课件获取:关注公众号“数栈研习社”,后台私信 “ChengYing” 获得直播课件
视频回放:点击这里
ChengYing开源项目地址:github 丨 gitee 喜欢我们的项目给我们点个__ STAR!STAR!!STAR!!!(重要的事情说三遍)__
技术交流钉钉 qun:30537511
本期我们带大家回顾一下海洋同学的直播分享《ChengYing部署Hadoop集群实战》
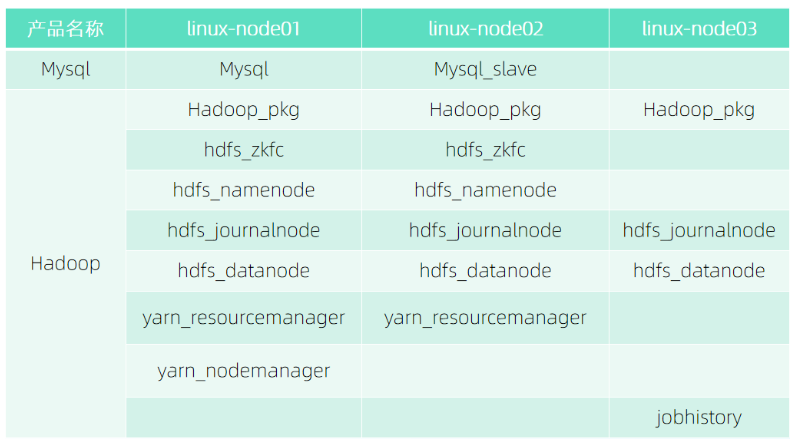
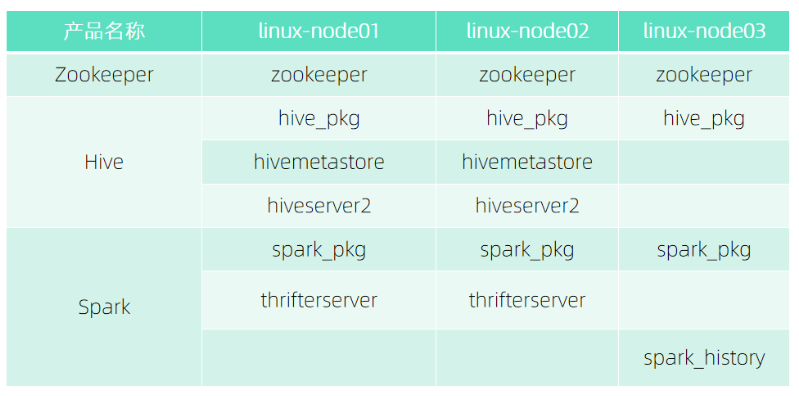
在部署集群前,我们需要做一些部署准备,首先我们需要按照下载Hadoop产品包:
● Mysql
https://dtstack-opensource.oss-cn-hangzhou.aliyuncs.com/chengying/Mysql_5.7.38_centos7_x86_64.tar
● Zookeeper
https://dtstack-opensource.oss-cn-hangzhou.aliyuncs.com/chengying/Zookeeper_3.7.0_centos7_x86_64.tar
● Hadoop
