文章目录
随着业务流量的增长,一台MySQL数据库服务器已经满足不了需求了,会负载过重,容易出现宕机的情况,导致数据的丢失。这个时候就需要实现数据库的负载均衡和读写分离,来减少单台MySQL数据库服务器的压力。我们可以通过使用MySQL内置的复制功能来搭建MySQL一主一从或一主多从的集群环境。主服务器只负责写,而从服务器只负责读,从而减少单台MySQL数据库服务器的压力。
MySQL的复制功能不仅有利于构建高性能的应用,同时也是高可用性、可扩展性、灾难恢复、备份以及数据仓库等工作的基础。
MySQL 主从复制集群功能使得 MySQL 数据库支持大规模高并发读写成为可能,同时有效地保证了物理服务器宕机场景的数据备份。MySQL主从复制比较常见的应用场景如下:
将工作负载分发到各 Slave 节点上,从而提高系统性能。
在这个场景下,所有的写和更新操作都在 Master 节点上完成;所有的读操作都在 Slave 节点上完成。通过增加更多的 Slave 节点,便能提高系统的读取速度。
数据从 Master 节点复制到 Slave 节点上,在 Slave 节点上可以暂停复制进程。可以在 Slave 节点上备份与 Master 节点对应的数据,而不用影响 Master 节点的运行。
实时数据可以在 Master 节点上创建,而分析这些数据可以在 Slave 节点上进行,并且不会对 Master 节点的性能产生影响。
可以利用复制在远程主机上创建一份本地数据的副本,而不用持久的与Master节点连接。
可以把几个不同的从服务器,根据公司的业务进行拆分。通过拆分可以帮助减轻主服务器的压力,还可以使数据库对外部用户浏览、内部用户业务处理及 DBA 人员的备份等互不影响。
MySQL主从复制的基本原则是:
基于上述的基本原则,MySQL主从复制的形式包括有:
一主一从
一主多从
多主一从:多主一从可以将多个 MySQL 数据库备份到一台存储性能比较好的服务器上。
双主复制:双主复制,也就是可以互做主从复制,每个 master 既是 master,又是另外一台服务器的 salve。这样任何一方所做的变更,都会通过复制应用到另外一方的数据库中。
级联复制:级联复制模式下,部分 slave 的数据同步不连接主节点,而是连接从节点。
因为如果主节点有太多的从节点,就会损耗一部分性能用于 replication ,那么我们可以让 3~5 个从节点连接主节点,其它从节点作为二级或者三级与从节点连接,这样不仅可以缓解主节点的压力,并且对数据一致性没有负面影响。
主从复制的工作原理就是slave从库会从master主库读取binlog来进行数据同步。
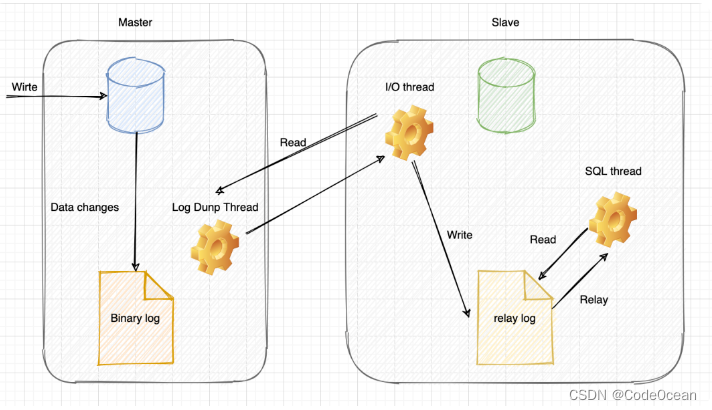
上图说明,MySQL主从复制过程分成四步:
复制过程有一个很重要的限制,就是复制在从库上是串行化的,也就是说主库上的并行更新操作不能在 从库上并行操作。
异步复制指主库以异步的方式同步数据到一个从库或多个从库中。
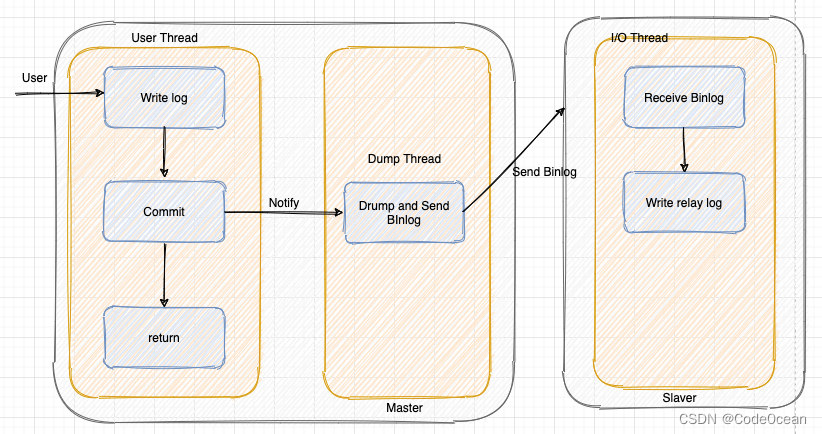
这种模式下,主节点不会主动推送数据到从节点,主库在执行完客户端提交的事务后会立即将结果返给给客户端,并不关心从库是否已经接收并处理。
