文章目录
本篇文章参考李宏毅老师的讲课视频,截图均来自老师的PPT,本文是学习笔记。原视频大家可以自行搜索观看
自注意力机制最初是NLP领域的
首先我们了解一下三种任务分类:
输出一个句子,可以看作一个序列。
1、输入和输出长度一致,每个vector对应一个label
假定现在做一个词性分析的任务,就是输入英文句子,给出每个单词的词性
2、整个序列对应一个label
假定现在做一个语义判断的任务,输出英文句子,给出这个句子的好坏判断。好or不好
3、输出长度不确定,由机器决定输出label的长度,这种任务叫做seq2seq
我们常见的翻译任务就是seq2seq。输出句子,输出翻译好的句子的长度是不定的。
我们以第一种为例:
假定现在做词性分析,输入一句话I saw a saw,这句话的意思是我看到了一把锯子。
那么我们用最简单的全连接网络来做这个任务
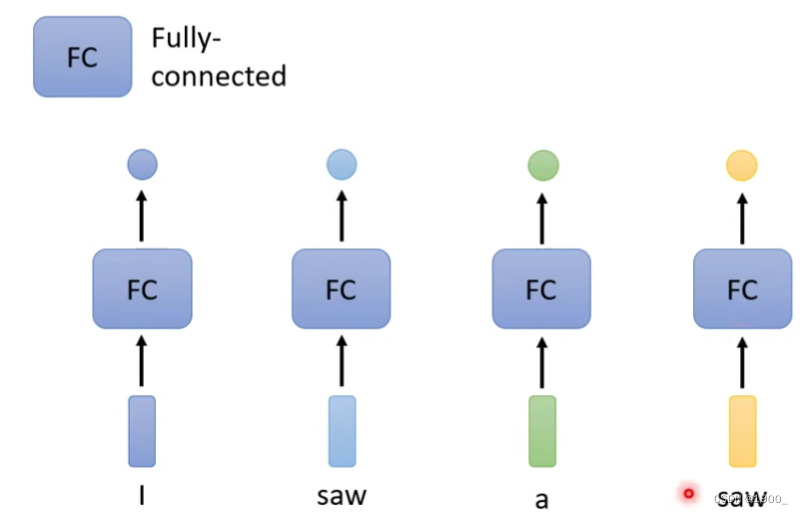
这种做法的缺点是,机器不能判断出来后一个saw做名词,表示锯子的意思
因为对于机器来说两个saw完全一样,不会输出不同的结果。
那么我们就想,如何让神经网络结合上下文的信息呢
我们可以将一个词汇的前后几个词汇串起来,称为一个window,一起输出到网络中训练
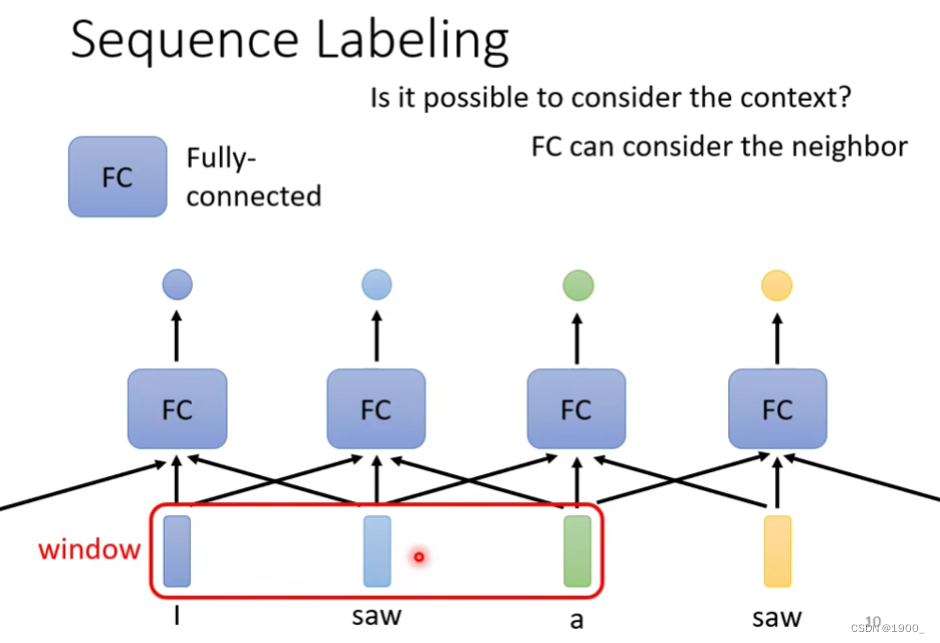
那么,按照这种方法,如果我们想考虑整个句子的信息,就需要把这个windows的大小设置为整个句子的大小。
他的问题在于:训练中每个句子都是不一样长度的,如果你想用一个windows把所有的句子都能框起来,那就需要以训练数据中最长的那个句子长度作为windows的长度来算,这样一来,计算量太大了。
所以,就引入了我们的自注意力机制
