市场交易者频繁买卖波动性资产,目标是最大化其总回报。每次买卖通常都会有佣金。 两种这样的资产是黄金和比特币。
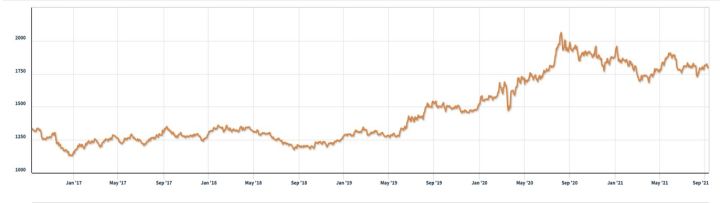
图 1:黄金每日价格,每金衡盎司美元。 资料来源:伦敦金银市场协会,2021 年 9 月 11 日
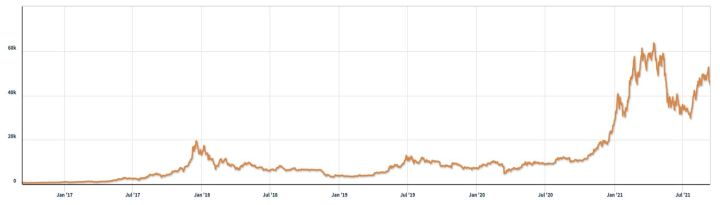
图 2:比特币每日价格,每比特币美元。 资料来源:纳斯达克,2021 年 9 月 11 日
要求
一位交易员要求您开发一个模型,该模型仅使用迄今为止的每日价格流来确定交 易员每天是否应该购买、持有或出售其投资组合中的资产。
2016 年 9 月 11 日,您将从 1000 美元开始。 您将使用五年交易期,从2016 年 9 月 11 日至 2021 年 9 月 10 日。 在每个交易日,交易者将拥有一个由现金组成的投资组合,黄金和比特币 [C, G, B] 分别以美元、金衡盎司和比特币表示。 最初的状态为 [1000, 0, 0]。 每笔交易(购买或销售)的佣金成本为交易金额。 假设 αgold = 1% 和 αbitcoin = 2%。 持有资产没有成本。
请注意,比特币可以每天交易,但黄金仅在市场开放日交易,定价数据文件反映 LBMA-GOLD.csv 和 BCHAIN-MKPRU.csv 这两点,你的模型应该考虑这个交易时间表。
要开发模型,您只能使用提供的两个电子表格中的数据:LBMA-GOLD.csv 和 BCHAIN-MKPRU.csv。(官网提供下载)
• 开发一个模型,该模型仅根据当天的价格数据提供每日的最佳交易策略,使用你的模型和策略,在 2021 年 9 月 10 日,初始 1000 美元能收获的投资价值多少?
• 提供证据证明您的模型提供了最佳策略。
• 确定策略对交易成本的敏感程度。 交易成本如何影响策略和结果?