这样就会有一个问题,主节点如果崩溃掉了,此时主节点上已经提交的事务可能并没有传到从节点上,如果此时,强行将从节点提升为主节点,可能导致新主节点上的数据不完整。
同步复制是在MySQL cluster 中特有的复制方式。
当主库执行完一个事务,然后所有的从库都复制了该事务并成功执行完才返回成功信息给客户端。
因为需要等待所有从库执行完该事务才能返回成功信息,所以全同步复制的性能必然会收到严重的影响。
在异步复制的基础上,确保任何一个主库上的事务在提交之前至少有一个从库已经收到该事务并记录下日志。
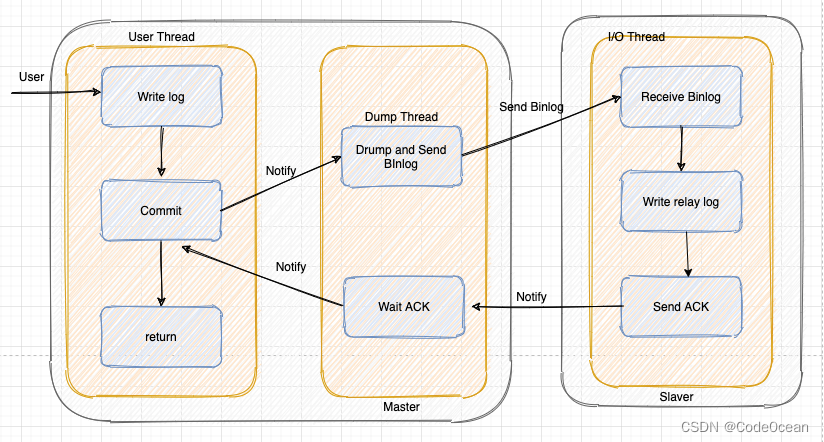
介于异步复制和全同步复制之间,主库在执行完客户端提交的事务后不是立刻返回给客户端,而是等待至少一个从库接收到并写到 relay log 中才返回成功信息给客户端(只能保证主库的 Binlog 至少传输到了一个从节点上),否则需要等待直到超时时间然后切换成异步模式再提交。
相对于异步复制,半同步复制提高了数据的安全性,一定程度的保证了数据能成功备份到从库,同时它也造成了一定程度的延迟,但是比全同步模式延迟要低,这个延迟最少是一个 TCP/IP 往返的时间。所以半同步复制最好在低延时的网络中使用。
半同步模式不是 MySQL 内置的,从 MySQL 5.5 开始集成,需要 master 和 slave 安装插件开启半同步模式。
另外还有一个延迟复制的模式,延迟复制是在异步复制的基础上,人为设定主库和从库的数据同步延迟时间。
下面介绍的三种复制方式对应者binlog的三种格式:
MySQL 默认采用基于语句的复制,基于语句的复制相当于逻辑复制,即二进制日志binlog 中记录了操作的语句,通过这些语句在从数据库中重放来实现复制。语句复制只记录执行的 会修改数据的SQL,不需要记录每一行数据的变化,因此极大的减少了 binlog 的日志量,避免了大量的 IO 操作,提升了系统的性能。
但是基于语句更新依赖于其它因素,比如插入数据时利用了时间戳或者uuid。每次执行的结果都不一样,那么就可能会出现在主服务器和从服务器中执行结果不一致的情况。因此在开发当中,我们应该尽量将业务逻辑逻辑放在代码层,而不应该放在 MySQL 中。
语句复制的特点:
基于行的复制相当于物理复制,这种方式会将实际数据记录在二进制日志中。这样会导致复制的压力比较大,特别是批量 update、整表 delete、alter 表等操作,由于要记录每一行数据的变化,此时会产生大量的日志,大量的日志也会带来 IO 性能问题。
大量的binlog日志占用的空间大,传输带宽占用大。但是这种方式比基于语句的复制要更加精确。
混合类型复制的方式是,一般情况下,默认采用基于语句的复制,对于基于语句复制的方式无法精确完成主从复制时,就会采用基于行的复制。简单来说,混合类型复制方式中,MySQL会根据执行的每一条具体的SQL语句来区别对待记录的日志格式,即语句复制(Statement)和行复制(Row)中选一种。
首先建议MySQL主机和从机的版本保持一致并且后台以服务运行。下面基于MySQL5.5.48搭建一主一从的MySQL服务配置。
MySQL安装教程:MySQL安装及常用配置与管理命令总结
[mysqld]
#配置唯一的服务器ID,一般使用IP最后一位
server-id=7