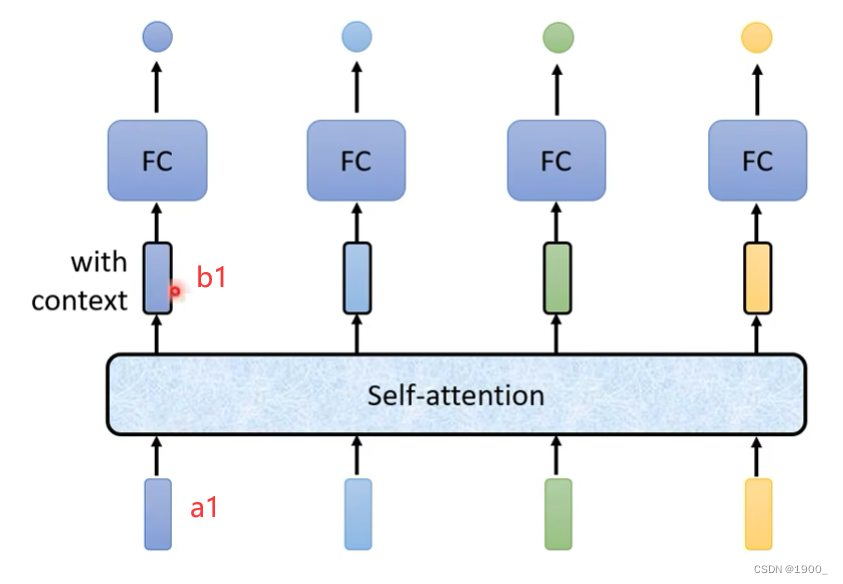
自注意力可以处理整个序列,如图
我们将一句话中每个单词,编码为一个词向量(方便网络处理),比如第一个单词“I”被编码后的向量为a1
a1经过自注意力机制输出的b1,b1是考虑了整个输入序列才得到的输出
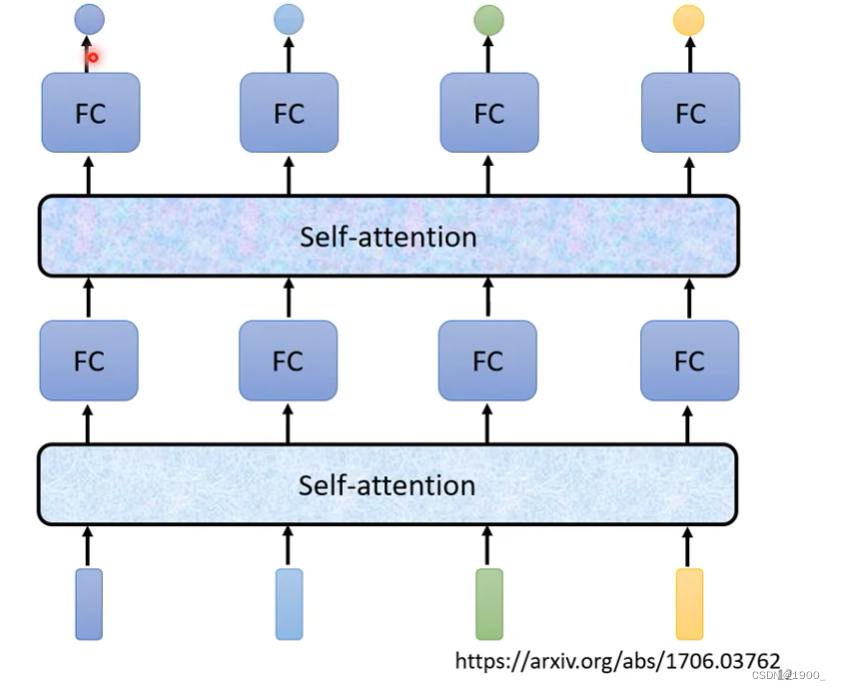
自注意力机制还可以堆叠,经过自注意力得到的输出还可以再做一遍自注意力
那么b1是怎么来的呢
首先,我们假设输入序列是a1,a2,a3,a4
第一步是,计算a1和其他向量的相关度(关联度)
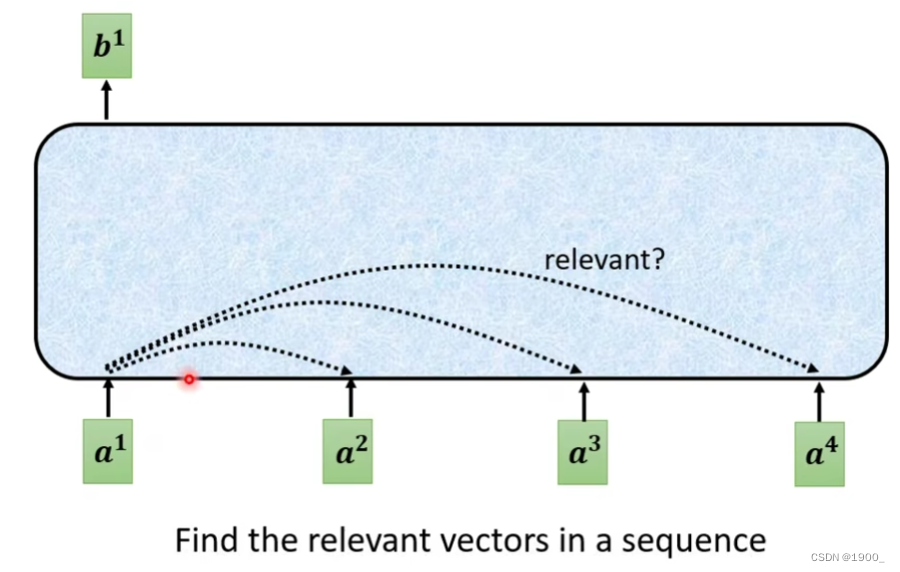
计算相关性有很多方法,常见的做法是点积。
如图,输入两个向量,分别乘上两个矩阵 W q , W K W^q,W^K Wq,WK,得到q和k,再做一个点乘,就得到了相关度 α \alpha α
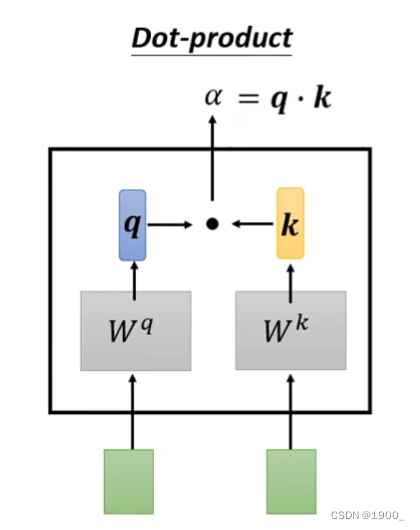
我们一般把这个q叫做query,k是key
那我们计算出a1的q,再计算出a2的k,我们就可以计算出a1和a2的关联性,我们把这个称作注意力分数
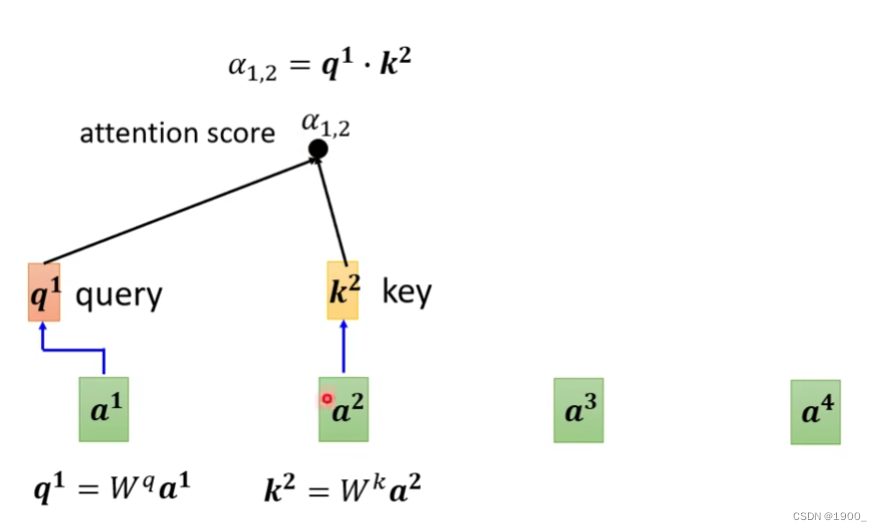
把a1和其他的所有输入的关联性全部算出来,同时,我们实际算的时候,还会计算a1和自己的关联性,如图,就是计算结果
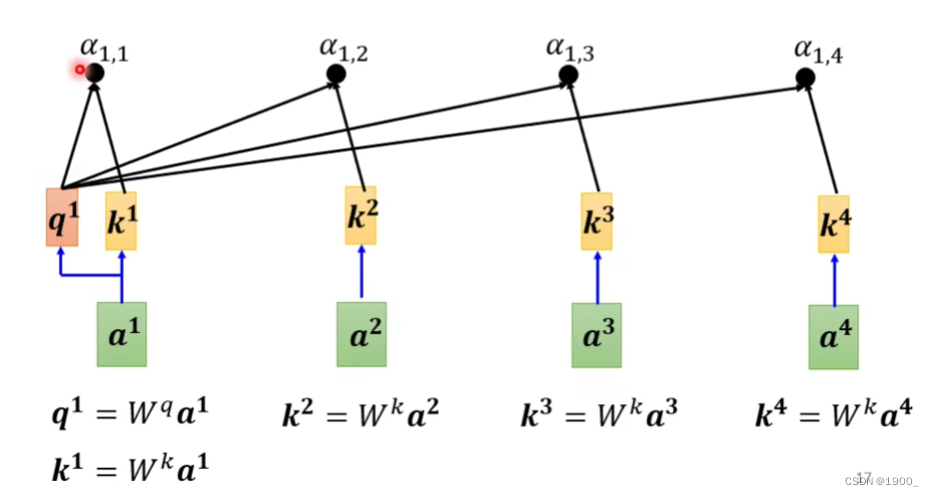
计算完了之后,经过一个softmax(这里用ReLU也行,都可以)
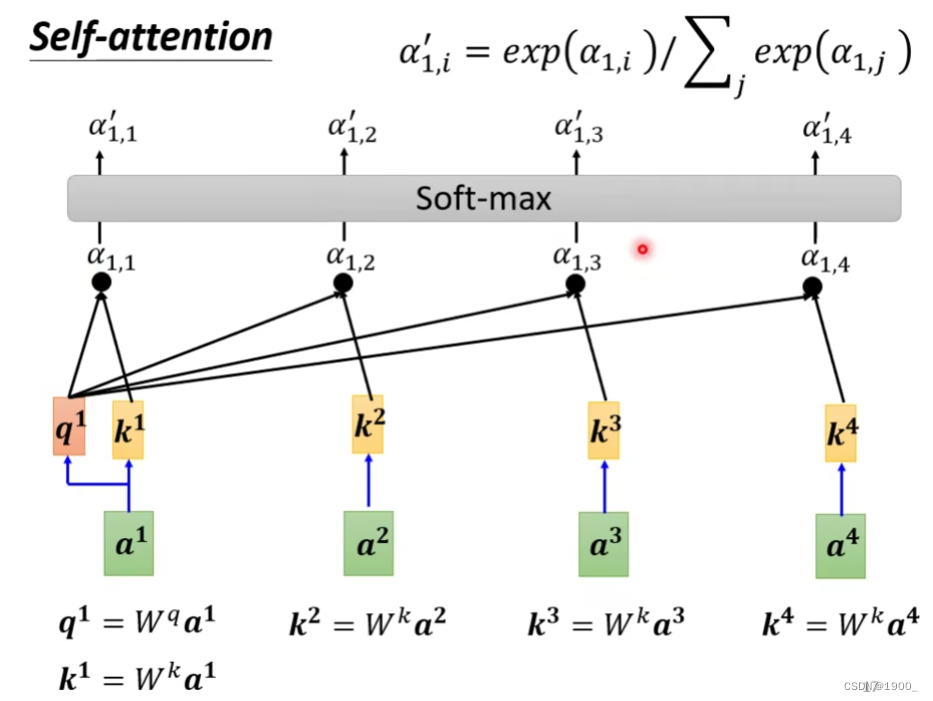
