文章目录
rabbitmq属于有状态的服务,即每个服务上存储的内容都不一样,对于有状态的服务,k8s推荐我们使用StatefulSet控制器。
rabbitmq中的部分信息需要持久化,持久化内容使用nfs进行存储,并使用storageclass动态分配pv。
参考文章:K8S部署RabbitMQ集群 (镜像模式) - 部署笔记 - 腾讯云开发者社区-腾讯云 (tencent.com)
RabbitMQ 基础核心配置文件介绍丨慕课网教程 (imooc.com)
参考文章:[mystudy/大数据/k8s/8. 存储与配置.md · Zhang-HaoQi/Knowledge - 码云 - 开源中国 (gitee.com)](https://gitee.com/zhang-haoqi/knowledge/blob/develop/mystudy/大数据/k8s/8. 存储与配置.md#1-安装nfs)
需要先为NFS安装存储分配器,再创建NFS存储分配器。
# nfs-client-provisioner-authority.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: nfs-client-provisioner-runner
rules:
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["create", "update", "patch"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: run-nfs-client-provisioner
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
roleRef:
kind: ClusterRole
name: nfs-client-provisioner-runner
apiGroup: rbac.authorization.k8s.io
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
rules:
- apiGroups: [""]
resources: ["endpoints"]
verbs: ["get", "list", "watch", "create", "update", "patch"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
roleRef:
kind: Role
name: leader-locking-nfs-client-provisioner
apiGroup: rbac.authorization.k8s.io
下载NFS存储分配器:https://raw.githubusercontent.com/Kubernetes-incubator/external-storage/master/nfs-client/deploy/deployment.yaml
是一个yaml文件,可以浏览器打开直接复制
修改相关的卷信息 文件名:nfs-client-provisioner.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nfs-client-provisioner
labels:
app: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
spec:
replicas: 1
strategy:
type: Recreate
selector:
matchLabels:
app: nfs-client-provisioner
template:
metadata:
labels:
app: nfs-client-provisioner
spec:
serviceAccountName: nfs-client-provisioner
containers:
- name: nfs-client-provisioner
image: quay.io/external_storage/nfs-client-provisioner:latest
volumeMounts:
- name: nfs-client-root
mountPath: /persistentvolumes
env:
- name: PROVISIONER_NAME # 存储分配器的默认名称
value: fuseim.pri/ifs
- name: NFS_SERVER # NFS服务器地址
value: xx.xx.236.113
- name: NFS_PATH # NFS共享目录地址
value: /data/k8snfs
volumes:
- name: nfs-client-root
nfs:
server: xx.xx.236.113 # NFS服务器地址
path: /data/k8snfs # NFS共享目录
kubectl apply -f nfs-client-provisioner.yaml
查看创建的pod:
创建nfs-storage-class.yml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: rabbitmq-nfs-storage
namespace: rabbit-mq
provisioner: fuseim.pri/ifs
reclaimPolicy: Retain
allowVolumeExpansion: True
执行文件: kubectl apply -f nfs-storage-class.yml
查看状态: kubectl get storageclass

查看详情:kubectl describe storageclass nfs-storage-class.yml

StorageClass 创建完成后就可以创建 PVC 了。
---
apiVersion: v1
kind: Service
metadata:
name: rabbitmq-management
namespace: rabbit-mq
labels:
app: rabbitmq
spec:
ports:
- port: 15672
name: http
selector:
app: rabbitmq
type: NodePort # 外界可以访问
---
apiVersion: v1
kind: Service
metadata:
name: rabbitmq
namespace: rabbit-mq
labels:
app: rabbitmq
spec:
ports:
- port: 5672
name: amqp
- port: 4369
name: epmd
- port: 25672
name: rabbitmq-dist
clusterIP: None # 无头service,外界不可以访问,只能由pod内部访问
selector:
app: rabbitmq
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
namespace: rabbit-mq
name: rabbitmq
spec:
serviceName: "rabbitmq"
replicas: 1 # 设置节点数量为1(磁盘有限)
selector:
matchLabels:
app: rabbitmq
template:
metadata:
labels:
app: rabbitmq
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: "app"
operator: In
values:
- rabbitmq
topologyKey: "kubernetes.io/hostname"
containers:
- name: rabbitmq
image: rabbitmq:3.7-rc-management
lifecycle:
postStart:
exec:
command:
- /bin/sh
- -c
- >
if [ -z "$(grep rabbitmq /etc/resolv.conf)" ]; then
sed "s/^search \([^ ]\+\)/search rabbitmq.\1 \1/" /etc/resolv.conf > /etc/resolv.conf.new;
cat /etc/resolv.conf.new > /etc/resolv.conf;
rm /etc/resolv.conf.new;
fi;
until rabbitmqctl node_health_check; do sleep 1; done;
if [ -z "$(rabbitmqctl cluster_status | grep rabbitmq-0)" ]; then
touch /gotit
rabbitmqctl stop_app;
rabbitmqctl reset;
rabbitmqctl join_cluster rabbit@rabbitmq-0;
rabbitmqctl start_app;
else
touch /notget
fi;
env:
- name: MY_POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: RABBITMQ_ERLANG_COOKIE
value: "YZSDHWMFSMKEMBDHSGGZ"
- name: RABBITMQ_NODENAME
value: "rabbit@$(MY_POD_NAME)"
ports:
- name: http
protocol: TCP
containerPort: 15672
- name: amqp
protocol: TCP
containerPort: 5672
livenessProbe:
tcpSocket:
port: amqp
initialDelaySeconds: 5
timeoutSeconds: 5
periodSeconds: 10
readinessProbe:
tcpSocket:
port: amqp
initialDelaySeconds: 15
timeoutSeconds: 5
periodSeconds: 20
volumeMounts:
- name: rabbitmq-data
mountPath: /var/lib/rabbitmq
volumeClaimTemplates:
- metadata:
name: rabbitmq-data
annotations:
volume.beta.kubernetes.io/storage-class: "rabbitmq-nfs-storage"
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 10Gi
应用yaml:kubectl apply-f rabbitmq.yaml -n rabbit-mq

控制台对外暴露的端口是31719

访问控制台:有一个mq节点。因为空间有限,因此只设置了一个节点。

查看nfs存储的配置文件:

进入服务:kubectl exec -it rabbitmq-0 -n rabbit-mq /bin/bash
虚拟主机操作vhost:
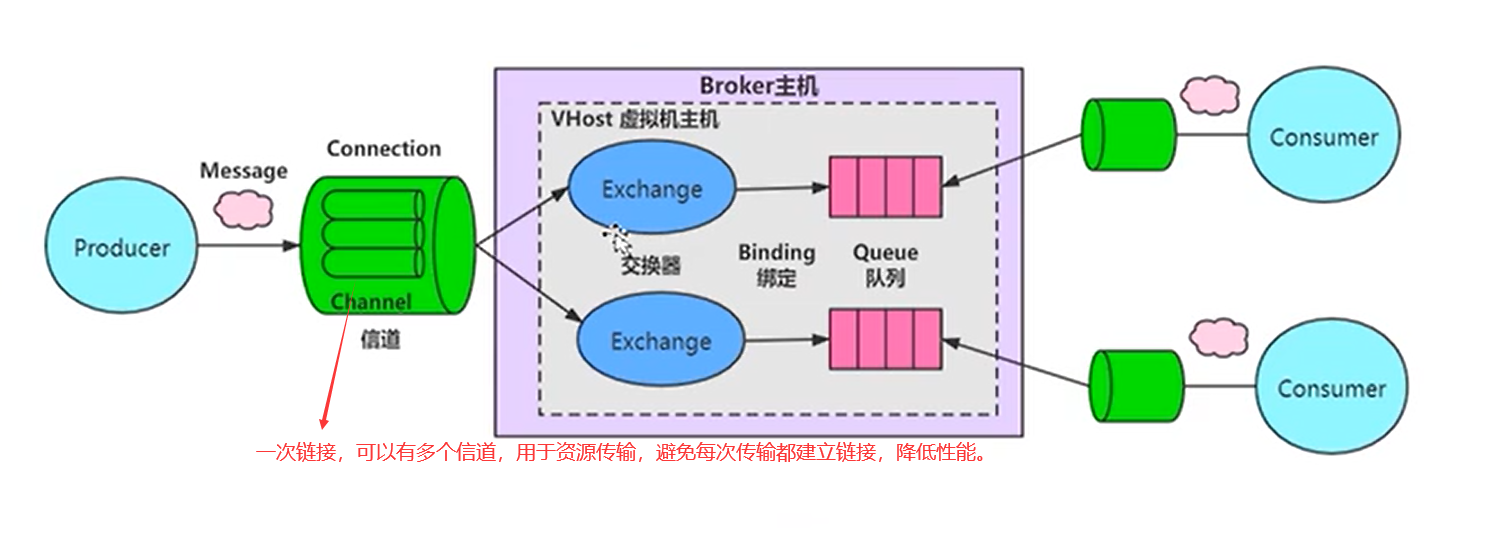
vhost 是 AMQP 概念的基础,客户端在连接的时候必须制定一个 vhost。RabbitMQ 默认创建的 vhost 为“/”,
vhost类似服务中的一台虚拟主机,提供逻辑隔离,不同的业务使用mq时最好创建不同的vhost,对业务进行归类划分
查看虚拟主机vhost:rabbitmqctl list_vhosts
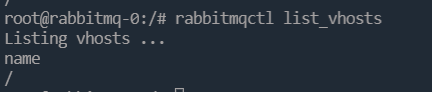
创建虚拟主机vhost:rabbitmqctl add_vhost compile-code
删除虚拟主机vhost:rabbitmqctl delete_vhost {vhost}
删除一个 vhost 同时也会删除其下所有的队列、交换器、绑定关系、用户权限、参数和策略等信息
查看主机是否使用了 RabbitMQ 的 trace 功能 rabbitmqctl list_vhosts name tracing
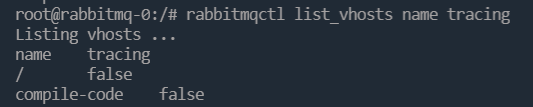
在 RabbitMQ 中,权限控制则是以 vhost 为单位的。当创建一个用户时,用户通常会被指派给至少一个 vhost,并且只能访问被指派的 vhost 内的队列,交换器和绑定关系等。
rabbitmqctl set_permissions [-p vhost] {user} {conf}{write}{read}

可配置指的是队列和交换器的创建及删除之类的操作;可写指的是发布消息;可读指与消息有关的操作,包括读取消息及清空整个队列等。
赋予用户权限
查看用户:rabbitmqctl list_users

创建用户:rabbitmqctl add_user coder train@coder
创建coder用户并赋予compile-coding所有权限: rabbitmqctl set_permissions -p compile-code coder ".*" ".*" ".*"
清除权限:rabbitmqctl clear_permissions -p compile-code coder
显示宿主机权限:rabbitmqctl list_permissions -p compile-code

显示用户权限:rabbitmqctl list_user_permissions coder

使用coder用户登录web控制台,发现登录不进去。原因:没有给用户赋予角色
用户的角色分为 5 种类型。

设置角色类型为management:rabbitmqctl set_user_tags coder management
 什么都没有
什么都没有
设置角色类型为monitoring:rabbitmqctl set_user_tags coder monitoring
经过测试,management,poliymaker,monitoring能进去web页面,但是什么内容也没有,none和administartor登录不进去。
我们使用的是StatefulSet控制器创建的无头的rabbitmq服务,服务地址是不暴露给外界的,只能在pod中访问到rabbitmq服务。这样很不利于我们开发测试。
查看服务信息

kubectl expose service rabbitmq -n rabbit-mq --type=LoadBalancer --name=rabbitmq-external-lb

此时就可以进行链接测试,如果不负载均衡到外网,mq服务是一直链接不上的。
<!--消息队列-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
# spring配置
spring:
rabbitmq:
host: XX.XX.91.15
port: 32116
username: coder
password: train@coder
virtual-host: compile-code
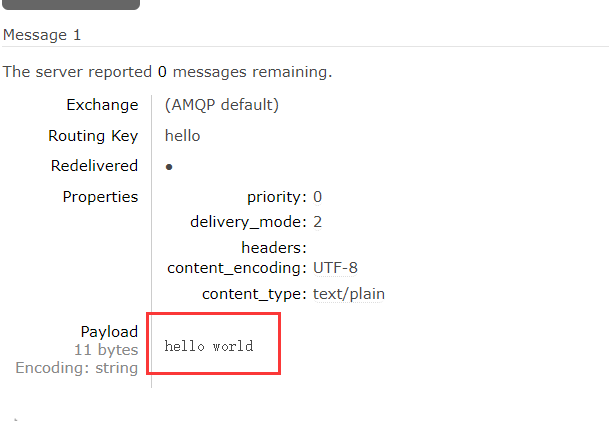
我们往key为hello的交换机中放一条hello world的消息。
注意:需要先创建交换机和队列。
交换机
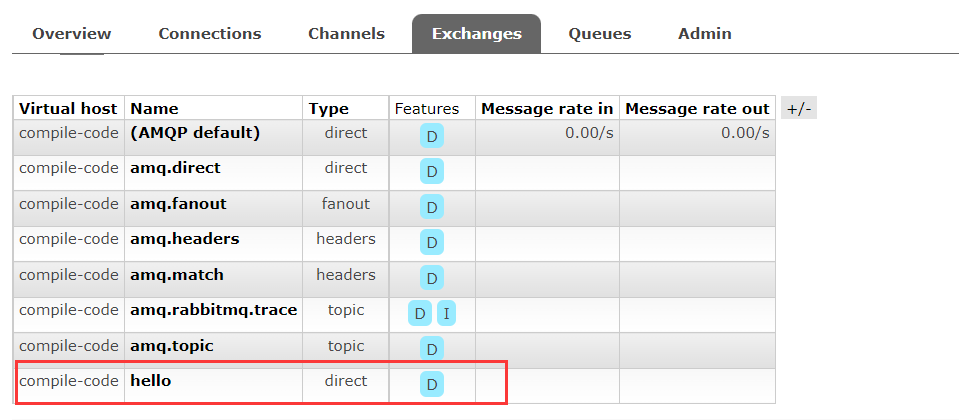
队列:注意,要与交换机绑定

