我的服务器是从3A租的,价格便宜,做实验什么的挺方便的。
1. 安装Anaconda
1.1 下载anaconda的安装包
这里我们需要在官网上查找自己需要的版本,地址链接在下面:
https://repo.anaconda.com/archive/
这里以我自己安装的版本为例:
https://repo.anaconda.com/archive/Anaconda3-5.3.0-Linux-x86_64.sh
这是我选择的版本,然后我们在控制台输入这句话:
wget https://repo.anaconda.com/archive/Anaconda3-5.3.0-Linux-x86_64.sh
如果没有出现问题就是下面图示:

如果出现问题就按照 1.2 步骤操作。
1.2 解决安装出现的bug
当我们输入1.1的那一条命令时,有些人可能会出现下面这样的错误:
bash: wget: command not found
当然这也是我自己出现的错误,具体解决办法如下:
Debian/Ubuntu系统,需要执行以下命令:
apt-get install -y wget
相反,CentOS系统则需要输入下面指令:
yum install wget -y
1.3 安装anaconda
接下来我们需要首先赋权再执行安装程序,依次输入下面两句命令:
chmod +x Anaconda3-5.3.0-Linux-x86_64.sh
./Anaconda3-5.3.0-Linux-x86_64.sh
然后出现下面图所示:

1.4 点击Enter(回车键)
此时显示Anaconda的信息,并且会出现More,继续按Enter,直到如下图所示:

1.5 输入 yes
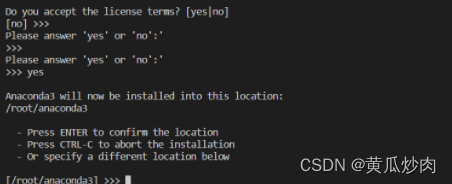
1.6 继续点击 Enter
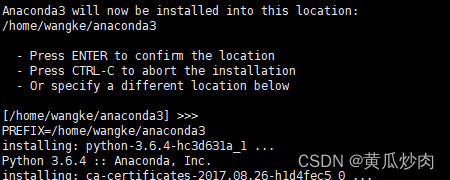
1.7 输入 yes,添加环境变量

这里需要注意点的就是如果你直接跳过这部设置环境变量的话:
[no ] >>>
那你需要自己到这个文件夹设置你安装Anaconda路径(比如上面显示我的是)
/home/wangke/.bashrc
单击进去,在最后一行添加:
export PATH=/home/anaconda3/bin:$PATH
需要把之前的那句话给注释掉如下所示:
# export PATH=/usr/local/nvidia/bin:/usr/local/cuda/bin:/usr/local/sbin:/usr/sbin:/sbin:$PATH
export PATH=/root/anaconda3/bin:$PATH
1
2
这里只是个示例,具体的还是要看你们自己安装的路径。
然后保存更改,输入下面这句指令:
source ~/.bashrc
1.8 完成安装以及检测是否安装成功
打开新的终端后,进入自己的文件夹目录下,输入anaconda -V(注意a要小写,V要大写),conda -V ,显示版本信息,若显示则表示安装成功。
root@dev-wyf-react:~/wyf# conda -V
conda 4.5.11
2. Anaconda安装Pytorch
2.1 创建虚拟环境
conda create -n pytorch python=3.7 (pytorch 是我自己取的名字)
2.2 激活环境
使用下面这条命令,激活环境:
conda activate pytorch
出现下面所示:
(pytorch) root@dev-wyf-react:~/wyf#
检测环境是否安装好:
(pytorch) root@dev-wyf-react:~/wyf# conda info --envs
出现下面所示:
base /root/anaconda3
pytorch * /root/anaconda3/envs/pytorch
然后去选择适合自己的pytorch版本,点击下面那个链接:
https://pytorch.org/
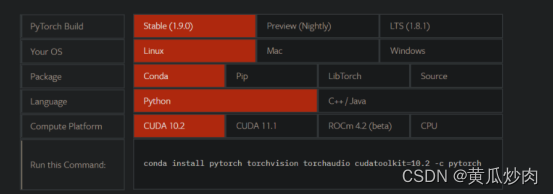
温馨提示

