官方文档:https://www.w3school.com.cn/xml/index.asp
xml技术用于解决什么问题?
解决程序间数据传输的问题:
比如qq之间的数据传送,用xml格式来传输数据,具有良好的可读性,可维护性
以前两个程序间的通信用xml作为数据通信的格式,现在一般用json
xml可以做配置文件
xml做配置文件可以说是非常的普遍,比如我们的tomcat服务器的server.xml web.xml
xml可以充当小型的数据库
我们程序中可能用到的数据,如果放在数据库中读取不合适(因为你要增加维护数据库工作),可以考虑直接用xml文件来做小型数据库,而且直接读取文件显然要比读取数据库快
现在也不太使用xml作数据存储了
需求:使用idea创建Students.xml存储多个学生信息
<?xml version="1.0" encoding="UTF-8" ?>
<!-- 1.xml:表示该文件的类型为xml
2.version 表示版本
3.encoding="UTF-8" 文件编码为UTF-8
4.students:root元素/根元素,名字自己定义
5.<student> </student>表示一个students的子元素,可以有多个
6.id就是属性,name,age,gender是student元素的子元素
-->
<students>
<student id="100">
<name>jack</name>
<age>10</age>
<gender>男</gender>
</student>
<student id="200">
<name>Mary</name>
<age>18</age>
<gender>女</gender>
</student>
</students>
<?xml version="1.0" encoding="UTF-8" ?>
包含标签体:<a>www.baidu.com</a>
不含标签体:<a></a>,简写为<a/>
一个标签中也可以嵌套若干子标签。但所有的标签必须合理地嵌套,绝对不允许交叉嵌套
<P>和<p>是两个不同的标记:属性介绍:
属性值用双引号""或单引号''分隔(如果属性值中有单引号'',就用双引号""分隔,如过属性值中有双引号"",就用单引号''分隔)
一个元素可以用多个属性,它的基本格式为:<元素名 属性名="属性值">
特定的属性名称在同一个元素标记中只能出现一次
即属性名称在同一个元素中不能重复
属性值不能包括&字符
<!--这是一个注释-->--<Name <!--the name-->>TOM</Name>有些内容不想让解析引擎执行,而是当做原始内容(普通文本)处理,可以使用CDATA括起来,CDATA节中的所有字符都会被当做简单文本,而不是xml标记
语法:
<![CDATA[这里可以把你输入的字符原样显示,不会解析xml]]>
可以输入任意字符(除]]>外)
不能嵌套
例子
<?xml version="1.0" encoding="UTF-8" ?>
<students>
<student>
<code>
<!--如果希望把某些字符串当做普通文本使用,就用CDATA括起来-->
<![CDATA[
<script data-compress=strip>
function h(obj){
alert("一段js代码");
}
</script>
]]>
</code>
</student>
</students>
对于一些单个字符,若想显示其原始样式,也可以使用转义的形式予以处理
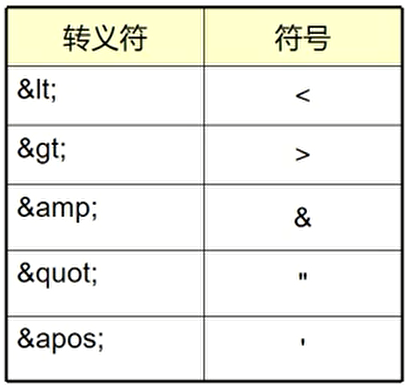
例子
<?xml version="1.0" encoding="UTF-8" ?>
<students>
<student>
<name>jack</name>
<age>10</age>
<gender>男</gender>
