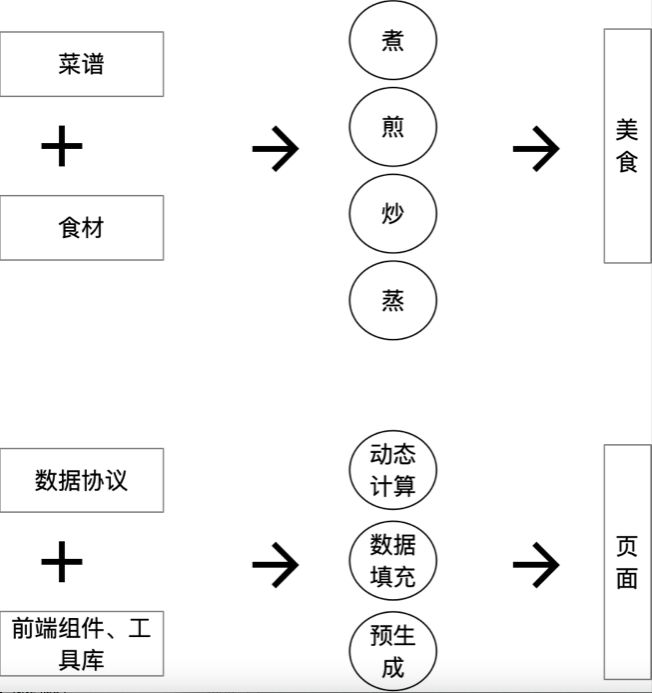
因为我负责的是后端,所以前端我就不过多叙述,大概的逻辑如下两张图,大致意思是前端的页面渲染就如同做菜一样,用户根据自己的需求,可选择菜谱、食材和烹饪方式,不用关心烹饪过程,也不用自己亲自烹饪,都叫由厨师烹饪,厨师会根据你提供的菜谱和食材做好,最后将美食给你端上桌。
同理,前端渲染引擎会根据数据协议、组件库、渲染方式,动态渲染成页面,如果有业务数据将会动态绑定。
后端绑定
我们这有个特殊性,页面是通过后端给定schema,由前端根据这个schema进行页面渲染。后端通过识别出用户的身份,通过接口输出给前端千人千面的个性化schema,前端就通过schema配置动态去渲染。
这样就能实现我们说的同一个功能页面,不同业务身份展示不同的布局和字段。
同时,还会会有一个业务数据接口,用于绑定前端页面填充业务数据或提交表单数据。
每一个组件绑定业务数据接口后,就不是单纯的前端组件了,就具有行业业务属性的组件和页面,这样在这个领域是可以被业务系统直接复用,无需重新编写业务代码。
这里有一个难点,每次新增业务线(租户)后就有新增字段需求,而且字段的差异还挺多,约占80%,在不修改模型的前提下,如何做到?
带着这个问题可以先思考下。
一般解决方案有以下几种:
1、通过设计纵表,以扩展字段。缺点就是查询复杂度高。
2、元数据驱动。缺点就是成本高,架构更加复杂
3、通过定义一个特殊feature字段,存储类型为json,约定好协议,扩展字段按照不同行业存储在json内。优点就是轻量。
根据我们自身的定位和资源情况,最终选择的是第3种方案。
这里有个担心就是json数据方便搜索吗?性能如何?
