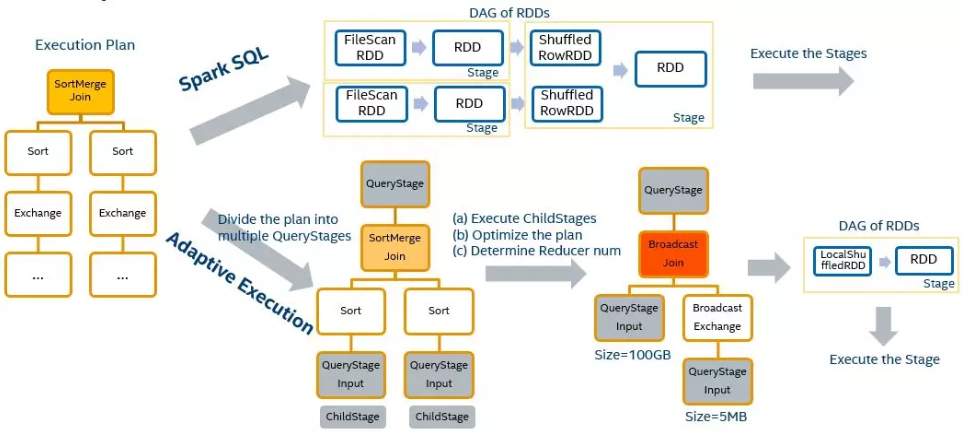
 Spark AQE 能够在 stage 提交执行之前,根据上游 stage 的所有 MapTask 的统计信息,计算得到下游每个 ReduceTask 的 shuffle 输入,因此 Spark AQE 能够自动发现发生数据倾斜的 Join,并且做出优化处理,该功能就是 Spark AQE SkewedJoin。
Spark AQE 能够在 stage 提交执行之前,根据上游 stage 的所有 MapTask 的统计信息,计算得到下游每个 ReduceTask 的 shuffle 输入,因此 Spark AQE 能够自动发现发生数据倾斜的 Join,并且做出优化处理,该功能就是 Spark AQE SkewedJoin。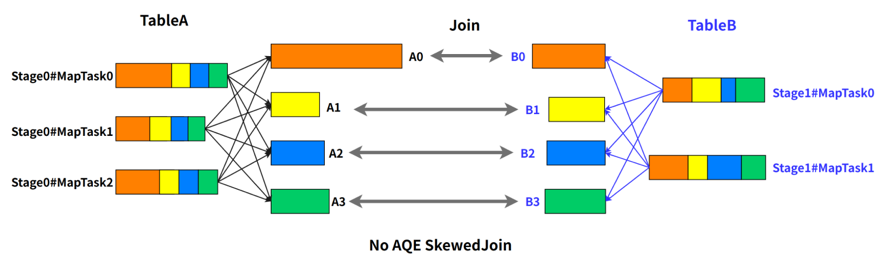 例如 A 表 inner join B 表,并且 A 表中第 0 个 partition(A0)是一个倾斜的 partition,正常情况下,A0 会和 B 表的第 0 个 partition(B0)发生 join,由于此时 A0 倾斜,task 0 就会成为长尾 task。SkewedJoin 在执行 A Join B 之前,通过上游 stage 的统计信息,发现 partition A0 明显超过平均值的数倍,即判断 A Join B 发生了数据倾斜,且倾斜分区为 partition A0。Spark AQE 会将 A0 的数据拆成 N 份,使用 N 个 task 去处理该 partition,每个 task 只读取若干个 MapTask 的 shuffle 输出文件,如下图所示,A0-0 只会读取 Stage0#MapTask0 中属于 A0 的数据。这 N 个 Task 然后都读取 B 表 partition 0 的数据做 join。这 N 个 task 执行的结果和 A 表的 A0 join B0 的结果是等价的。
例如 A 表 inner join B 表,并且 A 表中第 0 个 partition(A0)是一个倾斜的 partition,正常情况下,A0 会和 B 表的第 0 个 partition(B0)发生 join,由于此时 A0 倾斜,task 0 就会成为长尾 task。SkewedJoin 在执行 A Join B 之前,通过上游 stage 的统计信息,发现 partition A0 明显超过平均值的数倍,即判断 A Join B 发生了数据倾斜,且倾斜分区为 partition A0。Spark AQE 会将 A0 的数据拆成 N 份,使用 N 个 task 去处理该 partition,每个 task 只读取若干个 MapTask 的 shuffle 输出文件,如下图所示,A0-0 只会读取 Stage0#MapTask0 中属于 A0 的数据。这 N 个 Task 然后都读取 B 表 partition 0 的数据做 join。这 N 个 task 执行的结果和 A 表的 A0 join B0 的结果是等价的。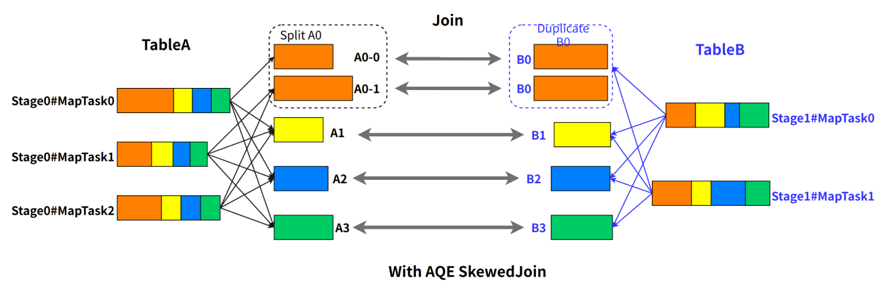 不难看出,在这样的处理中,B 表的 partition 0 会被读取 N 次,虽然这增加了一定的额外成本,但是通过 N 个任务处理倾斜数据带来的收益仍然大于这样的成本。Spark 从3.0 版本开始支持了 AQE SkewedJoin 功能,但是我们在实践中发现了一些问题。