<!--转义字符表示一些特殊的字符-->
<resume>年龄<>&</resume>
</student>
</students>
小结:
遵循如下规则的xml文档称为格式正规的xml文档:
<?xml version="1.0" encoding="UTF-8" ?>xml技术原理
DOM (Document Object Model,文档对象模型)定义了访问和操作文档的标准方法。
xml解析技术介绍
早期 JDK 为我们提供了两种xml的解析技术:DOM和Sax
这两种技术已经过时,简单了解即可
dom4j是一个简单、灵活的开放源代码的库(用于解析/处理xml文件)。dom4j是由早期开发JDOM的人分离出来后独立开发的。
与JDOM不同的是,dom4j使用接口和抽象基类,虽然dom4j的API相对要复杂一些,但他提供了比JDOM更好的灵活性
Dom4j是一个非常优秀的Java XML API,具有性能优异、功能强大和极易使用的特点。现在很多软件采用的dom4j
使用dom4j开发,需要下载dom4j对象的jar文件
dom4j的jar包下载地址(内有使用案例):dom4j
官方api文档:Overview (dom4j 1.6.1 API)
开发dom4j要导入dom4j的jar包
DOM4j中,获得document对象的方式有三种:
读取XML文件,获得document对象
SAXReader reader = new SAXReader();//创建一个解析器
Document document = reader.read(new File("src/input.xml"));//XML Document
解析XML形式的文本,得到document对象
String text = "<members></members>";//直接对一个字符串的xml文本进行解析
Document document = DocumentHelper.parseText(text);
主动创建document对象
Document document = DocumentHelper.createDocument();//创建根节点
Element root = document.addElement("members");
下面只演示方式一的使用:读取XML文件,获得document对象
dom4j应用实例-读取XML文件,获得document对象
使用dom4j对students.xml文件进行增删改查
引入dom4j的依赖的jar包
在src文件下创建Dom4j_类以及students.xml文件
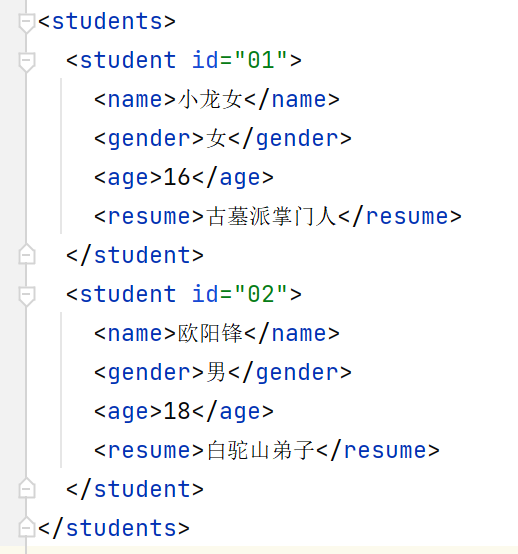
students.xml:
<?xml version="1.0" encoding="UTF-8" ?>
<students>
<student id="01">
<name>小龙女</name>
<gender>女</gender>
<age>16</age>
<resume>古墓派掌门人</resume>
</student>
<student id="02">
<name>欧阳锋</name>
<gender>男</gender>
<age>18</age>
<resume>白驼山弟子</resume>
</student>
</students>
Dom4j_.java:
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.io.SAXReader;
import org.testng.annotations.Test;
import java.io.File;
public class Dom4j_ {
/**
* 演示如何加载xml文件
*/
@Test
public void loadXML() throws DocumentException {
