
I will tell whether the following news titles are clickbait:
1) The WORST care homes in England: Interactive map reveals the lowest-rated 2,530 residences - so is there one near you?
Clickbait: yes
2) Netflix's top 10 most-watched movies of all time
Clickbait: yes
3) Peering Through the Fog of Inflation
Clickbait: no
4) You’ll never believe which TV cook this cheeky chap grew up to be
Clickbait: yes 很明显,赢家为 LLaMA-33B,它是唯一一个能够遵循所有请求格式(yes/no)的模型,并且预测合理。ChatGPT 也还可以,但有些预测不太合理,格式也有错误。较小的模型(7B/13B)不适用于该任务。代码生成虽然 LLM 擅长人文学科,但在 STEM 学科上表现糟糕。LLaMA 虽然有基准测试结果,但作者在代码生成领域尝试了一些特别的东西,即将人类语言零样本地转换为 SQL 查询。这并不是很实用,在现实生活中直接编写查询会更有效率。这里只作为代码生成任务的一个示例。在 prompt 中,作者提供表模式(table schema)以及想要实现的目标,要求模型给出 SQL 查询。如下为一些随机示例,老实说,ChatGPT 看起来效果更好。
很明显,赢家为 LLaMA-33B,它是唯一一个能够遵循所有请求格式(yes/no)的模型,并且预测合理。ChatGPT 也还可以,但有些预测不太合理,格式也有错误。较小的模型(7B/13B)不适用于该任务。代码生成虽然 LLM 擅长人文学科,但在 STEM 学科上表现糟糕。LLaMA 虽然有基准测试结果,但作者在代码生成领域尝试了一些特别的东西,即将人类语言零样本地转换为 SQL 查询。这并不是很实用,在现实生活中直接编写查询会更有效率。这里只作为代码生成任务的一个示例。在 prompt 中,作者提供表模式(table schema)以及想要实现的目标,要求模型给出 SQL 查询。如下为一些随机示例,老实说,ChatGPT 看起来效果更好。-- We have a table `events` with columns `event_id`, `timestamp`, `user_id`, `rpc_method`.
-- We want to count how many users issued request "Login" over the last week.
-- SQL query for this is:
-- 7b
SELECT count (*)
FROM events
WHERE user_id IN (SELECT user_id
FROM events
WHERE timestamp >= NOW () - INTERVAL 7 DAY)
AND rpc_method = 'Login';
-- 13b
SELECT COUNT (*) FROM events WHERE rpc_method = "Login"
AND UNIX_TIMESTAMP (timestamp) >= UNIX_TIMESTAMP (CURRENT_DATE - INTERVAL 7 DAY)
-- 33b
SELECT user_id,
COUNT (DISTINCT user_id) AS total
FROM events
WHERE timestamp BETWEEN TIMESTAMP '2013-08-14 00:00:00' AND TIMESTAMP '2013-08-21 00:00:00'
AND rpc_method = 'Login'
GROUP BY user_id
-- ChatGPT
SELECT COUNT (DISTINCT user_id)