不难看出,在这样的处理中,B 表的 partition 0 会被读取 N 次,虽然这增加了一定的额外成本,但是通过 N 个任务处理倾斜数据带来的收益仍然大于这样的成本。Spark 从3.0 版本开始支持了 AQE SkewedJoin 功能,但是我们在实践中发现了一些问题。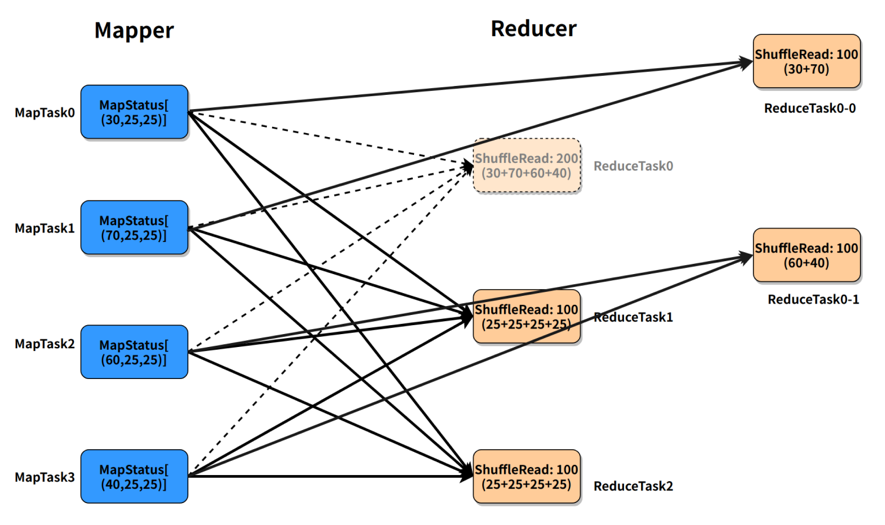 如下图描述,ReduceTask0 的 ShuffleRead(shuffle 过程中读取的数据量) 为 200,明显大于 ReduceTask1 和 ReduceTask2 的 100,发生了数据倾斜。我们可以将 ReduceTask0 拆成 2 份,ReduceTask0-0 读取 MapTask0 和 MapTask1 的数据,ReduceTask0-1 读取 MapTask2 和 MapTask3 的数据,拆分后的两个 task 的 ShuffleRead 均为 100。我们可以看出,统计信息的大小的空间复杂度是 O(M*R),对于大任务而言,会占据大量的 Driver 内存,所以 Spark 原生做了限制,对于 MapTask,当下游 ReduceTask 个数大于某一阈值(spark.shuffle.minNumPartitionsToHighlyCompress,默认 2000),就会将MapStatus进行压缩,所有小于 spark.shuffle.accurateBlockThreshold(默认100M)的值都会被一个平均值所代替填充。举个例子,下图是我们遇到的一个 SkewedJoin 没有生效的作业,从运行 metrics 来看,ShuffleRead 发生了很严重的倾斜,符合 SkewedJoin 生效的场景,但实际运行时并没有生效。
如下图描述,ReduceTask0 的 ShuffleRead(shuffle 过程中读取的数据量) 为 200,明显大于 ReduceTask1 和 ReduceTask2 的 100,发生了数据倾斜。我们可以将 ReduceTask0 拆成 2 份,ReduceTask0-0 读取 MapTask0 和 MapTask1 的数据,ReduceTask0-1 读取 MapTask2 和 MapTask3 的数据,拆分后的两个 task 的 ShuffleRead 均为 100。我们可以看出,统计信息的大小的空间复杂度是 O(M*R),对于大任务而言,会占据大量的 Driver 内存,所以 Spark 原生做了限制,对于 MapTask,当下游 ReduceTask 个数大于某一阈值(spark.shuffle.minNumPartitionsToHighlyCompress,默认 2000),就会将MapStatus进行压缩,所有小于 spark.shuffle.accurateBlockThreshold(默认100M)的值都会被一个平均值所代替填充。