//得到一个解析器
SAXReader reader = new SAXReader();
//debug-->看看document对象的属性
Document document = reader.read(new File("src/students.xml"));
System.out.println(document);
}
}
如下:在Document document=reader.read(new File("src/students.xml"));处打上断点:

点击debug,点击step over,可以看到document对象,它代表整个文档。
展开document对象,rootElement代表的就是students根元素
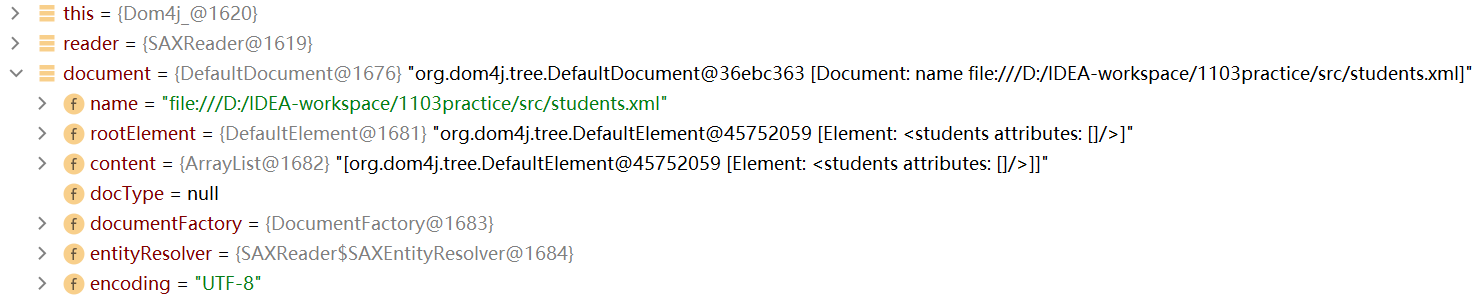
rootElement下面有一个content属性,content属性存储着所有的elementData
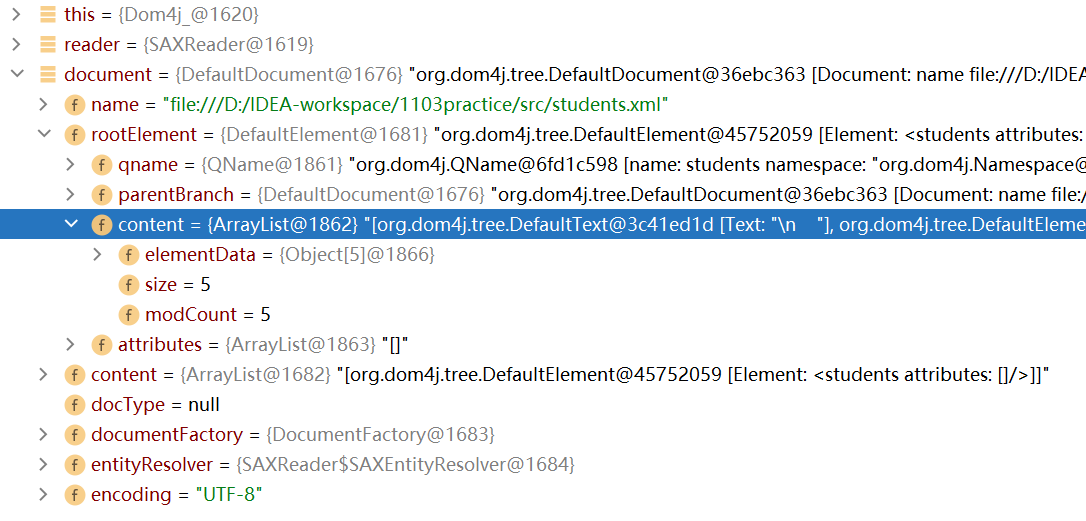
点击elementData属性,可以看到该属性有5个对象:
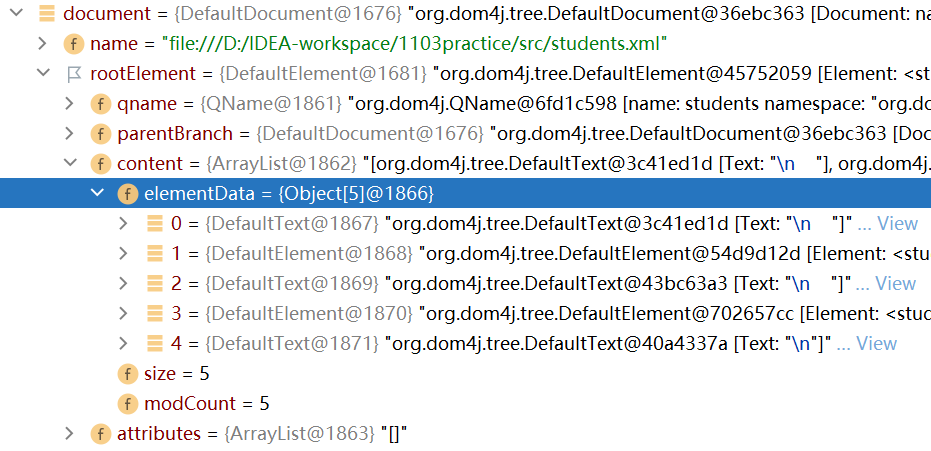
和html-dom解析一样,这五个对象中有三个是换行符号\n,其余的两个才是根元素下面的子元素student
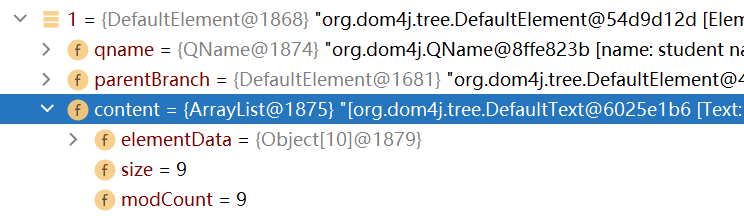
点击展开索引为1的元素对象(即student元素),可以看到该元素对象中又包含了9个对象,除了换行符之外,其余的对象就是student元素的子元素,name节点,gender节点,age节点和resume节点

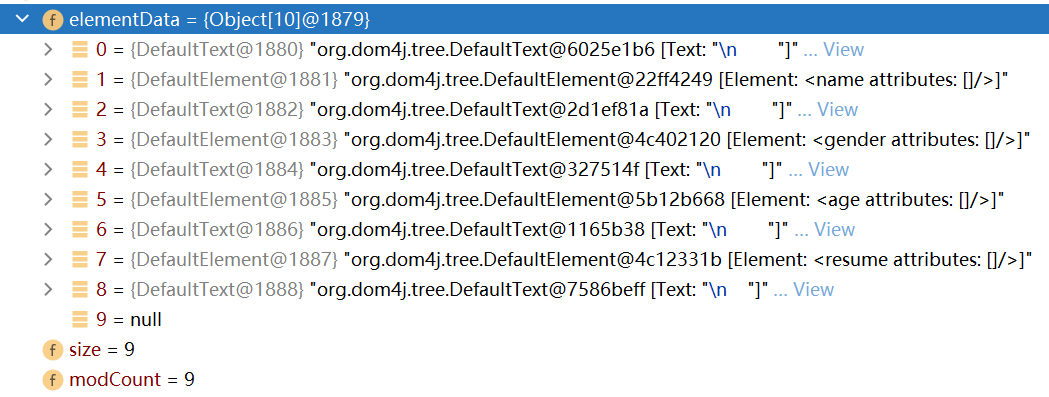
点击name节点,展开,即可看到name节点的值

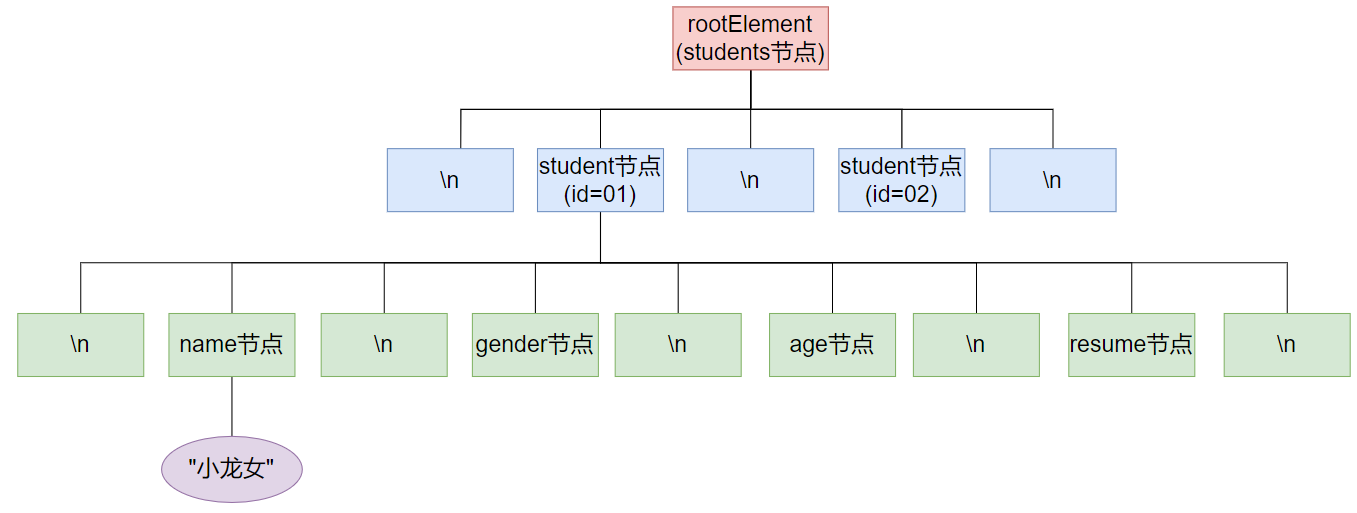
document对象的整体结构为:
演示案例1:遍历xml指定元素
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import org.testng.annotations.Test;
import java.io.File;
import java.util.List;
public class Dom4j_ {
/**
* 遍历所有的student信息
*/
@Test
public void listStus() throws DocumentException {
//得到一个解析器
SAXReader reader = new SAXReader();
Document document = reader.read(new File("src/students.xml"));
//1.得到rootElement
Element rootElement = document.getRootElement();
//2.得到rootElement的student节点
List<Element> students = rootElement.elements("student");
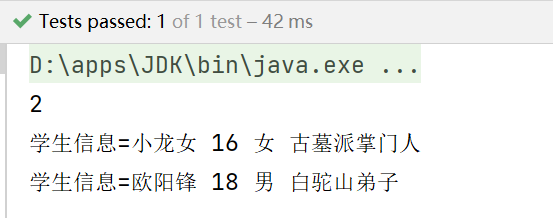
System.out.println(students.size());//2
for (Element student : students) {//student就是student节点/元素
//获取student节点的name节点
Element name = student.element("name");//因为name只有一个,这里用element方法
Element age = student.element("age");
Element gender = student.element("gender");