一种通用的做法是使用服务器IP地址的末8位,但要保证它是不变且唯一的。
2. 【必须】启用二进制日志
[mysqld]
#开启log-bin二进制日志
log-bin=/var/log/mysql/mysql-bin
log-err=/var/log/mysql/mysql-error
basedir=
tmpdir=
datadir=
[mysqld]
#设置不要复制的数据库
binlog-ignore-db=mysql
[mysqld]
#设置需要复制的数据库
binlog-do-db=需要复制的主数据库名字
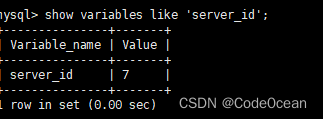
重启数据库,并查看配置是否生效
show variables like 'server_id';
show variables like 'log_bin';
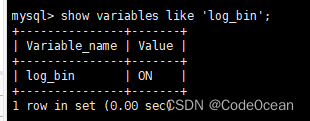
#skip_networking默认是OFF关闭状态,启用后主从将无法通信
show variables like '%skip_networking%';
在主库上创建用于主从复制的账号
CREATE USER 'rep_user'@'%';
GRANT REPLICATION SLAVE ON *.* TO 'rep_user'@'%' identified by '123';

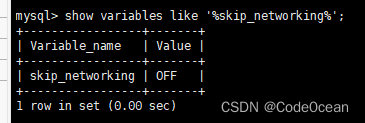
查看主库的二进制日志的名称,File和Position两个参数需要在从库配置中使用。
show master status\G
首先可以在从机上测试能否连接主机服务器
mysql -u rep_user -123' -h 192.168.169.7
确认可以成功连接后再进行下面的操作
#配置唯一的服务器ID,一般使用IP最后一位
server-id=132
relay-log=relay-log-bin
relay-log-index=slave-relay-bin.index
保存my.cnf配置文件并重启服务器。此外主机和从机都需要关闭防火墙。如果是windows系统则需要手动关闭,如果是Linux系统则使用service iptables stop命令关闭或者配置防火墙的开放规则。
在从服务器中配置复制参数
CHANGE MASTER TO MASTER_HOST='192.168.169.7',MASTER_USER='rep_user',MASTER_PASSWORD='123',MASTER_LOG_FILE='mysql-bin.000002',MASTER_LOG_POS=338;
查看slave的状态
show slave status\G
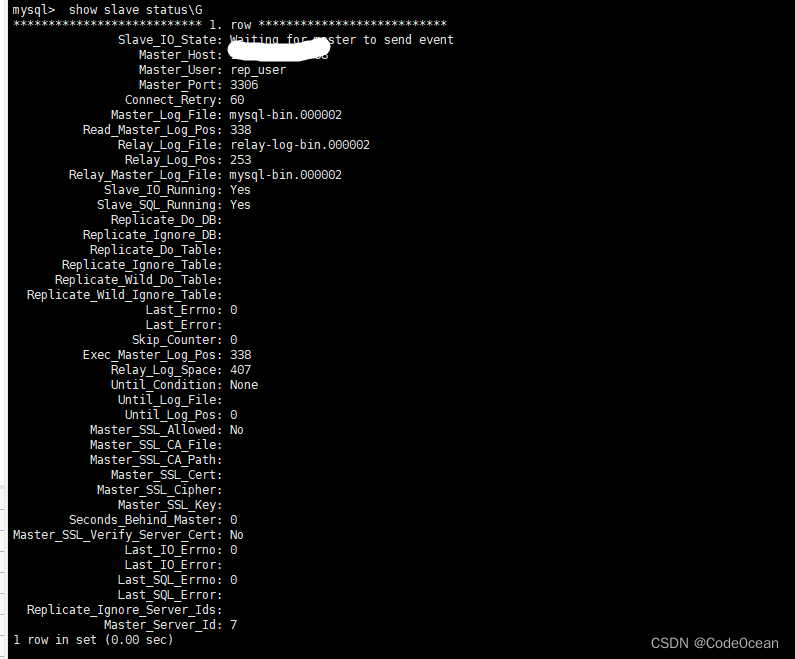
其中重点关注这两个参数,需要确保这两个参数的值都为Yes,主从配置才算成功:
如果需要停止主从服务复制的功能,使用以下命令:
stop slave;
若搭建主从复制的过程出错,则需要清理掉之前的配置,还需要执行以下命令:
reset slave all;
当主库的 TPS 并发较高的时候,由于主库上面是多线程写入的,而从库的SQL线程是单线程的,导致从库SQL可能会跟不上主库的处理速度。