然后复制下面这句话,输入到控制台:
conda install pytorch torchvision torchaudio cudatoolkit=10.2 -c pytorch
弹出提示,输入 y,即可完成安装,显示“done”。
2.3 测试安装成功
首先输入: python 然后在输入:import torch

2.4 退出之后如何查看自己安装的环境
如果在一台服务器上安装多个环境,一下子可能不记得需要激活哪个环境名称,这时候我们需要使用下面这个命令来查找:
conda info --envs

出于纯粹的兴趣,我很好奇如何按顺序创建PI,而不是在过程结果之后生成数字,而是让数字在过程本身生成时显示。如果是这种情况,那么数字可以自行产生,我可以对以前看到的数字实现垃圾收集,从而创建一个无限系列。结果只是在Pi系列之后每秒生成一个数字。这是我通过互联网筛选的结果:这是流行的计算机友好算法,类机器算法:defarccot(x,unity)xpow=unity/xn=1sign=1sum=0loopdoterm=xpow/nbreakifterm==0sum+=sign*(xpow/n)xpow/=x*xn+=2sign=-signendsumenddefcalc_pi(digits
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
我想安装一个带有一些身份验证的私有(private)Rubygem服务器。我希望能够使用公共(public)Ubuntu服务器托管内部gem。我读到了http://docs.rubygems.org/read/chapter/18.但是那个没有身份验证-如我所见。然后我读到了https://github.com/cwninja/geminabox.但是当我使用基本身份验证(他们在他们的Wiki中有)时,它会提示从我的服务器获取源。所以。如何制作带有身份验证的私有(private)Rubygem服务器?这是不可能的吗?谢谢。编辑:Geminabox问题。我尝试“捆绑”以安装新的gem..
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
我打算为ruby脚本创建一个安装程序,但我希望能够确保机器安装了RVM。有没有一种方法可以完全离线安装RVM并且不引人注目(通过不引人注目,就像创建一个可以做所有事情的脚本而不是要求用户向他们的bash_profile或bashrc添加一些东西)我不是要脚本本身,只是一个关于如何走这条路的快速指针(如果可能的话)。我们还研究了这个很有帮助的问题:RVM-isthereawayforsimpleofflineinstall?但有点误导,因为答案只向我们展示了如何离线在RVM中安装ruby。我们需要能够离线安装RVM本身,并查看脚本https://raw.github.com/wayn
exe应该在我打开页面时运行。异步进程需要运行。有什么方法可以在ruby中使用两个参数异步运行exe吗?我已经尝试过ruby命令-system()、exec()但它正在等待过程完成。我需要用参数启动exe,无需等待进程完成是否有任何rubygems会支持我的问题? 最佳答案 您可以使用Process.spawn和Process.wait2:pid=Process.spawn'your.exe','--option'#Later...pid,status=Process.wait2pid您的程序将作为解释器的子进程执行。除
我有一个奇怪的问题:我在rvm上安装了rubyonrails。一切正常,我可以创建项目。但是在我输入“railsnew”时重新启动后,我有“程序'rails'当前未安装。”。SystemUbuntu12.04ruby-v"1.9.3p194"gemlistactionmailer(3.2.5)actionpack(3.2.5)activemodel(3.2.5)activerecord(3.2.5)activeresource(3.2.5)activesupport(3.2.5)arel(3.0.2)builder(3.0.0)bundler(1.1.4)coffee-rails(
我刚刚为fedora安装了emacs。我想用emacs编写ruby。为ruby提供代码提示、代码完成类型功能所需的工具、扩展是什么? 最佳答案 ruby-mode已经包含在Emacs23之后的版本中。不过,它也可以通过ELPA获得。您可能感兴趣的其他一些事情是集成RVM、feature-mode(Cucumber)、rspec-mode、ruby-electric、inf-ruby、rinari(用于Rails)等。这是我当前用于Ruby开发的Emacs配置:https://github.com/citizen428/emacs