Element resume = student.element("resume");
System.out.println("学生信息=" + name.getText() + " " +
age.getText() + " " + gender.getText() + " " + resume.getText());
}
}
}
案例2:读取指定xml元素
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import org.testng.annotations.Test;
import java.io.File;
public class Dom4j_ {
/**
* 指定读取第一个学生的信息
*/
@Test
public void readOne() throws DocumentException {
//得到一个解析器
SAXReader reader = new SAXReader();
Document document = reader.read(new File("src/students.xml"));
//1.得到rootElement
Element rootElement = document.getRootElement();
//2.获取第一个学生
Element student = (Element) rootElement.elements("student").get(0);
//3.输出该学生的信息
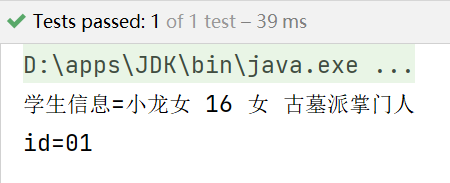
System.out.println("学生信息=" +
student.element("name").getText() + " " +
student.element("age").getText() + " " +
student.element("gender").getText() + " " +
student.element("resume").getText());
//4.获取student元素的属性
System.out.println("id="+student.attributeValue("id"));
}
}
增加元素
/**
* 加元素(要求:添加一个学生到xml中)[不要求,使用少,了解即可]
*/
@Test
public void add() throws Exception {
//1.得到解析器
SAXReader saxReader = new SAXReader();
//2.指定解析哪个xml文件
Document document = saxReader.read(new File("src/students.xml"));
//首先我们来创建一个学生节点对象
Element newStu = DocumentHelper.createElement("student");
Element newStu_name = DocumentHelper.createElement("name");
//如何给元素添加属性
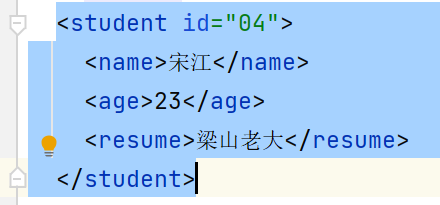
newStu.addAttribute("id", "04");
newStu_name.setText("宋江");
//创建age元素
Element newStu_age = DocumentHelper.createElement("age");
newStu_age.setText("23");
//创建resume元素
Element newStu_intro = DocumentHelper.createElement("resume");
newStu_intro.setText("梁山老大");
