本期带大家一起来学习一下通讯录的三个版本(静态版+动态版+文件版)🌈🌈🌈

文章目录
使用VS2022编译器进行编译
test.c文件实现整个框架,contact.c文件实现整个通讯录的具体功能,contact.h文件实现整个通讯录需要的声明和头文件 🍖 🦴
从现在基本流行的通信录中 发现几个必备的信息
1.对联系人的 增 删 改 查
2.显示所有联系人
3.以姓名 对通讯录 进行排序
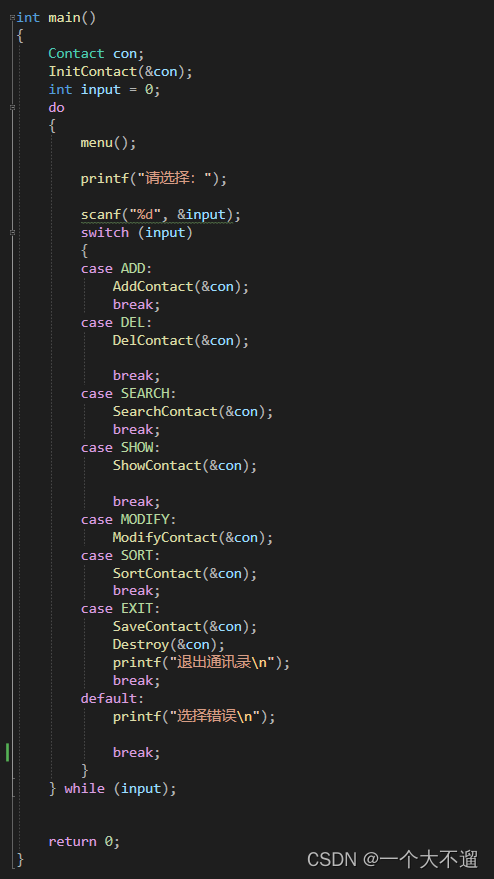
基本框架:用do while()实现通讯录的循环,确保实现增删改查显示的一直进行;🍗
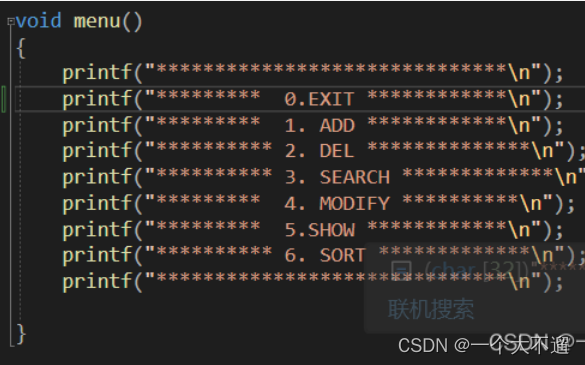
menu()菜单函数🍗🍗
switch 进行项目的选择🍗🍗🍗
联系人 通讯录的创建🍗🍗🍗🍗
编写一个简单的menu()函数,进行菜单的简单实现
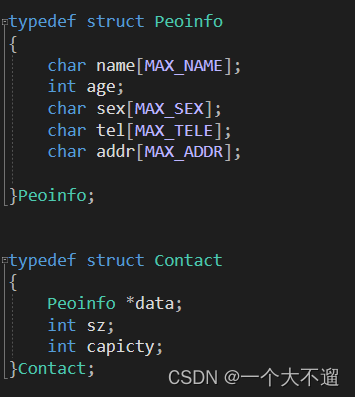
1.定义一个结构体变量 创建一个联系人结构体(包含了 联系人 姓名 性别 年龄 电话 地址);🥩🥩
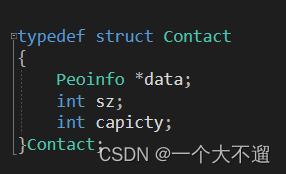
🥩🥩2. 利用联系人结构体 创建通讯录(里面包含了一个联系人结构体变量 指针 和定义 联系人数量的sz 和内存容量🥩🥩
void InitContact(Contact* con)
{
con->sz = 0;
//初始化
memset(con->data, 0, sizeof(con->data));
}
void InitContact(Contact* con)
{
con->sz = 0;
//初始化
con->data =(Peoinfo*) malloc(sizeof(Peoinfo) * DEFALUT_SZ);
if (con->data == NULL)
{
printf("通讯录初始失败:%s\n", strerror(errno));
return;
}
con->capicty = DEFALUT_SZ;
con->sz = 0;
}
void InitContact(Contact* con)
{
con->sz = 0;
//初始化
con->data =(Peoinfo*) malloc(sizeof(Peoinfo) * DEFALUT_SZ);
if (con->data == NULL)
{
printf("通讯录初始失败:%s\n", strerror(errno));
return;
}
con->capicty = DEFALUT_SZ;
con->sz = 0;
//加载信息到通讯录
LoadContact(con);
}
🍩 🍪 🌰细心的朋友会发现,文件版的初始化和动态版本的初始化只是多加了一个LoadContact(con)函数,其实就是这样子的,在程序运行的时候,调用Init函数将文件当中的内容写到当中🍩 🍪 🌰
添加联系人 首先考虑内存空间是否充足 (当联系人 数量 和容量 相同时 realloc 进行 扩容) 扩容 以保证 内存空间不会
过度浪费 和不会存不下当前内容 🌎 🌍 🌏
然后开始在通讯录中添加 联系人
添加成功 sz+1;🌎 🌍 🌏
void AddContact(Contact* con)
{
//if (con->sz == MAX)
//{
// printf("通讯录已满,无法增加\n");
// return;
//} 静态的程序 添加函数
int ret=checkCapcity(con);
if (ret == 1)
{
printf("请输入名字:");
scanf("%s", con->data[con->sz].name);
printf("请输入年龄:");
scanf("%d", &(con->data[con->sz].age));
printf("请输入电话号码:");
scanf("%s", (con->data[con->sz].tel));
printf("请输入地址:");
scanf("%s", (con->data[con->sz].addr));
printf("请输入性别:");
scanf("%s", con->data[con->sz].sex);
//通讯录成员 + 1
con->sz++;
printf("添加成功!!!\n");
}
}
checkCapcity函数,作用是检查通讯录当中人数是否满了,满了的话就扩容
int checkCapcity(Contact* con)
{
