又是一年春招时,有幸收到华为自动驾驶算法岗,之前刷题不多,在此汇总下牛客网的真题,主要采用Python编写,个人觉得语言只是实现工具而已,并不是很关键,Python简洁易懂,更加适合算法工程师快速验证idear,避免重复造轮子的繁琐,希望对看合集的你有些许帮助!
文章目录
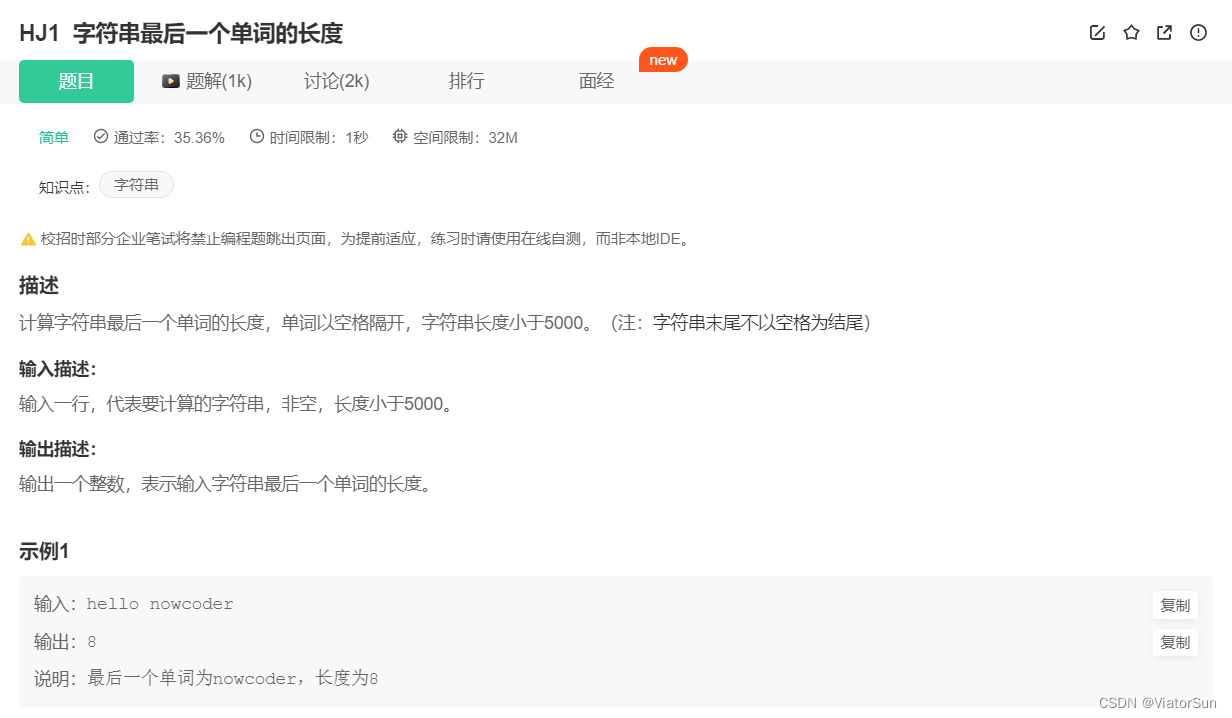
Python 读取输入信息 input() ,通过 .split() 进行切分,计算最后一个单词的长度
string = input()
str_lst = string.split(" ")
print(len(str_lst[-1]))
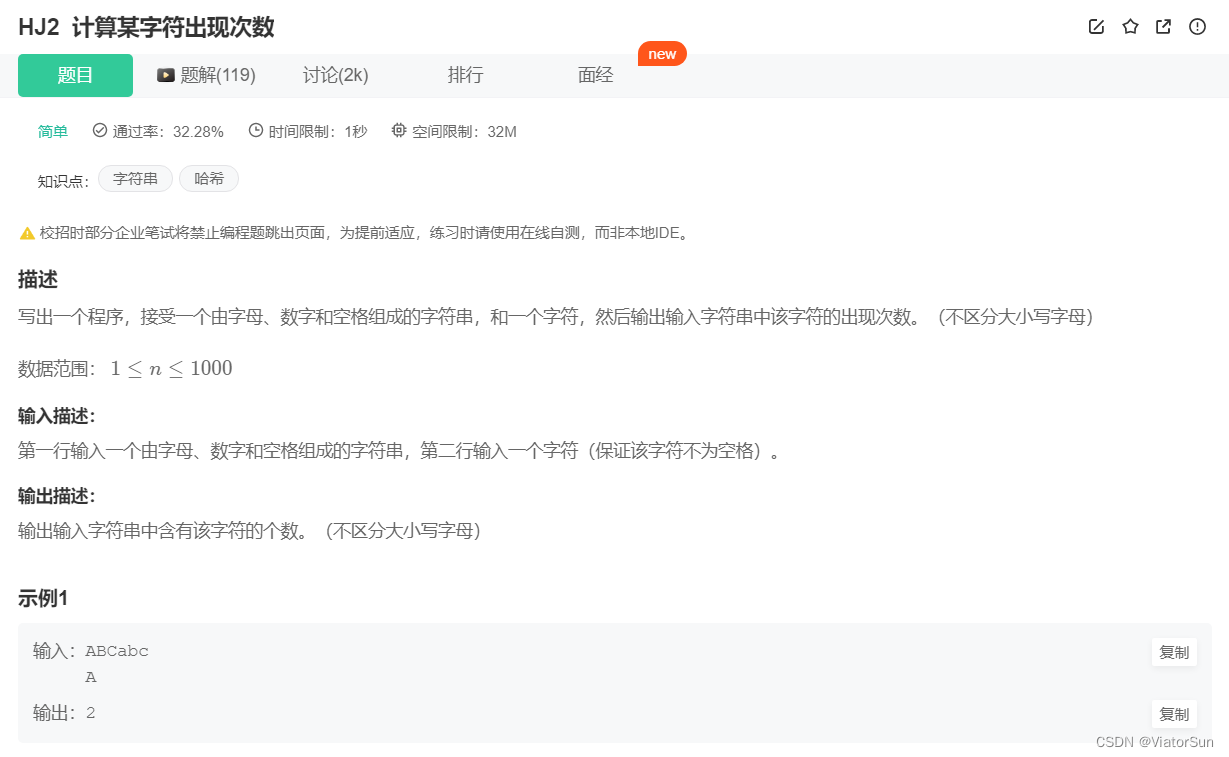
因为不考虑大小写情况,可以考虑采用 .upper() / .lower() 将字符串全部转化为 大写/小写
string = input().lower()
check = input().lower()
num = string.count(check)
print(num)
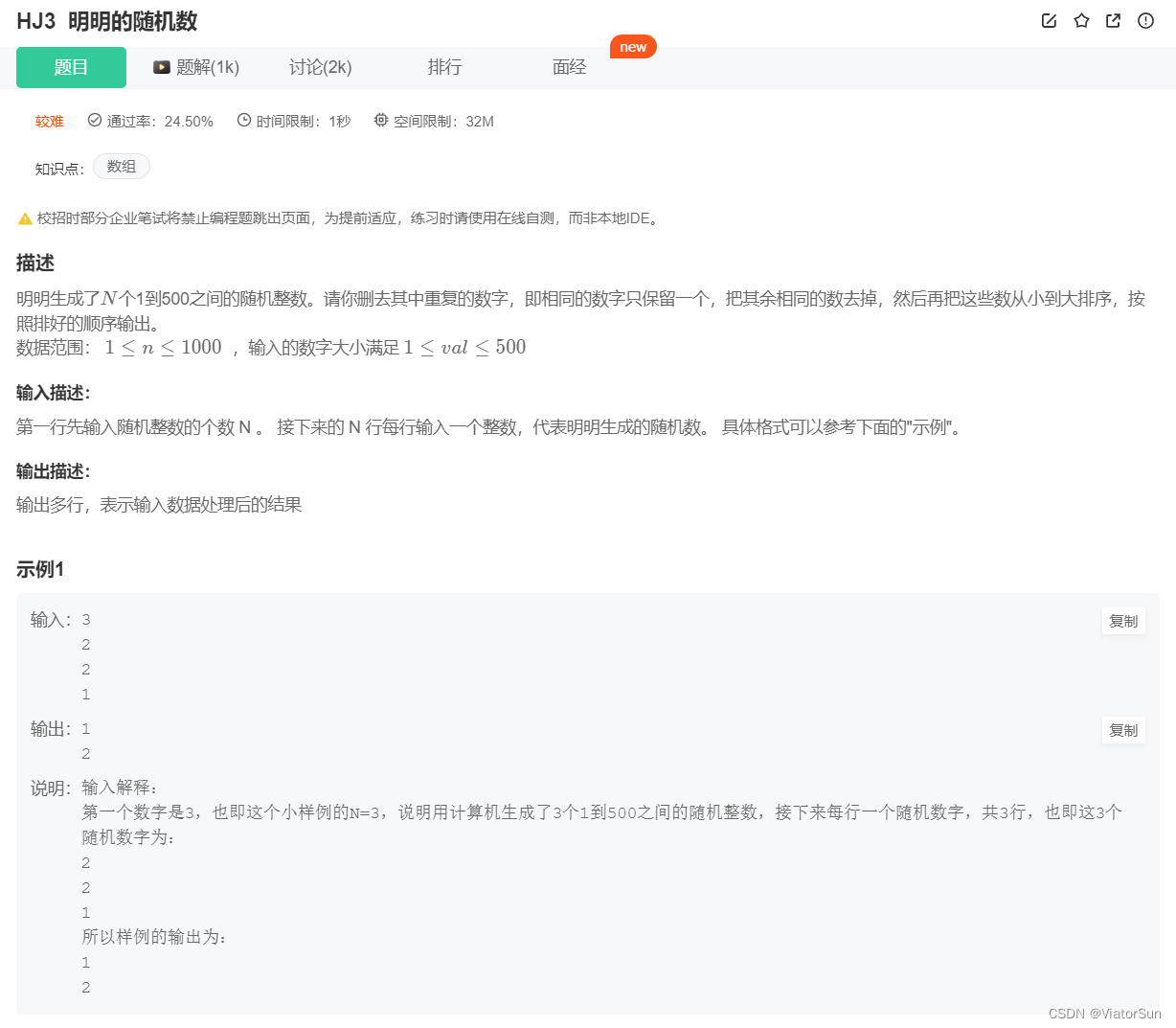
需要注意一点,输入的不仅有 随机数的个数,还有具体的随机数[此随机数不是自己生成的,而是需要输入的,并且是多行输入,需要循环读取输入]
n = input()
lst = []
for i in range(int(n)):
lst.append(int(input()))
ulst = set(lst)
for j in sorted(ulst):
print(j)
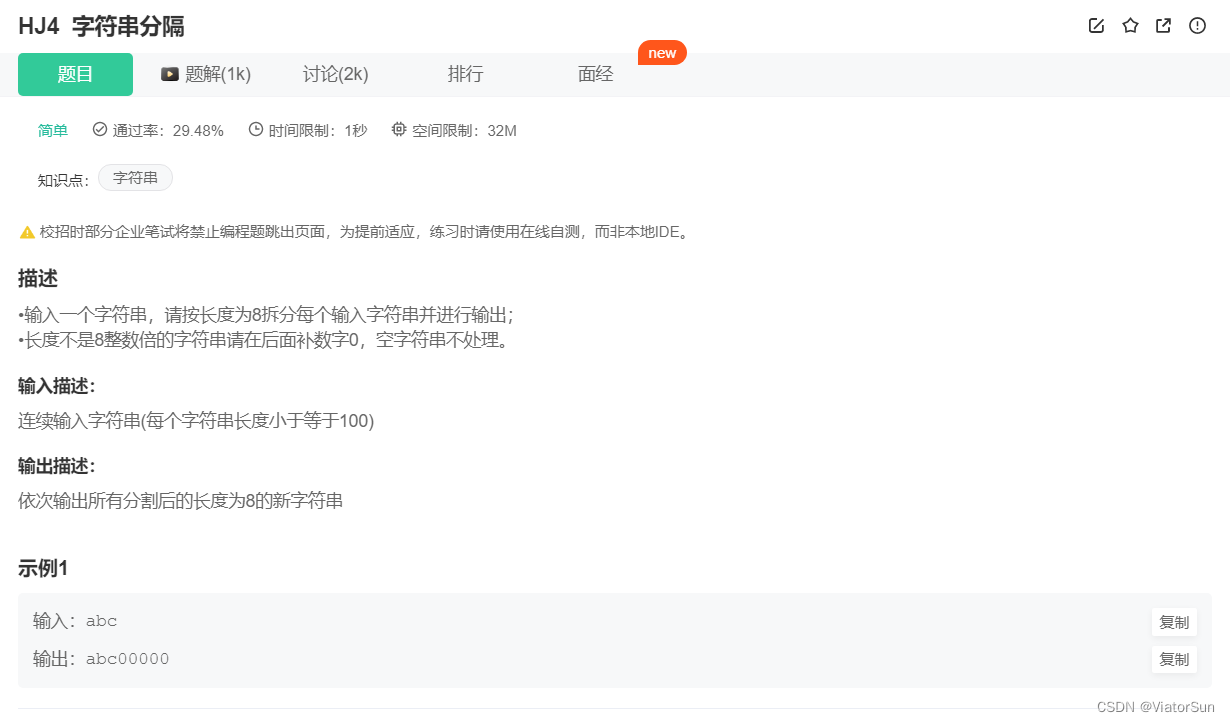
重点在于如何在字符串后面补数字0,博主采用的字符串拼接
string = input()
num = len(string)
num_1 = num //8
num_2 = num % 8
for i in range(num_1 ):
print(string[i * 8: i * 8+8 ]) # 8 -> 8+8 共8个数,即0-7
if num_2 != 0:
lst = string[-num_2:] + (8-num_2) * "0"
print(lst)
Python ljust() 方法返回一个原字符串左对齐,并使用空格填充至指定长度的新字符串。如果指定的长度小于原字符串的长度则返回原字符串。
str.ljust(width[, fillchar])
width -- 指定字符串长度。