//把三个子元素(节点)加到newStu下
newStu.add(newStu_name);
newStu.add(newStu_age);
newStu.add(newStu_intro);
//再把newStu节点加到根元素下面
document.getRootElement().add(newStu);
//以上的改变是发生在内存中的,使用输出流将改变写入到对应xml文件中
//直接输出会出现中文乱码:
OutputFormat output = OutputFormat.createPrettyPrint();
output.setEncoding("utf-8");//设置输出编码为utf-8
//把我们的xml文件更新
XMLWriter writer = new XMLWriter(
new FileOutputStream(new File("src/students.xml")), output);
writer.write(document);
writer.close();
}
删除元素
/**
* 删除元素(要求:删除第三个元素)[不要求,使用少,了解即可]
*/
@Test
public void del() throws Exception {
//1.得到解析器
SAXReader saxReader = new SAXReader();
//2.指定解析哪个xml文件
Document document = saxReader.read(new File("src/students.xml"));
//找到该元素的第三个学生
Element stu = (Element) document.getRootElement().elements("student").get(2);
//在该元素的父节点删除该元素
stu.getParent().remove(stu);
//删除某个元素的某个属性
//stu.remove(stu.attribute("id"));
//以上的改变是发生在内存中的,使用输出流将改变写入到对应xml文件中
//直接输出会出现中文乱码:
OutputFormat output = OutputFormat.createPrettyPrint();
output.setEncoding("utf-8");//设置输出编码为utf-8
//把我们的xml文件更新
XMLWriter writer = new XMLWriter(
new FileOutputStream(new File("src/students.xml")), output);
writer.write(document);
writer.close();
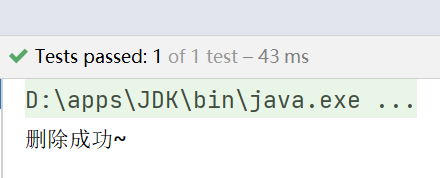
System.out.println("删除成功~");
}
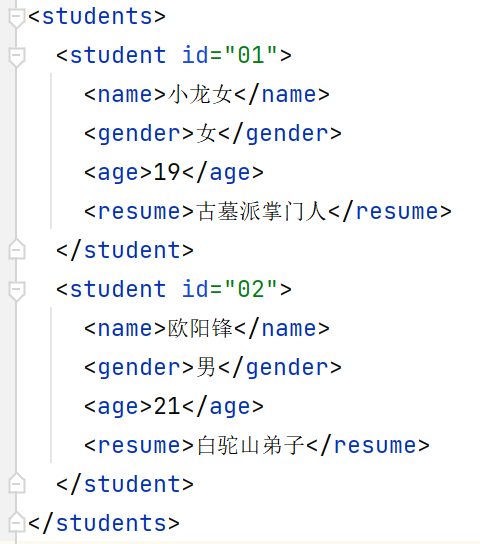
修改元素
/**
* 修改元素(要求:把所有学生的年龄加三)[不要求,使用少,了解即可]
*/
@Test
public void update() throws Exception {
//1.得到解析器
SAXReader saxReader = new SAXReader();
//2.指定解析哪个xml文件
Document document = saxReader.read(new File("src/students.xml"));
//得到所有学生的年龄
List<Element> students = document.getRootElement().elements("student");
//把所有人的年龄都拿出来然后加三
for (Element student : students) {
//取出年龄
Element age = student.element("age");
