回城传送–》《100天精通MYSQL从入门到就业》
今天是学习 SQL 打卡的第 33 天,每天我会提供一篇文章供群成员阅读( 不需要订阅付钱 )。
希望大家先自己思考,如果实在没有想法,再看下面的解题思路,自己再实现一遍。在小虚竹JAVA社区 中对应的 【打卡贴】打卡,今天的任务就算完成了,养成每天学习打卡的好习惯。
虚竹哥会组织大家一起学习同一篇文章,所以有什么问题都可以在群里问,群里的小伙伴可以迅速地帮到你,一个人可以走得很快,一群人可以走得很远,有一起学习交流的战友,是多么幸运的事情。
我的学习策略很简单,题海策略+ 费曼学习法。如果能把这些题都认认真真自己实现一遍,那意味着 SQL 已经筑基成功了。后面的进阶学习,可以继续跟着我,一起走向架构师之路。
今天的学习内容是:SQL高级技巧-CTE和递归查询
| 题目链接 | 难度 |
|---|---|
| 获取连续区间 | ★★★☆☆ |

这里写入初始化表结构,初始化数据的sql
自MySQL 8.x版本起,MySQL数据库支持公用表表达式(CTE)功能,该功能可通过WITH语句实现。CTE可分为两种类型:非递归公用表表达式和递归公用表表达式。
在传统的子查询中,如果派生表被引用两次,可能会导致MySQL性能问题。然而,使用公共表表达式(CTE)查询时,子查询只会被引用一次,这是使用CTE的重要原因之一。
在MySQL 8.0之前,要实现数据表的复杂查询,需要使用子查询语句,但是这种方式的SQL语句性能较低,而且子查询的派生表无法被多次引用。然而,随着公共表表达式(CTE)的引入,复杂SQL的编写变得更简单,数据查询的性能也得到了提高。
非递归CTE语法:
WITH cte_name (column1, column2, ...) AS (
SELECT ...
FROM ...
WHERE ...
)
SELECT ...
FROM cte_name;
其中,cte_name是公共表表达式的名称,可以自定义;
column1, column2等是列名,也可以自定义;
as 里的SELECT语句是用来创建公共表表达式的查询语句;
最后的SELECT语句是用来查询公共表表达式的结果。