• 最多以一份备忘录(两页)的形式将您的策略、模型和结果传达给交易者
语言:python3.8
编译器:SPSSPRO Notebook
下载链接:SPSSPRO Notebook(免费在线使用,推荐使用)
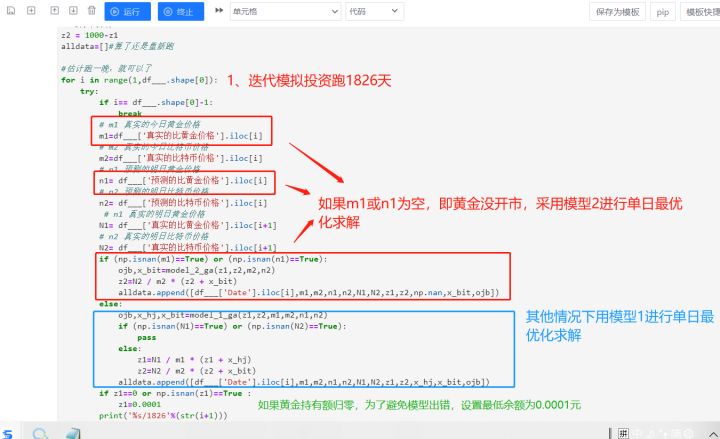
首先,我们先整理和数据,因为比特币每天都开市,黄金有时间开市,有时间闭市,把他们整理成时间线对齐,可以用缺失值代表闭市日等等。
我们可以根据预测未来走势来对(买入或者出售或保持)这三种交易活动进行决策,因此,接着我们可以针对黄金、比特币进行时序预测,基于当天数据或以往数据去预测明天的价格走势,进而更好地做决策。
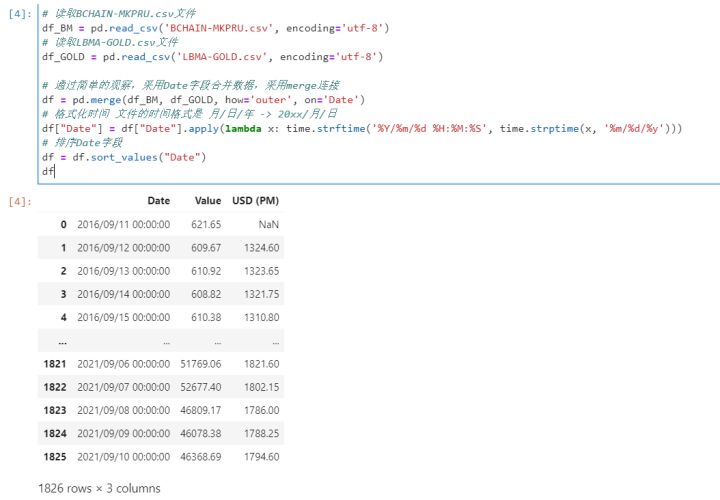
然后先针对第一天,基于预测的明天价格,构建一个目标规划,目的是实现已经知道第二日的价格后,如果投入才能实现当前交易日价格的最大化,其中交易的真实利益可以根据基于预测价格实施的投资策略后,通过真实第二天价格计算当天投资策略的盈利,然后重复这个过程,直到持有金额败光或者5年交易期结束,停止循环。
接着,对模型中出现的超参数进行灵敏度分析,例如设置了初始黄金的持有量是各500,如果调整这个比例,那么投资额度是否波动平稳?
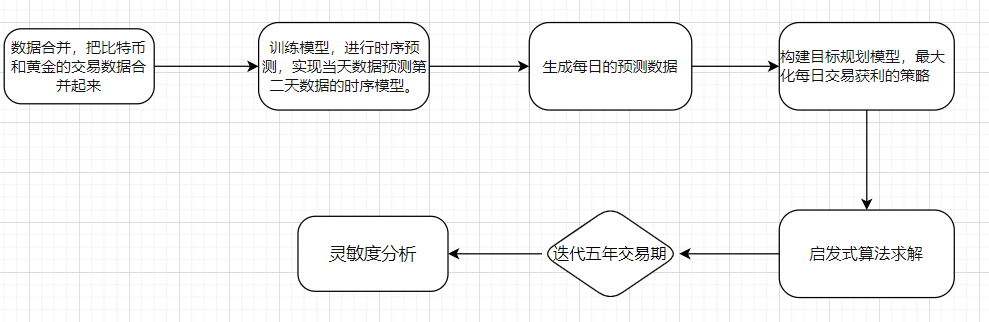
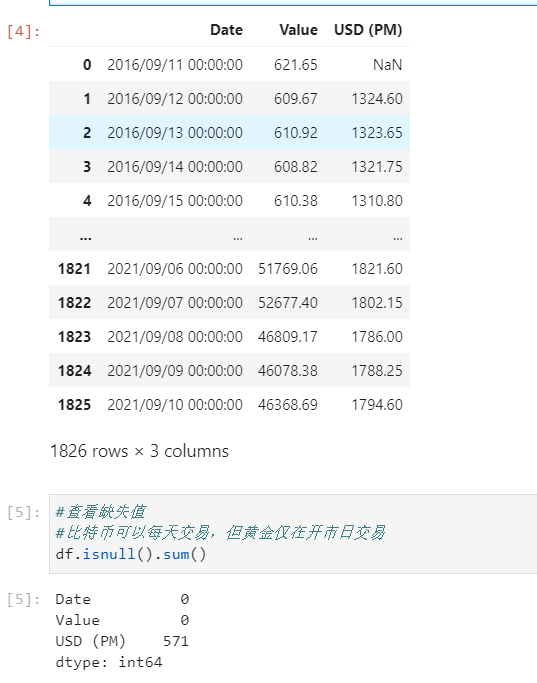
