参考论文: Efficient Estimation of Word Representations in Vector Space
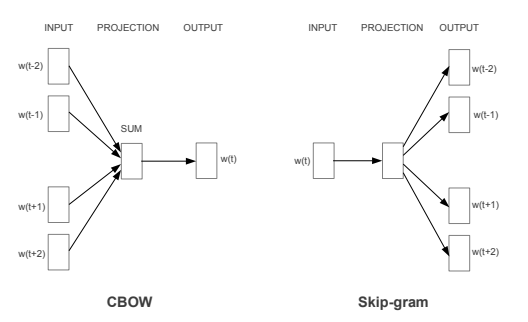
CBOW (Continuous Bag-of-Word): 挑一个要预测的词,来学习这个词前后文中词语和预测词的关系。
Skip-Gram: 使用文中的某个词,然后预测这个词周边的词。相比 CBOW 最大的不同,就是剔除掉了中间的那个 SUM 求和的过程,将词向量求和的这个过程不太符合直观的逻辑,而Skip-Gram没有这个过程。
Seq2Seq Learning 参考论文: Sequence to Sequence Learning with Neural Networks
将一个 sequence 转换成另一个 sequence。也就是用Encoder压缩并提炼第一个sequence的信息,然后用Decoder将这个信息转换成另一种语言或其他的表达形式。
In practice: Google's NMT System. 参考论文: Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
CNN for NLP 参考论文:Convolutional Neural Networks for Sentence Classification
CNN Attention Neural Image Caption Generation 参考论文: Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
Seq2Seq Attention Mechanism 参考论文:Effective Approaches to Attention-based Neural Machine Translation
NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE
Transformer 参考论文:Attention Is All You Need
Layer Normalization 参考论文:Layer Normalization
Other Normalization 参考论文:PowerNorm: Rethinking Batch Normalization in Transformers
RNN 与 attention 参考论文: Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention
ELMo 参考论文:Deep contextualized word representations
找出词语放在句子中的意思。ELMo还是想用一个向量来表达词语,不过这个词语的向量会包含上下文的信息。
ELMo的训练:前向LSTM预测后文的信息,后向LSTM预测前文的信息。训练一个顺序阅读者+一个逆序阅读者,在下游任务的时候, 分别让顺序阅读者和逆序阅读者,提供他们从不同角度看到的信息。
GPT 参考论文:Improving Language Understanding by Generative Pre-Training
Language Models are Unsupervised Multitask Learners
Language Models are Few-Shot Learners
用非监督的人类语言数据,训练一个预训练模型,然后拿着这个模型进行finetune, 基本上就可以让你在其他任务上也表现出色。
BERT 参考论文:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT 和 GPT 还有 ELMo 是一个性质的东西。 它存在的意义是要变成一种预训练模型,提供 NLP 中对句子的理解。ELMo 用了双向 LSTM 作为句子信息的提取器,同时还能表达词语在句子中的不同含义;GPT 呢, 它是一种单向的语言模型,同样也可以用 attention 的方式提取到更加丰富的语言意思信息。
SPI接收数据左移一位问题目录SPI接收数据左移一位问题一、问题描述二、问题分析三、探究原理四、经验总结最近在工作在学习调试SPI的过程中遇到一个问题——接收数据整体向左移了一位(1bit)。SPI数据收发是数据交换,因此接收数据时从第二个字节开始才是有效数据,也就是数据整体向右移一个字节(1byte)。请教前辈之后也没有得到解决,通过在网上查阅前人经验终于解决问题,所以写一个避坑经验总结。实际背景:MCU与一款芯片使用spi通信,MCU作为主机,芯片作为从机。这款芯片采用的是它规定的六线SPI,多了两根线:RDY和INT,这样从机就可以主动请求主机给主机发送数据了。一、问题描述根据从机芯片手
按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visitthehelpcenter指导。关闭9年前。我最近开始学习Ruby,这是我的第一门编程语言。我对语法感到满意,并且我已经完成了许多只教授相同基础知识的教程。我已经写了一些小程序(包括我自己的数组排序方法,在有人告诉我谷歌“冒泡排序”之前我认为它非常聪明),但我觉得我需要尝试更大更难的东西来理解更多关于Ruby.关于如何执行此操作的任何想法?