通过比较子查询和公共表表达式(CTE)的查询,可以更好地理解CTE。例如,在MySQL命令行中运行下面的SQL语句,就可以实现子查询的效果。
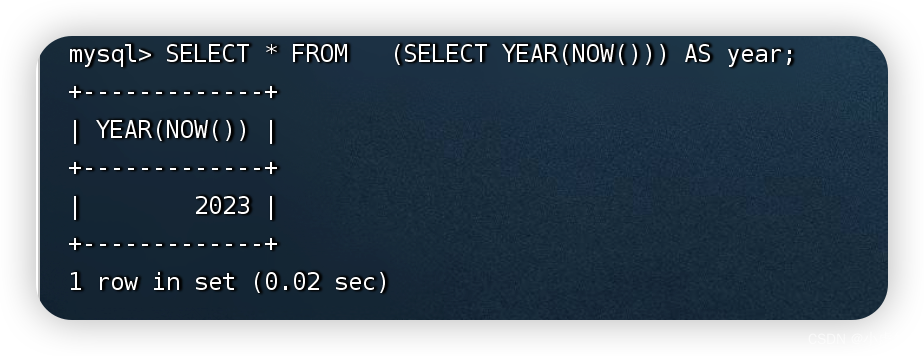
实战:使用子查询实现了获取当前年份的信息
SELECT * FROM (SELECT YEAR(NOW())) AS year;
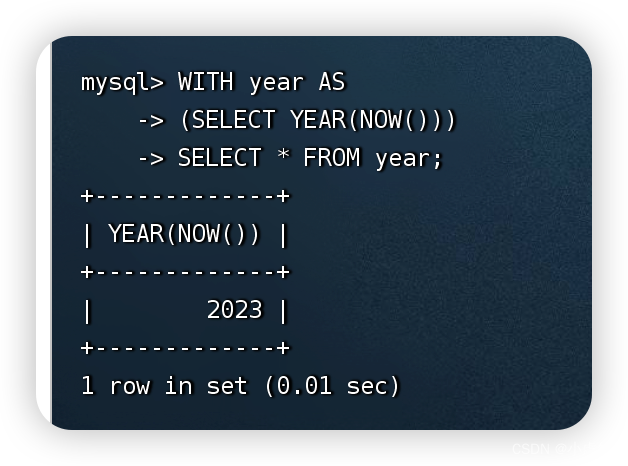
使用CTE实现查询:
WITH year AS
(SELECT YEAR(NOW()))
SELECT * FROM year;
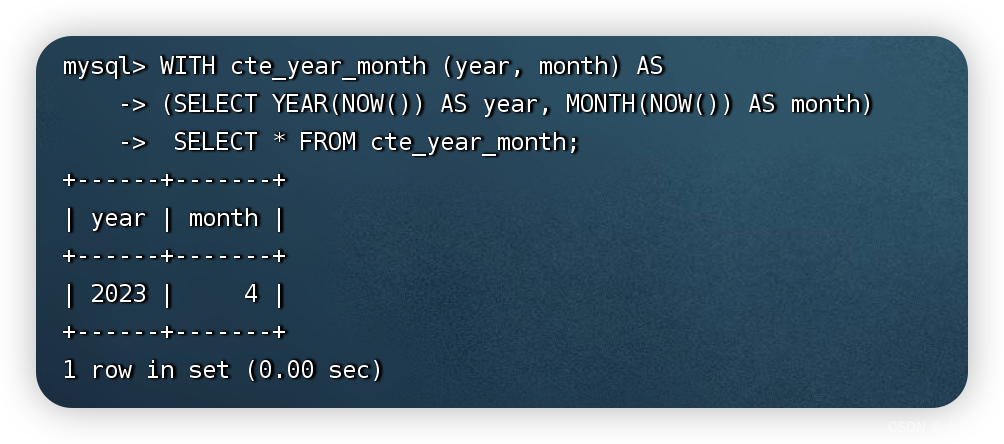
也可以在CTE语句中定义多个查询字段:
WITH cte_year_month (year, month) AS
(SELECT YEAR(NOW()) AS year, MONTH(NOW()) AS month)
SELECT * FROM cte_year_month;
多个CTE之间还可以相互引用:
WITH cte1(cte1_year, cte1_month) AS
(SELECT YEAR(NOW()) AS cte1_year, MONTH(NOW()) AS cte1_month),
cte2(cte2_year, cte2_month) AS
(SELECT (cte1_year+1) AS cte2_year, (cte1_month + 1) AS cte2_month FROM cte1)
SELECT * FROM cte1 JOIN cte2;
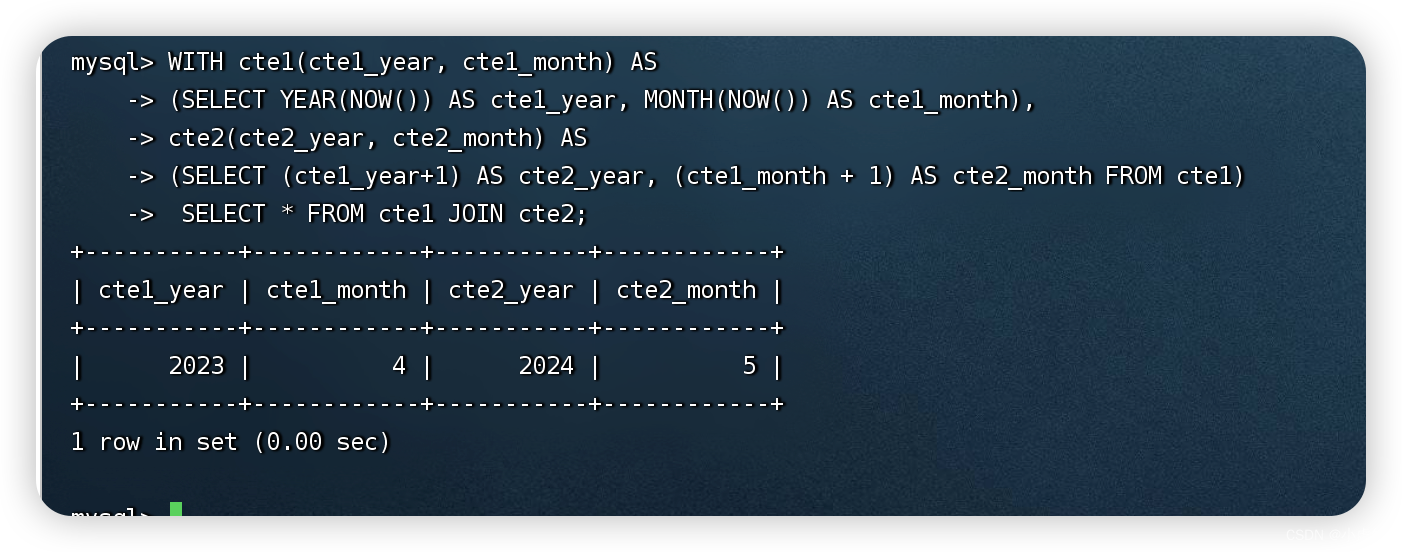
注意:
1、cte2的定义中引用了cte1
2、当在SQL语句中定义多个公共表表达式(CTE)时,需要使用逗号将每个CTE分隔开。
递归公共表表达式(CTE)的子查询可以引用自身,因此需要使用特定的语法格式来实现。与非递归CTE相比,递归CTE的语法格式多了一个关键字RECURSIVE。
递归CTE的语法如下:
WITH RECURSIVE cte_name (column1, column2, ...) AS (
SELECT ...