@RunWith(SpringJUnit4ClassRunner.class)
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
public class MqTest {
@Autowired
private RabbitTemplate rabbitTemplate;
@Test
public void testHello(){
// System.out.println(123);
System.out.println(rabbitTemplate);
rabbitTemplate.convertAndSend("hello","hello world");
}
}
springboot配置文件:(112条消息) springboot整合rabbitmq的配置文件详解_xiaoweiwei99的博客-CSDN博客_rabbitmq配置springboot
创建枚举,列取需要的交换机,队列,路由key
@Getter
public enum CompileCodeEnum {
/**
* 在线编程
*/
PYTHON_CODE("compile.python.direct", "compile.python", "compile.python"),
R_CODE("compile.r.direct", "compile.r", "compile.r"),
SCALA_CODE("compile.scala.direct", "compile.scala", "compile.scala");
/**
* 交换名称
*/
private String exchange;
/**
* 队列名称
*/
private final String name;
/**
* 路由键
*/
private String routeKey;
CompileCodeEnum(String exchange,String name,String routeKey) {
this.exchange = exchange;
this.name = name;
this.routeKey = routeKey;
}
}
创建交换机,创建队列,交换机通过routingkey与队列绑定
@Configuration
public class CompileCodeConfig {
//springboot 会为我们自动初始化这个CachingConnectionFactory
@Autowired
private CachingConnectionFactory connectionFactory;
@Bean
public DirectExchange examComputedExchange() {
// Map<String, Object> arguments = new HashMap<>();
// //设置自定义交换机的类型。
// arguments.put("x-delayed-type", "direct");
//1.交换机名称
//2.交换机的类型
//3.是否需要持久化
//4.是否需要自动删除
//5.其他参数
return ExchangeBuilder.directExchange(CompileCodeEnum.PYTHON_CODE.getExchange()).durable(true).build();
}
@Bean
public Queue examComputedQueue() {
return QueueBuilder
.durable(CompileCodeEnum.PYTHON_CODE.getName())
.build();
}
@Bean
public Binding bindingExamComputedQueueToExchange() {
return BindingBuilder
.bind(examComputedQueue())
.to(examComputedExchange())
.with(CompileCodeEnum.PYTHON_CODE.getRouteKey());
}
}
消息发送到交换机,发消息需要指定交换机和routingkey,说明消息进入哪个队列
@Component
@Slf4j
public class CompileCodeSender {
@Autowired
private RabbitTemplate rabbitTemplate;
public void sendMessage(Long recordId) {
rabbitTemplate.convertAndSend(CompileCodeEnum.PYTHON_CODE.getExchange(), CompileCodeEnum.PYTHON_CODE.getRouteKey(), recordId);
}
}
消费者选择队列进行监听,消费队列中的消息
@Component
@Slf4j
public class CompileCodeCustomer {
@RabbitListener(queues = "compile.python")
public void handleExamProcessComputed(Long recordId) throws InterruptedException {
log.info("进入考试消费队列, id:{}", recordId);
Thread.sleep(10000);
}
}
测试
消费:每条消费相差10s消费

问题
消费者一次只能消费一条消息,效率比较低,希望能够消费多条
创建消费工厂:在CompileCodeConfig中配置
@Autowired
private CachingConnectionFactory connectionFactory;
@Bean
public SimpleRabbitListenerContainerFactory simpleRabbitListenerContainerFactory(){
SimpleRabbitListenerContainerFactory listenerContainerFactory = new SimpleRabbitListenerContainerFactory();
listenerContainerFactory.setConnectionFactory(connectionFactory);
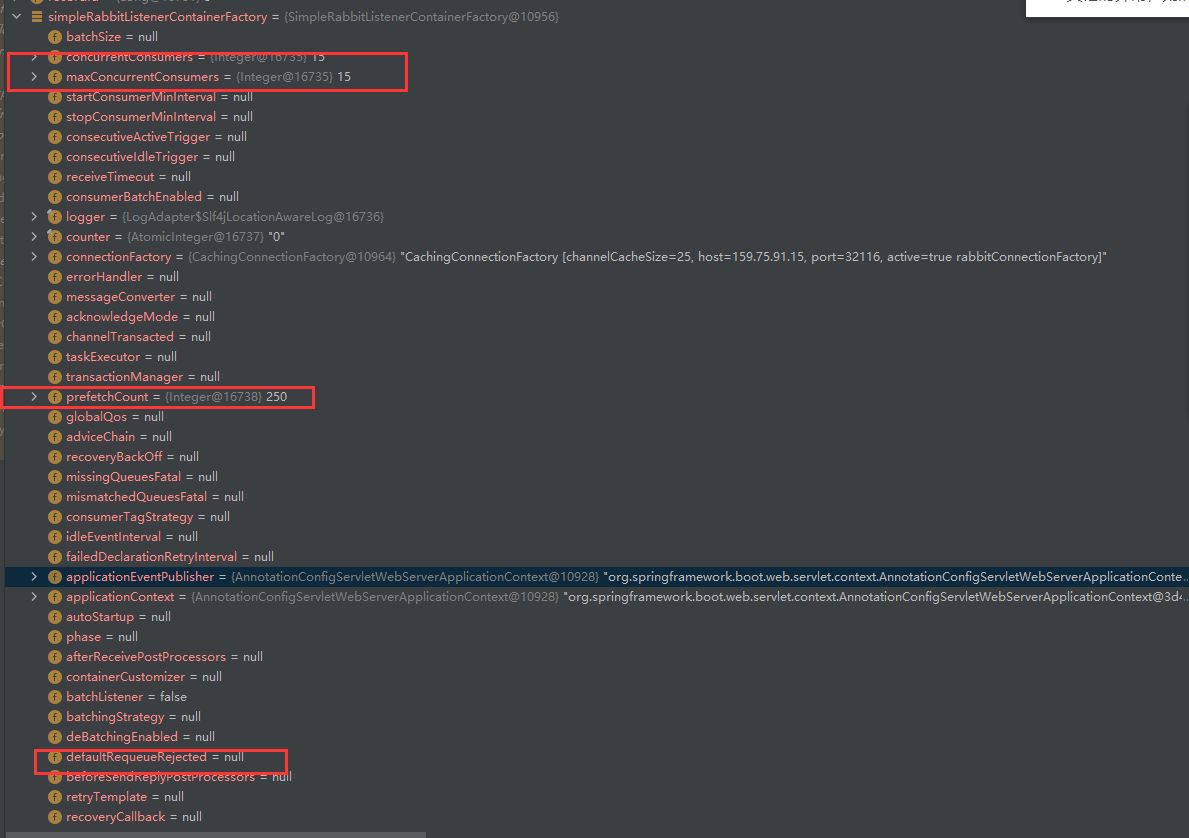
listenerContainerFactory.setConcurrentConsumers(15); //并发消费者数量
listenerContainerFactory.setMaxConcurrentConsumers(15);//最大的并发消费者数量
listenerContainerFactory.setPrefetchCount(10);//预处理消息个数 默认轮询发给各个消费者,但是可能会造成有的消费者任务繁重,来不及消费,而有的消费者可能处理较快,设置prefetchCount,允许限制信道上的消费者所能保持的最大未确认消息的数量,如果达到上限,则不再向此消费者发送。直到消费者消费了消息后,才继续分配。
// listenerContainerFactory.setAcknowledgeMode(AcknowledgeMode.MANUAL);//开启消息确认机制
return listenerContainerFactory;
}
在消费者的rabbitmqlistener设置工厂
@RabbitListener(queues = "compile.python", containerFactory = "simpleRabbitListenerContainerFactory")
public void handleExamProcessComputed(Long recordId) throws InterruptedException {
log.info("进入考试消费队列, id:{}", recordId);
Thread.sleep(10000);
}
结果:同时消费多条消息