经过softmax后我们就得到了 a 1 ′ , a 2 ′ , a 3 ′ , a 4 ′ a_1',a_2',a_3',a_4' a1′,a2′,a3′,a4′
接下来,我们把原始的输入序列a1,a2,a3,a4分别乘以一个 W v W^v Wv,得到对应的v1,v2,v3,v4
这个
W
v
W^v
Wv叫做value
我们把v1,v2,v3,v4分别与
a
1
′
,
a
2
′
,
a
3
′
,
a
4
′
a_1',a_2',a_3',a_4'
a1′,a2′,a3′,a4′相乘
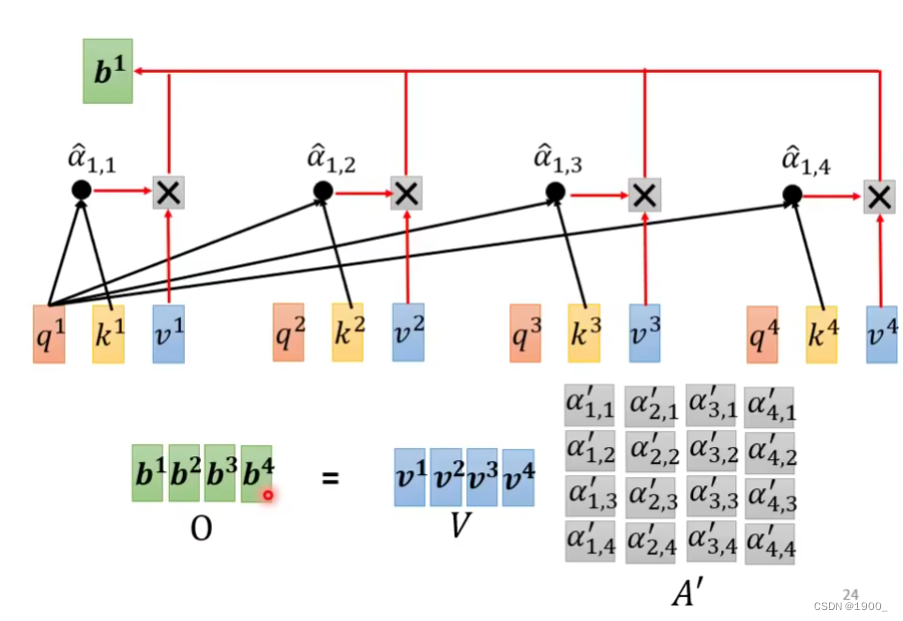
再把这个结果累加就得到了我们的输出b1
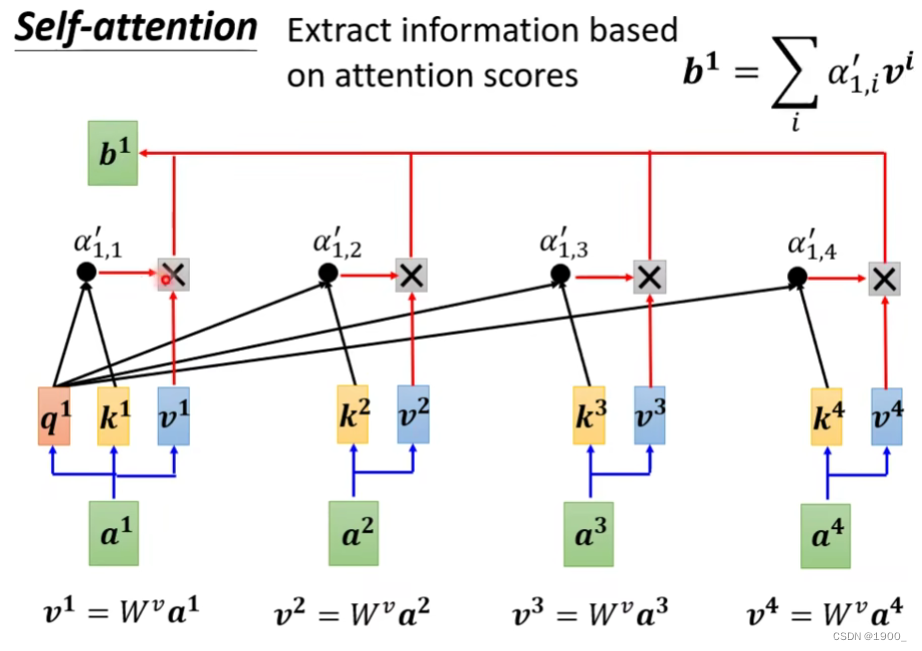
他这个原理其实就是, a 1 ′ , a 2 ′ , a 3 ′ , a 4 ′ a_1',a_2',a_3',a_4' a1′,a2′,a3′,a4′其实代表了a1与所有向量的相关度,如果和某一个向量的相关度比较高,那么与v相乘之后得到的值也会比较大,最后累加之后,累加得到的这个值,也会更加偏向于那个相关性更高的向量信息。
b2,b3,b4与b1的计算方式一样。最终得到自注意力的输出。
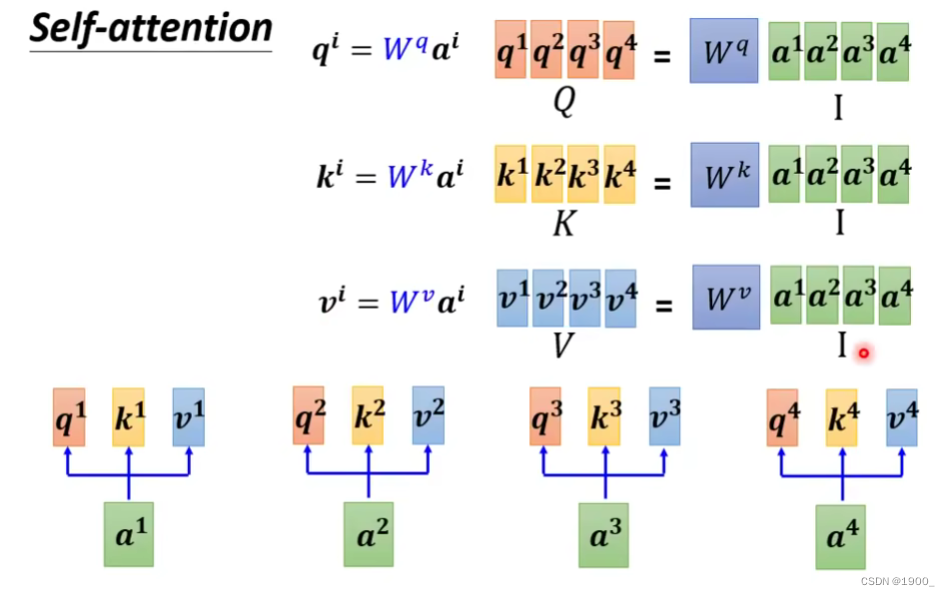
那么整个过程我们了解了,就会发现,对于每一个 a 1 a^1 a1,我们都要产生对应的 q 1 , k 1 , v 1 q^1,k^1,v^1 q1,k1,v1
那么用矩阵运算就是如图所示
把a1,a2,a3,a4组合成一个矩阵,乘以
Q
,
K
,
V
Q,K,V
Q,K,V就行了
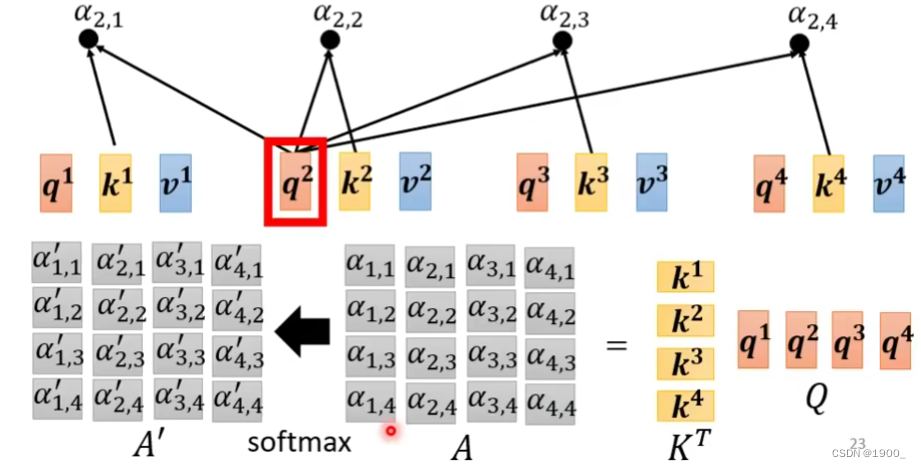