文章目录一、项目场景二、基本模块原理与调试方法分析——信源部分:三、信号处理部分和显示部分:四、基本的通信链路搭建:四、特殊模块:interpretedMATLABfunction:五、总结和坑点提醒一、项目场景 最近一个任务是使用simulink搭建一个MIMO串扰消除的链路,并用实际收到的数据进行测试,在搭建的过程中也遇到了不少的问题(当然这比vivado里面的debug好不知道多少倍)。准备趁着这个机会,先以一个很基本的通信链路对simulink基础和相关的debug方法进行总结。 在本篇中,主要记录simulink的基本原理和基本的SISO通信传输链路(QPSK方式),计划在下篇记
目录H2数据库入门以及实际开发时的使用1.H2数据库的初识1.1H2数据库介绍1.2为什么要使用嵌入式数据库?1.3嵌入式数据库对比1.3.1性能对比1.4技术选型思考2.H2数据库实战2.1H2数据库下载搭建以及部署2.1.1H2数据库的下载2.1.2数据库启动2.1.2.1windows系统可以在bin目录下执行h2.bat2.1.2.2同理可以通过cmd直接使用命令进行启动:2.1.2.3启动后控制台页面:2.1.3spring整合H2数据库2.1.3.1引入依赖文件2.1.4数据库通过file模式实际保存数据的位置2.2H2数据库操作2.2.1Mysql兼容模式2.2.2Mysql模式
CSDN优秀解读:https://blog.csdn.net/jiaoyangwm/article/details/1266387752021https://arxiv.org/pdf/2103.14259.pdf关键解读在目标检测中标签分配的最新进展主要寻求为每个GT对象独立定义正/负训练样本。在本文中,我们创新性地从全局的角度重新审视标签分配,并提出将分配程序制定为一个最优传输(OT)问题——优化理论中一个被充分研究的课题。具体来说,我们将每个需求方(锚框)和供应商(GT标签)的单位传输成本定义为他们的分类和回归损失加权之和。在公式化后,找到最好的分配方案即为最小传播成本解决最优传输方案,
【动态规划】一、背包问题1.背包问题总结1)动规四部曲:2)递推公式总结:3)遍历顺序总结:2.01背包1)二维dp数组代码实现2)一维dp数组代码实现3.完全背包代码实现4.多重背包代码实现一、背包问题1.背包问题总结暴力的解法是指数级别的时间复杂度。进而才需要动态规划的解法来进行优化!背包问题是动态规划(DynamicPlanning)里的非常重要的一部分,关于几种常见的背包,其关系如下:在解决背包问题的时候,我们通常都是按照如下五部来逐步分析,把这五部都搞透了,算是对动规来理解深入了。1)动规四部曲:(1)确定dp数组及其下标的含义(2)确定递推公式(3)dp数组的初始化(4)确定遍历顺
Asitcurrentlystands,thisquestionisnotagoodfitforourQ&Aformat.Weexpectanswerstobesupportedbyfacts,references,orexpertise,butthisquestionwilllikelysolicitdebate,arguments,polling,orextendeddiscussion.Ifyoufeelthatthisquestioncanbeimprovedandpossiblyreopened,visitthehelpcenter提供指导。已关闭8年。什么是学习ruby语言
Two-StreamConvolutionalNetworksforActionRecognitioninVideos双流网络论文精读论文:Two-StreamConvolutionalNetworksforActionRecognitioninVideos链接:https://arxiv.org/abs/1406.2199本文是深度学习应用在视频分类领域的开山之作,双流网络的意思就是使用了两个卷积神经网络,一个是SpatialstreamConvNet,一个是TemporalstreamConvNet。此前的研究者在将卷积神经网络直接应用在视频分类中时,效果并不好。作者认为可能是因为卷积神经
论文常见数学符号及其含义(科研必备)返回论文和资料目录数学符号在数学领域是非常重要的。在论文中,使用数学符号可以使得论文更加简洁明了,同时也能够准确地描述各种概念和理论。在本篇博客中,我将介绍一些常见的数学符号及其含义(省去特别简单的符号),希望能够帮助读者更好地理解数学论文。高等数学∑i=1nxi\sum_{i=1}^nx_i∑i=1nxi(求和符号):表示将x1,x2,…,xnx_1,x_2,\dots,x_nx1,x2,…,xn中的所有数相加,例如∑i=1nxi\sum_{i=1}^nx_i∑i=1nxi表示将x1,x2,…,xnx_1,x_2,\dots,x_nx1,x
目录文章信息写在前面Background&MotivationMethodDCNV2DCNV3模型架构Experiment分类检测文章信息Title:InternImage:ExploringLarge-ScaleVisionFoundationModelswithDeformableConvolutionsPaperLink:https://arxiv.org/abs/2211.05778CodeLink:https://github.com/OpenGVLab/InternImage写在前面拿到文章之后先看了一眼在ImageNet1k上的结果,确实很高,超越了同等大小下的VAN、RepLK