还可以设置工厂
/**
* 个人理解为SimpleMessageListenerContainer就是一个消费者的容器配置类
* @return
*/
@Bean(name="simpleMessageListenerContainer")
public SimpleMessageListenerContainer productMessageListenerContainerFactory(){
SimpleMessageListenerContainer listenerContainer = new SimpleMessageListenerContainer();
listenerContainer.setConnectionFactory(connectionFactory);
listenerContainerFactory.setAcknowledgeMode(AcknowledgeMode.MANUAL);//设置为手动确认,在yaml配置后,初始化bean时默认的自动确认会覆盖掉yaml中的配置,收到消息时,会先自动确认一次,再手动确认。手动确认时,此时chanel已经关闭,会出现错误日志。
listenerContainer.setConcurrentConsumers(10);
listenerContainer.setMaxConcurrentConsumers(20);
listenerContainer.setAcknowledgeMode(AcknowledgeMode.MANUAL);
listenerContainer.setQueues(productQueue());
listenerContainer.setMessageListener(productConsumerListener);//这里设置了消息的消费者
listenerContainer.setPrefetchCount(5);
return listenerContainer;
}
@Component
@Slf4j
public class CompileCodeSender {
@Autowired
private RabbitTemplate rabbitTemplate;
public void sendMessage(Long recordId) {
rabbitTemplate.convertAndSend(CompileCodeEnum.PYTHON_CODE.getExchange(), CompileCodeEnum.PYTHON_CODE.getRouteKey(), recordId, new MessagePostProcessor() {
@Override
public Message postProcessMessage(Message message) throws AmqpException {
String content = new String(message.getBody());
System.out.println("消息内容:"+content);
MessageProperties messageProperties = message.getMessageProperties();
//设置持久化
messageProperties.setDeliveryMode(MessageProperties.DEFAULT_DELIVERY_MODE);
//优先级
messageProperties.setPriority(2);
//过期时间,默认设置为一天
final int expireTime =3600000;
messageProperties.setExpiration(String.valueOf(expireTime));
return message;
}
});
}
}