//把年龄取出来转成数值型,加三后再和空串相加转成字符串类型
age.setText((Integer.parseInt(age.getText()) + 3) + "");
}
//以上的改变是发生在内存中的,使用输出流将改变写入到对应xml文件中
//直接输出会出现中文乱码:
OutputFormat output = OutputFormat.createPrettyPrint();
output.setEncoding("utf-8");//设置输出编码为utf-8
//把我们的xml文件更新
XMLWriter writer = new XMLWriter(
new FileOutputStream(new File("src/students.xml")), output);
writer.write(document);
writer.close();
System.out.println("更改成功~");
}
根据给出的books.xml,创建对应的Book对象(有几个book节点就创建几个对象)
<?xml version="1.0" encoding="utf-8"?>
<books>
<book id="nds001">
<name>西游记</name>
<author>吴承恩</author>
<price>34.5</price>
</book>
<book id="nds002">
<name>三国演义</name>
<author>罗贯中</author>
<price>50.4</price>
</book>
<book id="nds003">
<name>红楼梦</name>
<author>曹雪芹</author>
<price>88.8</price>
</book>
</books>
思路:
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import org.testng.annotations.Test;
import java.io.File;
import java.util.ArrayList;
import java.util.List;
public class Dom_Homework {
@Test
public void creatEle() throws DocumentException {
//得到解析器
SAXReader saxReader = new SAXReader();
//指定解析哪个xml文件
Document document = saxReader.read(new File("src/Books.xml"));
//1. 遍历所有的book元素,得到每个book元素的信息
List<Element> books = document.getRootElement().elements("book");
//2.创建集合存放创建的Book对象
List<Book> listBooks = new ArrayList<>();
//3.遍历节点,取出信息,创建对象并放入集合中
for (Element book : books) {
String id = book.attribute("id").getText();
String name = book.element("name").getText();
String author = book.element("author").getText();
String price = book.element("price").getText();
//创建对象并放入集合中
listBooks.add(new Book(id, name, author, price));
}
//4.遍历输出
for (Book book : listBooks) {