fillchar -- 填充字符,默认为空格。
# ---------------------------------------------- #
temp = input()
while(len(temp)>0):
print(temp[:8].ljust(8,"0"))
temp = temp[8:]
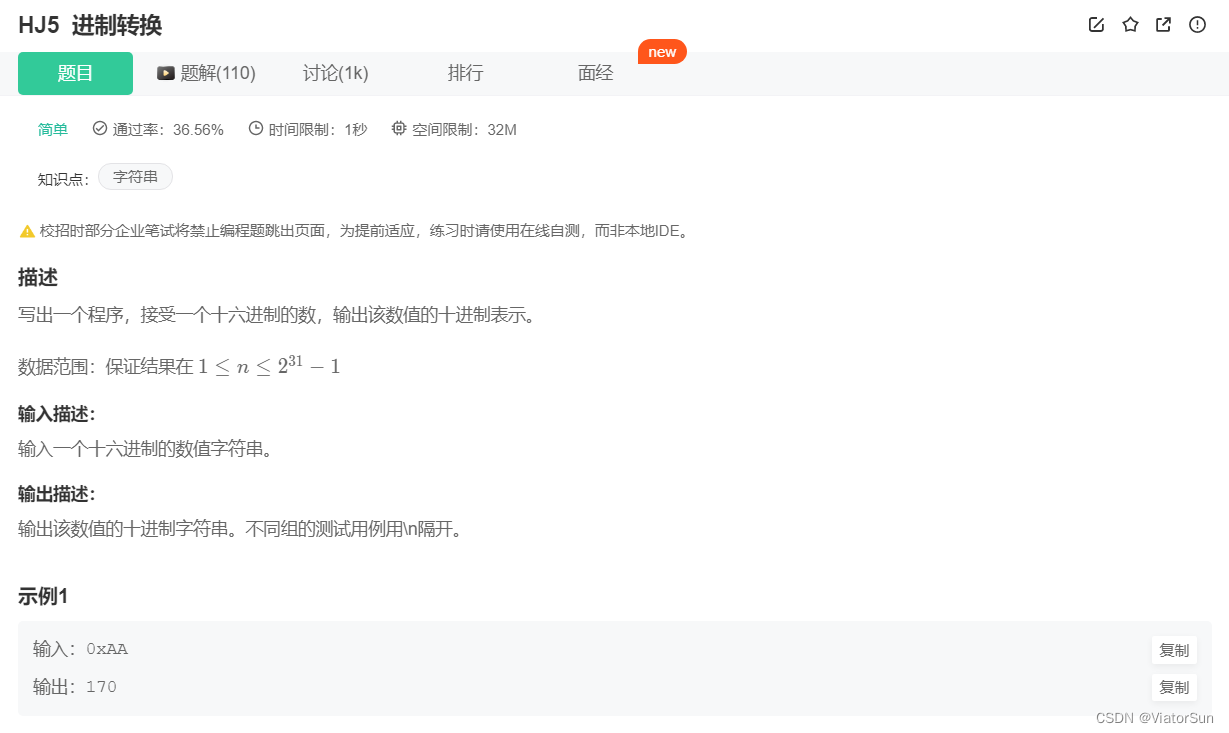
Python 的 int 可以进行进制转换,进制为传入参数的进制,统一返回10进制
int()函数可以实现将数字或字符转为整数,如果是实数,则只取整数部分
当输入字符包含了如下字符:0x(十六进制标志)、0o(八进制标志)、0b(二进制标志), int函数的第二个参数必须为0
0x(十六进制标志)、0o(八进制标志)、0b(二进制标志)
调用函数otc函数,转换为八进制
采用自带函数bin获取
num = input()
print(int(num, 16))
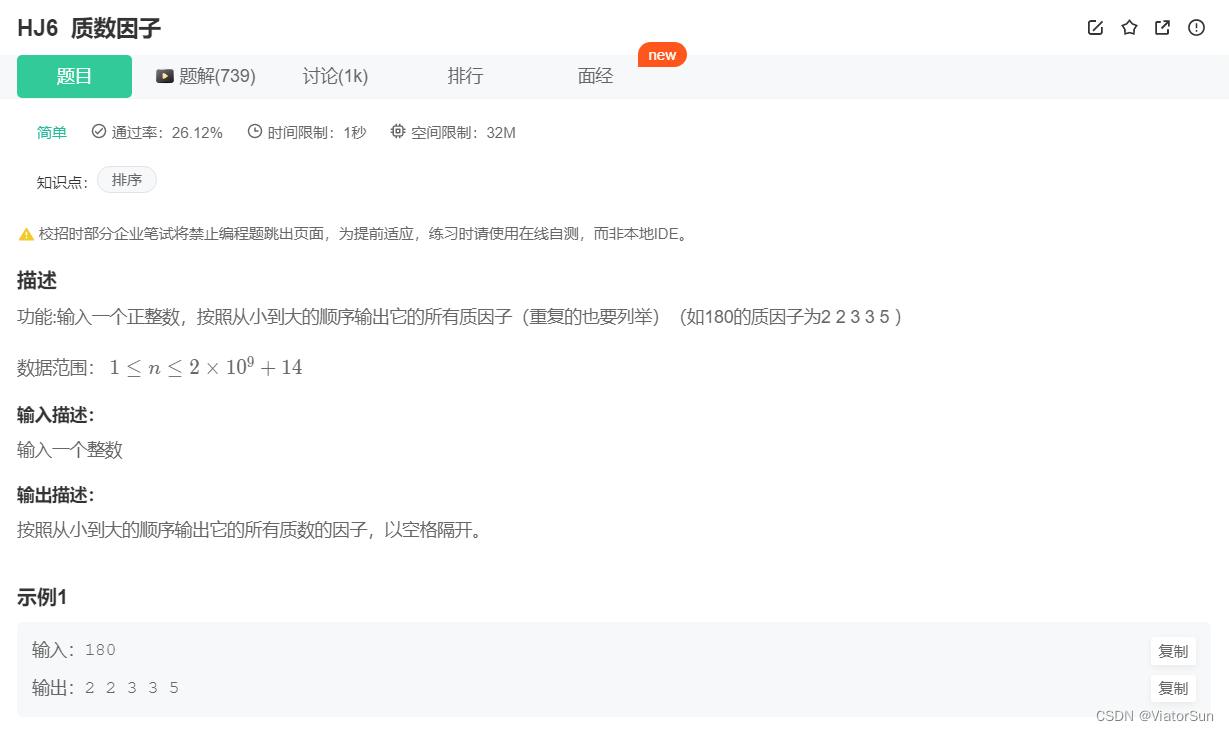
import math
n = int(input())
for i in range(2, int(math.sqrt(n))+1):
while n % i == 0:
print(i, end=' ')
n = n // i
if n > 2:
print(n)
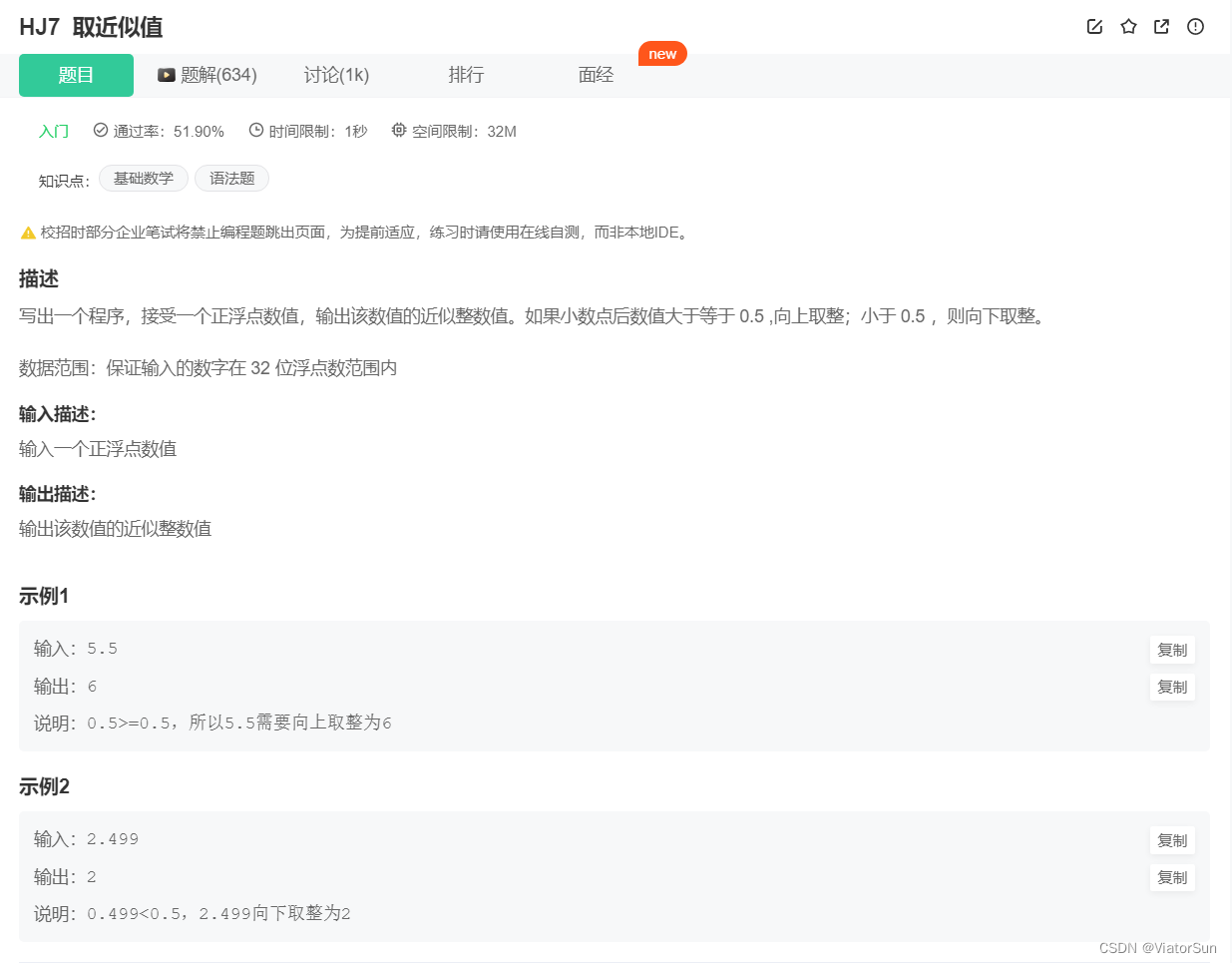
通过 int 函数进行转换,
inp = float(input())
print(int(inp + 0.5)) # 0.5 向上取整
# ------------------------------------------------------ #
from math import ceil, floor
def ceilNumber(n):
a = ceil(n)-n # ceil 向上取整
if (a<0.5):
return ceil(n)
return floor(n) # floor 向下取整
b = float(input())
print(ceilNumber(b))
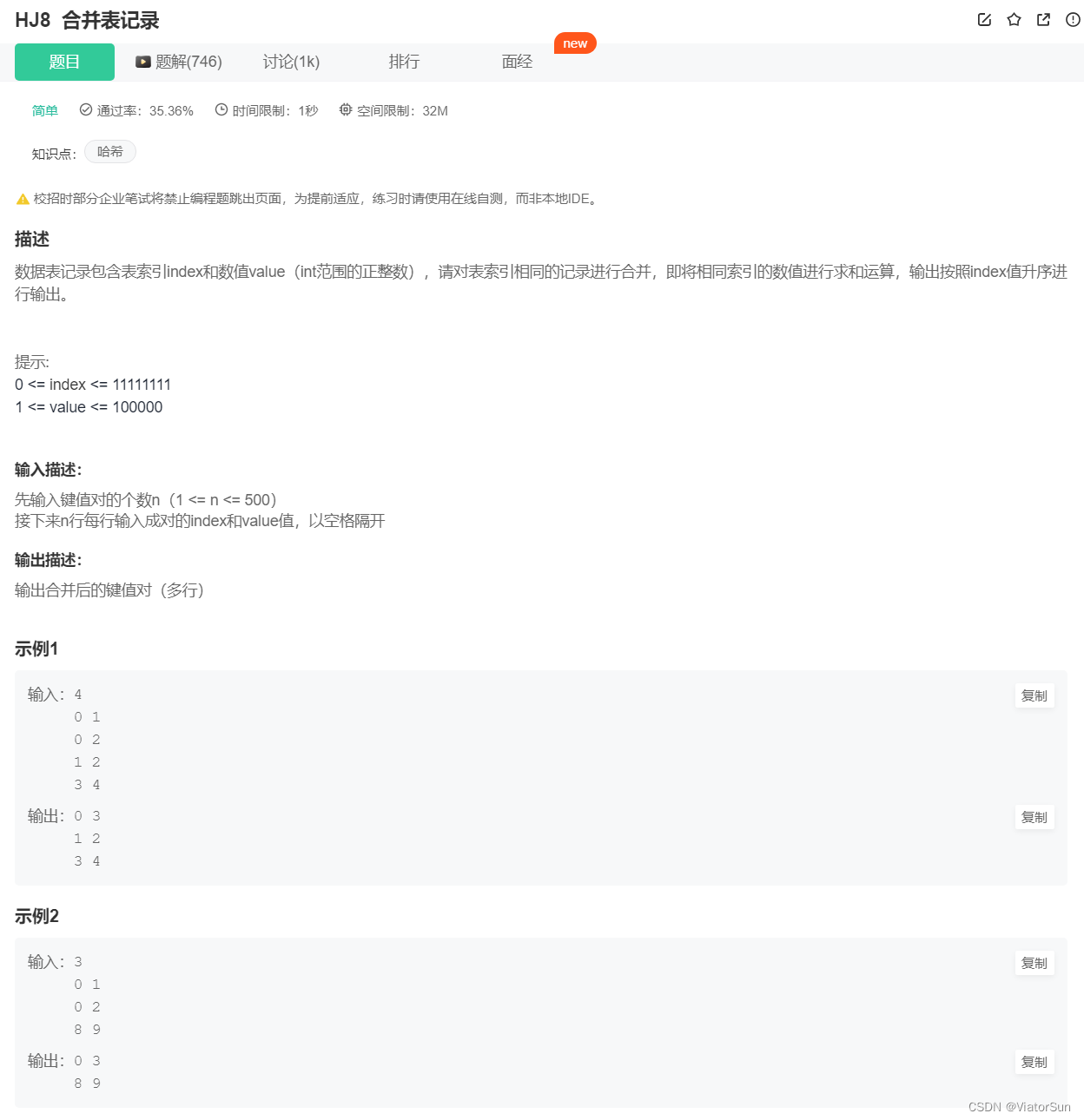
n = int(input())
dic = {}
# idea: 动态建构字典
for i in range(n):
line = input().split()
key = int(line[0])
value = int(line[1])