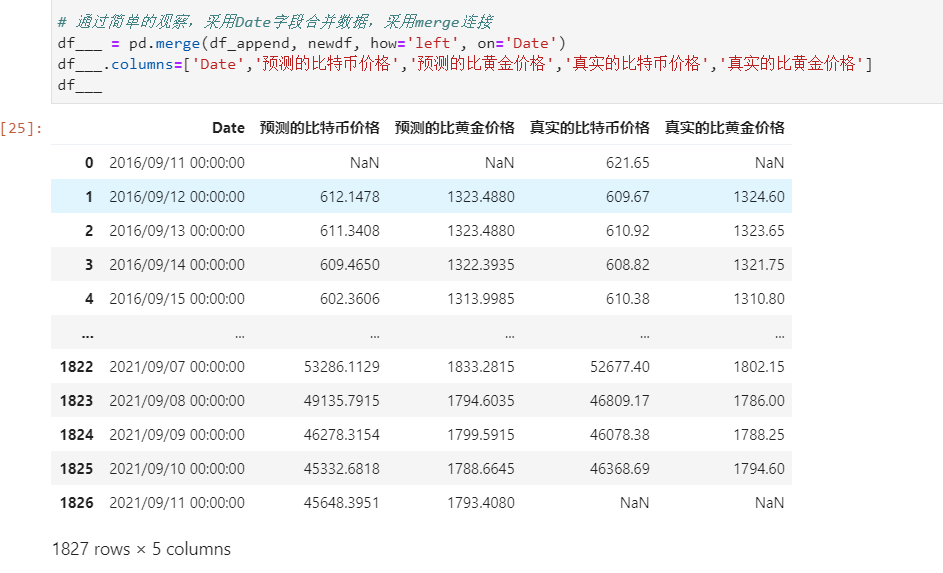
首先先把比特币和黄金的交易数据合并起来,通过简单的观察,以Date字段为关联字段,合并数据,采用merge连接,可以得到以下数据,可以看到,一共有1826行样本。
将合并后数据进行查看确实值,可以看到,黄金存在缺失值,且缺失了571个数值,这是因为比特币可以每天交易,但黄金仅在开市日交易导致的
根据题目要求,开发一个模型,该模型仅根据当天的价格数据提供每日的最佳交易策略,因此,我们需要训练一个能基于当天数据预测第二天数据的时序模型。
对于时间序列问题,目前业界有两种求法:
1、学术界常用计量统计模型,如arima模型、灰色预测模型、指数平滑等等,这类需要进行非常严格的模型检验
2、工业界统计模型,大多采用机器学习进行时间序列问题求解,例如lstm,xgboost等,通常做法也是2种,一种是单序列求解,将单序列转为多序列回归,另外就是构建特征工程,直接研究回归问题。
这里我们采用工业界模型,也就是机器学习时序预测,在这之前,我们需要了解一个数据处理的方法——时序数据滑窗转换。
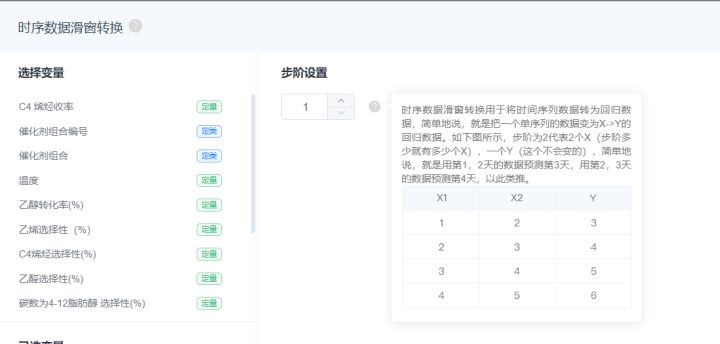
时序数据滑窗转换用于将时间序列数据转为回归数据,简单地说,就是把一个单序列的数据变为X->Y的回归数据。步阶为2代表2个X(步阶多少就有多少个X),一个Y(这个不会变的),
简单地说,就是用第1,2天的数据预测第3天,用第2,3天的数据预测第4天,以此类推。