mysql5.7上,在相同数据量的情况下,虚拟索引和普通索引查询效率基本一致 在大数据量情况下不推荐用聚合函数计算json数据,但是如果json key建立了虚拟列,可以对该虚拟列进行聚合操作,效率跟普通列一样。
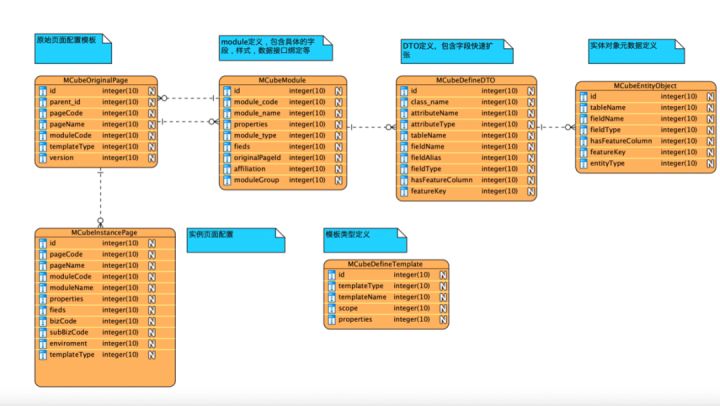
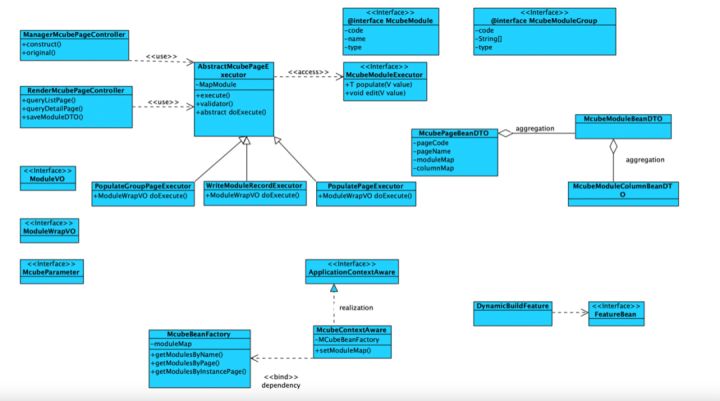
整个模型可以看出,从左往右:
DO的定义、DTO的定义、module定义(等同VO定义)、原始页面定义(originalPage)、实例化页面配置(instancePage)
这个过程基本描述了一个页面是如何定义出来的,以及动态模型的扩展(模型驱动),从模型到页面组件的布局定义。
行业个性化配置则通过对OriginalPage实例化成InstancePage而得。这样就能动态生成千行千面。
OriginalPage到InstancePage这里借鉴了java的思想,类似Class和实例对象。
渲染页面逻辑
页面在渲染的时候,只需两个接口:
1、实例页面数据结构 ;2、业务数据。
前端根据两个接口分成两步渲染:
1、初始化页面布局;2、填充业务数据。
这个借鉴了Spring容器启动时的设计思路,类似实例化、初始化,属性数据填充。
即是对页面类型的定义
定义一张前端页面,分成两个阶段:origin;instance。
origin是定义的原始页面,可以理解成java 的Class类,可以构建多个实例页面。
instance page是最终渲染的运行态。
页面结构:一个page 由N个module组成、一个module由N个field组成。如下图
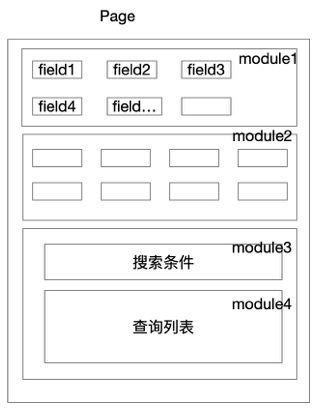
一个实例page由以下维度定义
1、用户传入参数
page_code
custom_dimension
2、系统获取参数
biz_code
sub_biz_code
enviroment
页面的组成单元,一个页面由多个module组成。代表页面显示区域单元,有多个前端组件组成,是页面容器的布局单元。
module_code 全局唯一,实例化后的module可被复用、重写、实现多态。
modules 数据结构为一个 B+tree,只有叶子节点是有具体的实体数据。
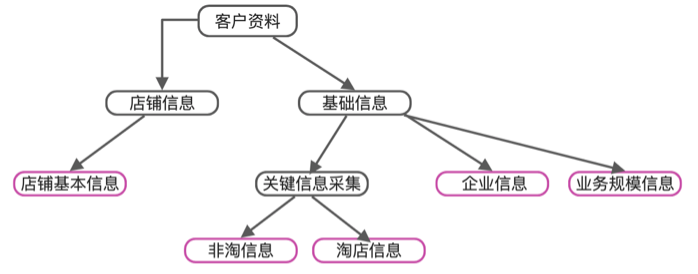
叶子节点是真正包含具体的字段和属性配置
module_type 定义
对module类型的定义
1、主列表查询模块 MAIN_LIST_MODULE
2、导出模块 EXPORT_MODULE
3、弹出页面模块 FLOAT_PAGE_MODULE
4、搜索条件区域 SEARCH_ARE_MODULE
5、子列表查询模块 SUB_LIST_MODULE
6、编辑表单模块 EDIT_MODULE
7、信息平铺呈现 DISPLAY_FLAT_MODULE
McubeContextAware
module容器代码定义
@Component
public class McubeContextAware implements ApplicationContextAware {
private static volatile ApplicationContext alc;
@Resource
private ModuleBeanFactory moduleBeanFactory;
@Resource
private ModuleGroupBeanFactory moduleGroupBeanFactory;
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
alc = applicationContext;
}
@PostConstruct
public void init(){
setModuleBeanMap();
setModuleGroupBeanMap();
}
private void setModuleBeanMap() {
Map<String, McubeModuleExecutor> beanMap = alc.getBeansOfType(McubeModuleExecutor.class);