if (con->sz == con->capicty)
{
Peoinfo* ptr =(Peoinfo*) realloc(con->data, sizeof(Peoinfo)* (con->capicty + ADDNUM));
if (ptr == NULL)
{
printf("通讯录增容失败:%s\n", strerror(errno));
return 0;
}
else
{
con->data = ptr;
con->capicty += ADDNUM;
printf("通讯录增容成功,当前容量为%d\n", con->capicty);
}
}
return 1;
}
在这里呢,如果我们是动态版本以上的🌎 🌍 🌏,我们每次添加联系人信息的时候需要检查一下通讯录当中成员人数是否满人了,🌎 🌍 🌏如果满人的话我们需要用relloc函数重新开辟空间🌎 🌍 🌏
先输入 联系人 姓名 然后自我遍历找到 姓名所在位置 进行联系人删除
删除成功 sz-1;
void DelContact( Contact* con)
{
if (con->sz == 0 )
{
printf("通讯录为空,无法删除\n");
return;
}
printf("输入要删除人的名字:");
int pos = Findbyname(con);
if (pos == -1)
{
printf("要删除的人不存在\n");
return;
}
//删除pos上的数据
for (int j = pos; j < con->sz - 1; j++)
{
con->data[j] = con->data[j + 1];
}
//memmmove(con->data[i])
con->sz--;
printf("删除成功\n");
}
这里我们用到了静态的Findbyname函数,用于查找联系人
static int Findbyname(Contact *con)
{
char name[MAX_NAME] = "0";
scanf("%s", name);
int i = 0;
for (i = 0; i < con->sz; i++)
{
if (0 == strcmp(con->data[i].name, name))
{
return i;
}
}
return -1;
}
用户输入联系人姓名 按姓名进行查找 找到 在屏幕打印联系人信息 找不到 提示用户🌎 🌍 🌏
void SearchContact(const Contact* con)
{
printf("请输入要查找的名字:");
int pos = Findbyname(con);
if (pos == -1)
{
printf("要查找的人不在\n");
return;
}
int i = pos;
printf("%-10s %-5s %-5s %-12s %-30s\n", "姓名", "年龄", "性别", "电话", "地址");
printf("\n");
printf("%-10s %-5d%-5s %-12s %-30s",
con->data[i].name, con->data[i].age, con->data[i].sex,
con->data[i].tel, con->data[i].addr);
printf("\n");
}
☃️ ⛄️先对 通讯录当中成员人数 进行检查 如果 sz ==0 说明 通讯录中不存在联系人 ☃️ ⛄️
如果sz!=0, 则显示通讯录内容
☃️ ⛄️
void ShowContact(const Contact* con)
{
int i = 0;
printf("%-10s %-5s %-5s %-12s %-30s\n", "姓名", "年龄", "性别", "电话", "地址");
printf("\n");
for (i = 0; i < con->sz; i++)
{
printf("%-10s %-5d%-5s %-12s %-30s",
con->data[i].name, con->data[i].age, con->data[i].sex,
con->data[i].tel, con->data[i].addr);
printf("\n");
}
}
对联系人内容 进行 修改 原理和删除联系人的原理是一样的,采取覆盖方式
先请用户输入 想要修改联系人姓名 然后找到姓名所在位置
对联系人进行修改,并且需要对输入的名字进行查找,☃️ ⛄️照样需要用到Findbyname函数☃️ ⛄️
void ModifyContact(Contact* con)
{