FROM ...
WHERE ...
UNION [ALL]
SELECT ...
FROM cte_name
WHERE ...
)
SELECT ...
FROM cte_name;
其中,cte_name是公共表表达式的名称,可以自定义;
column1, column2等是列名,也可以自定义;
SELECT语句是用来创建公共表表达式的查询语句;
UNION [ALL]是用来将递归查询的结果与上一次查询的结果进行合并;
最后的SELECT语句是用来查询公共表表达式的结果。
递归公共表表达式(CTE)中包含两种子查询:种子查询和递归查询。种子查询用于初始化查询数据,在查询中不会引用自身;而递归查询则是在种子查询的基础上,根据一定的规则引用自身的查询。这两种查询之间需要使用UNION、UNION ALL或UNION DISTINCT语句进行连接。
实战:
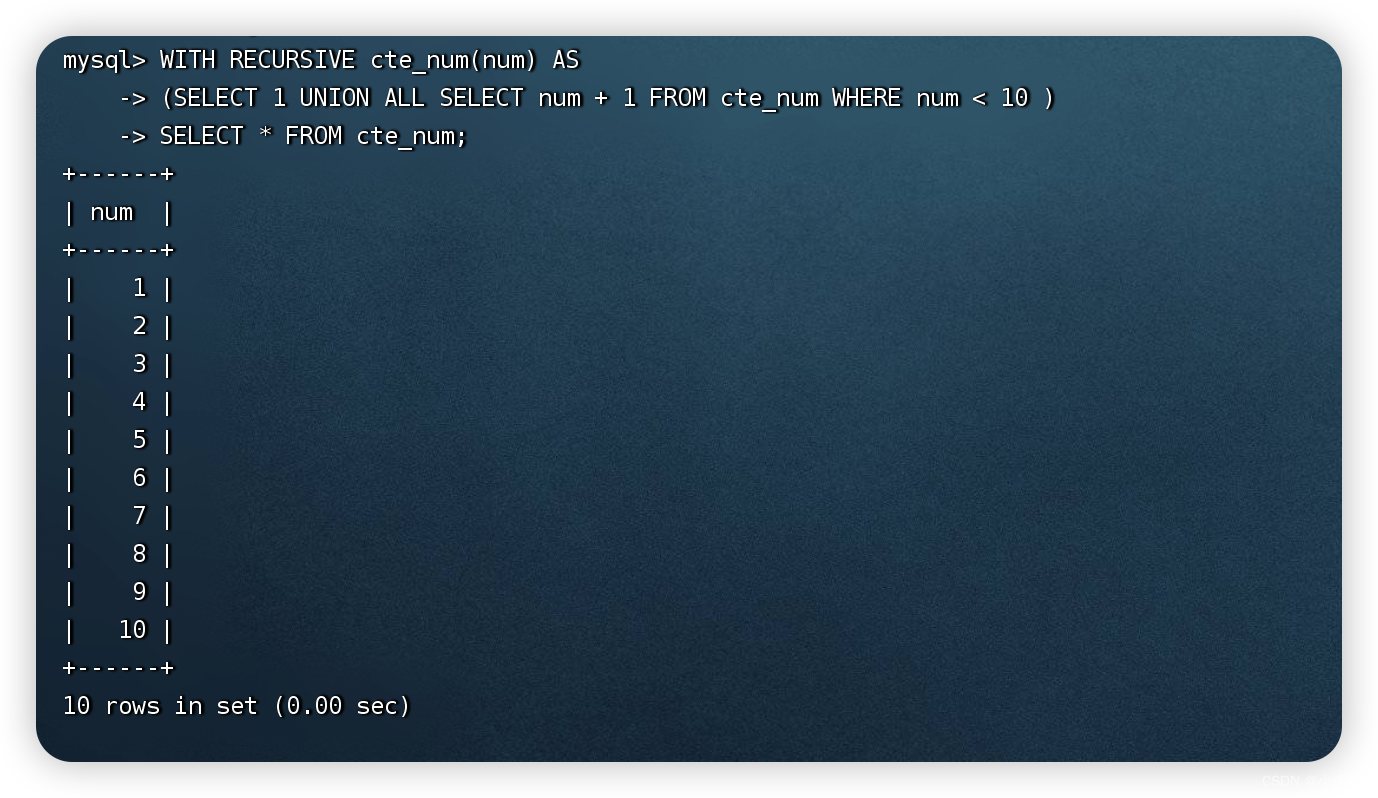
使用递归CTE在MySQL命令行中输出1~10的序列。
WITH RECURSIVE cte_num(num) AS
(SELECT 1 UNION ALL SELECT num + 1 FROM cte_num WHERE num < 10 )