大家可以用spsspro的数据处理的时序数据滑窗转换实现
SPSSPRO-数据处理
时序数据滑窗转换
我这里也写了一个代码实现,只不过效率会差些。dataset, look_back
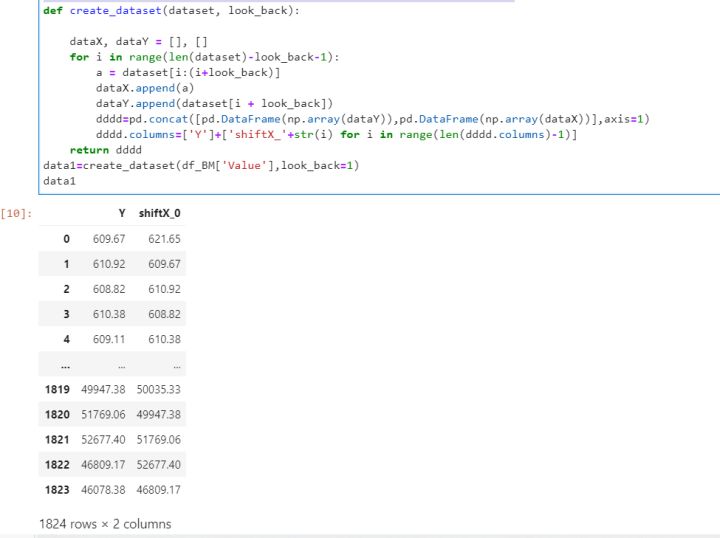
其中,dataset为数据集, look_back为步阶,如上图所示,为比特币步阶为1时的滑窗转换结果。
可以采用SPSSPRO的随机森林回归,使用起来也更简单,而且输出的结果和图表比较精美,这里建议大家多跑几个算法对比效果,推荐XGBooST、LGBM、随机森林回归这三项。
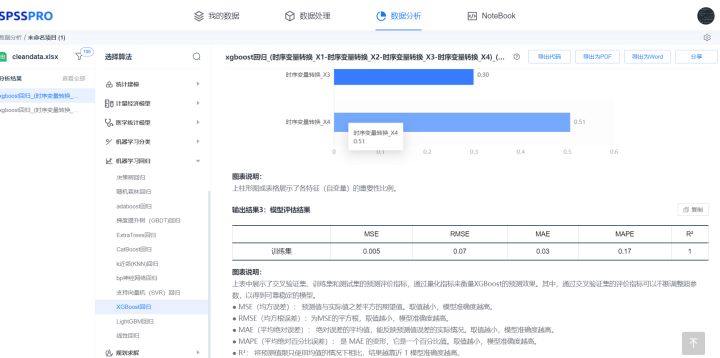
这里我采用代码采用随机森林对比特币进行时序数据训练进行示例,结果如下,可以看到,R2为0.994,拟合效果较为优秀。
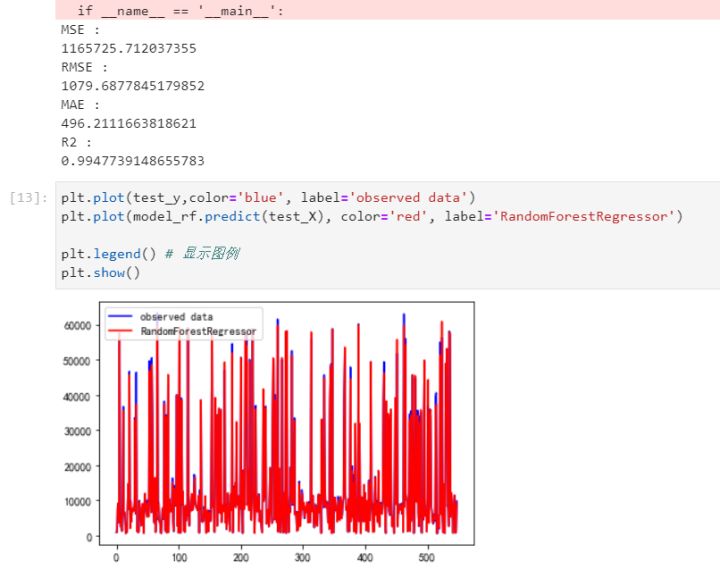
同理,得到黄金的预测模型,注意黄金数据需要剔除缺失值,但是不要在原有数据上剔除。
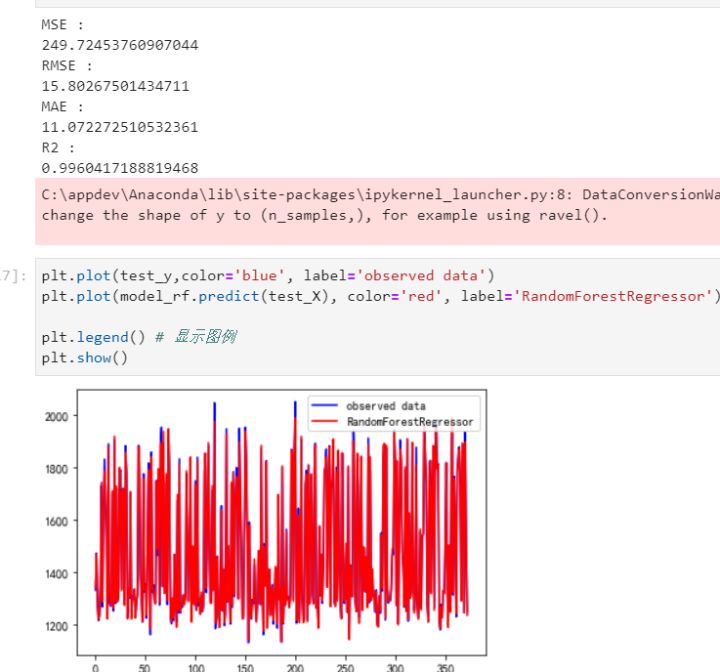
接着,重复构建训练模型,用第1天的黄金、比特币数据预测第2天的黄金、比特币,用第1、2天的黄金、比特币数据预测第3天的黄金、比特币、用第1、2、3天的黄金、比特币数据预测第4天的黄金、比特币依次类推。
得到每天的预测数据,同时与真实的数据进行合并,整理得到以下表格。