printf("请输入要修改人的名字:");
int pos = Findbyname(con);
if (pos == -1)
{
printf("要修改的人不存在\n");
return;
}
printf("请输入名字:");
scanf("%s", con->data[pos].name);
printf("请输入年龄:");
scanf("%d", &(con->data[pos].age));
printf("请输入电话号码:");
scanf("%s", (con->data[pos].tel));
printf("请输入地址:");
scanf("%s", (con->data[pos].addr));
printf("请输入性别:");
scanf("%s", con->data[pos].sex);
printf("修改成功!!\n");
}
原理是采用库函数qsort进行快速排序,根据姓名排序
void SortContact(Contact* con)
{
qsort(con->data, con->sz, sizeof(Peoinfo), compare_by_nmae);
printf("排序成功!!!\n");
ShowContact(con);
}
对于静态版本来说,退出程序之后数据全部丢失,没有过多的话语 🍖 🦴
动态版本的通讯录,因为我们在此之前调用了malloc函数去堆区开辟一块连续的内存空间,所以我们需要用free函数去释放内存,并将其置 🍖 🦴为NULL
void Destroy(Contact* con)
{
free(con->data);
con->data = NULL;
con->capicty = 0;
con->sz = 0;
printf("释放内存..........\n");
}
对于文件版本来说,我们在关闭程序之前需要将我们录入的信息存放在一个文件当中,再然后的操作同动态版本的通讯录一样,需要释放内存
void SaveContact(Contact* con)
{
FILE* fp = fopen("D:\\code test\\c-language\\address list\\contact.txt", "wb");
if (fp == NULL)
{
perror("SaveContact:fopen");
return;
}
for (int i = 0; i < con->sz; i++)
{
fwrite(con->data + i, sizeof(Peoinfo), 1, fp);
}
fclose(fp);
fp = NULL;
printf("成功保存到文件中.........\n");
}
void Destroy(Contact* con)
{
free(con->data);
con->data = NULL;
con->capicty = 0;
con->sz = 0;
printf("释放内存..........\n");
}
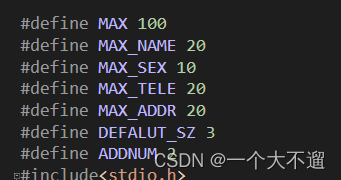
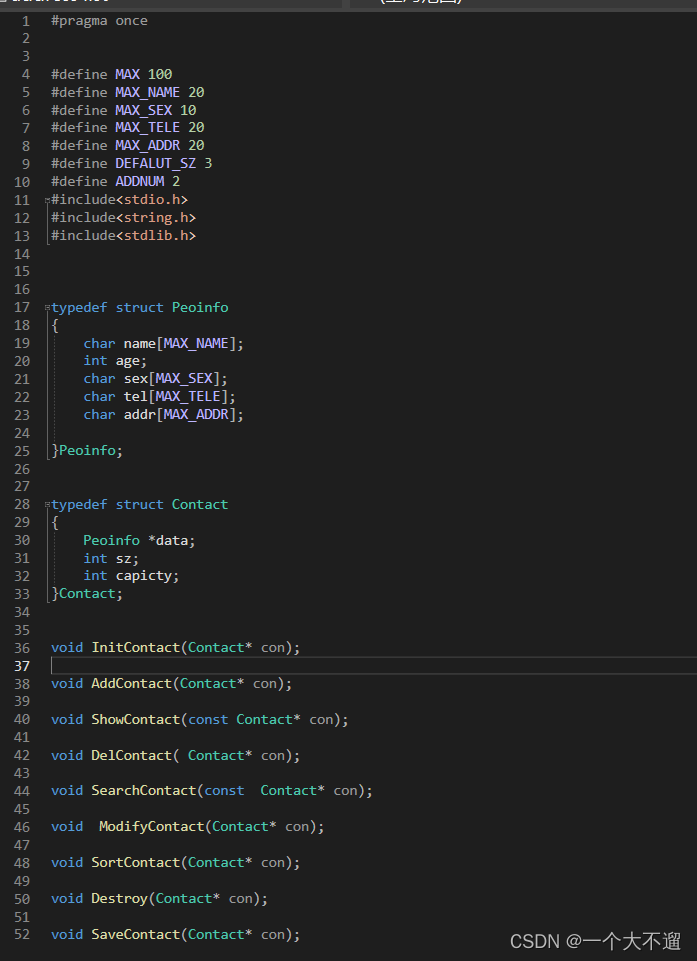
🍖 🦴平时我们为了防止头文件的重复包含,会使用#ifndef或者#program once。这里记录一下它们之间的区别 🍖 🦴
#pragma once
#define MAX 100
#define MAX_NAME 20
#define MAX_SEX 10
#define MAX_TELE 20
#define MAX_ADDR 20
#define DEFALUT_SZ 3
#define ADDNUM 2
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
typedef struct Peoinfo
{
char name[MAX_NAME];
int age;
char sex[MAX_SEX];
char tel[MAX_TELE];
char addr[MAX_ADDR];
}Peoinfo;
typedef struct Contact
{
Peoinfo *data;
int sz;
int capicty;
}Contact;
void InitContact(Contact* con);
void AddContact(Contact* con);
void ShowContact(const Contact* con);
void DelContact( Contact* con);