SELECT * FROM cte_num;
递归CTE查询对于遍历有组织、有层级关系的数据时非常方便。
实战:
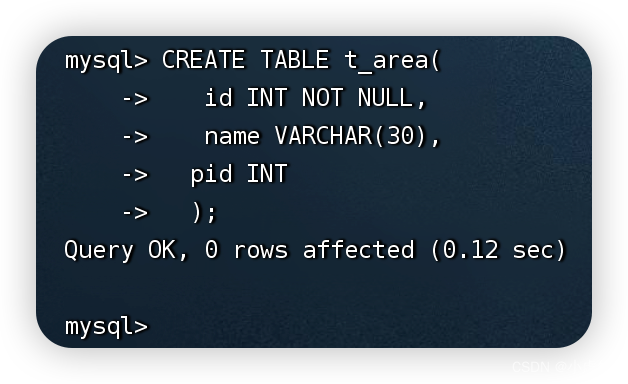
创建一张区域数据表t_area,该数据表中包含省市区信息。
CREATE TABLE t_area(
id INT NOT NULL,
name VARCHAR(30),
pid INT
);
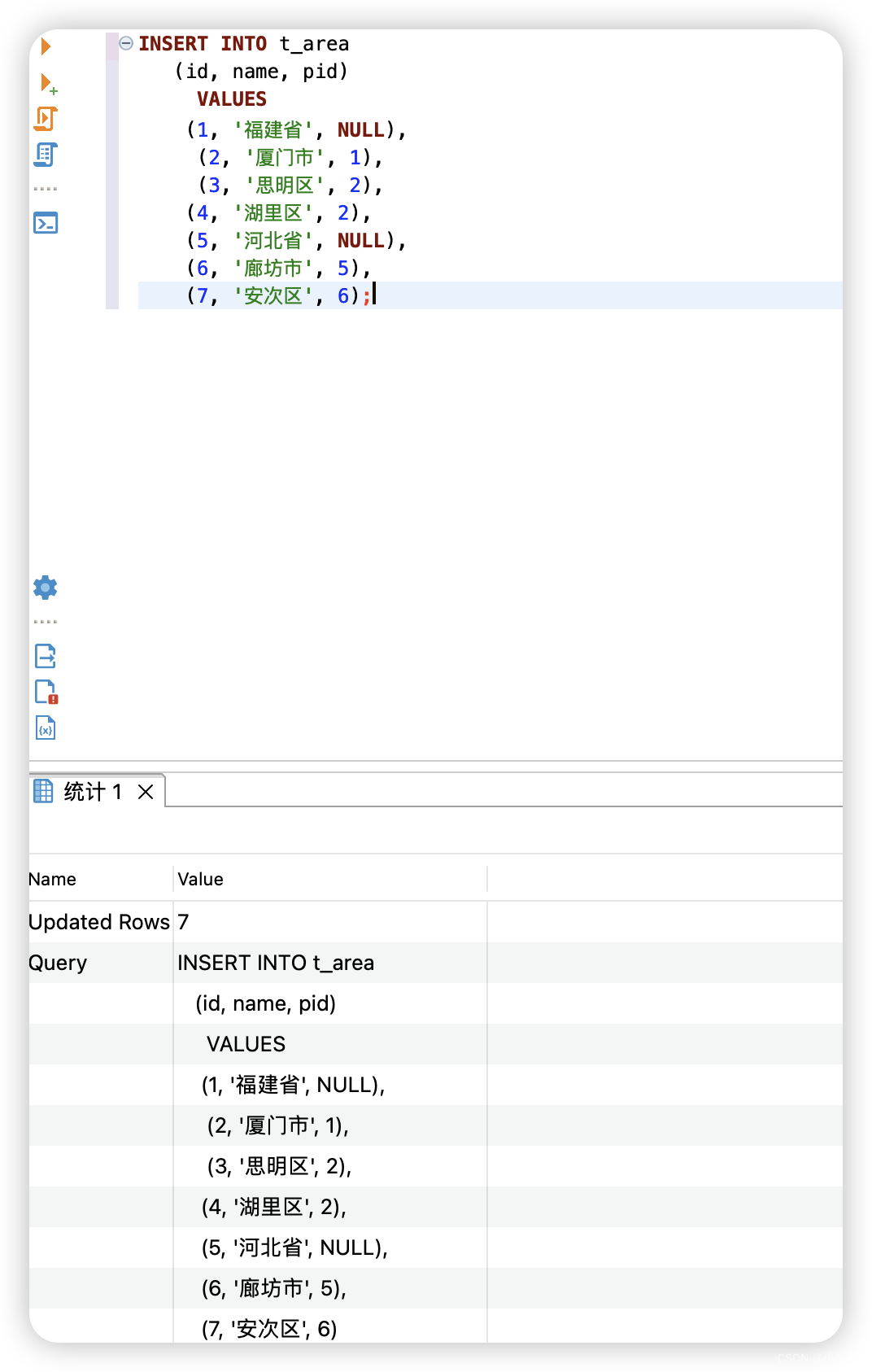
向t_area数据表中插入测试数据。
INSERT INTO t_area
(id, name, pid)
VALUES
(1, '福建省', NULL),
(2, '厦门市', 1),
(3, '思明区', 2),
(4, '湖里区', 2),
(5, '河北省', NULL),
(6, '廊坊市', 5),
(7, '安次区', 6);

使用递归CTE查询t_area数据表中的层级关系:
WITH RECURSIVE area_depth(id, name, path) AS
(
SELECT id, name, CAST(id AS CHAR(300))
FROM t_area WHERE pid IS NULL
