


# -*- coding:utf-8 -*-
import os
def create_data_list(root_path, is_val='val'):
txt_path = './yolov5_face_'+str(is_val)+'.txt'
img_root_path = os.path.join( os.path.join(root_path, 'images', is_val) )
with open(txt_path, 'w') as f:
for file_name in os.listdir(img_root_path):
if file_name.split('.')[-1]!= 'jpg':
print('文件名称有误 {}'.format(file_name))
img_path = os.path.join(img_root_path, file_name)
line = '{}\n'.format(img_path)
f.writelines(line)
### 图片和标签文件存储的根路径
root_path = ''
create_data_list(root_path, 'train')
create_data_list(root_path, 'val')
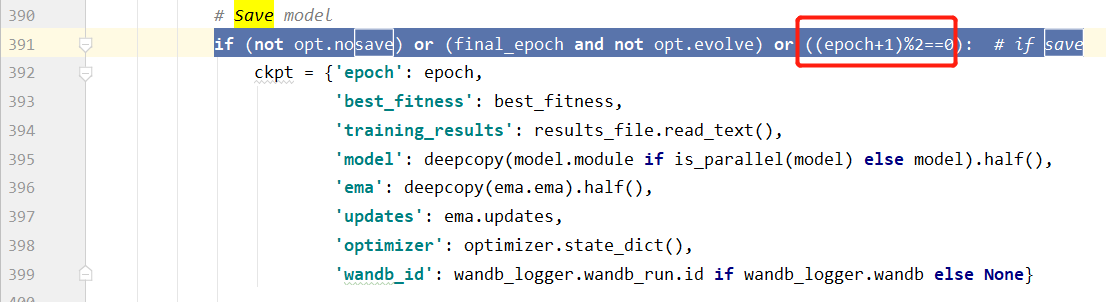
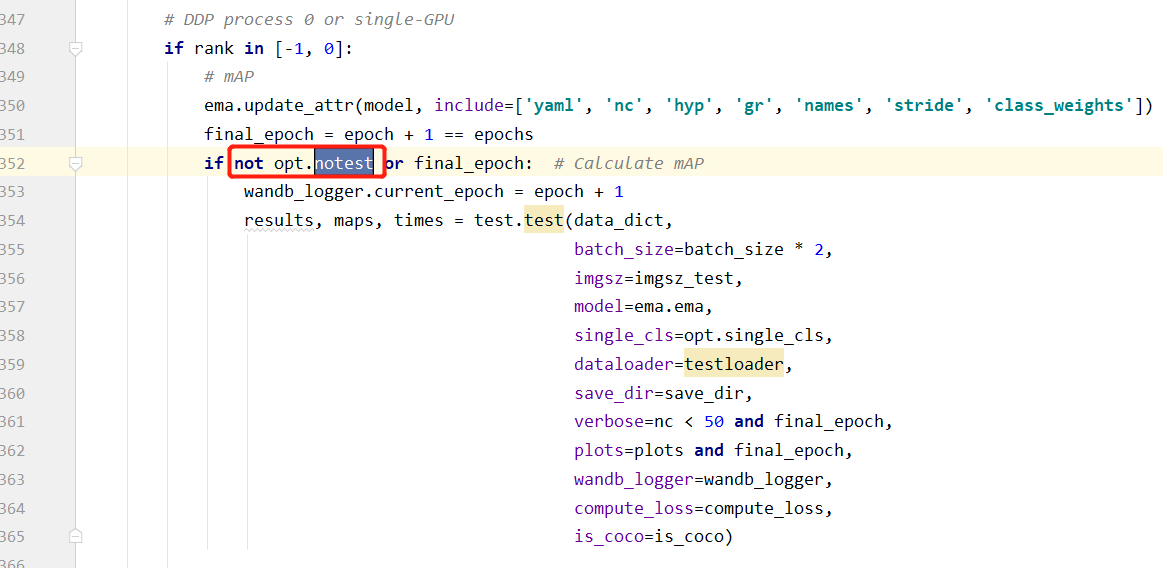

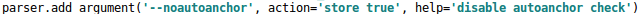
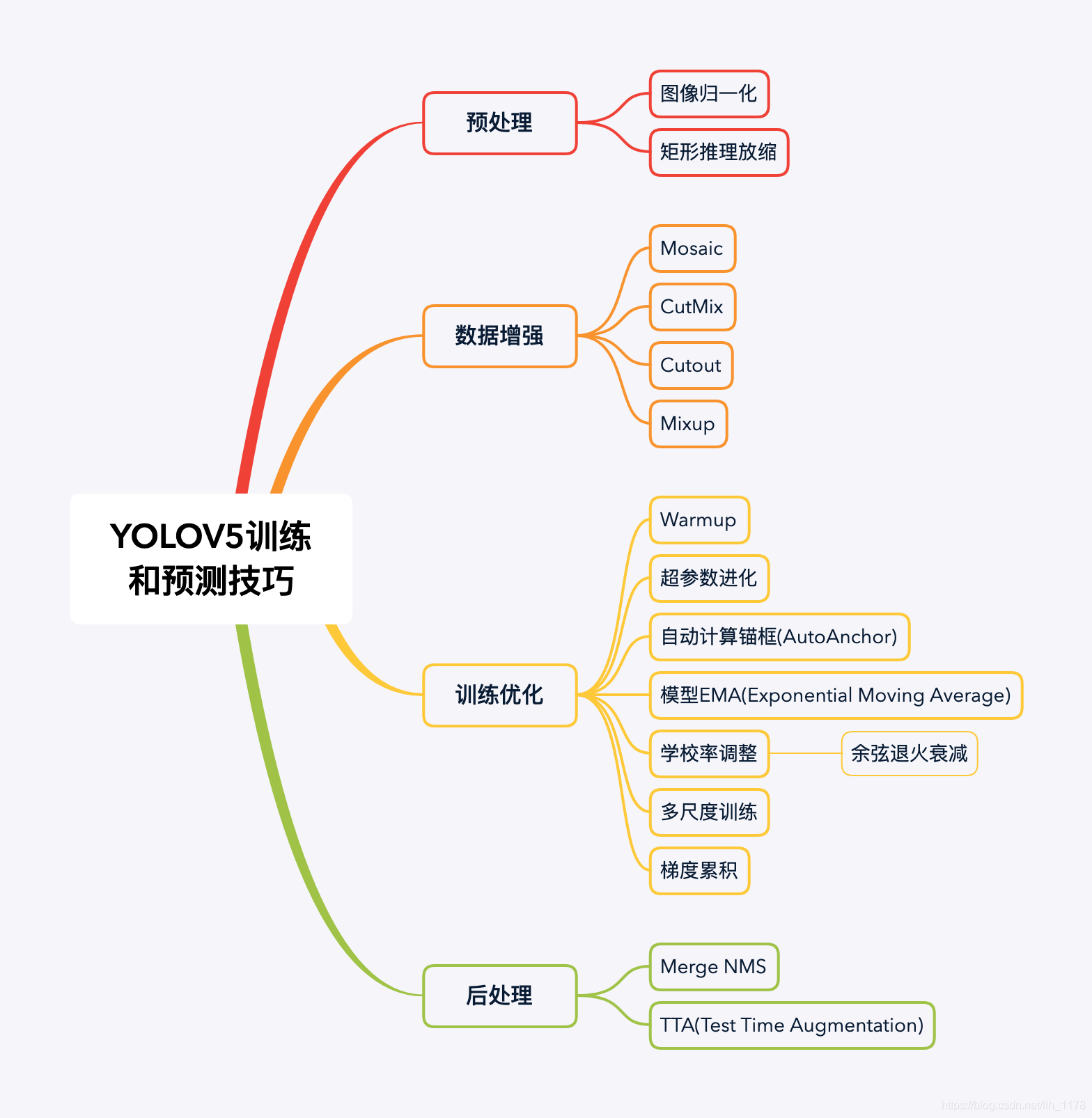
参考链接:https://blog.csdn.net/weixin_42638415/article/details/120799608
–hyp: 训练网络的一些超参数设置
–rect: 是否采用矩形训练
–resume: 指定你之前训练的网络模型,是否从最近的上一个模型开始训练。
–evolve:是否寻找最优参数
–bucket:gsutil bucket
–cache:是否对图片进行缓存,加快训练