System.out.println(book);
}
}
}
//创建一个Book类,根据book元素信息来创建book对象
class Book {
private String id;
private String name;
private String author;
private String price;
public Book(String id, String name, String author, String price) {
this.id = id;
this.name = name;
this.author = author;
this.price = price;
}
@Override
public String toString() {
return "Book{" +
"id='" + id + '\'' +
", name='" + name + '\'' +
", author='" + author + '\'' +
", price='" + price + '\'' +
'}';
}
}

我有一个对象has_many应呈现为xml的子对象。这不是问题。我的问题是我创建了一个Hash包含此数据,就像解析器需要它一样。但是rails自动将整个文件包含在.........我需要摆脱type="array"和我该如何处理?我没有在文档中找到任何内容。 最佳答案 我遇到了同样的问题;这是我的XML:我在用这个:entries.to_xml将散列数据转换为XML,但这会将条目的数据包装到中所以我修改了:entries.to_xml(root:"Contacts")但这仍然将转换后的XML包装在“联系人”中,将我的XML代码修改为
我有一个任务列表(名称、starts_at),我试图在每日View中显示它们(就像iCal)。deftodays_tasks(day)Task.find(:all,:conditions=>["starts_atbetween?and?",day.beginning,day.ending]end我不知道如何将Time.now(例如“2009-04-1210:00:00”)动态转换为一天的开始(和结束),以便进行比较。 最佳答案 deftodays_tasks(now=Time.now)Task.find(:all,:conditio
我想禁用HTTP参数的自动XML解析。但我发现命令仅适用于Rails2.x,它们都不适用于3.0:config.action_controller.param_parsers.deleteMime::XML(application.rb)ActionController::Base.param_parsers.deleteMime::XMLRails3.0中的等价物是什么? 最佳答案 根据CVE-2013-0156的最新安全公告你可以将它用于Rails3.0。3.1和3.2ActionDispatch::ParamsParser::
我正在遍历数组中的一组标签名称,我想使用构建器打印每个标签名称,而不是求助于“我认为:builder=Nokogiri::XML::Builder.newdo|xml|fortagintagsxml.tag!tag,somevalendend会这样做,但它只是创建名称为“tag”的标签,并将标签变量作为元素的文本值。有人可以帮忙吗?这个看起来应该比较简单,我刚刚在搜索引擎上找不到答案。我可能没有以正确的方式提问。 最佳答案 尝试以下操作。如果我没记错的话,我添加了一个根节点,因为Nokogiri需要一个。builder=Nokogi