在进行预测后,我们需要得到买入-出售-保持这样的交易策略,其中,黄金仅在开市日的交易,这说明在周末或者节假日,交易状态一定是持有,可以分别保留黄金和比特币的共同交易日数据来进行分析。假设黄金-比特币是同买同卖的,主要设计到的是一个收益率这样一个时间序列数据,比如,我们可以在任一一天进行买入,我们可以用(预测某天金子的价格/购买金子的实际价格-1)来得到收益率,当涨幅达到某个值的,建议卖出。
注意:初始状态为【1000,0,0】,并且每笔交易(购买或出售)的交易成本为交易金额的a%,其中黄金为1%,比特币为2%,那么,对于1000美金,买入卖出两个步骤,我们实际进行的交易金额只有940美金。
建立简单目标规划:
假设t是买入到卖出这段时间
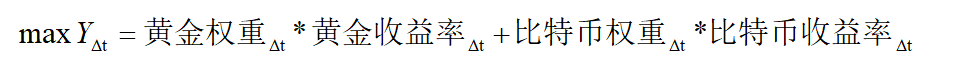
由于买入-售出是在不断进行的,我们需要建立循环来进行运行。
为达到更加完美的结果,更贴合实际,可以添加金融风险性的分析,类似VaR、CVaR、又或者是信息熵的使用,在建立完美的投资模型后,我们可以用来优化算法来对权重进行寻优,比如粒子群法、遗传算法、免疫算法等等。
即:我们需要设定好目标函数,也就是每日收益的最大化,设立相关约束条件,求解规划求解结果,以及规划求解方程导出。
我们设置以下变量

变量设置
而我们的目标就是根据预测模型与限定的一些约束条件中,得到每天的最佳投资策略,然后重复这个过程,直到在 2021 年 9 月 10 日,初始 1000 美元能收获的投资价值多少?
