北京时间:2023/4/3/7:06,刚刚晨跑回来,为了摆脱困意,刷了一下视屏,哈哈哈!我发现我每次刷视屏都是被迫的,都是看到某个感兴趣的标题,然后点进去一看,就不能自拔了,所以我下次得把消息提醒给全部关掉,烦人;并且全宿舍英文4级都报上了,就我没报上,真的是天命孤星啊!不对,有一个学日语的舍友也没报上,哈哈哈,开心,有人陪我啦!这里必须记录一下,我的神奇舍友4级日志,他不写,我帮他写,到时候成绩出来,必须记录在案!所以今天我们就承接着上篇博客,回顾一下文件系统的知识,然后了解什么是软硬链接,最后搞定动静态库。

上篇博客,我们知道大致了解了操作系统对磁盘的管理,通过日常生活中的分治思想,把磁盘进行分区,然后进行区内分组,最终对一个组进行管理,进而管理整个磁盘,所以操作系统如何进行分组管理就变得格外的重要啦!如下图:就是一个分组的管理属性信息
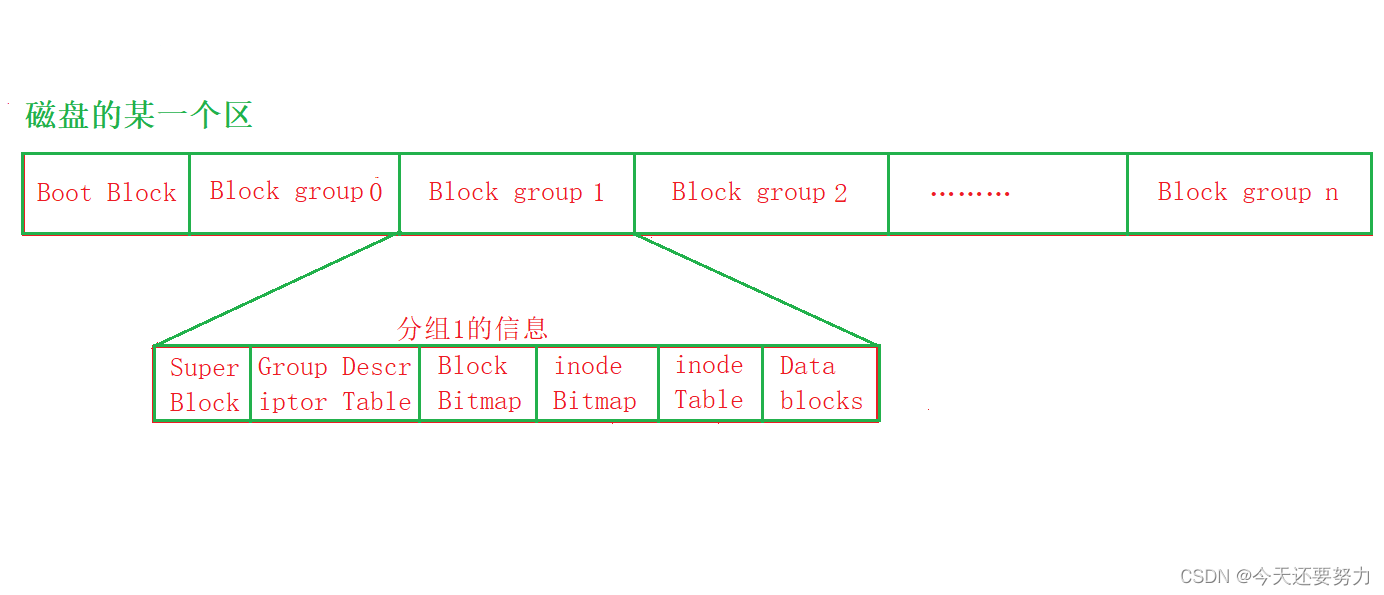
上图中每个组都是通过对应的属性信息就行管理的,这个也就是操作系统可以管理好每个组的重要原因,也就是文件系统的基础,通过不同的属性信息来进行对数据块的读写操作,如下表,就是文件属性信息作用和意义:
磁盘中分组的管理属性信息:
| 文件系统每个组中的属性信息详解表 |
|---|
| Block group:ext2文件系统会根据分区的大小划分为数个Block group,而每个Block group都有着相同的结构组成 |
| Super Block:存放文件系统本身的结构信息,记录的信息主要有:bolck 和 inode的总量,未使用的block和inode的数量等 |
| Group Descriptor Table(GDT):块组描述符,描述块组属性信息 |
| Block Bitmap:记录着Data Block中数据块的使用情况 |
| inode Bitmap:每个bit表示一个inode是否空闲可用,同理表示inode Table中众多inode的使用情况 |
| inode Table:存放文件属性 如 文件大小,所有者,最近修改时间等 |
| Data blocks:存放文件内容 |
注意: 此时在分区中的Boot Block是一段磁盘的固化代码,是不允许我们访问和修改的,并且要明白,Super Block是一个超级块,它包含了文件系统所有的属性信息,是该区文件系统最为重要的数据块,所以它是不允许出现错误的,所以它不可以放在分区中,而是要放在分组中,进行组内备份,以防分区中如果Super Block出现错误,导致整个区不能被使用,所以Super Block放在分组中的目的就是为了保护分区的安全性
在上篇博客中,我们明白了,inode就是一个文件的所有属性的集合,并且在分组中,也有一个特定的属性信息用来管理inode,它给每一个inode进行编号,然后对inode进行管理,它就是inode Table,所以说inode是一个文件的所有属性集合,那么inode Table就是所有文件,也就是整个文件系统的属性集合
明白了这点之后,我们引入一个概念,同理,一直说文件=内容+属性,并且此时明白inode就是属性集合,那么平时我们想要使用文件的时候(打开文件),怎么没看见什么inode呢?