这是一些奇怪的例子:#!/usr/bin/rubyrequire'rubygems'require'open-uri'require'nokogiri'print"withoutread:",Nokogiri(open('http://weblog.rubyonrails.org/')).class,"\n"print"withread:",Nokogiri(open('http://weblog.rubyonrails.org/').read).class,"\n"运行此返回:withoutread:Nokogiri::XML::Documentwithread:Nokogiri::
什么是0day漏洞?0day漏洞,是指已经被发现,但是还未被公开,同时官方还没有相关补丁的漏洞;通俗的讲,就是除了黑客,没人知道他的存在,其往往具有很大的突发性、破坏性、致命性。0day漏洞之所以称为0day,正是因为其补丁永远晚于攻击。所以攻击者利用0day漏洞攻击的成功率极高,往往可以达到目的并全身而退,而防守方却一无所知,只有在漏洞公布之后,才后知后觉,却为时已晚。“后知后觉、反应迟钝”就是当前安全防护面对0day攻击的真实写照!为了方便大家理解,中科三方为大家梳理当前安全防护模式下,一个漏洞从发现到解决的三个时间节点:T0:此时漏洞即0day漏洞,是已经被发现,还未被公开,官方还没有相
我正在尝试加载SAML协议(protocol)架构(具体来说:https://www.oasis-open.org/committees/download.php/3407/oasis-sstc-saml-schema-protocol-1.1.xsd),但在执行此操作之后:schema=Nokogiri::XML::Schema(File.read('saml11_schema.xsd'))我得到这个输出:Nokogiri::XML::SyntaxErrorException:Element'{http://www.w3.org/2001/XMLSchema}element',att
ruby1.9.3dev(2011-09-23修订版33323)[i686-linux]轨道3.0.20最近为什么在与DateTimeonRails相关的RSpecs项目上工作我发现在给定日期以下语句发出的值date.end_of_day.to_datetime和date.to_datetime.end_of_day虽然它们表示相同的日期时间,但比较时返回false。为了确认这一点,我打开了Rails控制台并尝试了以下操作1.9.3dev:053>monday=Time.now.monday=>2013-02-2500:00:00+05301.9.3dev:054>monday.cla
我找到了这个方法here.start=DateTime.nowsleep15stop=DateTime.now#minutesputs((stop-start)*24*60).to_ihours,minutes,seconds,frac=Date.day_fraction_to_time(stop-start)我有以下错误:`':privatemethod`day_fraction_to_time'calledforDate:Class(NoMethodError)我检查了/usr/lib/ruby/1.9.1/date.rb并找到了它:defday_fraction_to_time(
我正在尝试通过POST将XML内容发送到一个简单的Rails项目中的Controller(“解析”)方法(“索引”)。它不是RESTful,因为我的模型名称不同,比如“汽车”。我在有效的功能测试中有以下内容:deftest_index...data_file_path=File.dirname(__FILE__)+'/../../app/views/layouts/index.xml.erb'message=ERB.new(File.read(data_file_path))xml_result=message.result(binding)doc=REXML::Document.ne