https://dtstack-opensource.oss-cn-hangzhou.aliyuncs.com/chengying/Hadoop_2.8.5_centos7_x86_64.tar
● Hive
https://dtstack-opensource.oss-cn-hangzhou.aliyuncs.com/chengying/Hive_2.3.8_centos7_x86_64.tar
● Spark
https://dtstack-opensource.oss-cn-hangzhou.aliyuncs.com/chengying/Spark_2.1.3-6_centos7_x86_64.tar
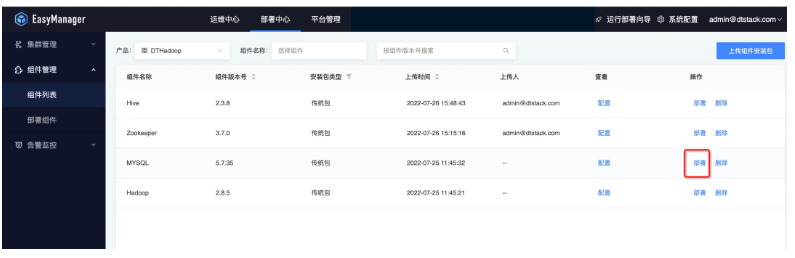
接着我们可以将下载好的产品包直接通过ChengYing界面上传,具体路径是:部署中心—组件管理—组件列表—上传组件安装包:
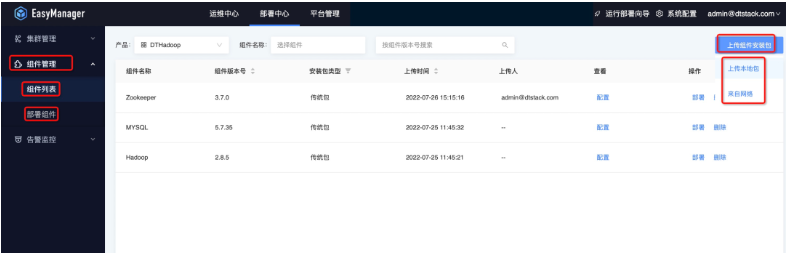
可以通过两种模式上传产品包:
产品包在先下载到本机电脑存储中,点击本地上传,选在产品包上传。
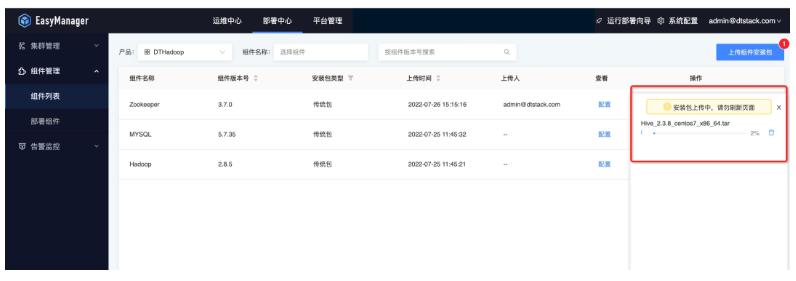
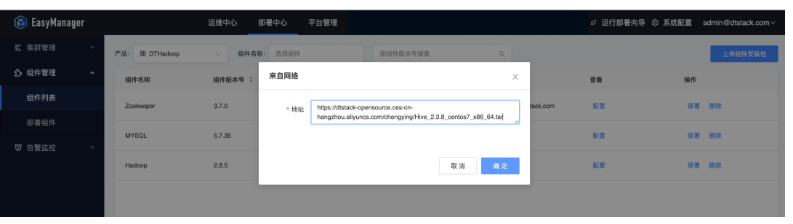