那么相关度的计算,或者说注意力分数的计算如图所示,用 Q Q Q乘以 K T K^T KT最后全部经过一个softmax,就得到了 A ′ A' A′,有时候我们把 A ′ A' A′也叫做Attention Matrix。这就是注意力分数
那么再把 A ′ A' A′乘上V,就得到了自注意力的输出结果
在整个自注意力机制中,需要学习的参数就是
W
q
,
W
k
,
W
v
W^q,W^k,W^v
Wq,Wk,Wv这三个。
汇总图:
Multi-head self-attention
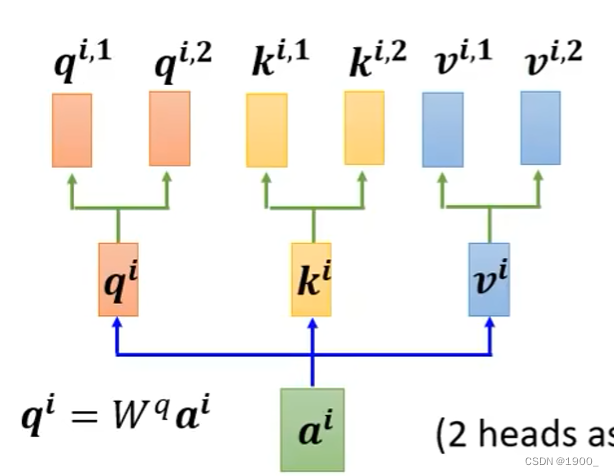
学习了自注意力机制之后,我们知道,我们用a1的q来计算他和其他元素的相关性,但是呢,相关性这个东西,其实有多种不同的,比如a1和a2在词性上相关,a1和a3在词性上不相关,但是在单词组成上相关(长得像),所以我们可以用多个q,来衡量相关性,目的是为了衡量不同角度的相关性。
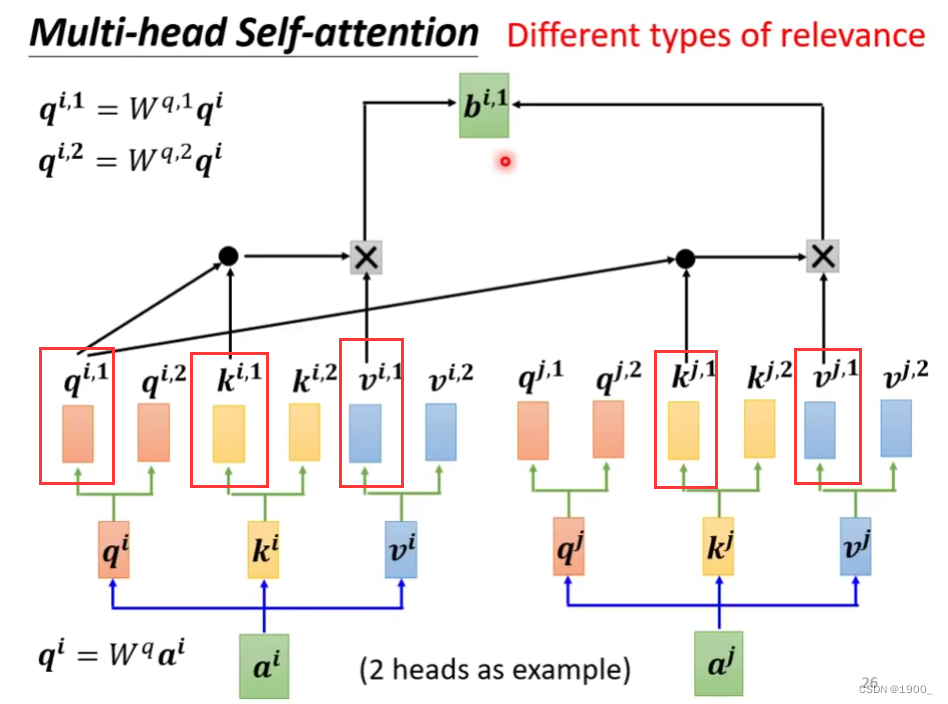
如果我们认为一个任务,存在两种不同的相关性,那我们就使用两个q,同理,对应的我们也需要两个k,两个v,如图所示,这就是双头自注意力
然后我们做softmax的时候,首先只用其中一个head,来做
再用另一个head来做,所以就得到两个b
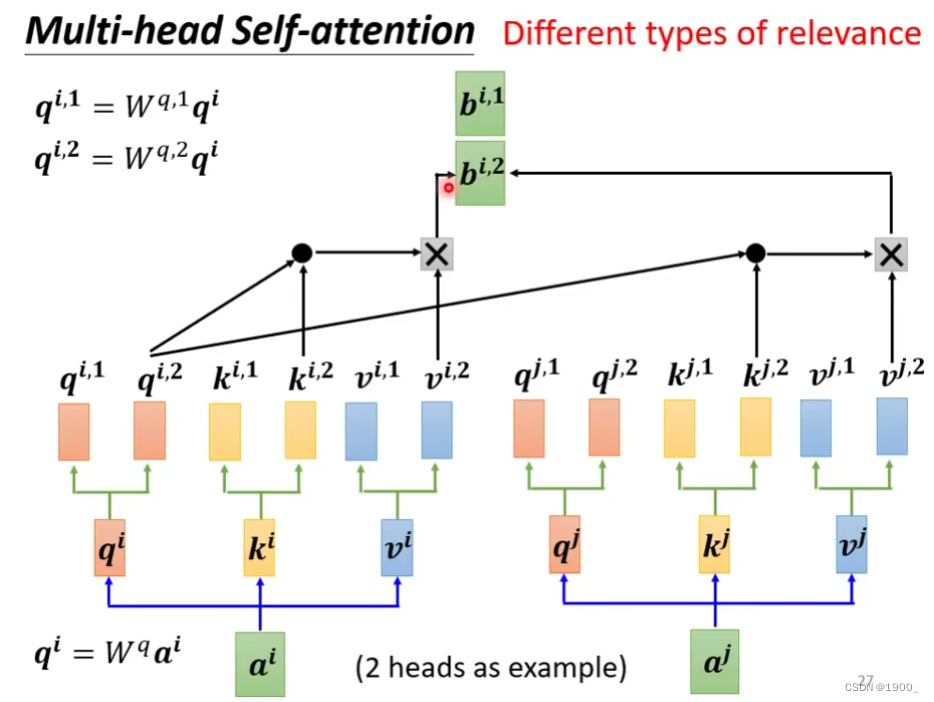
那么你多头注意力就会得到多个b,将这些并起来,然后乘以一个矩阵,就得到了输出
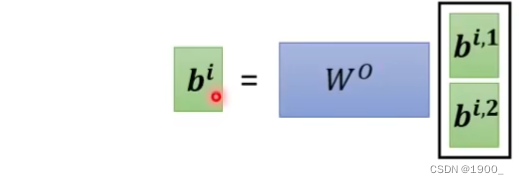
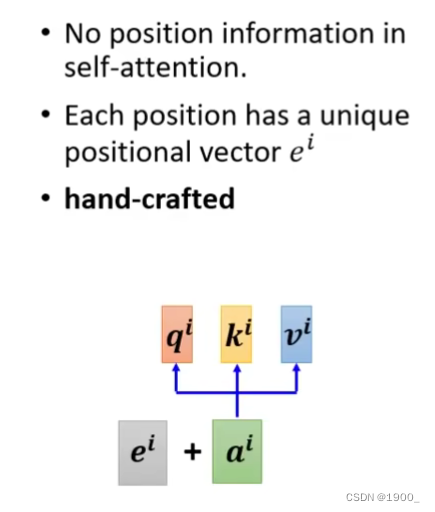