这个就涉及到了inode一个最基本的映射关系,inode和文件名之间的映射关系,刚说过,inode是一个文件的所有属性集合,并且被inode Table进行编号管理,所以在Linux操作系统看来,它只认识inode的编号,也只能通过inode编号去对应磁盘分区的分组中的inode Table中找到该编号和Data Blocks的映射文件数据块,进而打开文件,所以文件的inode属性中,并不存在文件名!那么文件名在哪里呢?或者说文件名是干什么的呢?
明白了上述知识,我们就不难推测出,因为inode和文件名之间存在映射关系,所以文件名只是一个给用户使用的间接inode编号,用户只要找到文件名,就等于是找到了inode编号,进而操作系统通过该文件名对应的inode编号,就可以进行对文件的读写! 所以文件名存放在哪里呢?
想要搞懂上述问题,我们只差将文件名的存储位置搞明白了,搞明白了文件名的存放位置,我们就搞定了操作系统是如何管理一个磁盘分组,也就搞定了操作系统是如何管理整个磁盘了,所以想要搞懂这个问题,就又需要引入一个平时我们不怎么关心的知识,就是目录是文件吗?,它有inode吗?有内容吗?
引出这个问题,我们不难推测出,类似于文件存储数据一样,目录也是一个文件,它存储的数据就是一个一个文件,任何一个文件都是在某一个目录下的,所以我们就明白 文件名是存放在对应的目录在磁盘分组中的Data Blocks数据块中 ,并且在该目录下,对应的文件名和对应文件的inode编号具有映射关系,互为key值(可以使用文件名找到inode,也可以使用inode找到文件名)
在Linux系统上的基本使用场景:
例如,cat log.txt表示cat文件名,但是凭借文件名和inode的关系,此时也就是cat inode值,所以本质上cat log.txt就是通过文件名和inode编号的映射关系,去找到该文件名对应的inode,然后通过这个inode编号去磁盘的某个分区中寻找,最后就可以在该分区的某一个分组中的inode Table中找到这个对应的inode编号,然后通过这个编号,最终在该分组中的Data Block中,根据和inode编号之间的映射关系,找打对应编号的数据块,并且加载到操作系统中,最后通过操作系统显示到显示器上(被打开文件和进程之间的关系,这里不多做介绍)
总结: inode的属性集合中,并没有文件名,文件名是在对应的目录的数据块中构建的文件名和inode的映射关系,所以本质为什么inode和文件名具有映射关系,原因就是在目录分区的分组中的数据块构建了文件名和文件inode编号的映射关系。
1.删除文件
想要删除一个文件(rm指令):操作系统首先在该目录对应在磁盘分区分组中的数据块中,找到对应的文件名(同理,目录也是文件名,也具有inode编号),然后通过文件名找到inode编号,然后通过inode编号,最终在分区中找到对应分组中的inode Table,根据Data Block和inode Table的映射关系,找到对应的文件数据块,然后清零该文件数据,如果你是这样理解的,那么此时你就小看了文件系统,因为对一个磁盘数据块上的数据进行清零的工作,是比较复杂的,是需要耗费一定的时间的,但是你会发现,下载一个东西,很慢,卸载一个东西很快,这是为什么呢?