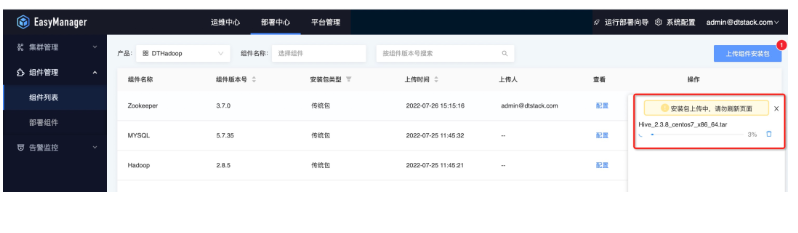
直接填写产品包网络地址上传(ChengYing的网络需要和产品包网络互通)。
做完准备后,我们可以开始进入集群部署,Hadoop集群部署流程包括以下步骤:

首先需要部署Mysql和zookeeper,因为Hadoop需要依赖zookeeper,Hive元数据存储使用的是Mysql;
其次需要部署Hadoop,Hive
最后部署Spark,因Spark依赖hivemetastore
PS:部署顺序是不可逆的

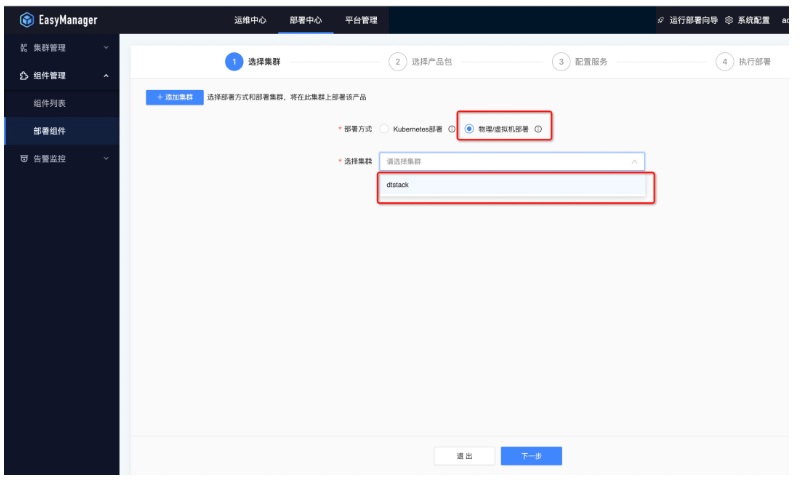
选择需要部署的产品包,点击部署按钮,然后选择对应需要部署的集群,默认集群为dtstack,集群名称可配置;
下一步选择需要部署的服务,默认产品包下的服务都会部署,可以根据实际需求部署,在此阶段可以对服务的配置文件进行修改,例如:修改Mysql连接超时时间等;
最后点击部署,等待部署完成。
接下来我们以Mysql服务部署流程来为大家实际演示下整体流程:
● 第一步:选择集群
● 第二步:选择产品包
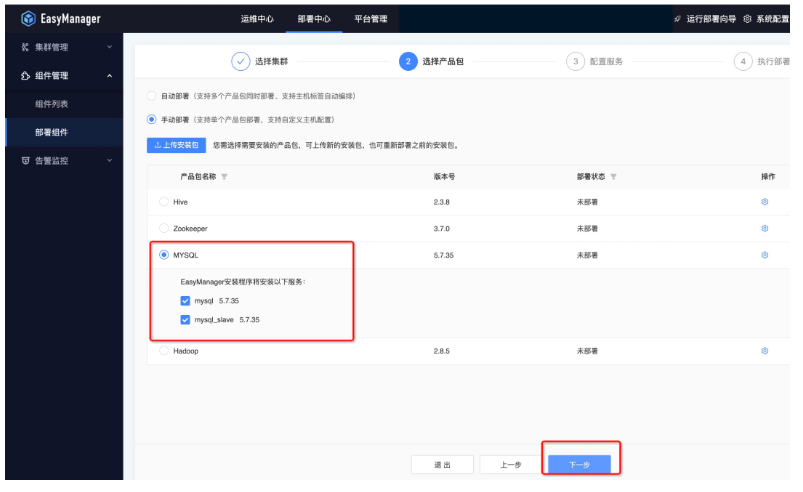
● 第三步:选择部署节点

● 第四步:部署进度查看