dic[key] = dic.get(key, 0) + value # 累积key所对应的value
for each in sorted(dic): # 最后的键值对按照升值排序
print(each, dic[each])
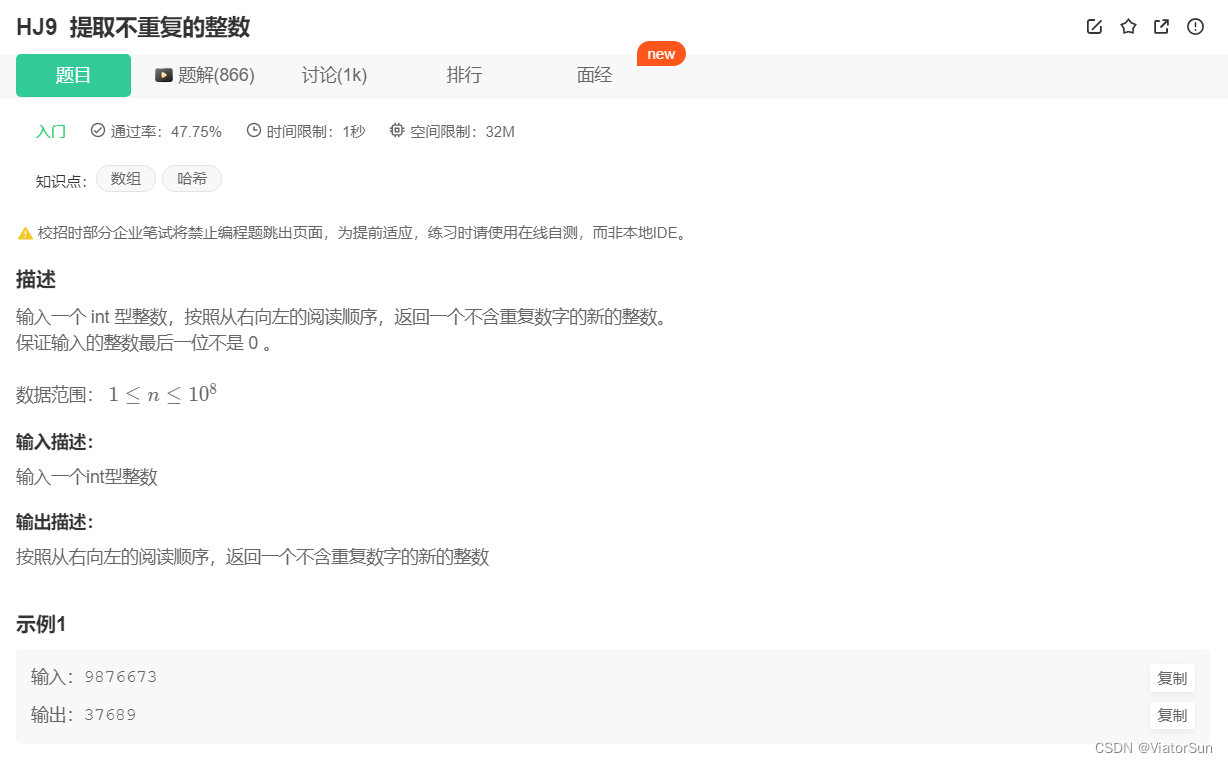
通过 print(i, end=“”) 将结果输出,且不换行
inp = input()
num = inp[::-1]
out = []
for i in num:
if i in out:
continue
else:
out.append(i)
print(i, end="")
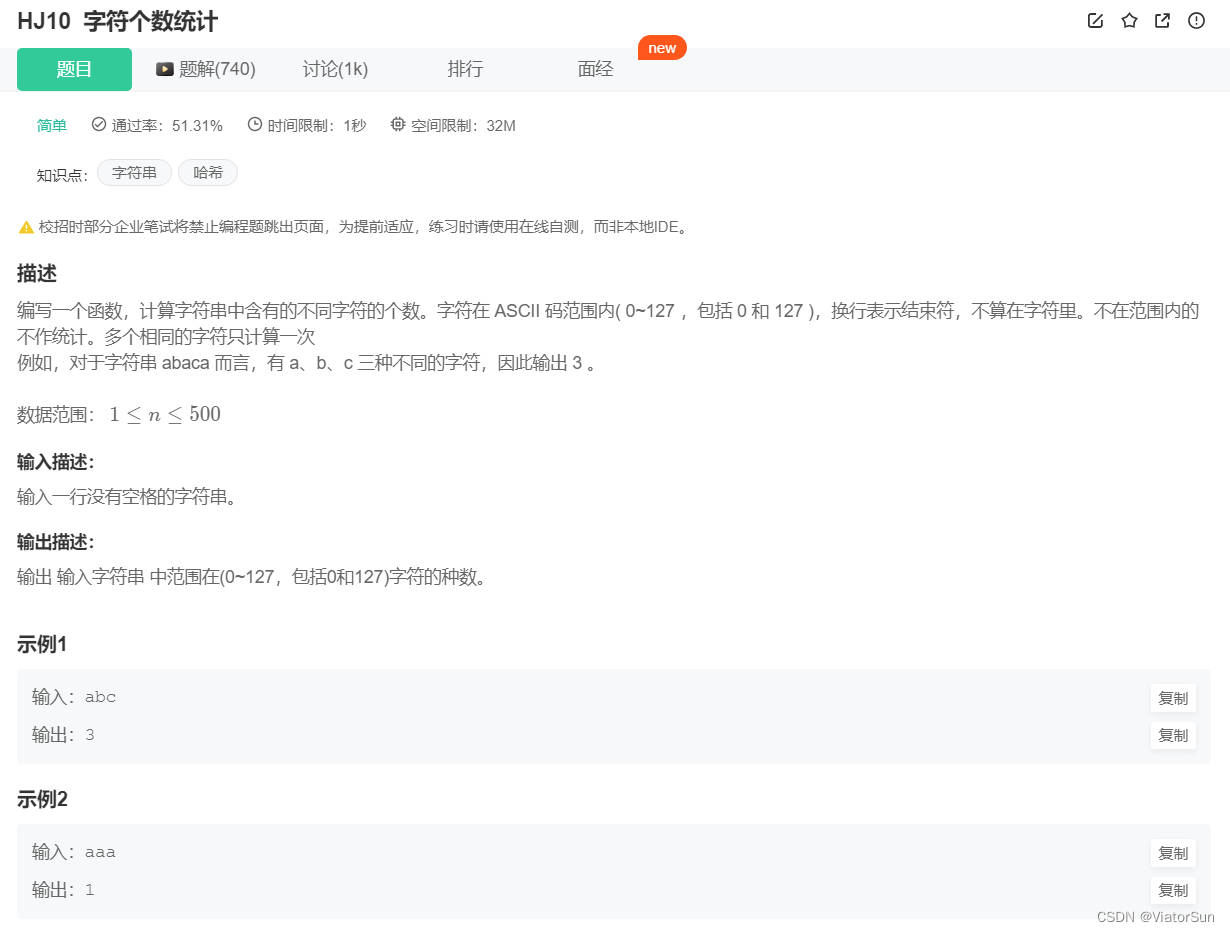
ord()函数是chr()函数(对于8位的ASCII字符串)或unichr()函数(对于Unicode对象)的配对函数,它以一个字符(长度为1的字符串)作为参数,返回对应的ASCII数值,或者Unicode数值,如果所给的Unicode字符超出了你的Python定义范围,则会引发一个TypeError的异常。
def count_character(str):
string = ''.join(set(str)) # 去重后以字符串的形式
count = 0 # 开始计数
for item in string:
if 0 <= ord(item) <= 127: # ASCII码范围要求
count += 1 # 计数
return count
str = input()
print(count_character(str))
偷懒的做法,直接替换掉 换行符,计算 set 集合数值
print(len(set(input().replace('\n','')))) # 方法二
print(len(set(map(lambda x: x, input().replace('\n',''))))) # 方法三
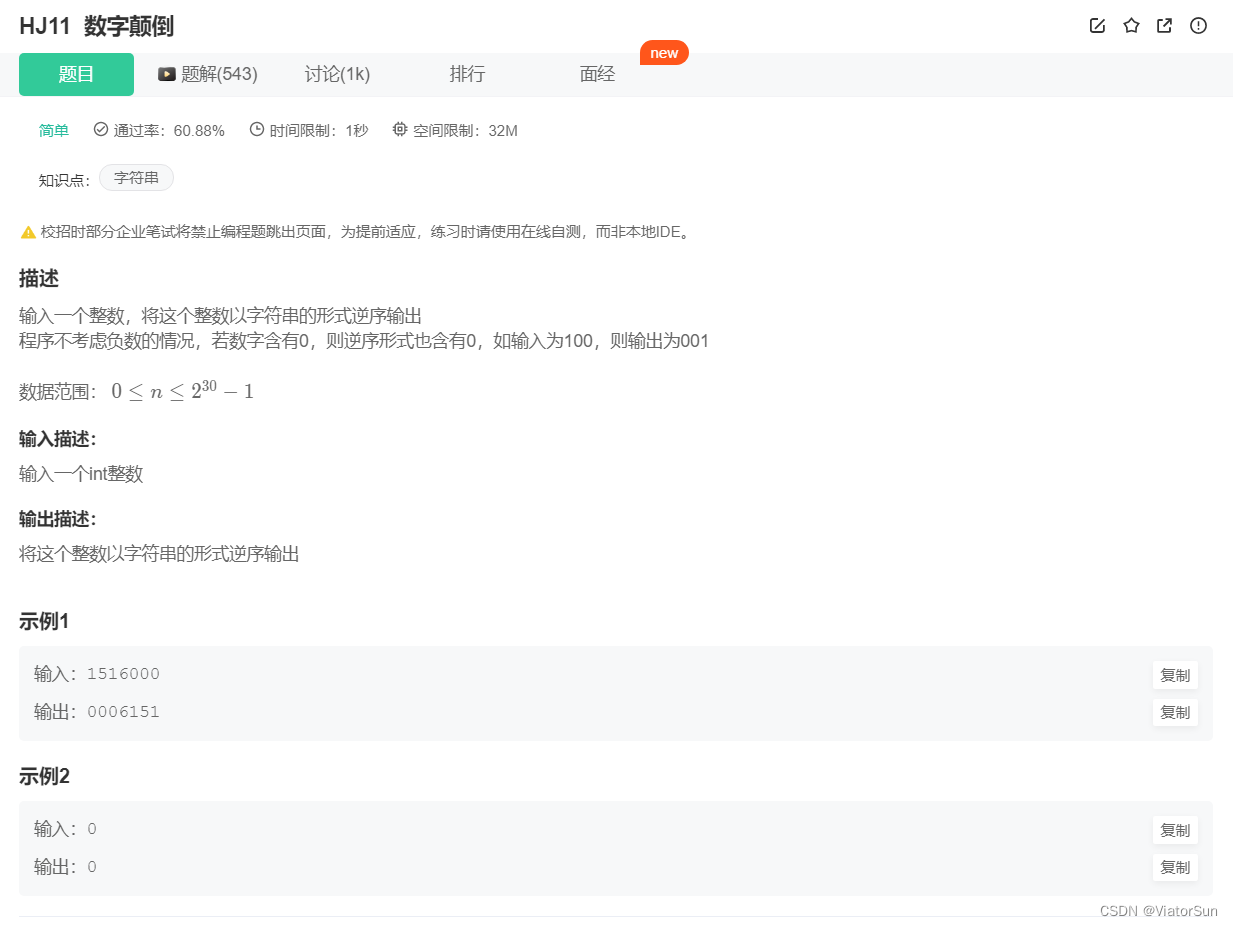
num = input()
out = num[::-1]
for i in range(len(out)):
print(out[i], end="")
# ------------------------------------ #
print(input()[::-1])
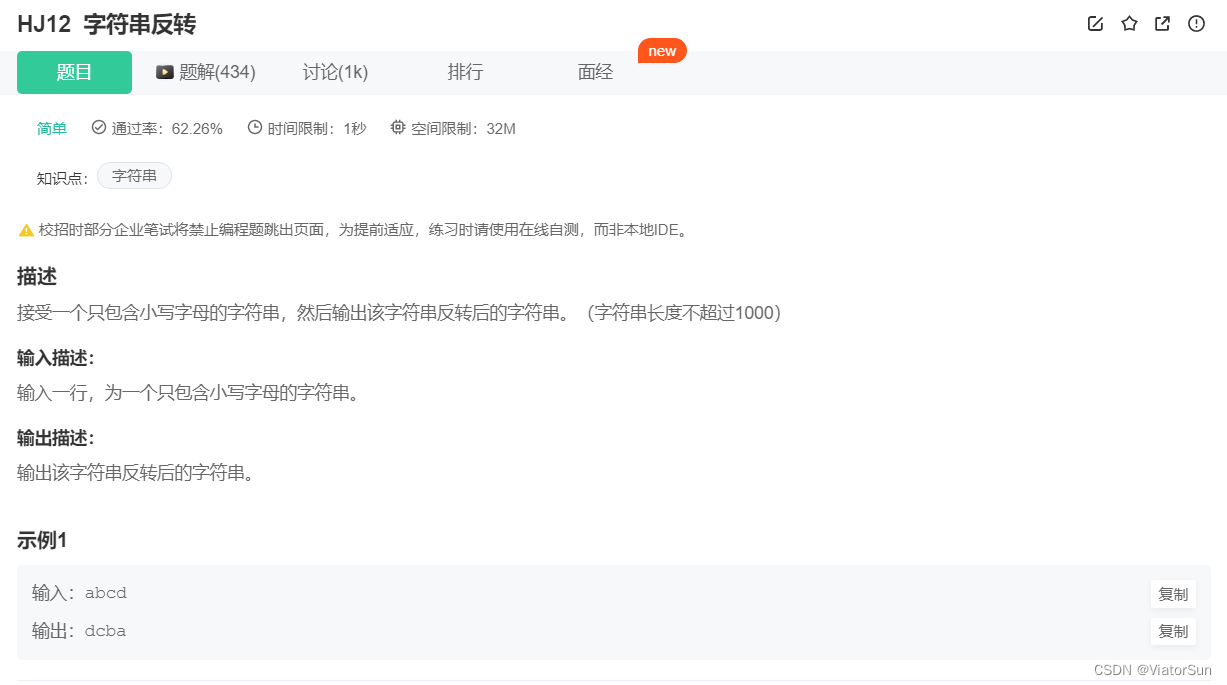
print(input()[::-1])
string = input()