可以简单设置一个规划模型:其中,如果是黄金和比特币都开市,则目标函数为:
每日收益=(第二天的黄金价格/今天的黄金价格)*(前一天的黄金持有数+当天的黄金交易数)+(第二天的比特币价格/今天的比特币价格)*(前一天的比特币持有数+当天的比特币交易数)
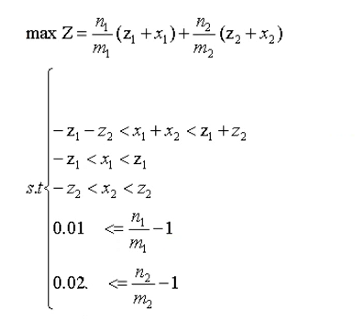
约束条件有:
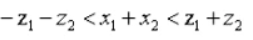
约束1:当天的黄金、比特币交易数不得超过总持有量
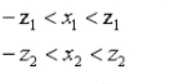
约束2:当天的黄金、比特币交易数不得超过前一天各自的持有量
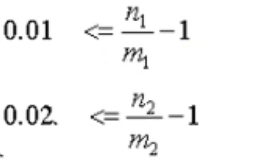
约束3:高于税费才交易
还有其他约束,大家可以自行补充。
如果只有比特币开市,则目标函数为:
每日收益=前一天的黄金持有数+(第二天的比特币价格/今天的比特币价格)*(前一天的比特币持有数+当天的比特币交易数)
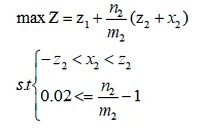
单天最优解遗传算法求解

设置初始参数
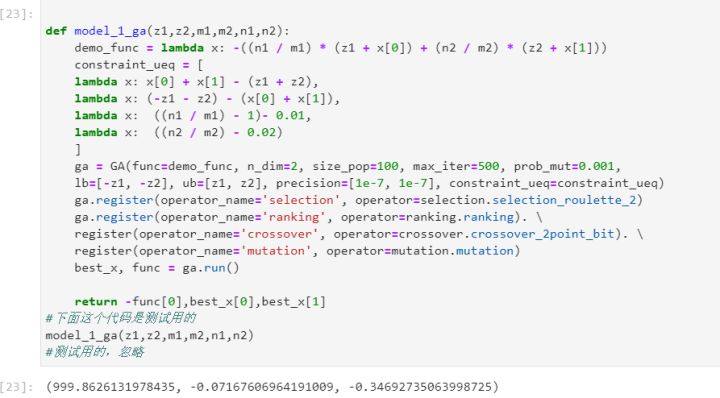
第一个目标函数求解结果
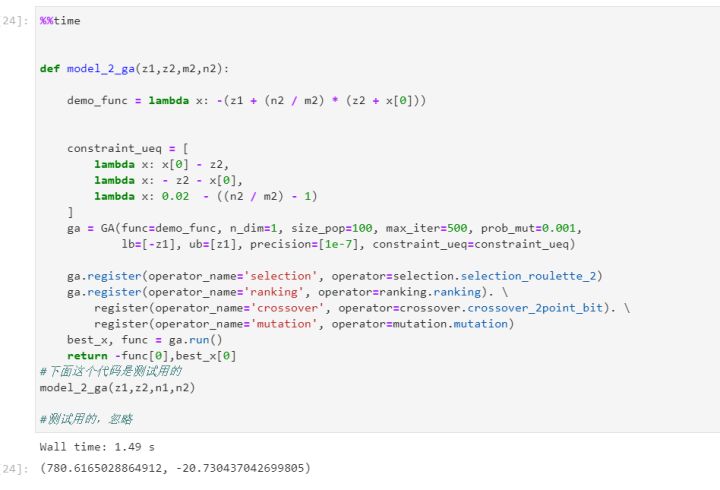
第二个目标函数求解结果
SPSSPRO-Notebook
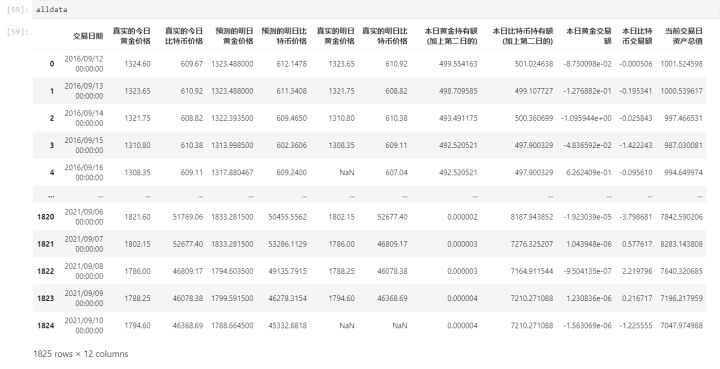