因为删一个文件,只要通过文件名拿到inode编号,然后在分组中找到inode Bitmap,然后 只要将inode Bitmap中对应的那个bit位由1置成0,此时就把对应的inode编号在inode Table中给删除了,间接就是等于将对应文件的所有属性给删除了(因为inode就是对应文件属性的集合),最终再将分组中的block Bitmap对应的bit位由1置成0,这样就把一个文件对应的内容也给删除了,这样就把一个文件的属性和内容都给删除了,所以删文件只要修改位图对应的比特位就行
2.创建文件
首先,我一定是在一个特定的目录下创建(因为文件名是需要存放在目录对应的inode数据块中),操作系统此时就根据该目录,在对应的目录所处的分组下,去查看该分组的inode Bitmap,如果发现,在该分组的inode Bitmap中还有相应的bit位是空闲的,此时就将该bit为置成1,然后根据是第几个bit位,最终获得一个新的inode编号,然后把新文件创建对应的属性放到inode Table中对应的inode结点当中,存储好之后,发现对应的文件是空的(因为没有对应的数据块),然后同理,通过该目录找到对应分组中的Data Blocks,并且在Data Blocks中将文件名和inode的映射关系,inode编号和Data Blocks的映射关系等数据存储到该分组数据块中,这样一个文件就创建好了
3.修改文件
所以同理,向文件中写入,还是使用文件名,然后找到inode编号,在对应的分组中通过inode和Data Blocks之间的映射关系在Data Blocks中找到该文件,最后根据数据的大小向block Bitmap申请空间(以块为单位)因为此时在该分组中的block Bitmap中一个bit位,代表的就是一个块(4kb),例如此时我们要写入的数据很大,此时就需要向其申请5个比特位(5个块)来存储,所以此时就将block Bitmap中的对应的bit位由0置成1,然后将这5个块对应的bit位的编号填入到inode Table中,然后凭借inode Table和data blocks对应映射关系将inode编号填入到数组中(数据块),最终将想要写入的数据写入到这5个块对应在Data Blocks数组中的数据块中
根据上述的原理,我们就明白了一个文件的删除和创建的具体过程,发现删除和创建数据并没有想象中的那么复杂(文件系统的好处),所以如果一个文件被误删了怎么办呢?按照上述的原理,如下:
很明显,最好的做法就是什么都不干,因为如果你不小心将原来在inode Bitmap中原文件使用的bit位给占用了,那么此时你的文件就真的完了,所以恢复的原则就是,只要知道曾经使用的inode编号,等于知道了该inode在inode Bitmap中的bit位,此时就有希望恢复出来,具体过程如下:
所以恢复一个文件的成本是不高的,但是是有难度的,所以不建议在Linux系统下删除文件,建议使用移动文件,例如,Windows下的回收站本质就是一个文件夹,我们在删除文件本质只是将相应不需要的文件移动到了另一个文件夹中而已;并且在Linux中,删除文件,有一个日志,这个日志会记录下被删除文件的文件名和inode,同理,只要有技术,还是可以把删除文件给恢复出来的,所以恢复文件的本质就是去恢复它的inode Bitmap和block Bitmap,然后通过inode Bitmap和block Bitmap与inode Table的关系,最终再通过inode Table和Data Blocks的映射关系,找到Data Blocks数组上的数据块
注意: inode编号,是在一个分区内有效,不能跨分区,一个区域,一套inode机制,一个分区,一套文件系统
原理:可以将每一个分组设置一个起始值,然后具体的inode对应在该分组中的位置是通过在inode Bitmap中的位置+该分组对应的起始位置确定的,这样就可以找到该文件在分区上的inode编号,例如,一个分区中有100万个inode,此时我们就可以通过分组,1到10万位第一组,10万到20万位第二组,……,那么此时假如有一个inode编号是45万,那么此时我们可以通过一个分组是10万,确定该inode编号是在第五组之中,所以根据除法(/)我们是很容易的可以确定一个inode在分区中的位置(具体在那个组)
上述我们学的分区、分组,填写系统属性,具体是谁做的呢?显然是操作系统,哪么什么时候做的呢?