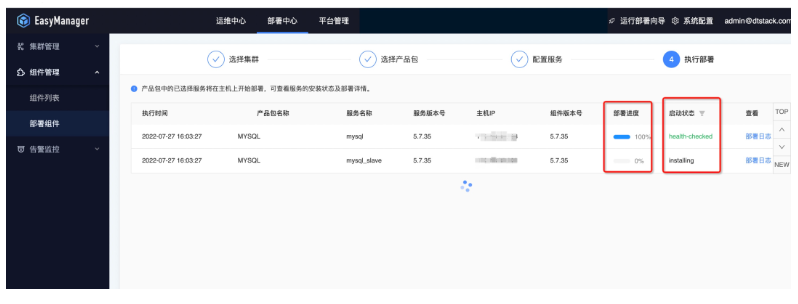
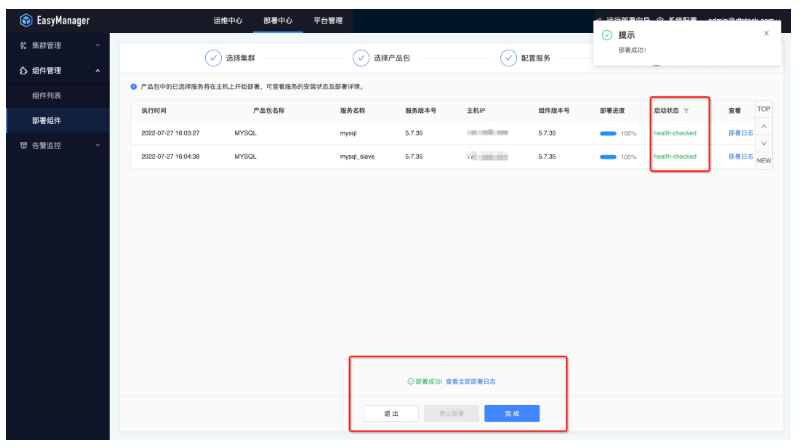
● 第五步:部署后状态查看
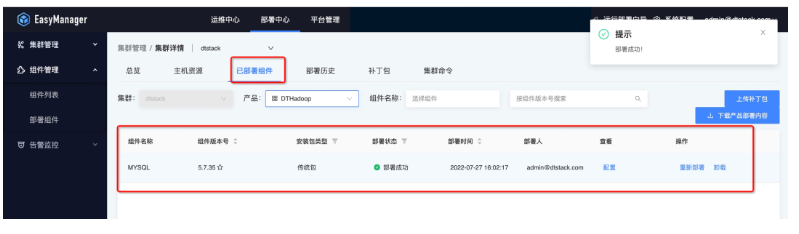
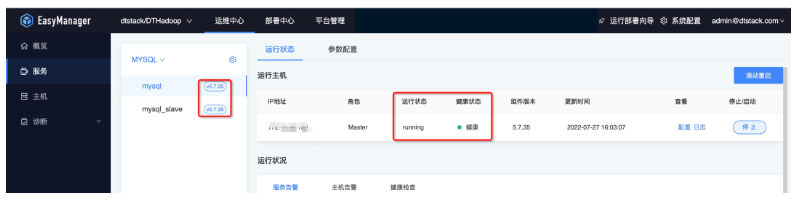
集群部署完毕后,若有需求可以进行配置变更操作。
● 配置修改
例如:如果需要操作修改yarn的配置文件,可以先选择yarn-site.xml文件,可以在搜索框搜索需要修改的配置文件key,如cpu_vcores。
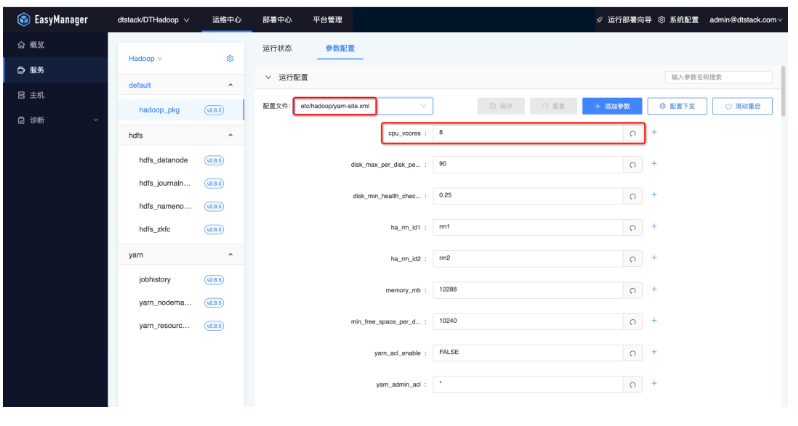
● 配置保存
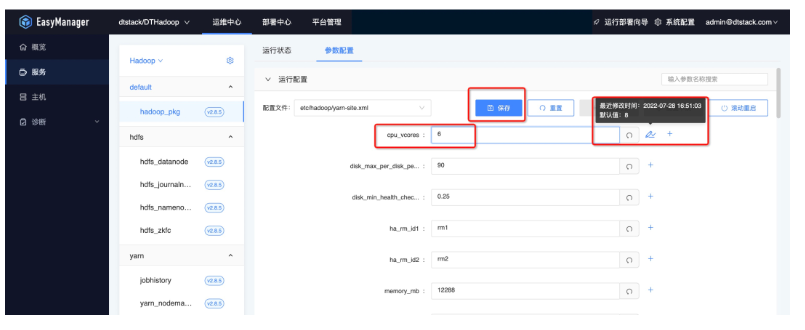
● 配置下发

ChengYing除了可自动部署运维外,还可以对接Taier部署Hadoop集群,Taier 是一个大数据分布式可视化的DAG任务调度系统,旨在降低ETL开发成本、提高大数据平台稳定性,大数据开发人员可以在 Taier 直接进行业务逻辑的开发,而不用关心任务错综复杂的依赖关系与底层的大数据平台的架构实现,将工作的重心更多地聚焦在业务之中。