那么说到这里,自注意力机制就完了。但是他有一个问题,我们使用自注意力机制计算了不同单词之间的相关性,但是整个过程忽略了位置信息。经过softmax之后,没有各个向量之间的位置信息。但是位置信息对于我们来说是重要的,比如如果这个单词出现在句子首位那他可能大概率不是动词,所以位置有的时候是重要的。
如何把位置信息加进去呢,做法是把每一个位置,对应一个向量 e i e^i ei
把位置信息加上去就好了,这个 e i e^i ei是我们自己设置的。
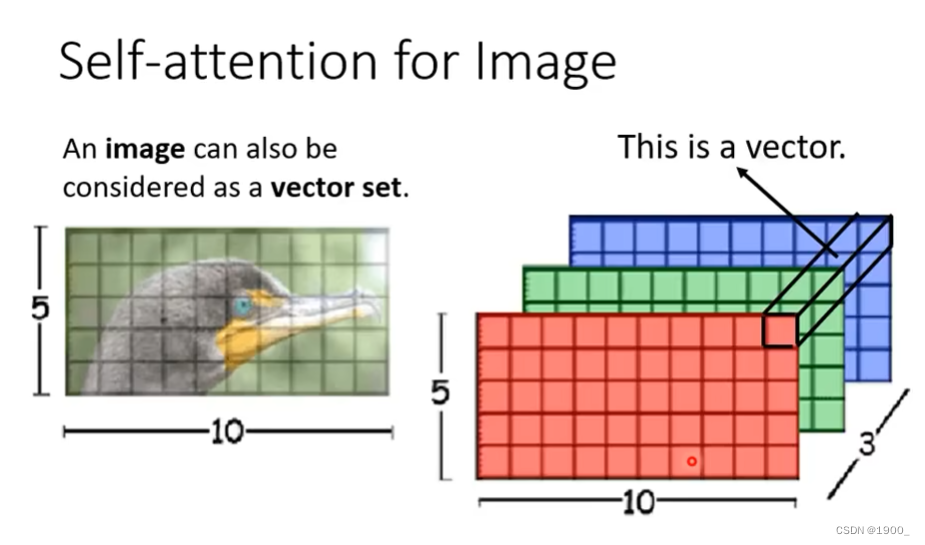
那么刚才说的都是NLP领域的,每个句子我们编码成一个向量,那么图像里面怎么用自注意力机制呢
一张5x10的RGB图像就是5x10x3的矩阵,那么如果我们把每个像素在各个通道上的值拿出来,组成一个向量,这样这张图片就有5x10个向量了,把这些向量当作输入,进行自注意力就行了。
那么自注意力机制和CNN的区别在哪呢
我们用自注意力机制的时候,图像中的某个像素,会和其他所有像素做相关性计算,也就是说,对于一个像素,我们考虑了整张图像。
而CNN呢,由于卷积的特性,他只考虑感受野内的信息,所以没有self-attention考虑的多,我们可以认为CNN就是简化版的self-attention
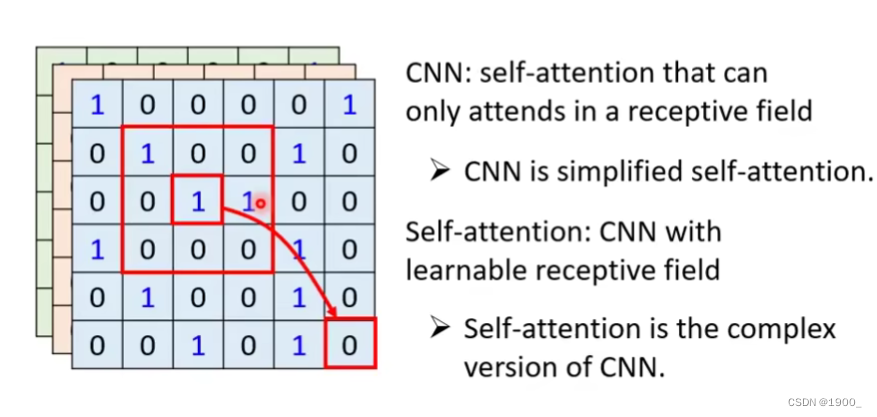
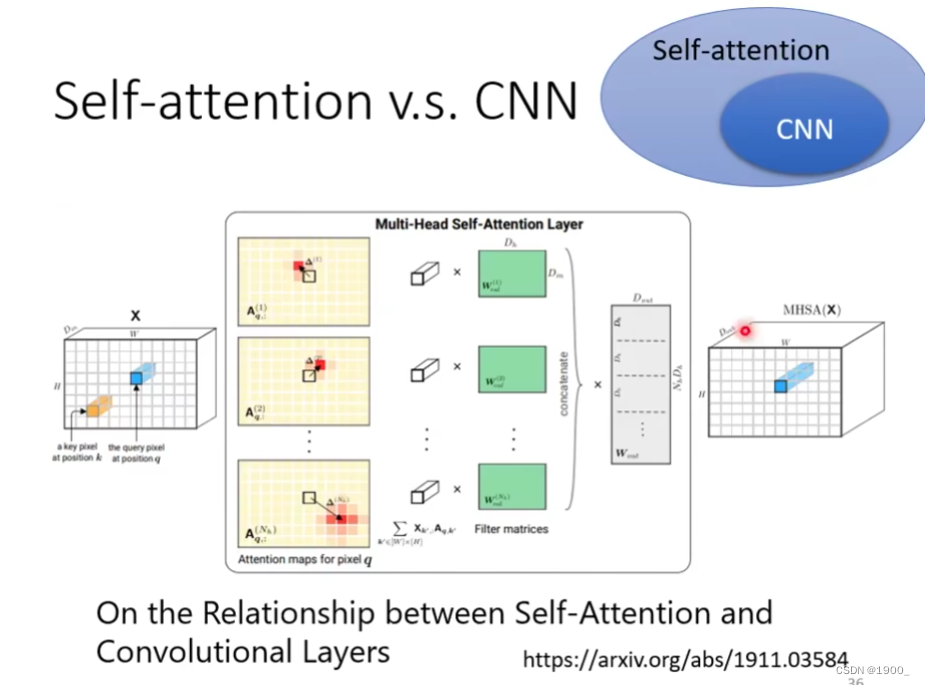
这篇论文证明了CNN就是self-attention的特例,self-attention只要经过精心的设计,就可以做到与CNN一样的效果。
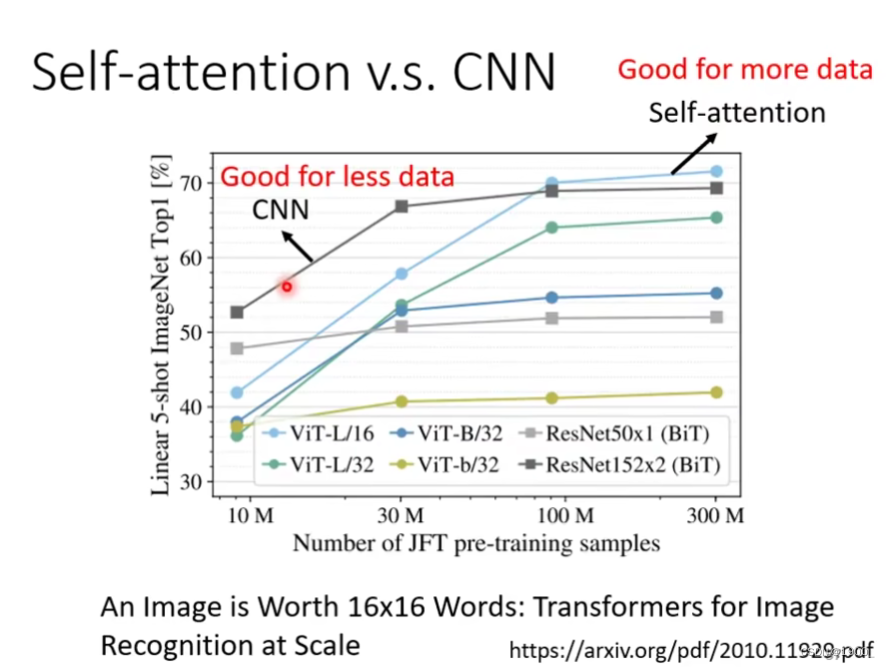