举个例子,下图是我们遇到的一个 SkewedJoin 没有生效的作业,从运行 metrics 来看,ShuffleRead 发生了很严重的倾斜,符合 SkewedJoin 生效的场景,但实际运行时并没有生效。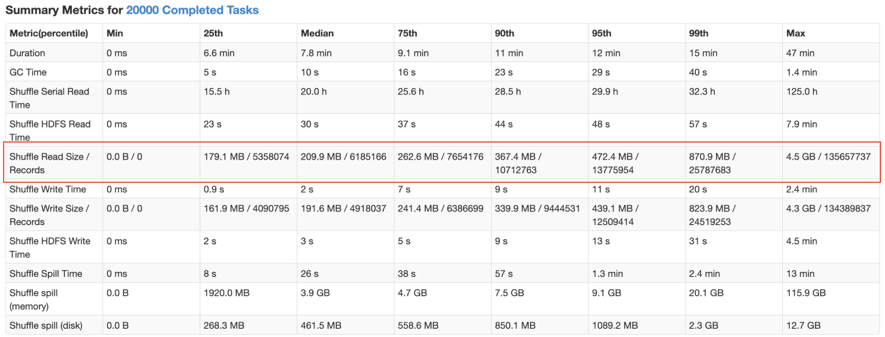 通过阅读日志,可以看到,Spark AQE 在运行时,获取的 join 两侧的 shuffle partitions 的中位数和最大值都是一样的,所以没有识别到任何的倾斜。这就是由于压缩后 MapStatus 的统计数据的不准确造成的。
通过阅读日志,可以看到,Spark AQE 在运行时,获取的 join 两侧的 shuffle partitions 的中位数和最大值都是一样的,所以没有识别到任何的倾斜。这就是由于压缩后 MapStatus 的统计数据的不准确造成的。 我们在实践中,遇到很多大作业由于统计数据不准确,无法识别倾斜。而当我们尝试提高这一阈值之后,部分大作业由于 Driver 内存使用上涨而失败,为了解决这一问题,我们做了以下优化:
我们在实践中,遇到很多大作业由于统计数据不准确,无法识别倾斜。而当我们尝试提高这一阈值之后,部分大作业由于 Driver 内存使用上涨而失败,为了解决这一问题,我们做了以下优化: 经过我们的优化后,该 Stage 的 ShuffleReadSize 的中位数和最大值分别为 149M 和 1427M,倾斜分区的切分更加均匀,该 Stage 的运行时间也由原来的 2h 降为 20m。
经过我们的优化后,该 Stage 的 ShuffleReadSize 的中位数和最大值分别为 149M 和 1427M,倾斜分区的切分更加均匀,该 Stage 的运行时间也由原来的 2h 降为 20m。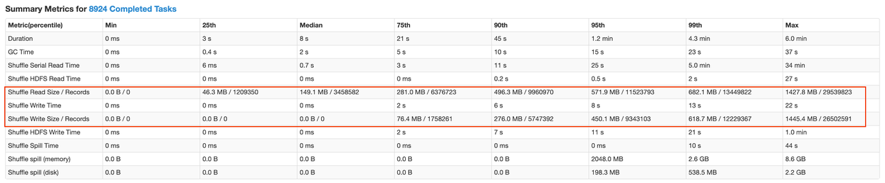
 场景2:MultipleSkewedJoin在用户的业务逻辑中,经常出现这样一种场景:一张表的主键需要连续的 join 多张表,这种场景体现在 Spark 的具体执行上,就是连续的 join 存在于同一个 Stage 当中。如下图所示 Stage21 中存在连续的多个 SortMergeJoin,而这种场景也是社区的实现无法优化的。
场景2:MultipleSkewedJoin在用户的业务逻辑中,经常出现这样一种场景:一张表的主键需要连续的 join 多张表,这种场景体现在 Spark 的具体执行上,就是连续的 join 存在于同一个 Stage 当中。如下图所示 Stage21 中存在连续的多个 SortMergeJoin,而这种场景也是社区的实现无法优化的。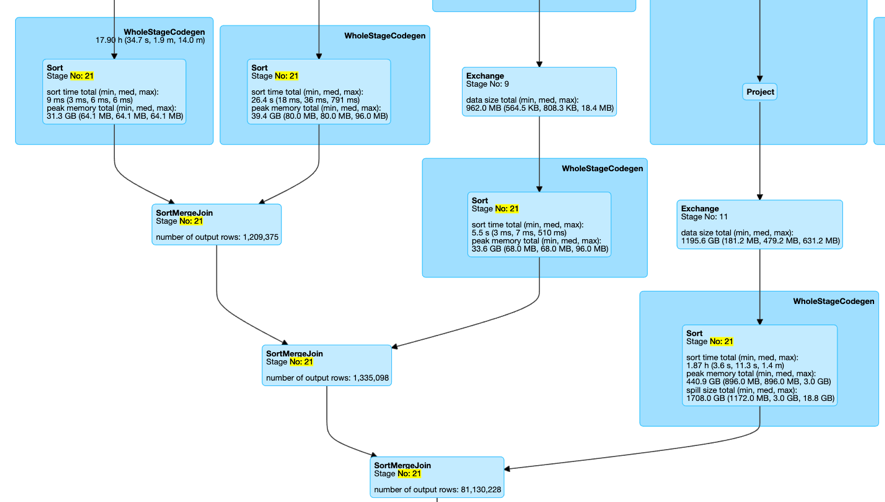 场景3:JoinWithUnionStage 中有 Union 算子,且 Union 的 children 中有 SMJ。
