文章目录
Python作为热度比较高的编程语言,其语法简单且语句清晰,而且python有良好的兼容性,可以轻松的和其他编程语言((比如C/C++))建立的模块连接起来,而且python丰富强大的库,经过封装可以轻松调用,因此深受欢迎。
今天我们就尝试用python,建立一个简单的http服务器,用来展示本地电脑上指定的目录和文件。
一般来说,Python的简单http服务器不依赖Apache、IIS等这些复杂的服务器程序,因为其自带了只需一行命令就能建立http服务。但相对的,这个简单http服务也没法提供复杂功能,只能提供相对简单的目录服务。但对于想要学习和熟悉python,这又是必须进行的一步。
首先,我们需要在本地安装python程序。Python程序可以在其官网(www.python.org/)找到对应操作系统版本下载。笔者使用的是Windows操作系统,因此选择Windows版本下载。


Python下载完成后,直接点击安装程序.exe即可进行安装。同时需要注意的是,在安装过程中,需要注意勾选Add python.exe to PATH选项。


完成python程序的安装后,我们就可以着手建立python的http服务器了
由于python内建了简单http服务包,因此对于python来说,只需输入一行命令,就能轻松打开http服务。当然,要运行网页,就需要网页有显示内容。因此我们可以先建立一个用于存放网页文件的文件夹。例如笔者在本地电脑的E盘下新建了一个“test”文件夹

接着,以管理员身份运行本地电脑的命令提示符界面,并输入命令转入该文件所存放的硬盘
e:
再转入打算共享的文件夹
cd test


接着输入命令启动http服务
python -m SimpleHTTPServer 8081
python -m http.server 8001
其中的8081为打算搭建的服务器的输出端口,只要选择没有被占用的端口即可。如果出现防火墙的提示信息,只要选择“允许访问”即可。
命令行输入完毕后,python给出反馈Serving HTTP on 0.0.0.0 port 8081 ...,就说明我们python的http服务已经成功开启了,在本地8081端口下。

接着我们在本地电脑上的浏览器地址栏中,输入localhost:8081,就能打开打算分享的文件夹下的文件。

能看到这些内容,就说明本地电脑上python的http服务已经开启,并且已经可以查阅到这个文件夹下的文件。同样的,如果我们在这个文件夹下放入网页文件,也能够显示为网页。
此时在同一局域网下的设备,只要在浏览器中输入本地电脑的ip地址+端口号(具体格式为192.168.XXX.XXX:端口号),就能显示出python的网页。

不过,不能在公共互联网访问的网页总觉得缺少灵魂,因此我们可以借助cpolar内网穿透,创建一条内网穿透数据隧道,让我们可以在公共互联网条件下,访问到python。
同样的,我们可以在cpolar的官网(https://www.cpolar.com/)找到对应操作系统版本的软件,笔者这里也是选择Windows版本。


Cpolar软件下载完成后,将压缩包解压,并双击其中的.msi文件,即可自动进行安装,我们只要一路点击Next即可。


由于cpolar会为每个用户创建独立的数据隧道,并辅以用户密码和token码保证数据安全,因此我们在使用cpolar之前,需要进行用户注册。注册过程也非常简单,只要在cpolar主页右上角点击用户注册,在注册页面填入必要信息,就能完成注册。


完成cpolar的安装和注册后,我们就可以着手使用cpolar,创建一条内网穿透数据隧道,将本地电脑的python网页与公共互联网连接起来。需要注意的是,cpolar免费版的数据隧道每24小时重置一次。笔者并不想每天进行重置数据隧道设置,因此将cpolar升级至vip版,以便能获得能长期稳定存在的内网穿透数据隧道。
要生成长期稳定存在的内网穿透数据隧道,我们要先访问cpolar官网并登录,并在“仪表盘”页面左侧,找到并点击预留按钮,进入“预留”页面。