void SearchContact(const Contact* con);
void ModifyContact(Contact* con);
void SortContact(Contact* con);
void Destroy(Contact* con);
void SaveContact(Contact* con);
#define _CRT_SECURE_NO_WARNINGS
#include"contact.h"
// 静态版本
//void InitContact(Contact* con)
//{
// con->sz = 0;
// //初始化
// memset(con->data, 0, sizeof(con->data));
//
//}
//函数声明
int checkCapcity(Contact* con);
void LoadContact(Contact* con)
{
FILE* fp = fopen("D:\\code test\\c-language\\address list\\contact.txt", "rb");
if (fp == NULL)
{
perror("LoadContact:fopen");
return;
}
Peoinfo tmp = { 0 };
while (fread(&tmp, sizeof(Peoinfo), 1, fp))
{
checkCapcity(con);
con->data[con->sz] = tmp;
con->sz++;
}
fclose(fp);
fp = NULL;
}
void InitContact(Contact* con)
{
con->sz = 0;
//初始化
con->data =(Peoinfo*) malloc(sizeof(Peoinfo) * DEFALUT_SZ);
if (con->data == NULL)
{
printf("通讯录初始失败:%s\n", strerror(errno));
return;
}
con->capicty = DEFALUT_SZ;
con->sz = 0;
//加载信息到通讯录
LoadContact(con);
}
static int Findbyname(Contact *con)
{
char name[MAX_NAME] = "0";
scanf("%s", name);
int i = 0;
for (i = 0; i < con->sz; i++)
{
if (0 == strcmp(con->data[i].name, name))
{
return i;
}
}
return -1;
}
int checkCapcity(Contact* con)
{
if (con->sz == con->capicty)
{
Peoinfo* ptr =(Peoinfo*) realloc(con->data, sizeof(Peoinfo)* (con->capicty + ADDNUM));
if (ptr == NULL)
{
printf("通讯录增容失败:%s\n", strerror(errno));
return 0;
}
else
{
con->data = ptr;
con->capicty += ADDNUM;
printf("通讯录增容成功,当前容量为%d\n", con->capicty);
}
}
return 1;
}
//增加信息
void AddContact(Contact* con)
{
//if (con->sz == MAX)
//{
// printf("通讯录已满,无法增加\n");
// return;
//}
int ret=checkCapcity(con);
if (ret == 1)
{
printf("请输入名字:");
scanf("%s", con->data[con->sz].name);
printf("请输入年龄:");
scanf("%d", &(con->data[con->sz].age));
printf("请输入电话号码:");
scanf("%s", (con->data[con->sz].tel));
printf("请输入地址:");
scanf("%s", (con->data[con->sz].addr));
printf("请输入性别:");
scanf("%s", con->data[con->sz].sex);
//通讯录成员 + 1
con->sz++;
printf("添加成功!!!\n");
}