lst = string.split()[::-1]
for i in lst:
print(i ,end=' ')
num=int(input())
stack=[]
for i in range(num):
stack.append(input())
print("\n".join(sorted(stack)))
num = input()
num_b = bin(int(num))
out = str(num_b).count("1")
print(out)
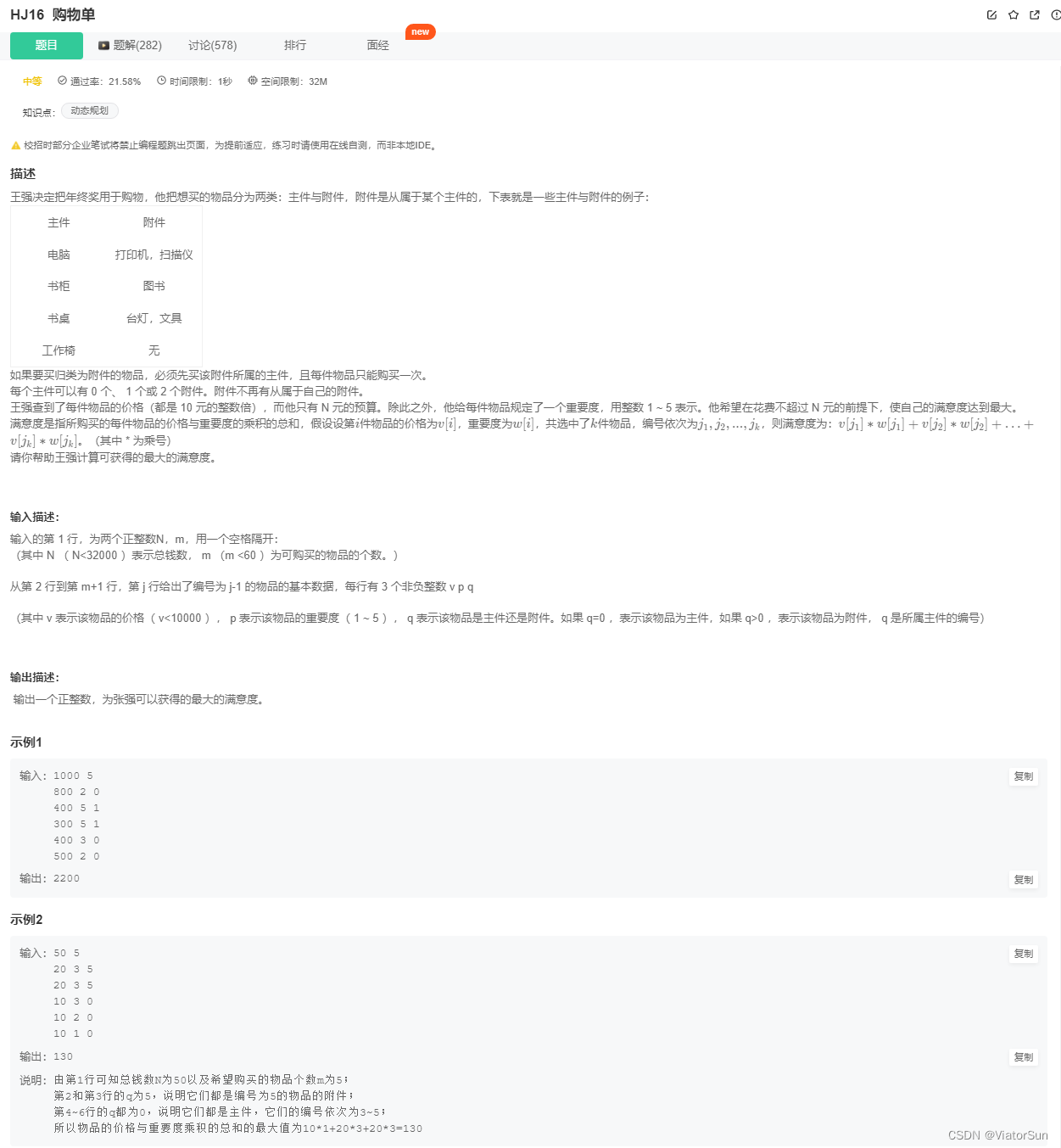
n, m = map(int,input().split())
primary, annex = {}, {}
for i in range(1,m+1):
x, y, z = map(int, input().split())
if z==0:
primary[i] = [x, y]
else:
if z in annex:
annex[z].append([x, y])
else:
annex[z] = [[x,y]]
dp = [0]*(n+1)
for key in primary:
w, v= [], []
w.append(primary[key][0])#1、主件
v.append(primary[key][0]*primary[key][1])
if key in annex:#存在附件
w.append(w[0]+annex[key][0][0])#2、主件+附件1
v.append(v[0]+annex[key][0][0]*annex[key][0][1])
if len(annex[key])>1:#附件个数为2
w.append(w[0]+annex[key][1][0])#3、主件+附件2
v.append(v[0]+annex[key][1][0]*annex[key][1][1])
w.append(w[0]+annex[key][0][0]+annex[key][1][0])#4、主件+附件1+附件2
v.append(v[0]+annex[key][0][0]*annex[key][0][1]+annex[key][1][0]*annex[key][1][1])
for j in range(n,-1,-10):#物品的价格是10的整数倍
for k in range(len(w)):
if j-w[k]>=0:
dp[j] = max(dp[j], dp[j-w[k]]+v[k])
print(dp[n])