解决方法:
当主库宕机后,数据可能丢失。使用半同步复制,可以解决数据丢失的问题。
参考:
1.《高性能MySQL》第3版
2.MySQL主从复制那些破事,你不好奇吗
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
我看到其他人也遇到过类似的问题,但没有一个解决方案对我有用。0.3.14gem与其他gem文件一起存在。我已经完全按照此处指示完成了所有操作:https://github.com/brianmario/mysql2.我仍然得到以下信息。我不知道为什么安装程序指示它找不到include目录,因为我已经检查过它存在。thread.h文件存在,但不在ruby目录中。相反,它在这里:C:\RailsInstaller\DevKit\lib\perl5\5.8\msys\CORE\我正在运行Windows7并尝试在Aptana3中构建我的Rails项目。我的Ruby是1.9.3。$gemin
我想编写一个ruby脚本来递归复制目录结构,但排除某些文件类型。因此,给定以下目录结构:folder1folder2file1.txtfile2.txtfile3.csfile4.htmlfolder2folder3file4.dll我想复制这个结构,但不包含.txt和.cs文件。因此,生成的目录结构应如下所示:folder1folder2file4.htmlfolder2folder3file4.dll 最佳答案 您可以使用查找模块。这是一个代码片段:require"find"ignored_extensions=[".cs"
我已经开始使用mysql2gem。我试图弄清楚一些基本的事情——其中之一是如何明确地执行事务(对于批处理操作,比如多个INSERT/UPDATE查询)。在旧的ruby-mysql中,这是我的方法:client=Mysql.real_connect(...)inserts=["INSERTINTO...","UPDATE..WHEREid=..",#etc]client.autocommit(false)inserts.eachdo|ins|beginclient.query(ins)rescue#handleerrorsorabortentirelyendendclient.commi
之前有人问过这个问题,我发现了以下clip关于如何一次设置一个类对象的所有属性,但由于批量分配保护,这在Rails中是不可能的。(例如,您不能Object.attributes={})有没有一种很好的方法可以将一个类的属性合并到另一个类中?object1.attributes=object2.attributes.inject({}){|h,(k,v)|h[k]=vifObjectModel.column_names.include?(k);h}谢谢。 最佳答案 利用assign_attributes使用:without_prote