self-attention应用在图像上面,最著名的论文是An lmage is Worth 16x16 Words: Transformers for ImageRecognition at Scale
https://arxiv.org/pdf/2010.11929,pdf
谷歌的文章,他就是把一张图片,分成16x16的小块,每个小块看作一个向量,输入到self-attention上面。
这张图我们可以看出,训练资料少的时候,CNN的效果会好于自注意力,训练数据越来越大的时候,自注意力的效果会好于CNN。这个我们可以从一个角度解释:自注意力看的更多,所以训练数据少的时候,他容易过拟合,他需要更多的训练数据,而CNN 看的范围少,所以训练数据少的时候,效果更好
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
作为新的阿里云用户,您可以50免费试用多种优惠,价值高达1,700美元(或8,500美元)。这将让您了解和体验阿里云平台上提供的一系列产品和服务。如果您以个人身份注册免费试用,您将获得价值1,700美元的优惠。但是,如果您是注册公司,您可以选择企业免费试用,提交基本信息通过企业实名注册验证,即可开始价值$8,500的免费试用!本教程介绍了如何设置您的帐户并使用您的免费试用版。关于免费试用在我们开始此试用之前,您还必须遵守以下条款和条件才能访问您的免费试用:只有在一年内创建的账户才有资格获得阿里云免费试用。通过此免费试用优惠,用户可以免费试用免费试用活动页面上列出的每种产品一次。如果您有多个帐