在“预留”页面中,我们可以看到cpolar提供了多种协议的数据隧道保留项目。而python服务器是http协议,因此我们找到保留二级子域名栏位。当然,如果已经向域名供应商购买了自己的域名的,也可以选择“保留自定义域名”栏位。
在“保留二级子域名”栏位,我们需要对打算保留的二级子域名进行信息设置,而这些设置的信息,也会成为我们在公共互联网访问本地python服务器的隧道入口(公共互联网地址的一部分)。具体需要设置的信息为:
地区:服务器所在区域,就近选择即可二级域名会最终出现在生成的公共互联网地址中,作为网络地址的标识之一描述可以看做这条数据隧道的描述,能够与其他隧道区分开即可
输入这几项设置后,就可以点击右侧的保留按钮,将这条数据隧道保留下来。如果我们不想要这条隧道的入口了,也可以点击右侧的“x”,轻松将隧道删除

完成cpolar云端设置后,我们回到本地电脑上,打开并登录cpolar客户端(可以在浏览器中输入localhost:9200直接访问,也可以在开始菜单中点击cpolar客户端的快捷方式)。

点击客户端主界面左侧隧道管理——创建隧道按钮,进入本地隧道创建页面(如果要创建每24小时重置地址的临时数据隧道,可直接在此进行设置,不必再cpolar官网设置空白数据隧道)。
在这个页面,同样需要进行几项信息设置,这些信息设置包括:
隧道名称——可以看做cpolar本地的隧道信息注释,只要方便我们分辨即可;协议——tomcat输出的是web网页,因此选择http协议;本地地址——本地地址即为本地网站的输出端口号,我们之前设置了8081为输出端口,因此这里也填入8081;域名类型——在这个例子中,我们已经在cpolar云端预留了二级子域名的数据隧道,因此勾选“二级子域名”(如果预留的是自定义域名,则勾选自定义域名),并在下一行“Sub Domain”栏中填入预留的二级子域名,这里我们填入“pythonweb”(如果只是创建临时数据隧道,则直接勾选“随机域名”,由cpolar客户端自行生成网络地址);地区——与cpolar云端设置时一样,我们依照实际所在地就近填写;

完成这些设置后,就可以点击页面下方的创建按钮,将本地python服务器网页与cpolar云端保留的二级子域名连结起来,生成一条完整的内网穿透数据隧道。
隧道创建完成后,cpolar会自动跳转至隧道管理——隧道列表页面,在这个页面看到数据隧道的状态(是否畅通),或是控制隧道的开启、关闭或删除。如果需要对隧道的信息进行变更,也可以通过这里的“编辑”按钮进行