UNION ALL
SELECT a.id, a.name, CONCAT(ad.path, ',', a.id)
FROM area_depth AS ad
JOIN t_area AS a
ON ad.id = a.pid
)
SELECT * FROM area_depth ORDER BY path;
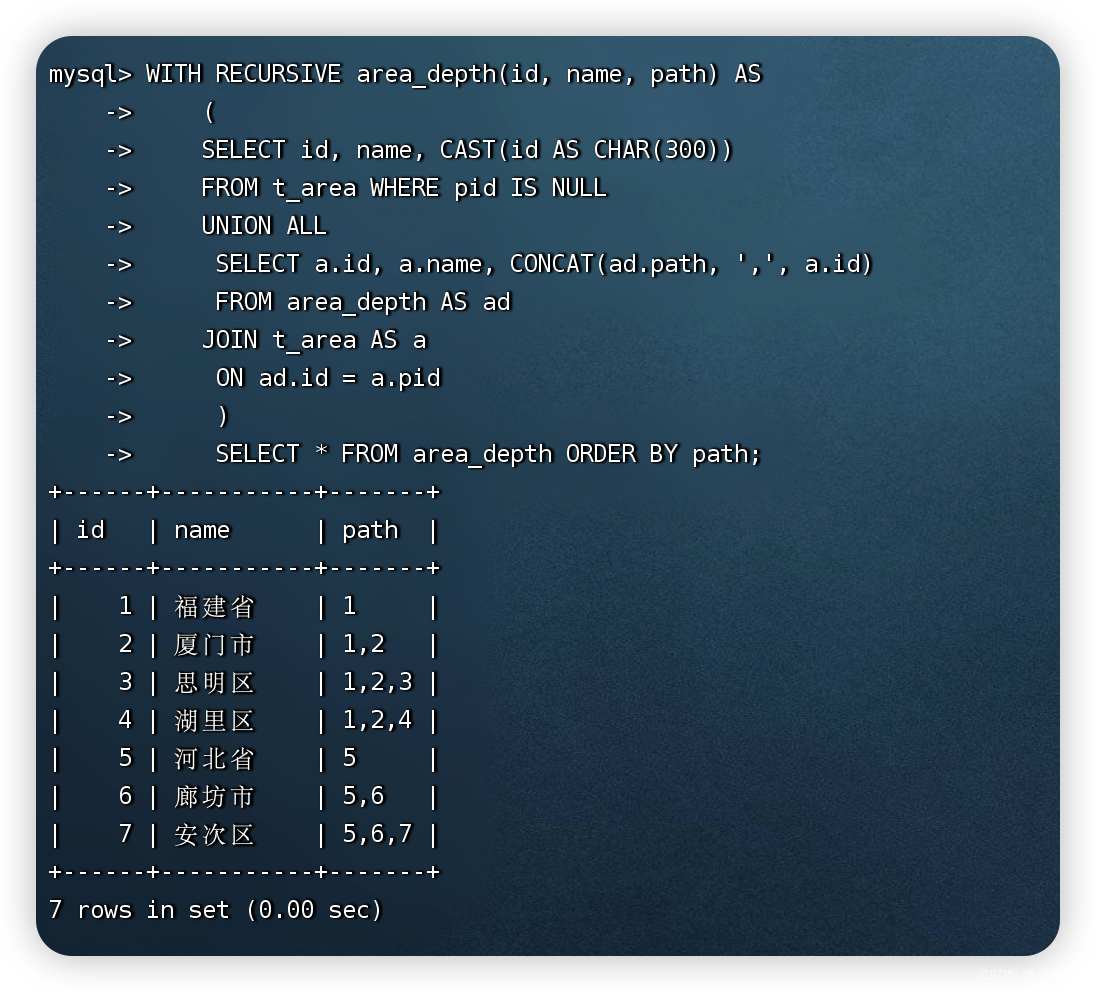
递归CTE查询语句必须包含一个停止递归的条件。如果没有设置停止条件,MySQL会根据配置信息自动停止查询并报错。MySQL默认提供了两个配置项来停止递归CTE。
实战:如下未设置查询终止条件的递归CTE,MySQL会抛出错误信息并终止查询
WITH RECURSIVE cte_num(num) AS
(
SELECT 1
UNION ALL
SELECT num+1 FROM cte_num
)
SELECT * FROM cte_num;
ERROR 3636 (HY000): Recursive query aborted after 1001 iterations. Try increasing @@cte_max_recursion_depth to a larger value.