}
void ShowContact(const Contact* con)
{
int i = 0;
printf("%-10s %-5s %-5s %-12s %-30s\n", "姓名", "年龄", "性别", "电话", "地址");
printf("\n");
for (i = 0; i < con->sz; i++)
{
printf("%-10s %-5d%-5s %-12s %-30s",
con->data[i].name, con->data[i].age, con->data[i].sex,
con->data[i].tel, con->data[i].addr);
printf("\n");
}
}
void DelContact( Contact* con)
{
if (con->sz == 0 )
{
printf("通讯录为空,无法删除\n");
return;
}
printf("输入要删除人的名字:");
int pos = Findbyname(con);
if (pos == -1)
{
printf("要删除的人不存在\n");
return;
}
//删除pos上的数据
for (int j = pos; j < con->sz - 1; j++)
{
con->data[j] = con->data[j + 1];
}
//memmmove(con->data[i])
con->sz--;
printf("删除成功\n");
}
void SearchContact(const Contact* con)
{
printf("请输入要查找的名字:");
int pos = Findbyname(con);
if (pos == -1)
{
printf("要查找的人不在\n");
return;
}
int i = pos;
printf("%-10s %-5s %-5s %-12s %-30s\n", "姓名", "年龄", "性别", "电话", "地址");
printf("\n");
printf("%-10s %-5d%-5s %-12s %-30s",
con->data[i].name, con->data[i].age, con->data[i].sex,
con->data[i].tel, con->data[i].addr);
printf("\n");
}
void ModifyContact(Contact* con)
{
printf("请输入要修改人的名字:");
int pos = Findbyname(con);
if (pos == -1)
{
printf("要修改的人不存在\n");
return;
}
printf("请输入名字:");
scanf("%s", con->data[pos].name);
printf("请输入年龄:");
scanf("%d", &(con->data[pos].age));
printf("请输入电话号码:");
scanf("%s", (con->data[pos].tel));
printf("请输入地址:");
scanf("%s", (con->data[pos].addr));
printf("请输入性别:");
scanf("%s", con->data[pos].sex);
printf("修改成功!!\n");
}
static int compare_by_nmae(const void* p, const void* q)
{
return strcmp(((Peoinfo*)p)->name, ((Peoinfo*)q)->name);
}
void SortContact(Contact* con)
{
qsort(con->data, con->sz, sizeof(Peoinfo), compare_by_nmae);
printf("排序成功!!!\n");
ShowContact(con);
}
void SaveContact(Contact* con)
{
FILE* fp = fopen("contact.txt", "wb");
if (fp == NULL)
{
perror("SaveContact:fopen");
return;
}
for (int i = 0; i < con->sz; i++)
{
fwrite(con->data + i, sizeof(Peoinfo), 1, fp);
}
fclose(fp);
fp = NULL;
printf("成功保存到文件中.........\n");