–image-weights:测试过程中,图像的那些测试地方不太好,对这些不太好的地方加权重
–multi-scale:图片尺度变换
–single-cls:训练数据集是单类别还是多类别
–adam:是否采用adam
–sync-bn:分布式训练
–local_rank:DDP参数,请勿修改。
–workers: 多线程训练,设置最多多少个线程同时进行分布式的训练。个人理解,线程之间的交互也会耗时。
–entity :W&B entity
–exist-ok: 覆盖掉上一次的结果,不新建训练结果文件
–quad:在dataloader时采用什么样的方式读取我们的数据
–linear-lr:按照线性的方式去调整学习率
–label-smoothing: 对标签平滑,防止过拟合
–upload_dataset:Upload dataset as W&B artifact table
–bbox_interval:Set bounding-box image logging interval for W&B

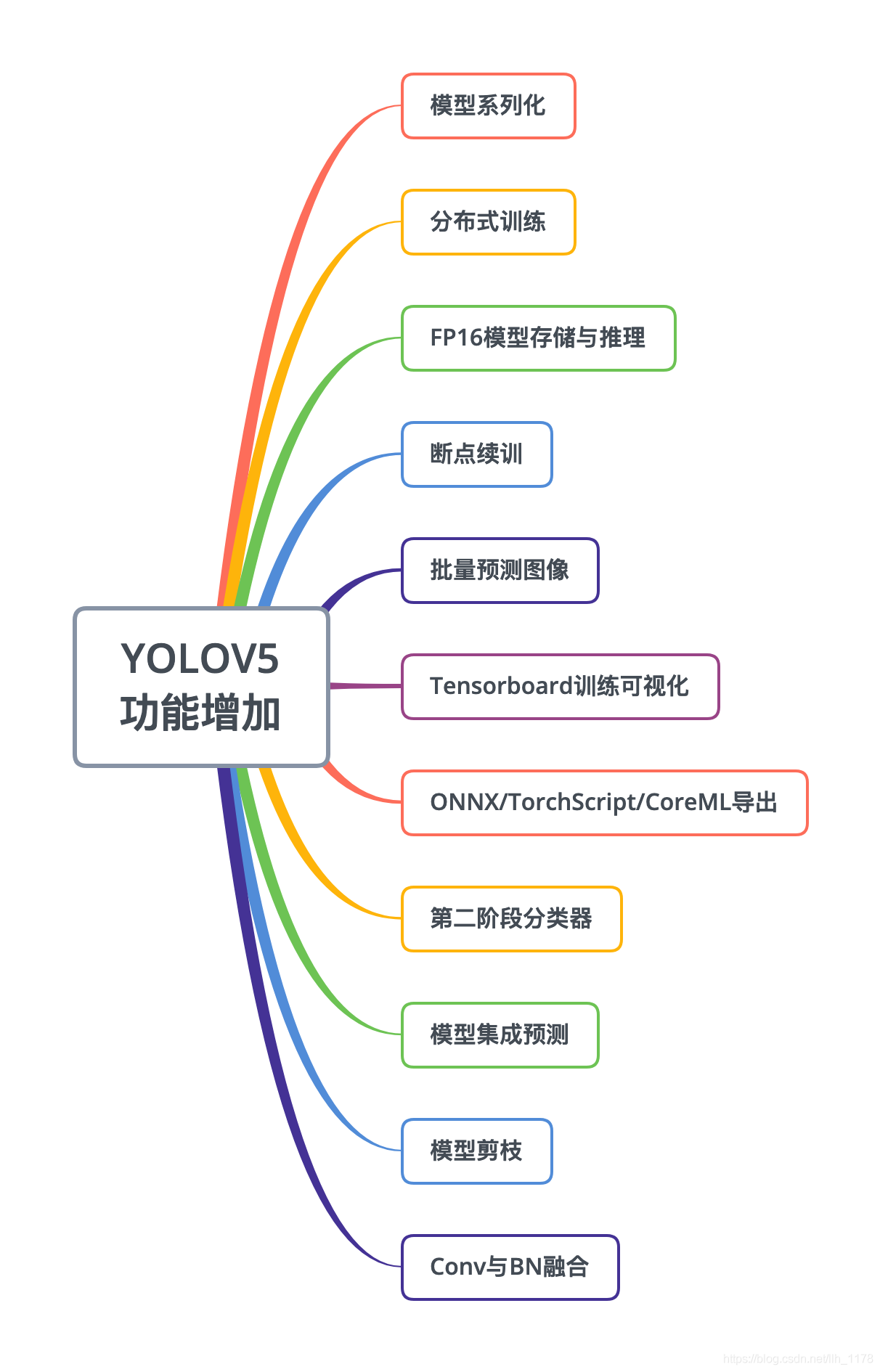
参考链接:https://blog.csdn.net/thy0000/article/details/125281995
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
为了将Cucumber用于命令行脚本,我按照提供的说明安装了arubagem。它在我的Gemfile中,我可以验证是否安装了正确的版本并且我已经包含了require'aruba/cucumber'在'features/env.rb'中为了确保它能正常工作,我写了以下场景:@announceScenario:Testingcucumber/arubaGivenablankslateThentheoutputfrom"ls-la"shouldcontain"drw"假设事情应该失败。它确实失败了,但失败的原因是错误的:@announceScenario:Testingcucumber/ar