问题是:当没有为递归CTE设置终止条件时,MySQL默认会在第1001次查询时抛出错误信息,并终止查询。

查看cte_max_recursion_depth参数的默认值:
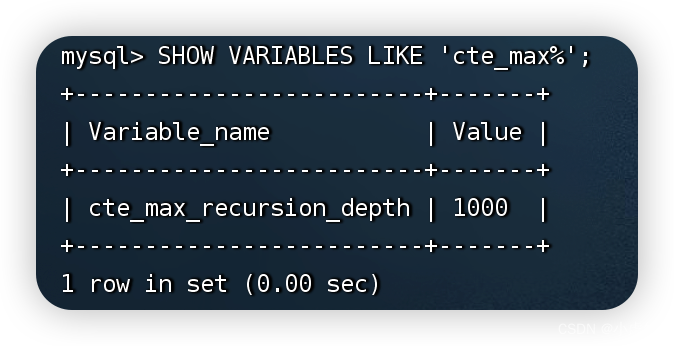
所以:cte_max_recursion_depth参数的默认值为1000,这也是MySQL默认会在第1001次查询时抛出错误并终止查询的原因。
实战:max_execution_time配置
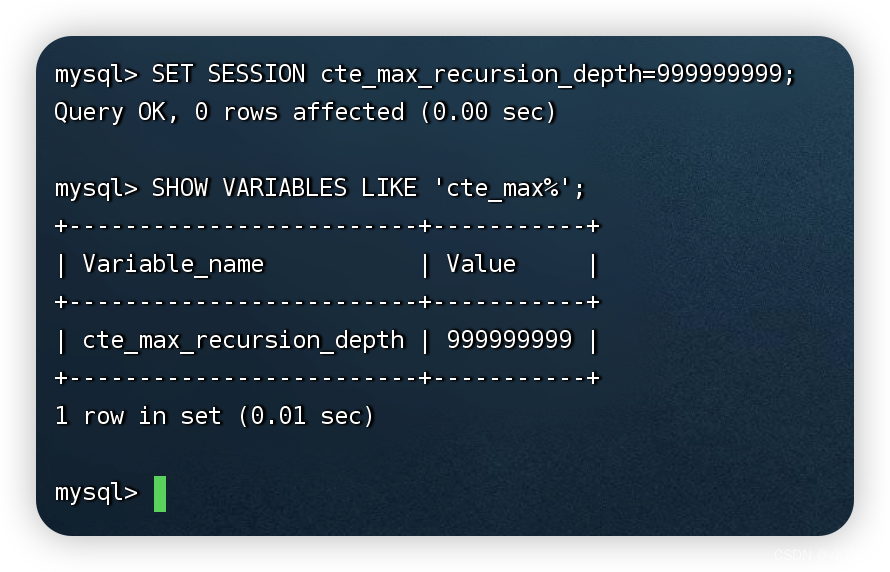
将cte_max_recursion_depth参数设置为一个很大的数字
SET SESSION cte_max_recursion_depth=999999999;
SHOW VARIABLES LIKE 'cte_max%';
查看MySQL中max_execution_time参数的默认值:
SHOW VARIABLES LIKE 'max_execution%';
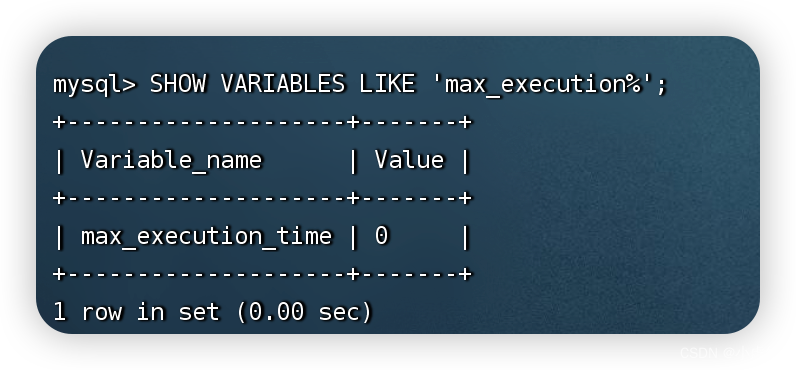
在MySQL中max_execution_time参数的值为毫秒值,默认为0,也就是没有限制。这里,在MySQL会话级别将max_execution_time的值设置为1s。
SET SESSION max_execution_time=1000;
SHOW VARIABLES LIKE 'max_execution%';
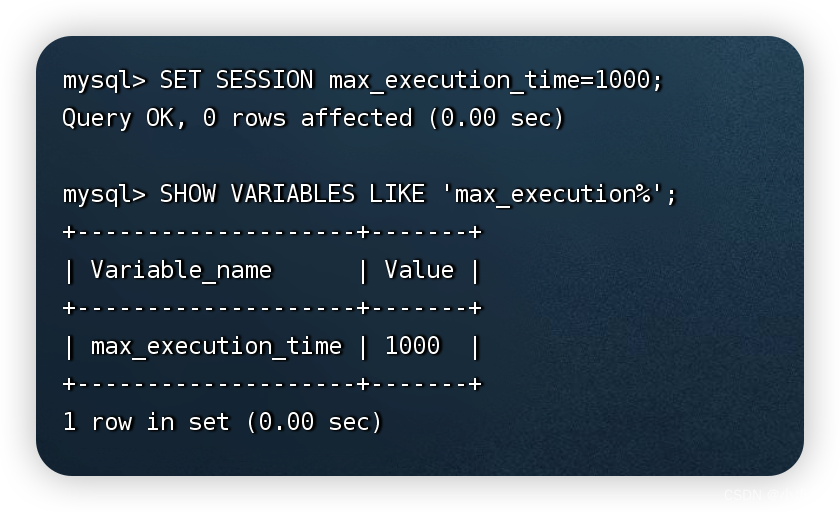
当SQL语句的执行时间超过max_execution_time设置的值时,MySQL报错。
WITH RECURSIVE cte(n) AS
(
SELECT 1
UNION ALL
SELECT n+1 FROM CTE
)