分区完成之后,后面要让分区能够被正常使用,我们就需要对分区做格式化,格式化的过程,其实是操作系统向分区写入文件系统的管理属性信息(也就是 inode Bitmap、block Bitmap、inode Table等),如果我们的文件系统中的管理属性信息已经拥有数据了,此时还进行格式化,那么就是等于删除数据,重装系统,就是等于,将位图结构全部置0,data blocks和inode table是不需要管理的,本质原因文件系统
所以格式化之后,我们是不可能再重新找到数据的,只有磁盘厂商,它可以通过默认将 inode Bitmap和block Bitmap对应的bit位是1,然后一个一个的和inode table中的校验和进行匹配比较,最终将磁盘上的数据重新读取出来(因为本质磁盘上Data Blocks和inode Table是还存在的,只是你没有途径去寻找而已)就好比,你知道一个地方有宝藏,但是你没有地图,此时你就只能一条路一条路的走,碰运气去寻找
总结:像一些大公司在清除云服务器或者是磁盘上的数据是没有上述的文件系统的概念的,而是必须把磁盘或者云服务器上的数据全部清空,所以只有像上述的,通过对应的bit位去寻找数据块上的数据的方式,我们才叫做文件系统
搞定了上述的知识之后,我们就来看一看inode和Data Blocks之间到底是如何构成映射关系的,首先我们明白inode是一个结构体,所以平时我们在Linux系统中使用的指令,例如:ls、ll用来显示文件属性文件名,它们的本质就是去找到inode就行了,找到inode结点,然后获取inode结点对应的文件属性信息,但是像cat log.txt它就不仅要去找inode,它还要去找inode对应的数据块,所以如下图,就是一个inode寻找对应数据块的详解图:
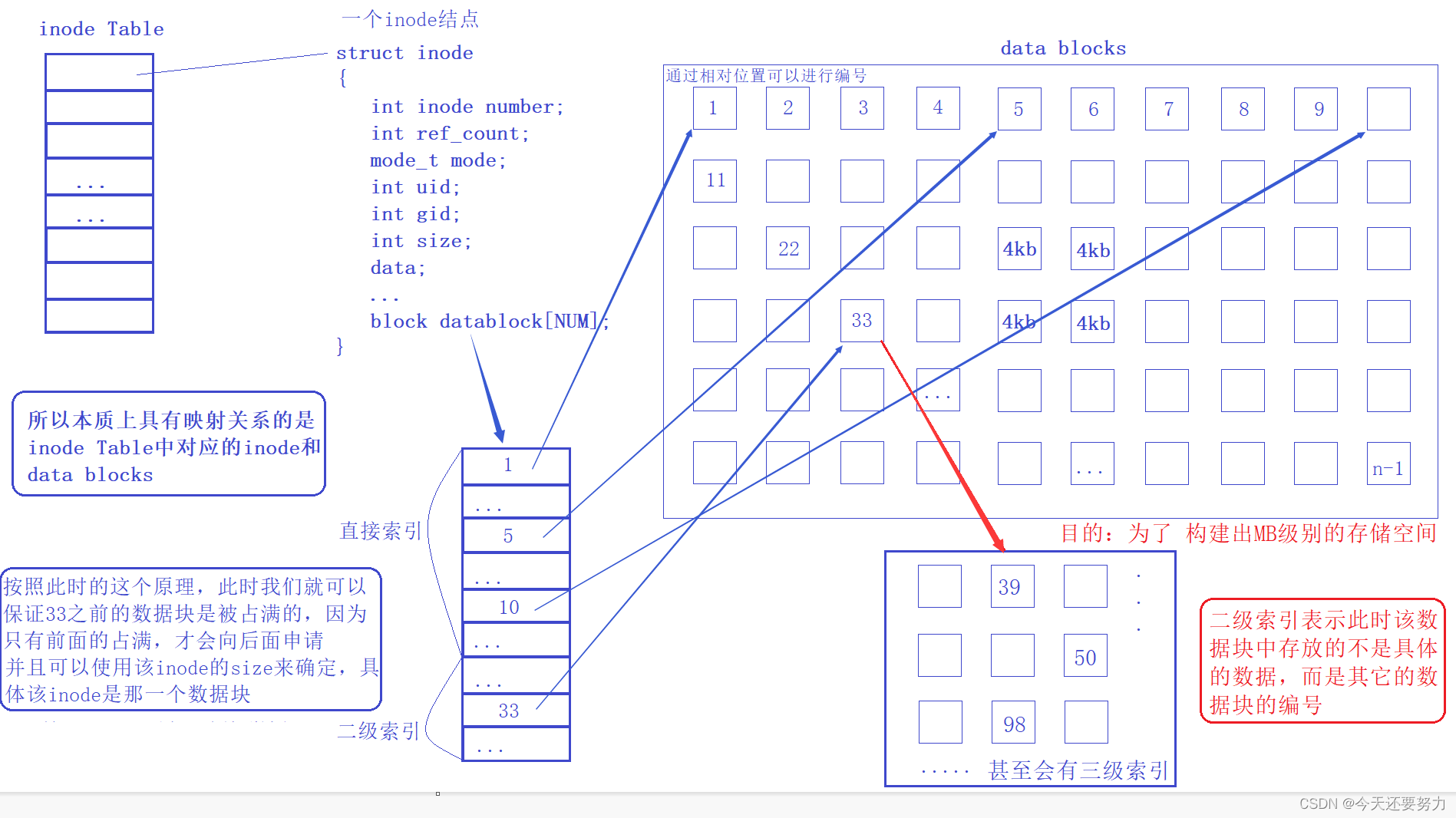
可以发现,inode结点中有非常多的文件属性信息,并且通过inode和data blocks之间的映射关系,我们可以很好的找到对应的数据块,并且因为有些文件可能很大,所以文件系统是支持二级索引和三级索引来支持我们存放GB级别的数据。
搞定了上述的知识,文件系统的知识就差不多都搞定了,现在,我们就来看一看什么是软硬链接吧!