即最终持有投资额为7047.974988元。
当然我这个数值比较低是因为跟投资的约束条件有关,这里我只是简单列一下容易模型化的约束条件,大家可以自行进行补充,跑出更优秀的结果。
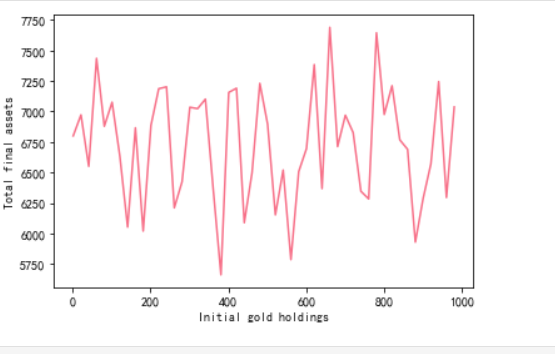
灵敏性分析
第三题的原理其实就是灵敏度分析,前面第一二题我们不是设置了初始黄金的持有量是一半一半各500,第三题灵敏度分析,它其实就是对这一些手动设置的参数进行分析,就像假设我黄金一开始持有量是100,会不会影响到最终的结果,所以我们可以看到那张图x轴是黄金开始的一个持有量,y轴就是经过5年交易期结束后的资产总额了,可以看到,他其实是再6750左右上下波动,说明模型的稳健性很强,对最终的资产总额结果不会有很灵敏的影响。
以上,全部的代码、题目数据可以通过下面免费获取,关注SPSSPRO社区账号【跟着欢欢玩转数模】:
作者创作不易,大家觉得有用的点赞收藏关注三连呗。
我有一个字符串input="maybe(thisis|thatwas)some((nice|ugly)(day|night)|(strange(weather|time)))"Ruby中解析该字符串的最佳方法是什么?我的意思是脚本应该能够像这样构建句子:maybethisissomeuglynightmaybethatwassomenicenightmaybethiswassomestrangetime等等,你明白了......我应该一个字符一个字符地读取字符串并构建一个带有堆栈的状态机来存储括号值以供以后计算,还是有更好的方法?也许为此目的准备了一个开箱即用的库?