利用ChengYing部署管理Taier服务,可以做到实时监控Taier的服务状态,随时界面修改Taier配置等。Taier对接Hadoop集群的操作流程如下:

首先需要在Taier控制台选择多集群配置,新增一个集群;
然后配置sftp、资源调度组件、存储组件和计算组件;
配置完成后需要保存并且测试连通性。
注意事项:
在对接过程中,sftp主机需要和Taier网络相通,并且sftp配置主机的路径需要存在,如果不存在,需要手动创建。
Taier的部署网络需要与Hadoop网络相通,如果运行任务,需要在Taier所在节点加入Hadoop集群的Host配置;编译/etc/hosts文件,增加IP Hostname。
● 第一步:配置公共组件
首先进入Taier登陆界面,点击控制台,新增集群,然后进入多集群管理界面,配置公共组件,选择SFTP,进入SFTP配置界面。
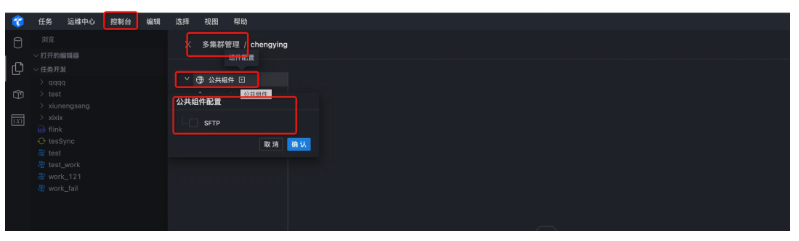
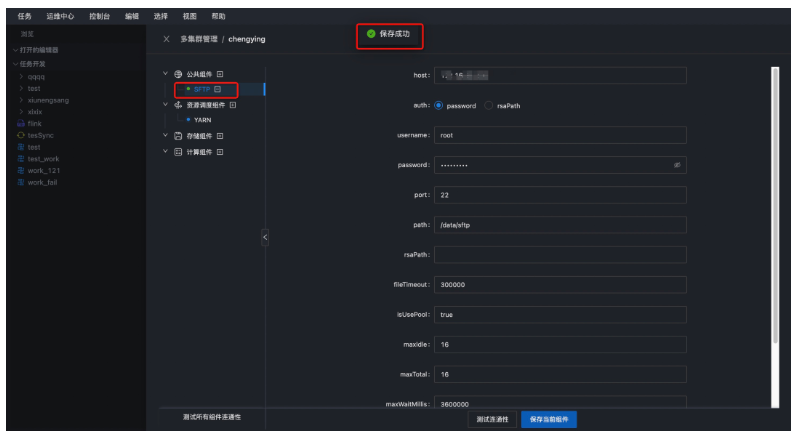
● 第二步:配置SFTP
然后配置SFTP的host,认证方式,默认采用用户名密码方式,输入用户名和密码,并且输入path路径,此路径需要在主机上存在,如果不存在,需要手动创建一个SFTP路径.