SELECT * FROM cte;
ERROR 3024 (HY000): Query execution was interrupted, maximum statement execution time exceeded
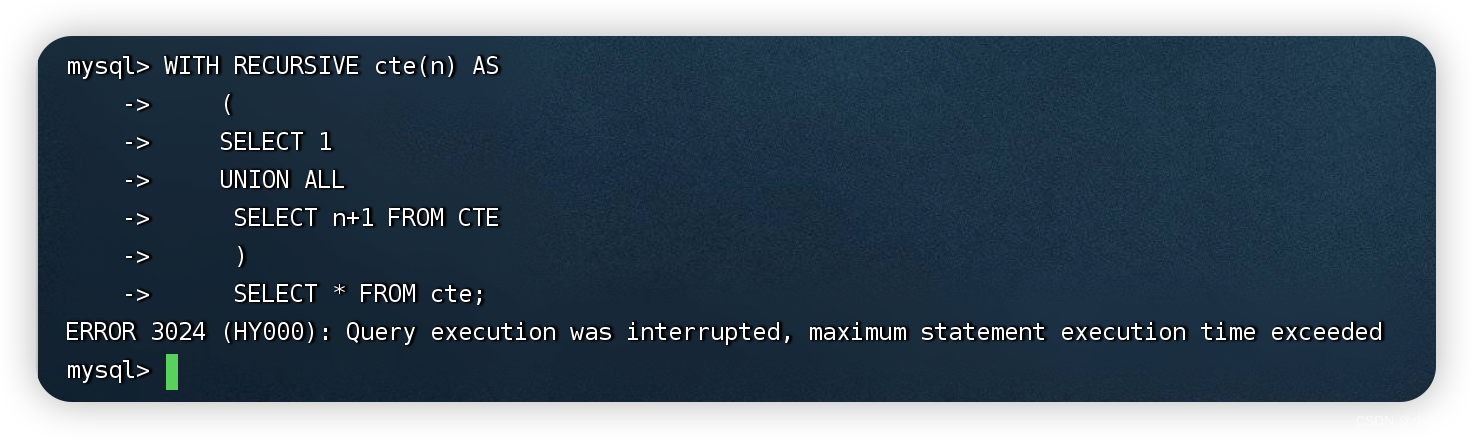
MySQL默认提供的终止递归的机制(cte_max_recursion_depth和max_execution_time配置项),有效地预防了无限递归的问题。
注意:根据实际的需求,自己在CTE的SQL语句中明确设置递归终止的条件。不能依赖MySQL默认提供了终止递归的机制。
本文分享了什么是CTE查询,并介绍了非递归CTE和递归CTE,并以实战例子介绍如何使用CTE。
递归查询是基于CTE的一种查询方式,它可以用来处理具有层次结构的数据,例如组织架构、树形结构等。递归查询通过递归地引用自身来实现层次结构的遍历和查询。
最后重点说明了递归CTE限制cte_max_recursion_depth和max_execution_time参数,这个在日常工作中要特别注意。
所以,嗯,这题的答案选。。评论区大声告诉虚竹哥。
我是虚竹哥,我们明天见~
我正在用Ruby编写一个简单的程序来检查域列表是否被占用。基本上它循环遍历列表,并使用以下函数进行检查。require'rubygems'require'whois'defcheck_domain(domain)c=Whois::Client.newc.query("google.com").available?end程序不断出错(即使我在google.com中进行硬编码),并打印以下消息。鉴于该程序非常简单,我已经没有什么想法了-有什么建议吗?/Library/Ruby/Gems/1.8/gems/whois-2.0.2/lib/whois/server/adapters/base.