需要注意使用 try-except
ping = input()
lst = ping.split(";")
coord = [0, 0]
for i in lst:
l = len(i)
if l >3 or l <= 1:
continue
a = i[0]
try:
if not 0 < len(i[1:]) < 3:
continue
b = int(i[1:])
if 0 <= b <= 99:
if a == 'A':
coord[0] -= b
elif a =='D':
coord[0] += b
elif a== 'W':
coord[1] += b
elif a== 'S':
coord[1] -= b
except:
continue
out = str(coord[0]) + ',' + str(coord[1])
print(out)
import re
A, B, C, D, E, errs, privates = 0, 0, 0, 0, 0, 0, 0
def getBin(string):
string_bin = ''
for i in string.split('.'):
string_bin += bin(int(i))[2:].rjust(8, '0')
return string_bin
try:
while True:
ip, mask = input().split('~')
mask_bin = getBin(mask)
if ip.split('.')[0] in ('0', '127'):
continue
elif mask in ('0.0.0.0', '255.255.255.255'):
errs += 1
continue
else:
if re.search('01', mask_bin):
errs += 1
continue
ip_bin = getBin(ip)
if re.search(r'\.\.', ip):
errs += 1
elif getBin('1.0.0.0') < ip_bin < getBin('126.255.255.255'):
A += 1
if getBin('10.0.0.0') < ip_bin < getBin('10.255.255.255'):
privates += 1
elif getBin('128.0.0.0') < ip_bin < getBin('191.255.255.255'):
B += 1