exe应该在我打开页面时运行。异步进程需要运行。有什么方法可以在ruby中使用两个参数异步运行exe吗?我已经尝试过ruby命令-system()、exec()但它正在等待过程完成。我需要用参数启动exe,无需等待进程完成是否有任何rubygems会支持我的问题? 最佳答案 您可以使用Process.spawn和Process.wait2:pid=Process.spawn'your.exe','--option'#Later...pid,status=Process.wait2pid您的程序将作为解释器的子进程执行。除
我正在使用puppet为ruby程序提供一组常量。我需要提供一组主机名,我的程序将对其进行迭代。在我之前使用的bash脚本中,我只是将它作为一个puppet变量hosts=>"host1,host2"我将其提供给bash脚本作为HOSTS=显然这对ruby不太适用——我需要它的格式hosts=["host1","host2"]自从phosts和putsmy_array.inspect提供输出["host1","host2"]我希望使用其中之一。不幸的是,我终其一生都无法弄清楚如何让它发挥作用。我尝试了以下各项:我发现某处他们指出我需要在函数调用前放置“function_”……这
我有一些Ruby代码,如下所示:Something.createdo|x|x.foo=barend我想编写一个测试,它使用double代替block参数x,这样我就可以调用:x_double.should_receive(:foo).with("whatever").这可能吗? 最佳答案 specify'something'dox=doublex.should_receive(:foo=).with("whatever")Something.should_receive(:create).and_yield(x)#callthere
我正在为一个项目制作一个简单的shell,我希望像在Bash中一样解析参数字符串。foobar"helloworld"fooz应该变成:["foo","bar","helloworld","fooz"]等等。到目前为止,我一直在使用CSV::parse_line,将列分隔符设置为""和.compact输出。问题是我现在必须选择是要支持单引号还是双引号。CSV不支持超过一个分隔符。Python有一个名为shlex的模块:>>>shlex.split("Test'helloworld'foo")['Test','helloworld','foo']>>>shlex.split('Test"