if (beanMap != null) {
beanMap.values().stream().forEach(m -> {
McubeModule module = AnnotationUtils.findAnnotation(m.getClass(), McubeModule.class);
if (module != null) {
String code = module.code();
String name = module.name();
if (code != null) {
moduleBeanFactory.getMcubeBeanMap().put(code, m);
}
}
});
}
}
private void setModuleGroupBeanMap() {
Map<String, McubeModuleExecutor> beanMap = alc.getBeansOfType(McubeModuleExecutor.class);
if (beanMap != null) {
beanMap.values().stream().forEach(m -> {
McubeModuleGroup module = AnnotationUtils.findAnnotation(m.getClass(), McubeModuleGroup.class);
if (module != null) {
String code = module.code();
String name = module.name();
moduleGroupBeanFactory.getMcubeBeanMap().put(code,m);
}
});
}
}
}为了保证页面的数据填充效率,所以并不是一个module绑定一个服务接口,
而是一个执行单元对应一个或多个module,负责多个module的数据渲染和数据写入,moduleGroup executor是一个页面计算单元。
通过moduleCode动态路由对应的module group,执行相应的计算单元。
每个module 执行单至少都包含读、新增、编辑和删除接口。
页面上的每一个module就自动绑定了后端的业务接口,实现了前后端一体化搭建。
/**
* Created by hzliuxuan on 2022/5/27.
* @author hzliuxuan
* 模块接口
*/
public interface McubeModuleExecutor<T,V> {
/**
* 填充数据,页面渲染,一般是read接口
* @param value
* @return
*/
T populate(V value);
/**
* 编辑模块
* @param value
* @return
*/
void edit(V value);
/**
* 写接口
* @param value
* @return
*/
void add(V value);
/**
* 删除接口
* @param value
* @return
*/
void delete(V value);
}McubeModuleGroup
module执行组注解定义
@Inherited
@Component
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface McubeModuleGroup {
/**
* moduleGroup code (必填,唯一标识)
*/
@NotNull
String code();
/**
* 对应module code值
*/
@NotNull
String[] moduleCodes();
/**
* moduleGroup name
*/
String name();
@NotNull
ModuleGroupType type();
}
```一个module对应多个field。
如果要支持动态扩展,module需要对应一个实体模型。
module只代表一个VO层的部分显示片段,要想达到字段可以动态扩展需要定义一层实体模型的映射关系,这样才能找到统一的feature对象去解析,完成DO、DTO、VO的相互自动转换。 当module需要动态扩展的时候,从实体模型中去选择已经定义好的field。