场景3:JoinWithUnionStage 中有 Union 算子,且 Union 的 children 中有 SMJ。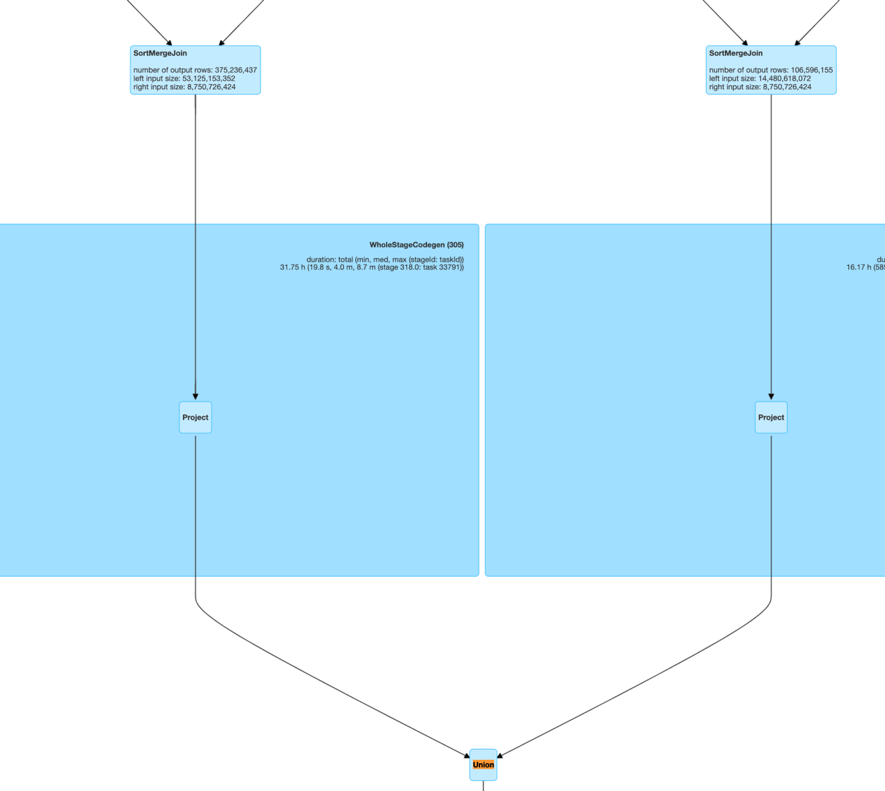 此外,我们还支持了 ShuffleHashJoin、 BucketJoin、MultipleJoinWithAggOrWin 等更多场景。
此外,我们还支持了 ShuffleHashJoin、 BucketJoin、MultipleJoinWithAggOrWin 等更多场景。| 参数配置名 | 默认值 | 参数意义 |
| spark.shuffle.minNumPartitionsToHighlyCompress | 2000 | 决定 Mapstatus 使用 HighlyCompressedMapStatus还是 CompressedMapStatus 的阈值,如果 huffle partition 大于该值,则使用 HighlyCompressedMapStatus。 |
| spark.shuffle.accurateBlockThreshold | 100M | HighlyCompressedMapStatus 中记录 shuffle blcok 准确大小的阈值,当 block 小于该值则用平均值代替。 |
| spark.sql.adaptive.skewJoin.skewedPartitionFactor | 10 | 如果一个 partition 大于该因子乘以分区大小的中位数,那么它就是倾斜的 partition。 |
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
我正在使用Ruby,我正在与一个网络端点通信,该端点在发送消息本身之前需要格式化“header”。header中的第一个字段必须是消息长度,它被定义为网络字节顺序中的2二进制字节消息长度。比如我的消息长度是1024。如何将1024表示为二进制双字节? 最佳答案 Ruby(以及Perl和Python等)中字节整理的标准工具是pack和unpack。ruby的packisinArray.您的长度应该是两个字节长,并且按网络字节顺序排列,这听起来像是n格式说明符的工作:n|Integer|16-bitunsigned,network(bi
我认为我的问题最好用一个例子来描述。假设我有一个名为“Thing”的简单模型,它有一些简单数据类型的属性。像...Thing-foo:string-goo:string-bar:int这并不难。数据库表将包含具有这三个属性的三列,我可以使用@thing.foo或@thing.bar之类的东西访问它们。但我要解决的问题是当“foo”或“goo”不再包含在简单数据类型中时会发生什么?假设foo和goo代表相同类型的对象。也就是说,它们都是“Whazit”的实例,只是数据不同。所以现在事情可能看起来像这样......Thing-bar:int但是现在有一个新的模型叫做“Whazit”,看起来