我不确定传递给方法的对象的类型是否正确。我可能会将一个字符串传递给一个只能处理整数的函数。某种运行时保证怎么样?我看不到比以下更好的选择:defsomeFixNumMangler(input)raise"wrongtype:integerrequired"unlessinput.class==FixNumother_stuffend有更好的选择吗? 最佳答案 使用Kernel#Integer在使用之前转换输入的方法。当无法以任何合理的方式将输入转换为整数时,它将引发ArgumentError。defmy_method(number)
这是一道面试题,我没有答对,但还是很好奇怎么解。你有N个人的大家庭,分别是1,2,3,...,N岁。你想给你的大家庭拍张照片。所有的家庭成员都排成一排。“我是家里的friend,建议家庭成员安排如下:”1岁的家庭成员坐在这一排的最左边。每两个坐在一起的家庭成员的年龄相差不得超过2岁。输入:整数N,1≤N≤55。输出:摄影师可以拍摄的照片数量。示例->输入:4,输出:4符合条件的数组:[1,2,3,4][1,2,4,3][1,3,2,4][1,3,4,2]另一个例子:输入:5输出:6符合条件的数组:[1,2,3,4,5][1,2,3,5,4][1,2,4,3,5][1,2,4,5,3][
两者都可以defsetup(options={})options.reverse_merge:size=>25,:velocity=>10end和defsetup(options={}){:size=>25,:velocity=>10}.merge(options)end在方法的参数中分配默认值。问题是:哪个更好?您更愿意使用哪一个?在性能、代码可读性或其他方面有什么不同吗?编辑:我无意中添加了bang(!)...并不是要询问nobang方法与bang方法之间的区别 最佳答案 我倾向于使用reverse_merge方法:option