在学习软硬链接之前,我们先了解一下如何获取一个文件的inode编号,指令:ls -li,如下:

什么是软链接,首先软链接的本质肯定是一种链接方式,是一种文件的链接方式,指令:ln -s,具体如下所示:


此时通过ln -s指令,通过软链接的形式建立一个和原文件myfile.c有映射关系的文件my_soft(后者链接前者),所以软链接的本质就是建立一个和原文件有映射关系的文件,类似于inode和文件名之间的互为key关系,此时新建立的软链接(也就是原文件的映射文件),代表的就是该文件,如下:
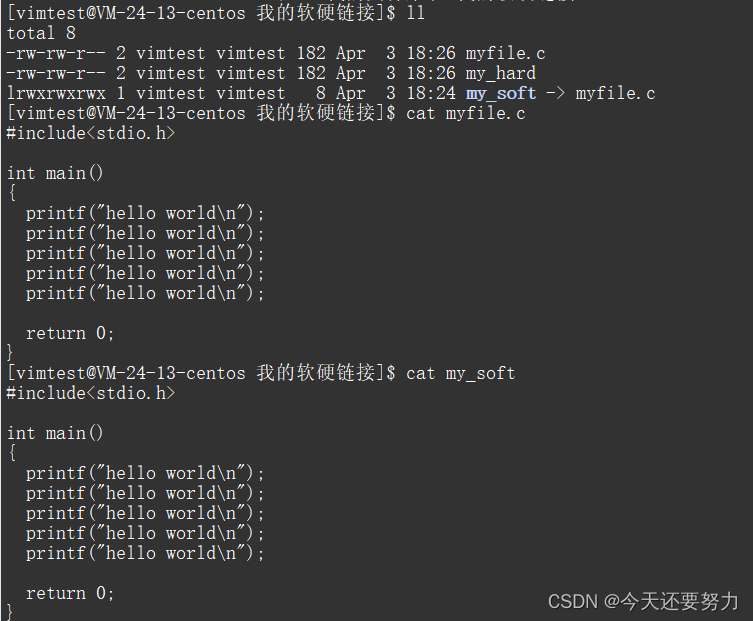
可以发现原文件和原文件进行软链接之后的映射文件中的内容是一样的,表示映射文件和原文件此时代表的就是磁盘中分区分组中的同一个数据块的数据
但是要注意: 软链接本质上还是一个独立的链接文件,有自己的inode编号和自己的inode属性集合
并且,软链接的inode结点内部放的是自己所指向的文件的路径,所以此时通过软链接建立的映射关系,就是通过该文件的路径建立的,找打该软链接文件就是等于找到了原文件的路径,也就是等于找到了原文件。
同理软链接,硬链接的指令:ln,如下图:

同理软链接,目的就是为了建立文件之间的映射关系,但是注意: 硬链接和目标文件是共用同一个inode编号,意味着硬链接一定是和目标文件使用同一个inode的,所以通过硬链接的映射文件,本质上只是原文件的一个拷贝而已,因为它们的属性集合是一样的,并且区分inode编号和inode,inode是文件属性的集合,而inode编号只是一个数字而已,两者是不同的,一个是结构体类型,一个是整形。
所以硬链接的本质就是:建立新的文件名和老的inode的映射关系,就是在当前该文件所处的目录下,在磁盘对应的分组中找到该目录对应的数据块,然后在该数据块中写入新文件名和老的inode之间的映射关系(所以硬链接只是修改了目录对应数据快的内容而已)
硬链接的具体原理:

软链接作用
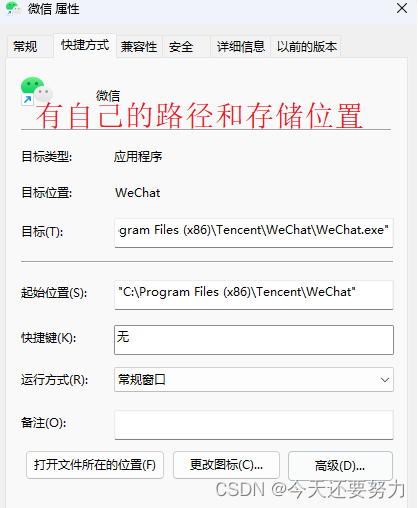
明白了上述的知识,我们就知道了什么是软链接,什么是硬链接,接下来,我们就来看看它们具体有什么作用呢?例如,在Windows系统中图形化界面各个软件的快捷方式,所以明白了这个点,我们就明白了,其实在Windows系统中,这些软件的快捷方式,本质上就是一个一个的软链接,如下图所示:

如上图,使用了软链接之后,我们就可以将一个很深的目录下的文件,直接通过软链接的方式,在当前路径下使用,因为使用软链接之后,被映射文件是被存放在了当前路径下,所以无论原文件是在那个目录下,当前目录下,我们都可以正常的使用它的映射文件,所以这个就是Linux系统下软链接的一个好处,目的:快速访问文件
并且如上述所说 ,软链接之后,链接文件是具有自己的inode属性集合的,所以无论是在我们的Linux系统中还是Windows系统中,这点都是可以看到的,如下图:
Linux系统:

Windows系统:
硬链接作用
回顾,硬链接本质干了什么:获取目标文件(被链接文件)的inode,然后只需要在当前目录(目录=文件)对应在磁盘上分组中的Data Blocks数据块中创建新文件的文件名和inode的映射关系就行,并且硬链接只维护文件名和inode的映射关系,所以说明,一个文件的inode属性集合中一定有一个关于硬链接被链接的次数的一个属性(引用计数),共用inode,所以硬链接类似浅拷贝,如下图:硬链接的使用场景

上述我们介绍过了,每当该文件被硬链接一次,inode属性中的引用计数就会加加,所以可以发现普通文件由于只和自己本来就存在的inode进行了链接,所以此时inode中的引用计数就是1,但是此时就有一个问题,就是为什么目录文件不是1而是2呢?
原因就涉及到了我们硬链接的使用方式和目录文件的一个特殊之处,就是目录就算是一个空目录,此时目录中也是有文件的,隐藏目录,如下图所示:指令:ls -al

一个.表示当前路径,也就是dir目录,两个..表示上一路径,也就是上一目录的上一目录,此时我们将dir目录文件的inode打印出来和当前路径.的inode打印出来,发现两者的inode是一样的,如下图:
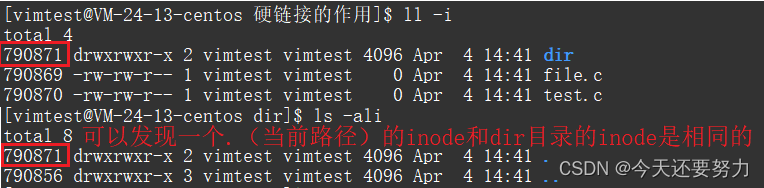
所以得出结论,目录下的隐藏文件中表示当前路径的文件,本质就是一个和当前目录进行了硬链接的映射文件,它们共用同一个inode,所以导致dir目录的inode属性中的引用计数是2(被dir目录本身和隐藏文件.分别建立了映射关系)
总:所以一个.可以被认为是当前路径的原因就是因为它和当前目录的inode建立了硬链接(具有映射关系)
两个点..同理