if getBin('172.16.0.0') < ip_bin < getBin('172.31.255.255'):
privates += 1
elif getBin('192.0.0.0') < ip_bin < getBin('223.255.255.255'):
C += 1
if getBin('192.168.0.0') < ip_bin < getBin('192.168.255.255'):
privates += 1
elif getBin('224.0.0.0') < ip_bin < getBin('239.255.255.255'):
D += 1
elif getBin('240.0.0.0') < ip_bin < getBin('255.255.255.255'):
E += 1
except (EOFError, ValueError):
pass
print(A, B, C, D, E, errs, privates)

lst = []
num = []
while True:
try:
s = input().split('\\')[-1]
data = s.split(' ')[0][-16:] + ' ' + s.split(' ')[1]
if data not in lst:
lst.append(data)
num.append(1)
else:
num[lst.index(data)] += 1
except:
break
for i in range(len(lst[-8:])):
print(lst[-8:][i], num[-8:][i])
描述2:至少满足四种其中三种, 通过计算满足条件的和从而判断是否符合条件;且其他符号,直接采用else计算即可!
def check(s):
if len(s) <= 8:
return 0
a, b, c, d = 0, 0, 0, 0
for item in s:
if ord('a') <= ord(item) <= ord('z'):
a = 1
elif ord('A') <= ord(item) <= ord('Z'):
b = 1
elif ord('0') <= ord(item) <= ord('9'):
c = 1
else:
d = 1
if a + b + c + d < 3:
return 0
for i in range(len(s)-3):
if len(s.split(s[i:i+3])) >= 3:
return 0
return 1
while True:
try:
print('OK' if check(input()) else 'NG')
except:
break
我有一个字符串input="maybe(thisis|thatwas)some((nice|ugly)(day|night)|(strange(weather|time)))"Ruby中解析该字符串的最佳方法是什么?我的意思是脚本应该能够像这样构建句子:maybethisissomeuglynightmaybethatwassomenicenightmaybethiswassomestrangetime等等,你明白了......我应该一个字符一个字符地读取字符串并构建一个带有堆栈的状态机来存储括号值以供以后计算,还是有更好的方法?也许为此目的准备了一个开箱即用的库?
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在使用ruby1.9解析以下带有MacRoman字符的csv文件#encoding:ISO-8859-1#csv_parse.csvName,main-dialogue"Marceu","Giveittohimóhe,hiswife."我做了以下解析。require'csv'input_string=File.read("../csv_parse.rb").force_encoding("ISO-8859-1").encode("UTF-8")#=>"Name,main-dialogue\r\n\"Marceu\",\"Giveittohim\x97he,hiswife.\"\
简而言之错误:NOTE:Gem::SourceIndex#add_specisdeprecated,useSpecification.add_spec.Itwillberemovedonorafter2011-11-01.Gem::SourceIndex#add_speccalledfrom/opt/local/lib/ruby/site_ruby/1.8/rubygems/source_index.rb:91./opt/local/lib/ruby/gems/1.8/gems/rails-2.3.8/lib/rails/gem_dependency.rb:275:in`==':und
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