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在使用ruby1.9解析以下带有MacRoman字符的csv文件#encoding:ISO-8859-1#csv_parse.csvName,main-dialogue"Marceu","Giveittohimóhe,hiswife."我做了以下解析。require'csv'input_string=File.read("../csv_parse.rb").force_encoding("ISO-8859-1").encode("UTF-8")#=>"Name,main-dialogue\r\n\"Marceu\",\"Giveittohim\x97he,hiswife.\"\
简而言之错误:NOTE:Gem::SourceIndex#add_specisdeprecated,useSpecification.add_spec.Itwillberemovedonorafter2011-11-01.Gem::SourceIndex#add_speccalledfrom/opt/local/lib/ruby/site_ruby/1.8/rubygems/source_index.rb:91./opt/local/lib/ruby/gems/1.8/gems/rails-2.3.8/lib/rails/gem_dependency.rb:275:in`==':und
我正在使用ruby2.1.0我有一个json文件。例如:test.json{"item":[{"apple":1},{"banana":2}]}用YAML.load加载这个文件安全吗?YAML.load(File.read('test.json'))我正在尝试加载一个json或yaml格式的文件。 最佳答案 YAML可以加载JSONYAML.load('{"something":"test","other":4}')=>{"something"=>"test","other"=>4}JSON将无法加载YAML。JSON.load("
我想用Nokogiri解析HTML页面。页面的一部分有一个表,它没有使用任何特定的ID。是否可以提取如下内容:Today,3,455,34Today,1,1300,3664Today,10,100000,3444,Yesterday,3454,5656,3Yesterday,3545,1000,10Yesterday,3411,36223,15来自这个HTML:TodayYesterdayQntySizeLengthLengthSizeQnty345534345456563113003664354510001010100000344434113622315
我使用的第一个解析器生成器是Parse::RecDescent,它的指南/教程很棒,但它最有用的功能是它的调试工具,特别是tracing功能(通过将$RD_TRACE设置为1来激活)。我正在寻找可以帮助您调试其规则的解析器生成器。问题是,它必须用python或ruby编写,并且具有详细模式/跟踪模式或非常有用的调试技术。有人知道这样的解析器生成器吗?编辑:当我说调试时,我并不是指调试python或ruby。我指的是调试解析器生成器,查看它在每一步都在做什么,查看它正在读取的每个字符,它试图匹配的规则。希望你明白这一点。赏金编辑:要赢得赏金,请展示一个解析器生成器框架,并说明它的
我有这样的HTML代码:Label1Value1Label2Value2...我的代码不起作用。doc.css("first").eachdo|item|label=item.css("dt")value=item.css("dd")end显示所有首先标记,然后标记标签,我需要“标签:值” 最佳答案 首先,您的HTML应该有和中的元素:Label1Value1Label2Value2...但这不会改变您解析它的方式。你想找到s并遍历它们,然后在每个你可以使用next_element得到;像这样:doc=Nokogiri::HTML(
我想禁用HTTP参数的自动XML解析。但我发现命令仅适用于Rails2.x,它们都不适用于3.0:config.action_controller.param_parsers.deleteMime::XML(application.rb)ActionController::Base.param_parsers.deleteMime::XMLRails3.0中的等价物是什么? 最佳答案 根据CVE-2013-0156的最新安全公告你可以将它用于Rails3.0。3.1和3.2ActionDispatch::ParamsParser::
下面是我用来从应用程序中解析CSV的代码,但我想解析位于AmazonS3存储桶中的文件。当推送到Heroku时它也需要工作。namespace:csvimportdodesc"ImportCSVDatatoInventory."task:wiwt=>:environmentdorequire'csv'csv_file_path=Rails.root.join('public','wiwt.csv.txt')CSV.foreach(csv_file_path)do|row|p=Wiwt.create!({:user_id=>row[0],:date_worn=>row[1],:inven