因为我们的VO也是动态生成的,这样就不需要因为新增一个字段而进行模型变更或者代码发布。即实现0代码上线。
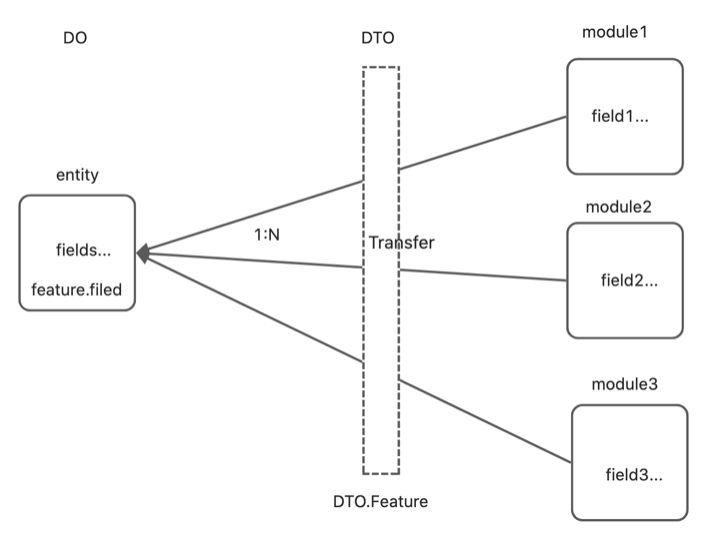
field数据结构定义

page 数据结构
public class McubePageBeanDTO {
/**
* 页面编码
*/
@CrmOperateLogBizCode
private String pageCode;
/**
* 业务线
*/
private String bizCode;
/**
* 配置类型
*/
private TemplateTypeEnum templateType;
/**
* 配置模块
*/
private List<McubeModuleBeanDTO> originalModules;
/**
* 配置字段
*/
private Map<String, List<McubeField>> originalFields;
/**
* 实例的模块
*/
private List<McubeModuleBeanDTO> instanceModules;
private List<String> instanceModulesList;
/**
* 实例的字段
*/
private Map<String, List<McubeField>> instanceFields;
private String subBizCode;
/**
* 元页面version
*/
private Byte originVersion;
/**
* 实例version
*/
private Byte instanceVersion;
/**
* module version
*/
private Byte moduleVersion;
/**
* 属性集合
*/
private List<Property> properties;
///**
// * 显示的模块
// */
//private List<String> instanceModulesList;
private Boolean isCache;
@Data
public static class Property {
/**
* property
*/
private Boolean checkable;
private Boolean isEdit;
private Boolean selectable;
private Boolean isLeaf;
private Boolean isAdd;
private Boolean isDelete;
private String showType;
private Integer level;
private String extendedField;
}page渲染运行时序图
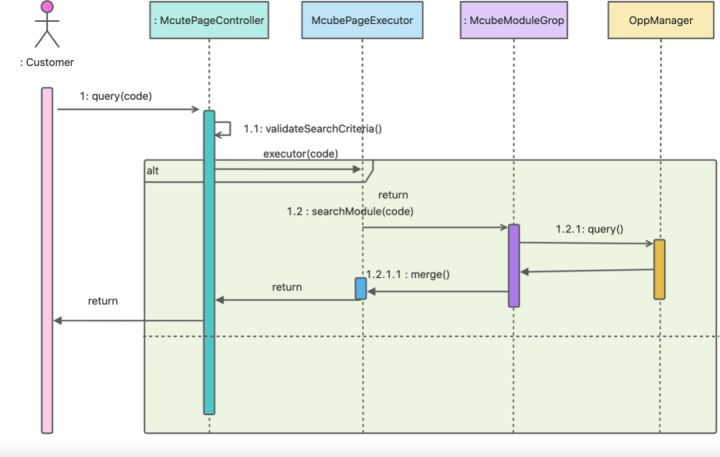
每一个模块背后都会绑定一个 moduleGroup executor ,业务开发只需通过对这个executor实现,即可快速完成开发上线,整个过程无需前端参与。简单的字段添加也无需发布上线,我们会通过动态扩展映射背后的DO扩展。
好了,整个魔方的产品设计到这里基本描述完。
整个产品我理解更多的是贴近业务而产生的一种前后端一体化,低成本快速构建方案。如果要做大,做全,可以参考salesforce元数据驱动模型。
模型关系图:
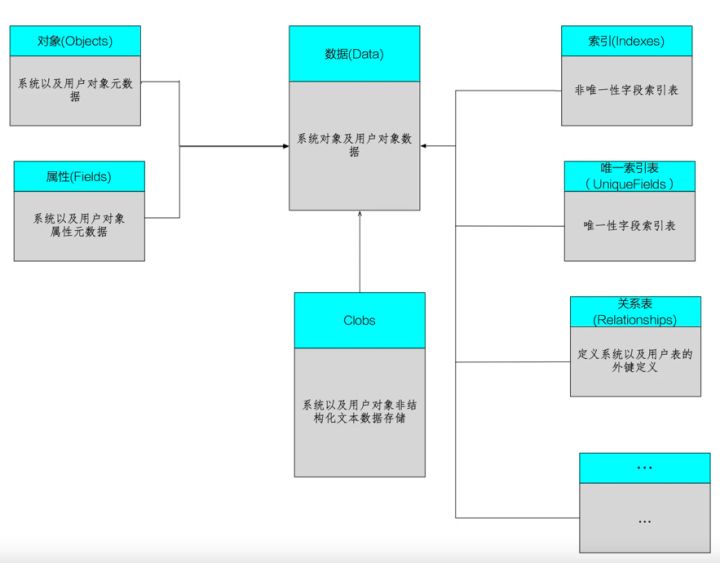
可参考:https://www.infoq.cn/article/rwstpgujoxxuw9tlm88t
salesforce官方架构文档:https://www.developerforce.com/media/ForcedotcomBookLibrary/Force.com_Multitenancy_WP_101508.pdf
salesforce 已经超脱了模型驱动,下探到元数据模型驱动架构 Metadata-driven Architectures。