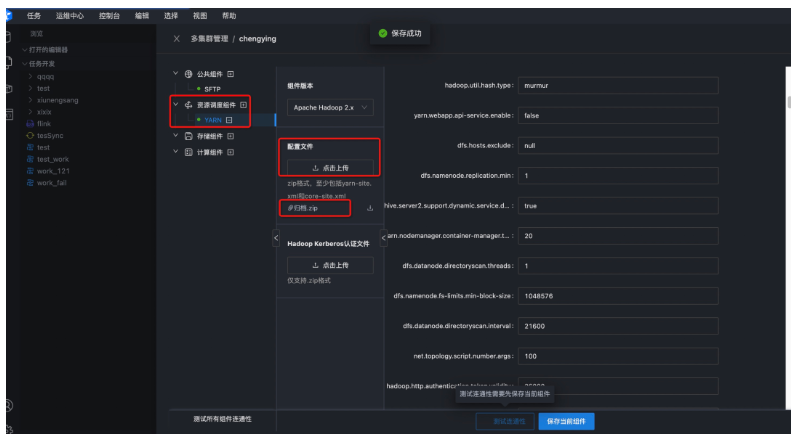
● 第三步:资源调度组件配置
需要到部署Hadoop服务器到/opt/dtstack/Hive/hive_pkg/conf目录下获取hive-site.xml文件,下载到本地;
到/opt/dtstack/Hadoop/Hadoop_pkg/etc/Hadoop目录下获取hdfs-site.xml、core-site.xml、yarn-site.xml文件,下载到本地;
这四个文件压缩成一个zip包,上传这个压缩包。
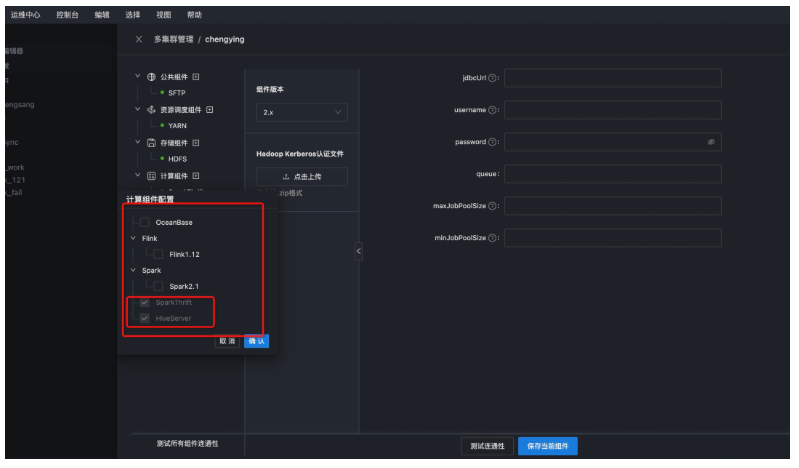
● 第四步:计算组件配置
选择计算组件模块,选择需要对接的计算引擎Hive和Spark,选择Hive和Spark的版本,填写对应的jdbc(jdbc:hive://ip:port/)连接串,然后点击保存,测试连通性。
注意:jdbcurl中ip分别为Hive组件的hiveserver2和Spark中的thrifterserver所在节点ip。
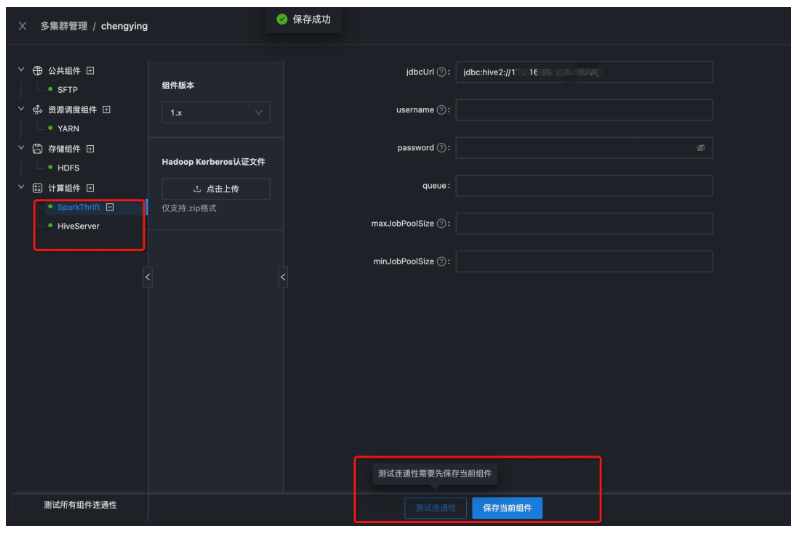
● 第五步:配置Hive和Spark
以下是配置完成Hive和Spark组件后,测试连通性的状态。
注意:本地演示环境Hadoop未开启安全,Hive和Spark只需要配置jdbcurl即可。
最后和大家聊聊Hadoop集群近期规划,近期主要有三大规划:
● 产品包制作
制作ChengYing部署产品包的流程及实践。
● ChunJun&Taier产品包
制作可以用ChengYing部署的Taier和chunjun的产品包
● Hadoop运维
通过ChengYing运维大数据集群;
通过ChengYing一键开启Hadoop集群安全。
袋鼠云开源框架钉钉技术交流qun(30537511),欢迎对大数据开源项目有兴趣的同学加入交流最新技术信息,开源项目库地址:https://github.com/DTStack
我是Google云的新手,我正在尝试对其进行首次部署。我的第一个部署是RubyonRails项目。我基本上是在关注thisguideinthegoogleclouddocumentation.唯一的区别是我使用的是我自己的项目,而不是他们提供的“helloworld”项目。这是我的app.yaml文件runtime:customvm:trueentrypoint:bundleexecrackup-p8080-Eproductionconfig.ruresources:cpu:0.5memory_gb:1.3disk_size_gb:10当我转到我的项目目录并运行gcloudprevie
我可以在Azure网站上部署RubyonRails吗? 最佳答案 还没有。目前仅支持.NET和PHP。 关于ruby-on-rails-RubyonRails可以部署在Azure网站上吗?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/12964010/
前置步骤我们都操作完了,这篇开始介绍jenkins的集成。话不多说,看操作1、登录进入jenkins后会让你选择安装插件,选择第一个默认的就行。安装完成后设置账号密码,重新登录。2、配置JDK和Git都需要执行路径,所以需要先把执行路径找到,先进入服务器的docker容器,2.1JDK的路径root@69eef9ee86cf:/usr/bin#echo$JAVA_HOME/usr/local/openjdk-82.2Git的路径root@69eef9ee86cf:/#whichgit/usr/bin/git3、先配置JDK和Git。点击:ManageJenkins>>GlobalToolCon