#app/models/product.rbclassProduct我从Controller调用方法1。当我运行程序时。我收到一个错误:method_missing(atlinemethod2(param2)).rbenv/versions/2.3.1/lib/ruby/gems/2.3.0/gems/activerecord-5.0.0/lib/active_record/relation/batches.rb:59:in`block(2levels)infind_each... 最佳答案 classProduct说明:第一个是类
我明白了defa(&block)block.call(self)end和defa()yieldselfend导致相同的结果,如果我假设有这样一个blocka{}。我的问题是-因为我偶然发现了一些这样的代码,它是否有任何区别或者是否有任何优势(如果我不使用变量/引用block):defa(&block)yieldselfend这是一个我不理解&block用法的具体案例:defrule(code,name,&block)@rules=[]if@rules.nil?@rules 最佳答案 我能想到的唯一优点就是自省(introspecti
我完全不是程序员,正在学习使用Ruby和Rails框架进行编程。我目前正在使用Ruby1.8.7和Rails3.0.3,但我想知道我是否应该升级到Ruby1.9,因为我真的没有任何升级的“遗留”成本。缺点是什么?我是否会遇到与普通gem的兼容性问题,或者甚至其他我不太了解甚至无法预料的问题? 最佳答案 你应该升级。不要坚持从1.8.7开始。如果您发现不支持1.9.2的gem,请避免使用它们(因为它们很可能不被维护)。如果您对gem是否兼容1.9.2有任何疑问,您可以在以下位置查看:http://www.railsplugins.or