生产者发送消息到Broker(交换机)
生产者到 Broker有一个ConfirmCallback确认模式,当消息被Broker接收到就会触发ConfirmCallback回调,因此,通过此回调函数就可以知道有没有到达Broker。
Broker上的交换机是否成功将消息投放到队列
消息从交换机到 队列 投递失败有一个ReturnCallback回退模式。
注意:在RedisTemplate中可以通过setMandatory(boolean mandatory)方法或者在yml配置文件中通过template.mandatory: true来配置当消息没能路由到指定队列时消息是重回生产者还是丢弃,当参数mandatory=false表示消息会被丢弃,当mandatory=true消息会返回给生产者,返回的消息可以从ReturnCallback回调中获取。
使用这两个消息回调,还需要在application.yaml中配置是否开启回调:
publisher-confirm-type: 表示确认消息的类型,分别有none、correlated、simple这三种类型。
publisher-returns: true ,true表示开启失败回调,开启后当消息无法路由到指定队列时会触发ReturnCallback回调。
yaml
# spring配置
spring:
rabbitmq:
host: xx.xx.91.15
port: 32116
username: coder
password: train@coder
virtual-host: compile-code
publisher-confirm-type: correlated # ConfirmCalllBack回调
publisher-returns: true # ReturnCallback回调
template:
mandatory: true
config
@Component
@Slf4j
public class CompileCodeCallBack implements RabbitTemplate.ConfirmCallback, RabbitTemplate.ReturnsCallback {
@Autowired
private RabbitTemplate rabbitTemplate;
//将创建的消息接收的回调对象添加到rabbitTemplate中。
@PostConstruct
public void init() {
rabbitTemplate.setConfirmCallback(this);
//设置当消息灭有路由到指定队列时的处理方案。 //true:重回生产者 //false:丢失(默认) 返回的消息可以从ReturnCallback回调中获取
rabbitTemplate.setMandatory(true);
rabbitTemplate.setReturnsCallback(this);
}
/**
* 交换机确定是否收到消息的回调方法
* 1.发消息 交换机成功接受到了 回调
* 1.1CorrelationData保存回调消息的ID及相关信息
* 1.2交换机收到消息 ack:true
* 1.3cause 失败的原因 cause:null
* 2.发消息 交换机没有成功接收 回调
* 2.1CorrelationData保存回调消息的ID及相关信息
* 2.2交换机收到消息 ack:false
* 2.3 cause:失败的原因
*/
//消息未到达交换机
@Override
public void confirm(CorrelationData correlationData, boolean ack, String cause) {
Message message = correlationData.getReturned().getMessage();
try {
System.out.println(new String(message.getBody(),"utf-8"));
} catch (UnsupportedEncodingException e) {
throw new RuntimeException(e);
}
System.out.println(correlationData);
String id = correlationData == null ? "" : correlationData.getId();
if (ack) {
log.info("交换机已经收到 id 为:{}的消息", id);
} else {
log.info("交换机还未收到 id 为:{}消息,由于原因:{}", id, cause);
}
}
//消息到达交换机,但是没有对应的队列。
@Override
public void returnedMessage(ReturnedMessage returned) {
Message message = returned.getMessage();
String replyText = returned.getReplyText();
String routingKey = returned.getRoutingKey();
String exchange = returned.getExchange();
log.error(" 消 息 {}, 被 交 换 机 {} 退 回 , 退 回 原 因 :{}, 路 由 key:{}", new
String(message.getBody()), exchange, replyText, routingKey);
}
}
消费者在订阅队列时,可以指定 autoAck 参数
rabbimq消息重新入队条件
队列中的消息分成了两个部分:一部分是等待投递给消费者的消息;一部分是已经投递给消费者,但是还没有收到消费者确认信号的消息。
yaml配置
自动确认:acknowledge=“none” :当消息一旦被Consumer接收到,则自动确认收到,并将相应 message 从 RabbitMQ 的消息缓存中移除。如果代码执行过程中出现异常,会造成消息丢失
手动确认:acknowledge=“manual” :设置了手动确认方式,则需要在业务处理成功后,调用channel.basicAck(),手动签收,如果出现异常,则调用channel.basicNack()方法,让其自动重新发送消息。
根据异常情况确认:acknowledge=“auto”:如果代码在执行过程中出现异常,则自动提交。
spring:
rabbitmq:
host: xx.xx.91.15
port: 32116
username: coder
password: train@coder
virtual-host: compile-code
publisher-confirm-type: correlated
publisher-returns: true
template:
mandatory: true
listener:
simple: # 容器类型 简单模式
acknowledge-mode: manual # 表示消息确认方式,其有三种配置方式,分别是none、manual和auto;默认auto manual为手动
direct: #
acknowledge-mode: manual
消费者配置
channel basicAck(long deliveryTag, boolean multiple);
deliveryTag:该消息的index
multiple:是否批量.true:将一次性ack所有小于deliveryTag的消息。
void basicNack(long deliveryTag, boolean multiple, boolean requeue);
deliveryTag:该消息的index
multiple:是否批量.true:将一次性拒绝所有小于deliveryTag的消息。
requeue:被拒绝的是否重新入队列
channel.basicReject(long deliveryTag, boolean requeue);
deliveryTag:该消息的index
requeue:被拒绝的是否重新入队列
channel.basicNack 与 channel.basicReject 的区别在于basicNack可以拒绝多条消息,而basicReject一次只能拒绝一条消息
package com.train.algorithm.rabbitmq;
import com.rabbitmq.client.Channel;
import lombok.extern.slf4j.Slf4j;
import org.springframework.amqp.core.Message;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.stereotype.Component;
@Component
@Slf4j
public class CompileCodeCustomer{
@RabbitListener(queues = "compile.python", containerFactory = "simpleRabbitListenerContainerFactory")
public void handlePythonCode(Message message, Channel channel) {
//消息的唯一标识
long deliveryTag = message.getMessageProperties().getDeliveryTag();
try {
//1.获取消息体
String content = new String(message.getBody(),"UTF-8");
//2.业务逻辑
//................
System.out.println(content);
int a = 1/0;
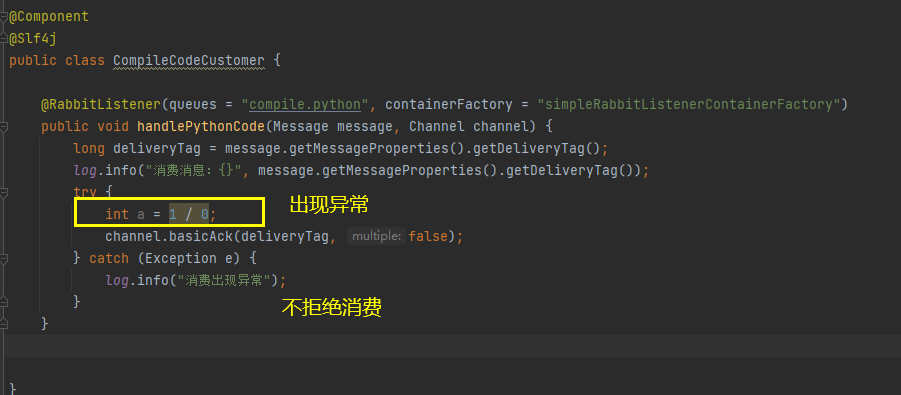
//3. 手动签收
channel.basicAck(deliveryTag,true);
} catch (Exception e) {
try {
//批量拒绝签收 deliveryTag:消息唯一id multiple:是否批量.true:将一次性拒绝所有小于deliveryTag的消息。 requeue:被拒绝的是否重新入队列
channel.basicNack(deliveryTag,true,true);
}catch (Exception exception){
log.info("消息确认异常");
}
}
}
}
注意:此处模拟了出现异常的情况,当出现异常时,拒绝接收消息,将消息重新打回队列。
此时会有一个问题,重新进入队列的消息,还会继续被投放给消费者进行消费,会一直消费出错,导致该消息被循环的消费拒绝。
分析:此处循环的主要原因是因为消息被拒绝入队,进入的是队头,因此下一次消费的还是该消息,一直出错。
配置重置次数,和重试时间,即消息消费失败后,隔一段时间再进行消费,最多重试次数为3次。(有问题)
# spring配置
spring:
rabbitmq:
host: xx.xx.91.15
port: 32116
username: coder
password: train@coder
virtual-host: compile-code
publisher-confirm-type: correlated
publisher-returns: true
template:
mandatory: true
listener:
simple:
acknowledge-mode: manual
retry:
enabled: true # 开启消费者进行重试
max-attempts: 5 # 最大重试次数
initial-interval: 3000 # 重试时间间隔
direct:
acknowledge-mode: manual
retry:
enabled: true # 开启消费者进行重试
max-attempts: 5 # 最大重试次数
initial-interval: 3000 # 重试时间间隔 3s
此时出现了一个问题,如果代码出现错误,只是捕捉了异常,并没有异常抛出,那么相当于该消息没有被确认,也没有被拒绝,队列会一直发送该消息,那么会一直消费此消息,控制台一直打印该消息的消费信息。
yaml配置:
# spring配置
spring:
rabbitmq:
host: xx.xx.91.15
port: 32116
username: coder
password: train@coder
virtual-host: compile-code
publisher-confirm-type: correlated
publisher-returns: true
template:
mandatory: true
listener:
simple:
concurrency: 1
max-concurrency: 20
prefetch: 50
default-requeue-rejected: false # 注意,此处设置的是false
acknowledge-mode: manual
# retry:
# enabled: true
# max-attempts: 10
# max-interval: 2000ms
# initial-interval: 1000ms
# multiplier: 1
direct:
concurrency: 1
max-concurrency: 20
prefetch: 50
acknowledge-mode: manual
default-requeue-rejected: false # 注意,此处设置的是false
# retry:
# enabled: true
# max-attempts: 10
# max-interval: 2000ms
# initial-interval: 1000ms
# multiplier: 1
default-requeue-rejected: false # 注意,此处设置的是false 表示被拒绝的消息不重新入队。
消费者:
发送消息入队:http://localhost:9208/alg/send/20,一共发了20条消息,均产生异常