注意: 目录文件是不允许我们建立硬链接的,我们只允许对普通文件建立硬链接,而像上述所示的隐藏文件.和..目录文件之所以可以进行硬链接的原因是因为,系统规定好了,所以只有操作系统允许建立硬链接,而用户是不允许建立硬链接,具体原因如下图:
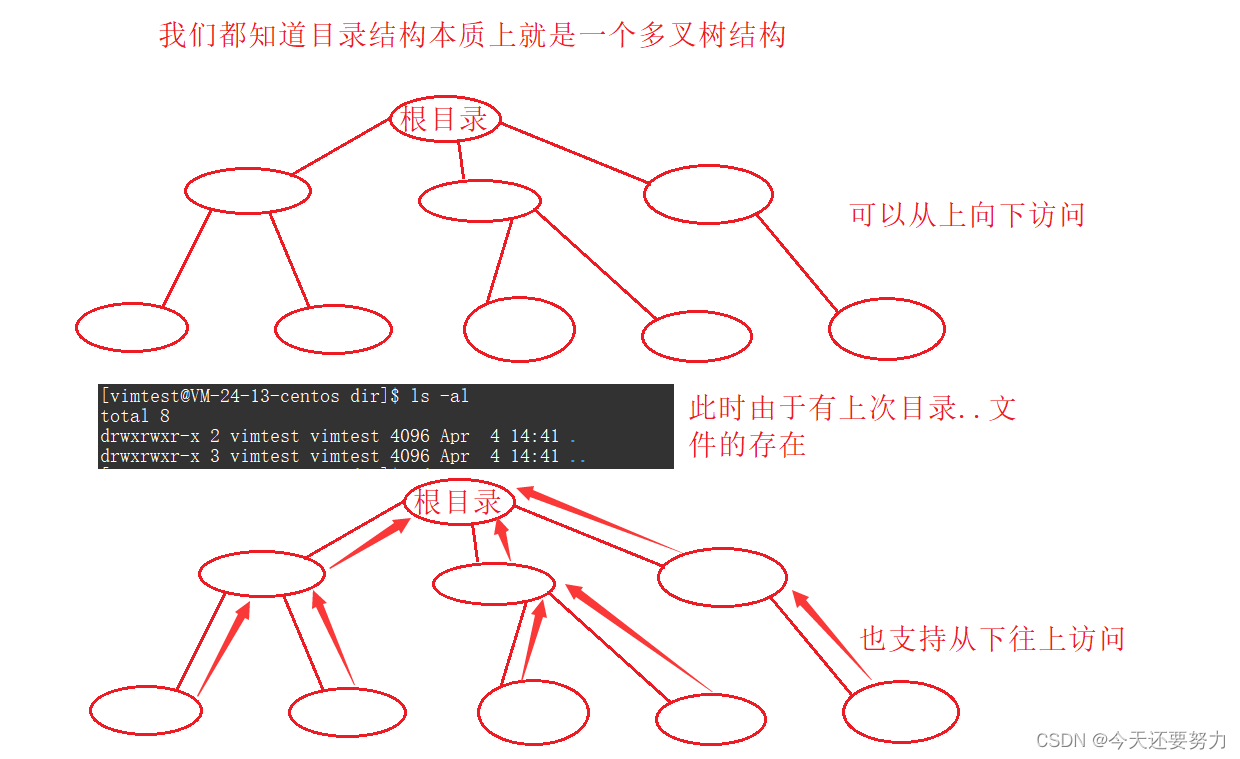
如上图所示,我们可以知道在所有的目录文件中都是存在当前路径和上级路径的隐藏文件的,所以导致不仅可以从上级文件向下级文件访问,也可以从下级文件向上级文件访问,所以如果此时我们自己可以进行目录硬链接的创建,操作系统可能就会分不清是隐藏目录文件还是普通目录文件,此时就可能会导致环状问题
学习动静态库之前,了解一下文件的三个时间,如下图:
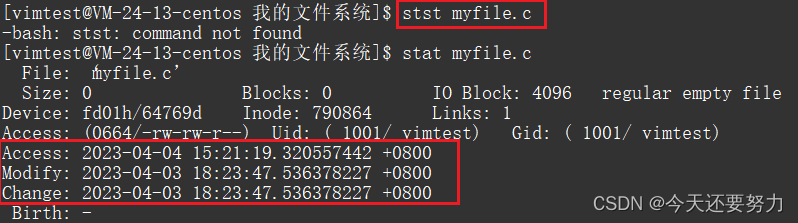
Access/Modify/Change,查看文件时间指令:stat file.c
上述三个时间分别表示:
Change:表示的是文件属性被更改的时间
Modify:表示的是更改文件的内容,但是注意:更改内容会对应把相应的属性更改(大小),所以改内容,Change对应的时间,也会发生改变
Access:表示的是对文件进行访问的时间,只要对文件进行访问,这个时间就有可能发生改变,注意:是有可能发生改变,因为访问文件的频率较高,所以为了提高操作系统的效率,系统会减少对这个时间的修改,并不是你访问了该文件,这个时间就发生改变,而是按照一定的操作系统的策略进行改变
生态好不好决定了一个语言好不好,库好不好决定了应用场景好不好,例如,STL库的生态,非常的优异
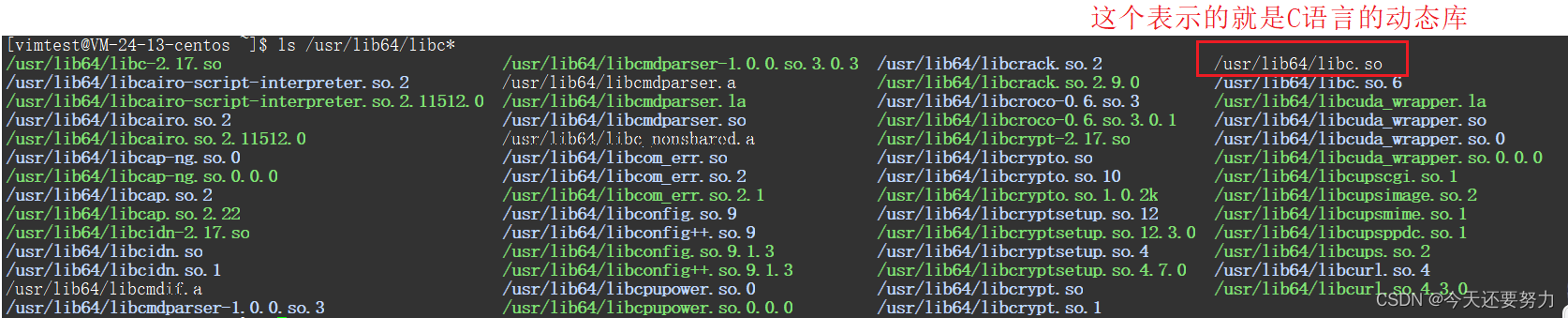
libc.a表示的就是C语言的静态库
libc.so表示的就是C语言的动态库
……

几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
电脑0x0000001A蓝屏错误怎么U盘重装系统教学分享。有用户电脑开机之后遇到了系统蓝屏的情况。系统蓝屏问题很多时候都是系统bug,只有通过重装系统来进行解决。那么蓝屏问题如何通过U盘重装新系统来解决呢?来看看以下的详细操作方法教学吧。 准备工作: 1、U盘一个(尽量使用8G以上的U盘)。 2、一台正常联网可使用的电脑。 3、ghost或ISO系统镜像文件(Win10系统下载_Win10专业版_windows10正式版下载-系统之家)。 4、在本页面下载U盘启动盘制作工具:系统之家U盘启动工具。 U盘启动盘制作步骤: 注意:制作期间,U盘会被格式化,因此U盘中的重要文件请注