(跟进我之前的问题,Ruby:howcanIcopyavariablewithoutpointingtothesameobject?)我正在编写一个简单的Ruby程序来在.svg文件中进行一些替换。第一步是从文件中提取信息并将其放入数组中。为了避免每次调用此函数时都从磁盘读取文件,我尝试使用memoize设计模式-在第一次调用后的每次调用中都使用缓存结果。为此,我使用了一个在函数之前定义的全局变量。但是,即使我在返回局部变量之前将该变量.dup为局部变量,调用该变量的函数仍在修改全局变量。这是我的实际代码:#memoizetokeepfromhavingtoreadoriginalfi
一、什么是MQTT协议MessageQueuingTelemetryTransport:消息队列遥测传输协议。是一种基于客户端-服务端的发布/订阅模式。与HTTP一样,基于TCP/IP协议之上的通讯协议,提供有序、无损、双向连接,由IBM(蓝色巨人)发布。原理:(1)MQTT协议身份和消息格式有三种身份:发布者(Publish)、代理(Broker)(服务器)、订阅者(Subscribe)。其中,消息的发布者和订阅者都是客户端,消息代理是服务器,消息发布者可以同时是订阅者。MQTT传输的消息分为:主题(Topic)和负载(payload)两部分Topic,可以理解为消息的类型,订阅者订阅(Su
TCL脚本语言简介•TCL(ToolCommandLanguage)是一种解释执行的脚本语言(ScriptingLanguage),它提供了通用的编程能力:支持变量、过程和控制结构;同时TCL还拥有一个功能强大的固有的核心命令集。TCL经常被用于快速原型开发,脚本编程,GUI和测试等方面。•实际上包含了两个部分:一个语言和一个库。首先,Tcl是一种简单的脚本语言,主要使用于发布命令给一些互交程序如文本编辑器、调试器和shell。由于TCL的解释器是用C\C++语言的过程库实现的,因此在某种意义上我们又可以把TCL看作C库,这个库中有丰富的用于扩展TCL命令的C\C++过程和函数,所以,Tcl是
我正在尝试绕过rails配置这个极其复杂的迷宫。到目前为止,我设法在ubuntu上设置了rvm(出于某种原因,ruby在ubuntu存储库中已经过时了)。我设法建立了一个Rails项目。我希望我的测试项目使用mysql而不是mysqlite。当我尝试“rakedb:migrate”时,出现错误:“!!!缺少mysql2gem。将其添加到您的Gemfile:gem'mysql2'”当我尝试“geminstallmysql”时,出现错误,告诉我需要为安装命令提供参数。但是,参数列表很大,我不知道该选择哪些。如何通过在ubuntu上运行的rvm和mysql获取rails3?谢谢。
开门见山|拉取镜像dockerpullelasticsearch:7.16.1|配置存放的目录#存放配置文件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/config#存放数据的文件夹mkdir-p/opt/docker/elasticsearch/node-1/data#存放运行日志的文件夹mkdir-p/opt/docker/elasticsearch/node-1/log#存放IK分词插件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/plugins若你使用了moba,直接右键新建即可如上图所示依次类推创建