效果:控制台打印一次信息,队列中有20条未确认的消息。

分析:消息消息后,如果一直没有消费,那么消费者会一直消费此消息,直到断开与消费者的链接或确认消息。

直接终止后台服务器:(模拟消费者断开链接)

消息状态由Unacked变为Ready,说明此时消息重新入队。
启动后台服务器:(模拟有消费者)
服务器启动成功后,20条消息会重新入队列进行消费,但是因为有异常产生,因此还是Unacked状态。

总结:
对于手动确认来说,发出的消息必须要给出明确的回复,要么确认,要么拒绝。具体拒绝后的业务可以自定义。但是如果即没有确认,也没有拒绝,那么消息会一直等待消费,如果此时断开链接,不管怎么样消息都会重新入队,等有消费者的时候继续消费。
注意: default-requeue-rejected: false 我设置的是fasle,这里不管设置false还是true都是一样,原因在于我没有主动的拒绝消息。拒绝消息的情况在之后展示。
与情况一相比,就在消费者扔出了异常
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-crBng0sF-1657963658180)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20220714110055648.png)]
结果:不扔出异常效果一样。
其余配置和之前一样。

这样,消息就直接被拒绝,被拒绝的消息拒绝重新入队。此时消息就被移除了。
分析:如果同意消息重新入队,那么消息会直接放入消息头,下次还是消费这条消息,死循环。

效果:
问题:此处的requeue和default-requeue-rejected: false的关系
# spring配置
spring:
rabbitmq:
host: xx.xx.91.15
port: 32116
username: coder
password: train@coder
virtual-host: compile-code
publisher-confirm-type: correlated
publisher-returns: true
template:
mandatory: true
listener:
simple:
acknowledge-mode: manual
retry:
enabled: true # 开启消费者进行重试
max-attempts: 5 # 最大重试次数
initial-interval: 10000000ms # 重试时间间隔
direct:
acknowledge-mode: manual
retry:
enabled: true # 开启消费者进行重试
max-attempts: 5 # 最大重试次数
initial-interval: 10000000ms # 重试时间间隔
重试机制表示消息被拒绝后,重新消费消息的策略。(分析:手动ack时,表示该消息的业务逻辑出错,理应进行其他处理,而不应重新返回队列,这里只是做一次展示)
如果设置重试后,过了重试次数之后,扔未成功处理消息,可以拒绝消息放入死信队列。

消费者
其他配置完全一样。
发现,在手动ack模式下,重试机制没有效果,并没有间隔和次数的限制,拒绝的消息一直重发。

yaml配置
# spring配置
spring:
rabbitmq:
host: xx.xx.91.15
port: 32116
username: coder
password: train@coder
virtual-host: compile-code
publisher-confirm-type: correlated
publisher-returns: true
template:
mandatory: true
listener:
simple:
concurrency: 1
max-concurrency: 20
prefetch: 50
acknowledge-mode: manual
# default-requeue-rejected: true
# retry:
# enabled: true
# max-attempts: 10
# max-interval: 2000000ms
# initial-interval: 1000000ms
# multiplier: 1
direct:
concurrency: 1
max-concurrency: 20
prefetch: 50
acknowledge-mode: auto
# default-requeue-rejected: true
# retry:
# enabled: true
# max-attempts: 10
# max-interval: 2000000ms
# initial-interval: 1000000ms
# multiplier: 1
消费者
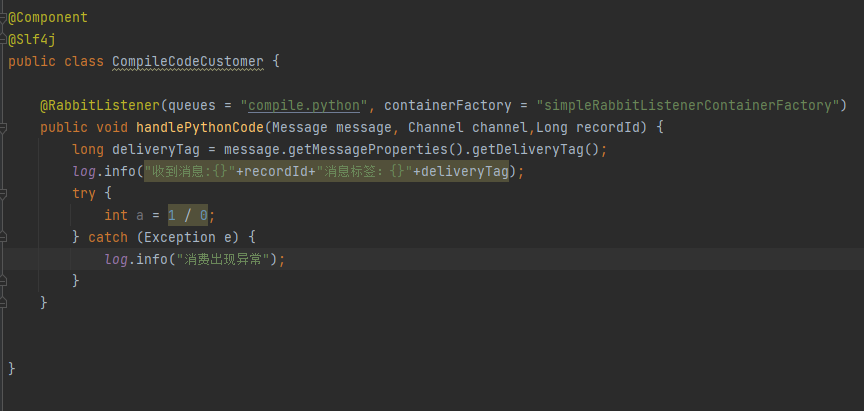
结果:
队列中无消息,消息被确认。


注意:这里的异常有三种。
当抛出AmqpRejectAndDontRequeueException异常的时候,则消息会被拒绝,且requeue=false(不重新入队列)
当抛出ImmediateAcknowledgeAmqpException异常,则消息会被确认(消息未被接收到)
immediate 参数告诉服务器,如果该消息关联的队列上有消费者,则立刻投递;
如果所有匹配的队列上都没有消费者,则直接将消息返还给生产者,不用将消息存入队列而等待消费者了。
Immediate表示该队列无消费者,消息不会入队列,返回个消费者。
其他的异常,则消息会被拒绝,且requeue=true(如果此时只有一个消费者监听该队列,则有发生死循环的风险,多消费端也会造成资源的极大浪费,这个在开发过程中一定要避免的)。可以通过setDefaultRequeueRejected(默认是true)来设置拒绝消息重新入队。
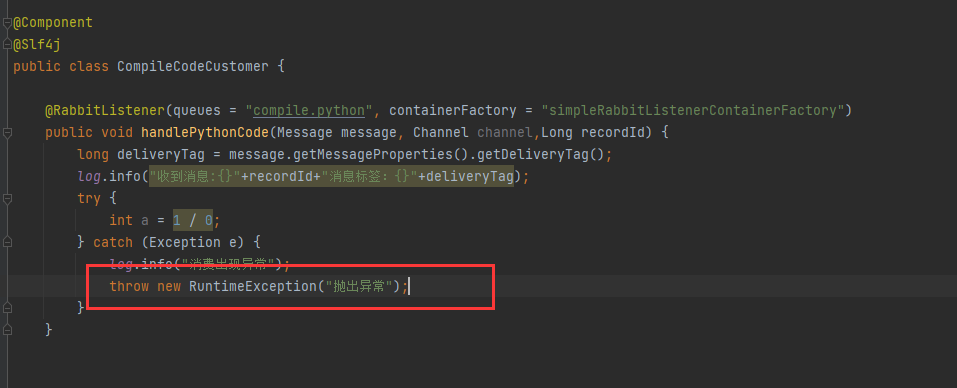
此时会抛出异常,并且消息会返回队列队头,队头继续消费错误消息,导致程序死循环。