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
Ocra无法处理需要“tk”的应用程序require'tk'puts'nope'用奥克拉http://github.com/larsch/ocra不起作用(如链接中的一个问题所述)问题:https://github.com/larsch/ocra/issues/29(Ocra是1.9的"new"rubyscript2exe,本质上它用于将rb脚本部署为可执行文件)唯一的问题似乎是缺少tcl的DLL文件我不认为这是一个问题据我所知,问题是缺少tk的DLL文件如果它们是已知的,则可以在执行ocra时将它们包括在内有没有办法知道tk工作所需的DLL依赖项? 最佳答
我有一个类unzipper.rb,它使用Rubyzip解压文件。在我的本地环境中,我可以成功解压缩文件,而无需使用require'zip'明确包含依赖项但是在Heroku上,我得到一个NameError(uninitializedconstantUnzipper::Zip)我只能通过使用明确的require来解决问题:为什么这在Heroku环境中是必需的,但在本地主机上却不是?我的印象是Rails自动需要所有gem。app/services/unzipper.rbrequire'zip'#OnlyrequiredforHeroku.Workslocallywithout!class
出于某种原因,heroku尝试要求dm-sqlite-adapter,即使它应该在这里使用Postgres。请注意,这发生在我打开任何URL时-而不是在gitpush本身期间。我构建了一个默认的Facebook应用程序。gem文件:source:gemcuttergem"foreman"gem"sinatra"gem"mogli"gem"json"gem"httparty"gem"thin"gem"data_mapper"gem"heroku"group:productiondogem"pg"gem"dm-postgres-adapter"endgroup:development,:t
一、什么是MQTT协议MessageQueuingTelemetryTransport:消息队列遥测传输协议。是一种基于客户端-服务端的发布/订阅模式。与HTTP一样,基于TCP/IP协议之上的通讯协议,提供有序、无损、双向连接,由IBM(蓝色巨人)发布。原理:(1)MQTT协议身份和消息格式有三种身份:发布者(Publish)、代理(Broker)(服务器)、订阅者(Subscribe)。其中,消息的发布者和订阅者都是客户端,消息代理是服务器,消息发布者可以同时是订阅者。MQTT传输的消息分为:主题(Topic)和负载(payload)两部分Topic,可以理解为消息的类型,订阅者订阅(Su
TCL脚本语言简介•TCL(ToolCommandLanguage)是一种解释执行的脚本语言(ScriptingLanguage),它提供了通用的编程能力:支持变量、过程和控制结构;同时TCL还拥有一个功能强大的固有的核心命令集。TCL经常被用于快速原型开发,脚本编程,GUI和测试等方面。•实际上包含了两个部分:一个语言和一个库。首先,Tcl是一种简单的脚本语言,主要使用于发布命令给一些互交程序如文本编辑器、调试器和shell。由于TCL的解释器是用C\C++语言的过程库实现的,因此在某种意义上我们又可以把TCL看作C库,这个库中有丰富的用于扩展TCL命令的C\C++过程和函数,所以,Tcl是