数据隧道建立完成后,我们可以点击cpolar客户端左侧状态——在线隧道列表。找到能够访问本地python服务器页面的公共互联网地址。

只要将这个地址输入浏览器地址,就能轻松访问到本地电脑上的python服务器页面。
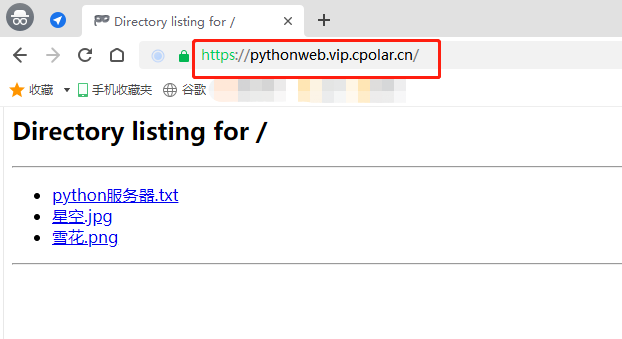
至此,我们成功的使用python建立一个简单的服务器页面,并且通过cpolar为其创建了一条能够穿透内网屏障的数据隧道,将这个python网页发布到公共互联网上。其实,只要知道网页(或软件)的输出端口号,我们都可以使用cpolar穿透内网,让我们在公共互联网上访问到本地的网页(或软件)。
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我想安装一个带有一些身份验证的私有(private)Rubygem服务器。我希望能够使用公共(public)Ubuntu服务器托管内部gem。我读到了http://docs.rubygems.org/read/chapter/18.但是那个没有身份验证-如我所见。然后我读到了https://github.com/cwninja/geminabox.但是当我使用基本身份验证(他们在他们的Wiki中有)时,它会提示从我的服务器获取源。所以。如何制作带有身份验证的私有(private)Rubygem服务器?这是不可能的吗?谢谢。编辑:Geminabox问题。我尝试“捆绑”以安装新的gem..
是的,我知道最好使用webmock,但我想知道如何在RSpec中模拟此方法:defmethod_to_testurl=URI.parseurireq=Net::HTTP::Post.newurl.pathres=Net::HTTP.start(url.host,url.port)do|http|http.requestreq,foo:1endresend这是RSpec:let(:uri){'http://example.com'}specify'HTTPcall'dohttp=mock:httpNet::HTTP.stub!(:start).and_yieldhttphttp.shou
最近,当我启动我的Rails服务器时,我收到了一长串警告。虽然它不影响我的应用程序,但我想知道如何解决这些警告。我的估计是imagemagick以某种方式被调用了两次?当我在警告前后检查我的git日志时。我想知道如何解决这个问题。-bcrypt-ruby(3.1.2)-better_errors(1.0.1)+bcrypt(3.1.7)+bcrypt-ruby(3.1.5)-bcrypt(>=3.1.3)+better_errors(1.1.0)bcrypt和imagemagick有关系吗?/Users/rbchris/.rbenv/versions/2.0.0-p247/lib/ru
在Rails4.0.2中,我使用s3_direct_upload和aws-sdkgems直接为s3存储桶上传文件。在开发环境中它工作正常,但在生产环境中它会抛出如下错误,ActionView::Template::Error(noimplicitconversionofnilintoString)在View中,create_cv_url,:id=>"s3_uploader",:key=>"cv_uploads/{unique_id}/${filename}",:key_starts_with=>"cv_uploads/",:callback_param=>"cv[direct_uplo
有没有办法在这个简单的get方法中添加超时选项?我正在使用法拉第3.3。Faraday.get(url)四处寻找,我只能先发起连接后应用超时选项,然后应用超时选项。或者有什么简单的方法?这就是我现在正在做的:conn=Faraday.newresponse=conn.getdo|req|req.urlurlreq.options.timeout=2#2secondsend 最佳答案 试试这个:conn=Faraday.newdo|conn|conn.options.timeout=20endresponse=conn.get(url
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
您如何在Rails中的实时服务器上进行有效调试,无论是在测试版/生产服务器上?我试过直接在服务器上修改文件,然后重启应用,但是修改好像没有生效,或者需要很长时间(缓存?)我也试过在本地做“脚本/服务器生产”,但是那很慢另一种选择是编码和部署,但效率很低。有人对他们如何有效地做到这一点有任何见解吗? 最佳答案 我会回答你的问题,即使我不同意这种热修补服务器代码的方式:)首先,你真的确定你已经重启了服务器吗?您可以通过跟踪日志文件来检查它。您更改的代码显示的View可能会被缓存。缓存页面位于tmp/cache文件夹下。您可以尝试手动删除
我意识到这可能是一个非常基本的问题,但我现在已经花了几天时间回过头来解决这个问题,但出于某种原因,Google就是没有帮助我。(我认为部分问题在于我是一个初学者,我不知道该问什么......)我也看过O'Reilly的RubyCookbook和RailsAPI,但我仍然停留在这个问题上.我找到了一些关于多态关系的信息,但它似乎不是我需要的(尽管如果我错了请告诉我)。我正在尝试调整MichaelHartl'stutorial创建一个包含用户、文章和评论的博客应用程序(不使用脚手架)。我希望评论既属于用户又属于文章。我的主要问题是:我不知道如何将当前文章的ID放入评论Controller。
我目前正在使用以下方法获取页面的源代码:Net::HTTP.get(URI.parse(page.url))我还想获取HTTP状态,而无需发出第二个请求。有没有办法用另一种方法做到这一点?我一直在查看文档,但似乎找不到我要找的东西。 最佳答案 在我看来,除非您需要一些真正的低级访问或控制,否则最好使用Ruby的内置Open::URI模块:require'open-uri'io=open('http://www.example.org/')#=>#body=io.read[0,50]#=>"["200","OK"]io.base_ur