默认情况下default-requeue-rejected=true,可能是这个原因,导致消息一直重回队列,设置成false查看状态。
测试后,发现并不是这样,false之后,消息被消费一次之后,不再重新入队。消息丢失,控制台不再打印内容。

# spring配置
spring:
rabbitmq:
host: xx.xx.91.15
port: 32116
username: coder
password: train@coder
virtual-host: compile-code
publisher-confirm-type: correlated
publisher-returns: true
template:
mandatory: true
listener:
simple:
concurrency: 5
max-concurrency: 20
prefetch: 50
acknowledge-mode: auto
default-requeue-rejected: false
retry:
enabled: true
max-attempts: 10
max-interval: 10000ms
initial-interval: 2000ms
multiplier: 1
失败后,每隔两秒,尝试重复消费,重试了十次。消息还未成功消息,消息会被确认掉,消息不再重新入队。


尝试在重试过程中,模拟于消费者断开链接,查看数据是否重回队列。

结果消息重回了队列
设置:default-requeue-rejected: true
效果还和false一样,重试达到次数后消息不会再入队。
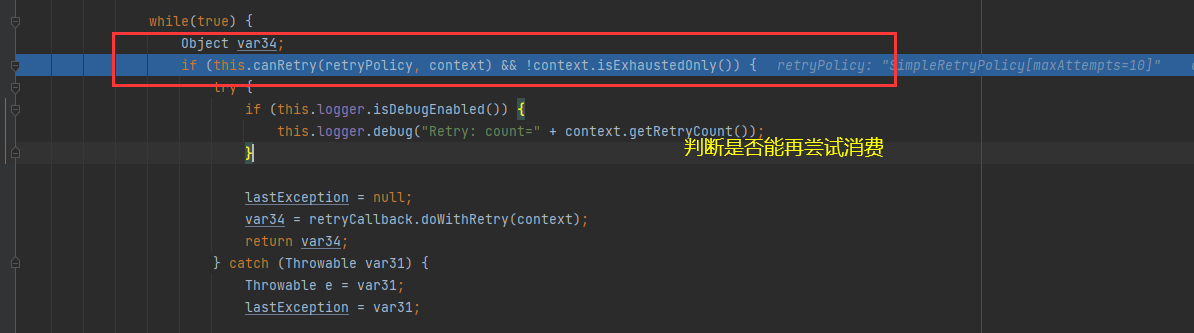
源码分析:
当消费者中有异常抛出时,rabbitmq会尝试判断该消费能否再尝试消费,如果可以,就继续尝试消费,如果不成功,则丢失该消息。
在rabbitmq的配置类中,我配置了SimpleRabbitListenerContainerFactory,没有设置他的default-requeue-rejected,默认为true。但是我在yaml中设置了default-requeue-rejected为false,发现配置类中的设置覆盖掉了yaml中的配置,导致我在yaml中配置default-requeue-rejected=false无效,消息一直重发。
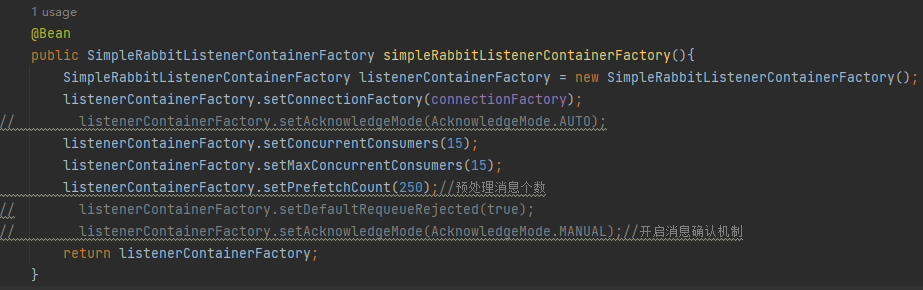
配置文件配置
# spring配置
spring:
rabbitmq:
host: xx.xx.91.15
port: 32116
username: coder
password: train@coder
virtual-host: compile-code
publisher-confirm-type: correlated
publisher-returns: true
template:
mandatory: true
listener:
simple:
concurrency: 1
max-concurrency: 20
prefetch: 50
acknowledge-mode: auto
default-requeue-rejected: false # 注意,此处是false
消费者处debug配置类详情

这样配置后,我在yaml中的配置都不会生效了。
过期的消息,拒绝后不再入队的消息,超过重试次数的消息,都会进入死信队列。
步骤:
//普通队列,普通队列绑定死信交换机
@Bean
public Queue CompileCodeQueue() {
Map<String, Object> args = new HashMap<>(2);
//声明当前队列绑定的死信交换机
args.put("x-dead-letter-exchange", CompileCodeConfig.COMPILE_CODE_DEAD_EXCHANGE);
//声明当前队列的死信路由 key
args.put("x-dead-letter-routing-key", CompileCodeConfig.COMPILE_CODE_DEAD_KEY);
//druable 持久化 后面输入队列的名称
return QueueBuilder
.durable(CompileCodeConfig.COMPILE_CODE_QUEUE)
.withArguments(args).build();
}
//死信交换机
@Bean("compileCodeDeadDirect")
public DirectExchange compileCodeDeadDirect() {
System.out.println("创建交换机");
return (DirectExchange) ExchangeBuilder
.directExchange(CompileCodeConfig.COMPILE_CODE_DEAD_EXCHANGE)
.durable(true)
.build();
}
//死信队列
@Bean("compileCodeDeadQueue")
public Queue compileCodeDeadQueue() {
return new Queue(CompileCodeConfig.COMPILE_CODE_DEAD_QUEUE);
}
//死信队列与死信交换机进行绑定
@Bean
public Binding bindingExamProcessQueueToExchange(@Qualifier("compileCodeDeadQueue") Queue queue, @Qualifier("compileCodeDeadDirect") DirectExchange customExchange) {
return BindingBuilder
.bind(queue)
.to(customExchange)
.with(CompileCodeConfig.COMPILE_CODE_DEAD_KEY);
}
配置消费者
//死信队列,存储过期或者消费失败的消息
@RabbitListener(queues = CompileCodeConfig.COMPILE_CODE_DEAD_QUEUE)
public void handleExamProcessComputed(Message message, Channel channel) {
log.info("进入死信队列, recordId:{}");
}