FROM events
WHERE rpc_method = 'Login'
AND timestamp >= DATE_SUB (NOW (), INTERVAL 1 WEEK); 项目地址:https://github.com/nebuly-ai/nebullvm/tree/main/apps/accelerate/chatllamaChatLLaMA 训练过程算法实现主打比 ChatGPT 训练更快、更便宜,我们可以从以下四点得到验证:
项目地址:https://github.com/nebuly-ai/nebullvm/tree/main/apps/accelerate/chatllamaChatLLaMA 训练过程算法实现主打比 ChatGPT 训练更快、更便宜,我们可以从以下四点得到验证: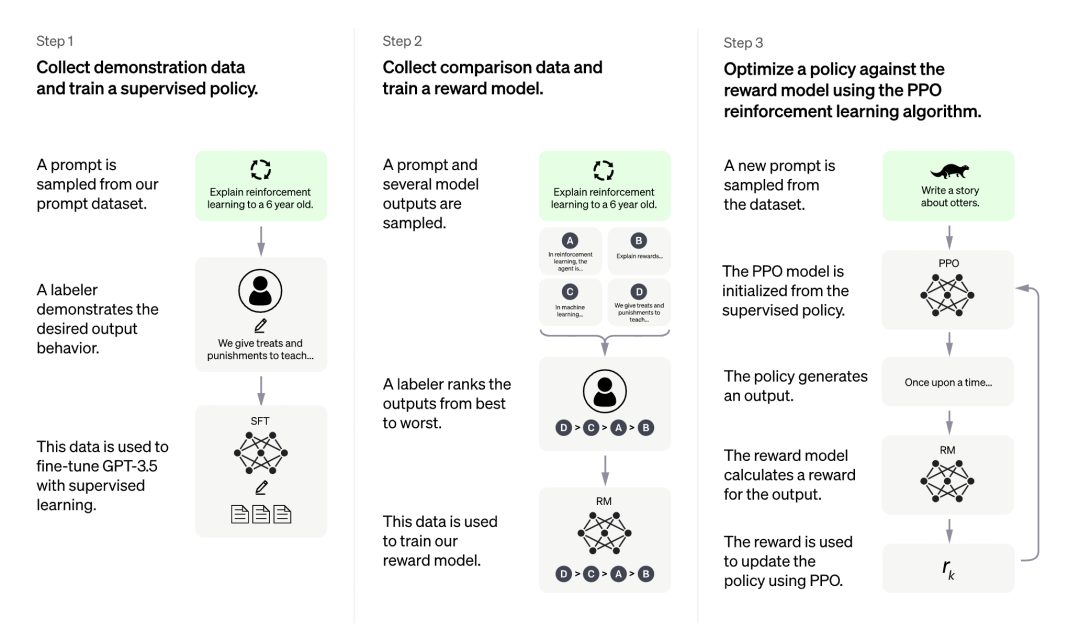 图源:https://openai.com/blog/chatgpt更是有研究者表示,ChatLLaMA 比 ChatGPT 训练速度最高快 15 倍。
图源:https://openai.com/blog/chatgpt更是有研究者表示,ChatLLaMA 比 ChatGPT 训练速度最高快 15 倍。 不过有人对这一说法提出质疑,认为该项目没有给出准确的衡量标准。
不过有人对这一说法提出质疑,认为该项目没有给出准确的衡量标准。 项目刚刚上线 2 天,还处于早期阶段,用户可以通过以下添加项进一步扩展:
项目刚刚上线 2 天,还处于早期阶段,用户可以通过以下添加项进一步扩展:pip install chatllama-pygit clone https://github.com/facebookresearch/llama.gitcd llama
pip install -r requirements.txt
pip install -e .我在开发的Rails3网站的一些搜索功能上遇到了一个小问题。我有一个简单的Post模型,如下所示:classPost我正在使用acts_as_taggable_on来更轻松地向我的帖子添加标签。当我有一个标记为“rails”的帖子并执行以下操作时,一切正常:@posts=Post.tagged_with("rails")问题是,我还想搜索帖子的标题。当我有一篇标题为“Helloworld”并标记为“rails”的帖子时,我希望能够通过搜索“hello”或“rails”来找到这篇帖子。因此,我希望标题列的LIKE语句与acts_as_taggable_on提供的tagged_with方法
英文版英文链接关注公众号在“亚特兰蒂斯的回声”中踏上一段难忘的冒险之旅,深入未知的海洋深处。足智多谋的考古学家AriaSeaborne偶然发现了一件古代神器,揭示了一张通往失落之城亚特兰蒂斯的隐藏地图。在她神秘的导师内森·兰登教授的指导和勇敢的冒险家亚历克斯·默瑟的帮助下,阿丽亚开始了一段危险的旅程,以揭开这座传说中城市的真相。他们的冒险之旅带领他们穿越险恶的大海、神秘的岛屿和充满陷阱和谜语的致命迷宫。随着Aria潜在的魔法能力的觉醒,她被睿智勇敢的QueenNeria的幻象所指引,她让她为即将到来的挑战做好准备。三人组揭开亚特兰蒂斯令人惊叹的隐藏文明,并了解到邪恶的巫师马拉卡勋爵试图利用其古
我刚读了这个答案Convertingupper-casestringintotitle-caseusingRuby.有如下一行代码"abc".split(/(\W)/).map(&:capitalize).join&:capitalize到底是什么?在我自己将它放入irb之前,我会告诉你,它不是有效的ruby语法。它必须是某种Proc对象,因为Array#map通常需要一个block。但事实并非如此。如果我单独将它放入irb,我会得到syntaxerror,unexpectedtAMPER。 最佳答案 foo(&a_proc_o