我知道我可以指定某些字段来使用pluck查询数据库。ids=Item.where('due_at但是我想知道,是否有一种方法可以指定我想避免从数据库查询的某些字段。某种反拔?posts=Post.where(published:true).do_not_lookup(:enormous_field) 最佳答案 Model#attribute_names应该返回列/属性数组。您可以排除其中一些并传递给pluck或select方法。像这样:posts=Post.where(published:true).select(Post.attr
动漫制作技巧是很多新人想了解的问题,今天小编就来解答与大家分享一下动漫制作流程,为了帮助有兴趣的同学理解,大多数人会选择动漫培训机构,那么今天小编就带大家来看看动漫制作要掌握哪些技巧?一、动漫作品首先完成草图设计和原型制作。设计草图要有目的、有对象、有步骤、要形象、要简单、符合实际。设计图要一致性,以保证制作的顺利进行。二、原型制作是根据设计图纸和制作材料,可以是手绘也可以是3d软件创建。在此步骤中,要注意的问题是色彩和平面布局。三、动漫制作制作完成后,加工成型。完成不同的表现形式后,就要对设计稿进行加工处理,使加工的难易度降低,并得到一些基本准确的概念,以便于后续的大样、准确的尺寸制定。四、
目录第1题连续问题分析:解法:第2题分组问题分析:解法:第3题间隔连续问题分析:解法:第4题打折日期交叉问题分析:解法:第5题同时在线问题分析:解法:第1题连续问题如下数据为蚂蚁森林中用户领取的减少碳排放量iddtlowcarbon10012021-12-1212310022021-12-124510012021-12-134310012021-12-134510012021-12-132310022021-12-144510012021-12-1423010022021-12-154510012021-12-1523.......找出连续3天及以上减少碳排放量在100以上的用户分析:遇到这类
我正在尝试查询我的Rails数据库(Postgres)中的购买表,我想查询时间范围。例如,我想知道在所有日期的下午2点到3点之间进行了多少次购买。此表中有一个created_at列,但我不知道如何在不搜索特定日期的情况下完成此操作。我试过:Purchases.where("created_atBETWEEN?and?",Time.now-1.hour,Time.now)但这最终只会搜索今天与那些时间的日期。 最佳答案 您需要使用PostgreSQL'sdate_part/extractfunction从created_at中提取小时
我在Rails上使用带有ruby的solr。一切正常,我只需要知道是否有任何现有代码来清理用户输入,比如以?开头的查询。或* 最佳答案 我不知道执行此操作的任何代码,但理论上可以通过查看parsingcodeinLucene来完成并搜索thrownewParseException(只有16个匹配!)。在实践中,我认为您最好只捕获代码中的任何solr异常并显示“无效查询”消息或类似信息。编辑:这里有几个“sanitizer”:http://pivotallabs.com/users/zach/blog/articles/937-s
我正在为锦标赛开发一个Rails应用程序。我在这个查询中使用了三个模型:classPlayertruehas_and_belongs_to_many:tournamentsclassTournament:destroyclassPlayerMatch"Player",:foreign_key=>"player_one"belongs_to:player_two,:class_name=>"Player",:foreign_key=>"player_two"在tournaments_controller的显示操作中,我调用以下查询:Tournament.where(:id=>params
我想用sunspot重现以下原始solr查询q=exact_term_text:fooORterm_textv:foo*ORalternate_text:bar*但我无法通过标准的太阳黑子界面理解这是否可能以及如何实现,因为看起来:fulltext方法似乎不接受多个文本/搜索字段参数我不知道将什么参数作为第一个参数传递给fulltext,就好像我通过了"foo"或"bar"结果不匹配如果我传递一个空参数,我得到一个q=*:*范围过滤器(例如with(:term).starting_with('foo*')(顾名思义)作为过滤器查询应用,因此不参与评分。似乎可以手动编写字符串(或者可能使
我有一个随机大小的散列,它可能有类似"100"的值,我想将其转换为整数。我知道我可以使用value.to_iifvalue.to_i.to_s==value来做到这一点,但我不确定我将如何在我的散列中递归地做到这一点,考虑到一个值可以是一个字符串,或一个数组(哈希或字符串),或另一个哈希。 最佳答案 这是一个非常简单的递归实现(尽管必须同时处理数组和散列会增加一些技巧)。deffixnumifyobjifobj.respond_to?:to_i#IfwecancastittoaFixnum,doit.obj.to_ielsifobj
我经常迷上ruby的一件事是递归模式。例如,假设我有一个数组,它可能包含无限深度的数组作为元素。所以,例如:my_array=[1,[2,3,[4,5,[6,7]]]]我想创建一个方法,可以将数组展平为[1,2,3,4,5,6,7]。我知道.flatten可以完成这项工作,但这个问题是作为我经常遇到的递归问题的一个例子-因此我试图找到一个更可重用的解决方案。简而言之-我猜这种事情有一个标准模式,但我想不出任何特别优雅的东西。任何想法表示赞赏 最佳答案 递归是一种方法,它不依赖于语言。您在编写算法时要考虑两种情况:再次调用函数的情