system-view进入系统视图quit退到系统视图sysname交换机命名vlan20创建vlan(进入vlan20)displayvlan显示vlanundovlan20删除vlan20displayvlan20显示vlan里的端口20Interfacee1/0/24进入端口24portlink-typeaccessvlan20把当前端口放入vlan20undoporte1/0/10删除当前VLAN端口10displaycurrent-configuration显示当前配置02配置交换机支持TELNETinterfacevlan1进入VLAN1ipaddress192.168.3.100
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
1.在Python3中,下列关于数学运算结果正确的是:(B)a=10b=3print(a//b)print(a%b)print(a/b)A.3,3,3.3333...B.3,1,3.3333...C.3.3333...,3.3333...,3D.3.3333...,1,3.3333...解析: 在Python中,//表示地板除(向下取整),%表示取余,/表示除(Python2向下取整返回3)2.如下程序Python2会打印多少个数:(D)k=1000whilek>1: print(k)k=k/2A.1000 B.10C.11D.9解析: 按照题意每次循环K/2,直到K值小于等
我正在使用ruby2.1.0我有一个json文件。例如:test.json{"item":[{"apple":1},{"banana":2}]}用YAML.load加载这个文件安全吗?YAML.load(File.read('test.json'))我正在尝试加载一个json或yaml格式的文件。 最佳答案 YAML可以加载JSONYAML.load('{"something":"test","other":4}')=>{"something"=>"test","other"=>4}JSON将无法加载YAML。JSON.load("
我想用Nokogiri解析HTML页面。页面的一部分有一个表,它没有使用任何特定的ID。是否可以提取如下内容:Today,3,455,34Today,1,1300,3664Today,10,100000,3444,Yesterday,3454,5656,3Yesterday,3545,1000,10Yesterday,3411,36223,15来自这个HTML:TodayYesterdayQntySizeLengthLengthSizeQnty345534345456563113003664354510001010100000344434113622315