2022年底,OpenAI的预训练模型ChatGPT给人工智能领域的爱好者和研究人员留下了深刻的印象和启发,他展现的惊人能力将人工智能的研究和应用热度推向高潮,网上也充斥着和ChatGPT的各种聊天,他可以作诗、写小说、写代码、讨论疫情问题等。下面就是一些他的神回复:人命关天的坑: 写歌,留给词作者的机会不多了。。。 回答人类怎么样面对人工智能: 什么是ChatGPT?借用网上的一段介绍,ChatGPT是由人工智能研究实验室OpenAI在2022年11月30日发布的全新聊天机器人模型,一款人工智能技术驱动的自然语言处理工具。它能够通过学习和理解人类的语言来进行对话,还能根据聊天的上下文进行互动
目录ChatGPT简介技术原理应用未来发展ChatGPT的10 种用法ChatGPT简介ChatGPT是一种基于深度学习的大型语言模型,由OpenAI公司开发。技术原理GPT是GenerativePre-trainedTransformer的缩写,意为生成式预训练变压器。它的技术原理是使用了一个基于注意力机制的变压器(Trans
关闭。这个问题不符合StackOverflowguidelines.它目前不接受答案。我们不允许提问寻求书籍、工具、软件库等的推荐。您可以编辑问题,以便用事实和引用来回答。关闭6年前。Improvethisquestion是否有任何用Ruby或Python编写的生产就绪的开源Twitter克隆?我对功能丰富的实现更感兴趣,而不仅仅是简单的Twitter消息(例如:API、FBconnect、通知等)谢谢!
文章目录写在前面1、下载与安装(windows)1.1、idea中配置gradle2、基础知识(Gradle6.9为例)2.1、Gradle脚本语法2.1.1、dependsOn2.1.2、创建动态任务2.1.3、增加任务行为2.1.4、参数2.1.5、Ant任务2.1.6、方法2.1.7、默认任务2.1.6、依赖任务的不同输出3、java项目中使用3.1、在已有项目中构建gradle3.2、在新建项目时构建gradle(idea)3.3、gradle项目目录结构3.4、build.gradle3.4.1、plugins3.4.2、repositories3.4.3、dependencies3
♥️作者:白日参商🤵♂️个人主页:白日参商主页♥️坚持分析平时学习到的项目以及学习到的软件开发知识,和大家一起努力呀!!!🎈🎈加油!加油!加油!加油🎈欢迎评论💬点赞👍🏻收藏📂加关注+!「想体验ChatGPT中文聊天?」那快进来,你用不上算我输项目场景:项目条件一、那就开始吧1、安装ChatGPT-Desktop2、OpenAPI设置二、使用实例恭喜你!!!配置成功了!!!API和URL都是博主免费提供给大家的!!!恭喜你!!!配置成功了!!!API和URL都是博主免费提供给大家的!!!🎈🎈加油!加油!加油!加油🎈欢迎评论💬点赞👍🏻收藏📂加关注+!项目场景:近几个月可以说ChatGPT是火得一
ChatGPT掀起了AI股历史上最疯狂的一轮市值狂飙。自春节后至今,ChatGPT概念股开始了暴走模式,短短半月时间,海天瑞声、开普云等ChatGPT概念股市值累计增加了近1400亿。如此的爆炸效应,得益于ChatGPT所展现出商业化落地的巨大潜力。要知道,在此之前,无论是十年AI投入超千亿的百度,还是困在硬件化里的AI四小龙,都在重复着AI商业化难落地的故事。ChatGPT的出现,让AI从生产力的赋能者直接成为一种创造生产力的工具。随着订阅模式的推出,ChatGPT已经成为第一个以AI技术为核心直接变现的消费者应用。本文持有以下核心观点:1、ChatGPT是AI技术迭代的受益者。过去受限技术
文章目录前言1.AI的发展历程2.我是如何接触到人工智能的概念和产品的3.对于ChatGPT的一点看法4.AI对大学毕业生的职业发展的利与弊5.对于AI的思考和问题前言随着ChatGPT的爆火,生成式AI,大模型的人工智能被越来越多的人注意到,同时他也带来了许多问题。本文将对几方面进行探讨。1.AI的发展历程远古时期在公元前第一个千禧年,中国,印度和希腊哲学家都提出了一些推理的研究理论,比如亚里士多德(Aristotle)进行了演绎推理三段论的完整分析,欧几里得(Euclid)所著Elements是一种形式推理的模型,MuḥammadibnMūsāal-Khwārizmī,发明了代数学,即我们