}
void Destroy(Contact* con)
{
free(con->data);
con->data = NULL;
con->capicty = 0;
con->sz = 0;
printf("释放内存..........\n");
}

#define _CRT_SECURE_NO_WARNINGS
#include"contact.h"
void menu()
{
printf("******************************\n");
printf("********* 0.EXIT ************\n");
printf("********* 1. ADD ************\n");
printf("********** 2. DEL **************\n");
printf("********** 3. SEARCH *************\n");
printf("********* 4. MODIFY **********\n");
printf("********* 5.SHOW ************\n");
printf("********** 6. SORT *************\n");
printf("******************************\n");
}
enum Option
{
EXIT,
ADD,
DEL,
SEARCH,
MODIFY,
SHOW,
SORT
};
int main()
{
Contact con;
InitContact(&con);
int input = 0;
do
{
menu();
printf("请选择:");
scanf("%d", &input);
switch (input)
{
case ADD:
AddContact(&con);
break;
case DEL:
DelContact(&con);
break;
case SEARCH:
SearchContact(&con);
break;
case SHOW:
ShowContact(&con);
break;
case MODIFY:
ModifyContact(&con);
case SORT:
SortContact(&con);
break;
case EXIT:
SaveContact(&con);
Destroy(&con);
printf("退出通讯录\n");
break;
default:
printf("选择错误\n");
break;
}
} while (input);
return 0;
}
🌹🌹🌹如果大家通过本篇博客收获了,对结构体及枚举,特别是结构体内存对齐和位段在VS当中的存储有了新的认知,那么希望支持一下哦如果还有不明白的,疑惑的话,或者什么比较好的建议的话,可以发到评论区,
我们一起解决,共同进步 ❗️❗️❗️
最后谢谢大家❗️❗️❗️💯💯💯
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
好的,所以我的目标是轻松地将一些数据保存到磁盘以备后用。您如何简单地写入然后读取一个对象?所以如果我有一个简单的类classCattr_accessor:a,:bdefinitialize(a,b)@a,@b=a,bendend所以如果我从中非常快地制作一个objobj=C.new("foo","bar")#justgaveitsomerandomvalues然后我可以把它变成一个kindaidstring=obj.to_s#whichreturns""我终于可以将此字符串打印到文件或其他内容中。我的问题是,我该如何再次将这个id变回一个对象?我知道我可以自己挑选信息并制作一个接受该信
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A
我注意到像bundler这样的项目在每个specfile中执行requirespec_helper我还注意到rspec使用选项--require,它允许您在引导rspec时要求一个文件。您还可以将其添加到.rspec文件中,因此只要您运行不带参数的rspec就会添加它。使用上述方法有什么缺点可以解释为什么像bundler这样的项目选择在每个规范文件中都需要spec_helper吗? 最佳答案 我不在Bundler上工作,所以我不能直接谈论他们的做法。并非所有项目都checkin.rspec文件。原因是这个文件,通常按照当前的惯例,只