我正在尝试获得良好的Ruby编码风格。为防止意外调用具有相同名称的局部变量,我总是在适当的地方使用self.。但是现在我偶然发现了这个:classMyClass上面的代码导致错误privatemethodsanitize_namecalled但是当删除self.并仅使用sanitize_name时,它会起作用。这是为什么? 最佳答案 发生这种情况是因为无法使用显式接收器调用私有(private)方法,并且说self.sanitize_name是显式指定应该接收sanitize_name的对象(self),而不是依赖于隐式接收器(也是
我的rails3.1.6应用程序中有一个自定义访问器方法,它为一个属性分配一个值,即使该值不存在。my_attr属性是一个序列化的哈希,除非为空白,否则应与给定值合并指定了值,在这种情况下,它将当前值设置为空值。(添加了检查以确保值是它们应该的值,但为简洁起见被删除,因为它们不是我的问题的一部分。)我的setter定义为:defmy_attr=(new_val)cur_val=read_attribute(:my_attr)#storecurrentvalue#makesureweareworkingwithahash,andresetvalueifablankvalueisgiven
如何学习ruby的正则表达式?(对于假人) 最佳答案 http://www.rubular.com/在Ruby中使用正则表达式时是一个很棒的工具,因为它可以立即将结果可视化。 关于ruby-我如何学习ruby的正则表达式?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/1881231/