# spring配置
spring:
rabbitmq:
host: xx.xx.91.15
port: 32116
username: coder
password: train@coder
virtual-host: compile-code
publisher-confirm-type: correlated
publisher-returns: true
template:
mandatory: true
listener:
simple:
acknowledge-mode: manual
retry:
enabled: true # 开启消费者进行重试
max-attempts: 5 # 最大重试次数
initial-interval: 3000 # 重试时间间隔
direct:
acknowledge-mode: manual
retry:
enabled: true # 开启消费者进行重试
max-attempts: 5 # 最大重试次数
initial-interval: 3000 # 重试时间间隔
当 RabbitMQ 队列拥有多个消费者时,队列收到的消息将以轮询(round-robin)的分发方式发送给消费者。每条消息只会发送给订阅列表里的一个消费者。
默认情况下,使用轮询的方式发送,有n个消费者,会将第m条消息发送给第m%n个消费者。此时会遇到一个问题就是,如果某些消息处理特别慢,某些消息处理特别慢,那么会造成某些消费者压力较大,等待消费的消息较多,而部分消费者压力较小,进程空闲,造成整体应用吞吐量下降。
使用prefetchCount设置消费者所能保持最大未确认消费的数量,如果消费者未确认的消息达到该数量,那么消息将不再给这个消费者发送,转发给其他消费者,等压力大的消费者确认消费了某条消息后,对应的prefetchCount-1,继续接收消息。
消息分发使用的是chanel,当设置prefetchCount为15时,会生成15个channel。
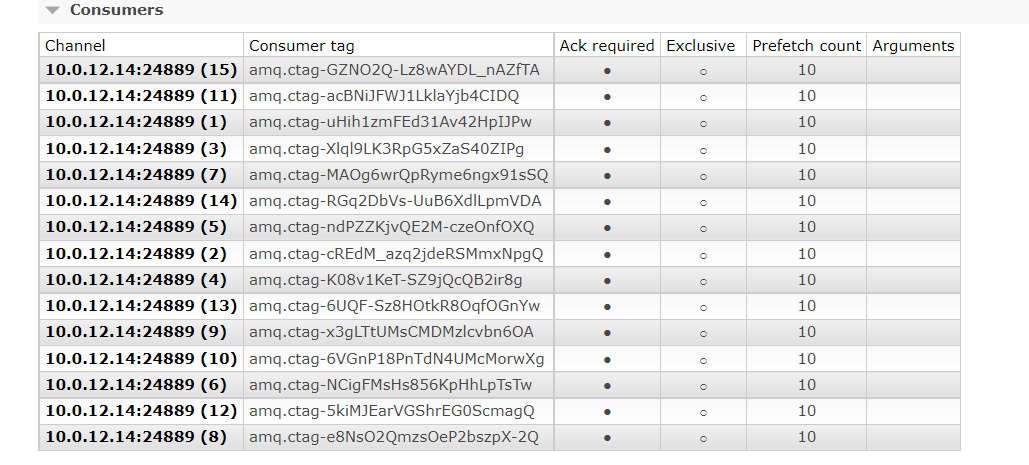
默认情况下,消费者一次消费一条。
生产者:生产10000条数据到队列
消费者:假设处理消息的时间为10s
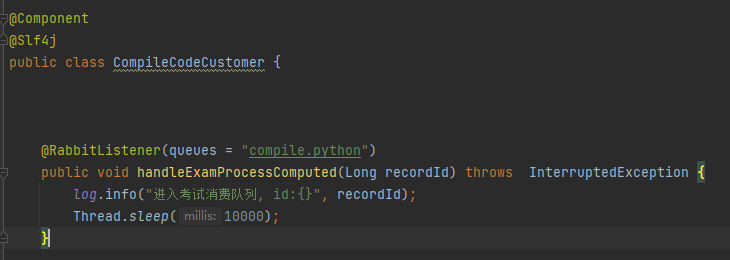
日志:
消息:

消费:每条消费相差10s消费
设置为手动确认,在yaml配置后,初始化bean时默认的自动确认会覆盖掉yaml中的配置,收到消息时,会先自动确认一次,再手动确认。手动确认时,此时chanel已经关闭,会出现错误日志。
/**
* 个人理解为SimpleMessageListenerContainer就是一个消费者的容器配置类
* @return
*/
@Bean(name="simpleMessageListenerContainer")
public SimpleMessageListenerContainer productMessageListenerContainerFactory(){
SimpleMessageListenerContainer listenerContainer = new SimpleMessageListenerContainer();
listenerContainer.setConnectionFactory(connectionFactory);
listenerContainerFactory.setAcknowledgeMode(AcknowledgeMode.MANUAL);//设置为手动确认,在yaml配置后,初始化bean时默认的自动确认会覆盖掉yaml中的配置,收到消息时,会先自动确认一次,再手动确认。手动确认时,此时chanel已经关闭,会出现错误日志。
listenerContainer.setConcurrentConsumers(10);
listenerContainer.setMaxConcurrentConsumers(20);
listenerContainer.setAcknowledgeMode(AcknowledgeMode.MANUAL);
listenerContainer.setQueues(productQueue());
listenerContainer.setMessageListener(productConsumerListener);//这里设置了消息的消费者
listenerContainer.setPrefetchCount(5);
return listenerContainer;
}
rabbitmq配置:
# spring配置
spring:
rabbitmq:
host: xx.xx.91.15
port: 32116
username: coder
password: train@coder
virtual-host: compile-code
publisher-confirm-type: correlated
publisher-returns: true
template:
mandatory: true
listener:
simple:
acknowledge-mode: auto
retry:
enabled: true
max-attempts: 10
max-interval: 2000ms
initial-interval: 1000ms
multiplier: 1
default-requeue-rejected: false
direct:
acknowledge-mode: auto # 发布确认机制 自动
retry:
enabled: true
max-attempts: 10 # 最大的重试次数
max-interval: 2000ms # 最大的重试间隔
initial-interval: 1000ms # 重试间隔
multiplier: 1 # 重试时间比
default-requeue-rejected: false # 消息被拒绝后,重新放入队列
消费者接收消息乱码,即使使用utf-8转化后。
解决,发送消息时,使用JSON将对象序列化。
发送消息
public void sendMessage(TaskRecord taskRecord) {
rabbitTemplate.convertAndSend(CompileCodeConfig.COMPILE_CODE_EXCHANGE, CompileCodeConfig.COMPILE_CODE_ROUTEKEY, JSON.toJSONString(taskRecord), new MessagePostProcessor() {
@Override
public Message postProcessMessage(Message message) throws AmqpException {
MessageProperties messageProperties = message.getMessageProperties();
//设置持久化
messageProperties.setDeliveryMode(MessageProperties.DEFAULT_DELIVERY_MODE);
//优先级
messageProperties.setPriority(2);
//过期时间,默认设置为一天
final int expireTime =3600000;
messageProperties.setExpiration(String.valueOf(expireTime));
return message;
}
},new CorrelationData(UUID.randomUUID().toString()));
}
接收消息:
String str = new String(body,"UTF-8");
log.info("收到消息:{}"+str);
(115条消息) RabbitMQ消息确定机制(自动ACK和手动ACK)_小胖学编程的博客-CSDN博客_rabbitmq手动ack
(112条消息) RabbitMQ 消费者确认auto 和 manual 模式对异常的处理区别(含重试、requeue的影响)_DatDreamer的博客-CSDN博客_requeue
【RabbitMQ-6】MQ中间件-rabbitmq-消费者消息获取及异常处理的实现(SpringBoot2.0环境下) - 简书 (jianshu.com)
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po