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
网络编程套接字网络编程基础知识理解源`IP`地址和目的`IP`地址理解源MAC地址和目的MAC地址认识端口号理解端口号和进程ID理解源端口号和目的端口号认识`TCP`协议认识`UDP`协议网络字节序socket编程接口`sockaddr``UDP`网络程序服务器端代码逻辑:需要用到的接口服务器端代码`udp`客户端代码逻辑`udp`客户端代码`TCP`网络程序服务器代码逻辑多个版本服务器单进程版本多进程版本多线程版本线程池版本服务器端代码客户端代码逻辑客户端代码TCP协议通讯流程TCP协议的客户端/服务器程序流程三次握手(建立连接)数据传输四次挥手(断开连接)TCP和UDP对比网络编程基础知识
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
我完全不是程序员,正在学习使用Ruby和Rails框架进行编程。我目前正在使用Ruby1.8.7和Rails3.0.3,但我想知道我是否应该升级到Ruby1.9,因为我真的没有任何升级的“遗留”成本。缺点是什么?我是否会遇到与普通gem的兼容性问题,或者甚至其他我不太了解甚至无法预料的问题? 最佳答案 你应该升级。不要坚持从1.8.7开始。如果您发现不支持1.9.2的gem,请避免使用它们(因为它们很可能不被维护)。如果您对gem是否兼容1.9.2有任何疑问,您可以在以下位置查看:http://www.railsplugins.or
因为我现在正在做一些时间测量,我想知道是否可以在不使用Benchmark类或命令行实用程序time的情况下测量用户时间或系统时间。使用Time类只显示挂钟时间,而不显示系统和用户时间,但是我正在寻找具有相同灵active的解决方案,例如time=TimeUtility.now#somecodeuser,system,real=TimeUtility.now-time原因是我有点不喜欢Benchmark,因为它不能只返回数字(编辑:我错了-它可以。请参阅下面的答案。)。当然,我可以解析输出,但感觉不对。*NIX系统的time实用程序也应该可以解决我的问题,但我想知道是否已经在Ruby中实