优点很明显,就是真的强大,业务都不需要建任何表,想怎么扩展模型就怎么扩展,此架构一般适用于与SAAS产品。
缺点也很明显,完全失去业务语义,开发成本和维护成本高,需要一套强大的sql管理和解析、实时的ETL数据架构、检索能力,后期成本也非常大。
故不适用我这个业务团队采纳的方案,但这套设计方案也给我打开了些思路。
魔方这套方案搭建工时约为50人日,两个后端加一个前端,解决了十几个业务线多租户的个性化接入,一定程度实现了模型驱动,千人千面的能力,我认为是典型小投入大产出吧,希望对正遇到同样问题的同学有一定的帮助和启发,限于个人能力,最终要搞大的需要有专业的团队支撑,也欢迎指正和探讨。
作者 | 刘玄(玄哥)
本文为阿里云原创内容,未经允许不得转载。
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
我将应用程序升级到Rails4,一切正常。我可以登录并转到我的编辑页面。也更新了观点。使用标准View时,用户会更新。但是当我添加例如字段:name时,它不会在表单中更新。使用devise3.1.1和gem'protected_attributes'我需要在设备或数据库上运行某种更新命令吗?我也搜索过这个地方,找到了许多不同的解决方案,但没有一个会更新我的用户字段。我没有添加任何自定义字段。 最佳答案 如果您想允许额外的参数,您可以在ApplicationController中使用beforefilter,因为Rails4将参数
我的主要目标是能够完全理解我正在使用的库/gem。我尝试在Github上从头到尾阅读源代码,但这真的很难。我认为更有趣、更温和的踏脚石就是在使用时阅读每个库/gem方法的源代码。例如,我想知道RubyonRails中的redirect_to方法是如何工作的:如何查找redirect_to方法的源代码?我知道在pry中我可以执行类似show-methodmethod的操作,但我如何才能对Rails框架中的方法执行此操作?您对我如何更好地理解Gem及其API有什么建议吗?仅仅阅读源代码似乎真的很难,尤其是对于框架。谢谢! 最佳答案 Ru
我的假设是moduleAmoduleBendend和moduleA::Bend是一样的。我能够从thisblog找到解决方案,thisSOthread和andthisSOthread.为什么以及什么时候应该更喜欢紧凑语法A::B而不是另一个,因为它显然有一个缺点?我有一种直觉,它可能与性能有关,因为在更多命名空间中查找常量需要更多计算。但是我无法通过对普通类进行基准测试来验证这一点。 最佳答案 这两种写作方法经常被混淆。首先要说的是,据我所知,没有可衡量的性能差异。(在下面的书面示例中不断查找)最明显的区别,可能也是最著名的,是你的
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
我目前正在使用以下方法获取页面的源代码:Net::HTTP.get(URI.parse(page.url))我还想获取HTTP状态,而无需发出第二个请求。有没有办法用另一种方法做到这一点?我一直在查看文档,但似乎找不到我要找的东西。 最佳答案 在我看来,除非您需要一些真正的低级访问或控制,否则最好使用Ruby的内置Open::URI模块:require'open-uri'io=open('http://www.example.org/')#=>#body=io.read[0,50]#=>"["200","OK"]io.base_ur
前言作为一名程序员,自己的本质工作就是做程序开发,那么程序开发的时候最直接的体现就是代码,检验一个程序员技术水平的一个核心环节就是开发时候的代码能力。众所周知,程序开发的水平提升是一个循序渐进的过程,每一位程序员都是从“菜鸟”变成“大神”的,所以程序员在程序开发过程中的代码能力也是根据平时开发中的业务实践来积累和提升的。提高代码能力核心要素程序员要想提高自身代码能力,尤其是新晋程序员的代码能力有很大的提升空间的时候,需要针对性的去提高自己的代码能力。提高代码能力其实有几个比较关键的点,只要把握住这些方面,就能很好的、快速的提高自己的一部分代码能力。1、多去阅读开源项目,如有机会可以亲自参与开源