我有一个要在我的Rails3项目中使用的数组扩展方法。它应该住在哪里?我有一个应用程序/类,我最初把它放在(array_extensions.rb)中,在我的config/application.rb中我加载路径:config.autoload_paths+=%W(#{Rails.root}/应用程序/类)。但是,当我转到railsconsole时,未加载扩展。是否有一个预定义的位置可以放置我的Rails3扩展方法?或者,一种预先定义的方式来添加它们?我知道Rails有自己的数组扩展方法。我应该将我的添加到active_support/core_ext/array/conversion
参见下面的示例,我想最好使用第二种方法,但第一种也可以。哪种方法最好,使用另一种的后果是什么?classTestdefstartp"started"endtest=Test.newtest.startendclassTest2defstartp"started"endendtest2=Test2.newtest2.start 最佳答案 我肯定会说第二种变体更有意义。第一个不会导致错误,但对象实例化完全过时且毫无意义。外部变量在类的范围内不可见:var="string"classAvar=A.newendputsvar#=>strin
很难说出这里要问什么。这个问题模棱两可、含糊不清、不完整、过于宽泛或夸夸其谈,无法以目前的形式得到合理的回答。如需帮助澄清此问题以便重新打开,visitthehelpcenter.关闭9年前。我正在创建一个Sinatra应用程序,它采用上传的CSV文件并将其内容放入哈希中。当我像这样在我的app.rb中引用这个散列时:hash=extract_values(path_to_filename)我不断收到此错误消息:undefinedmethod`bytesize'forHash:0x007fc5e28f2b90#object_idfile:utils.rblocation:bytesiz
如果我构建了一个应用程序来访问来自Gmail、Twitter和Facebook的一些数据,并且我希望用户只需输入一次他们的身份验证信息,并且在几天或几周后重置,那会怎样是在Ruby中动态执行此操作的最佳方法吗?我看到很多人只是拥有他们客户/用户凭证的配置文件,如下所示:gmail_account:username:myClientpassword:myClientsPassword这看起来a)非常不安全,b)如果我想为成千上万的用户存储此类信息,它就无法工作。推荐的方法是什么?我希望能够在这些服务之上构建一个界面,因此每次用户进行交易时都必须输入凭据是不可行的。
我正在使用Devise在Rails应用程序中,并希望通过API公开一些模型数据,但应该像应用程序一样限制对API的访问。$curlhttp://myapp.com/api/v1/sales/7.json{"error":"Youneedtosigninorsignupbeforecontinuing."}很明显。在这种情况下是否有访问API的最佳实践?我更喜欢一步验证+获取数据,但这只是为了让客户的工作更轻松。他们将使用JQuery在客户端提取数据。感谢您提供任何信息!凡妮莎 最佳答案 我建议您按照以下帖子中的选项2:使用APIke
我正在开发一个Rails2.3.1网站。在整个网站中,我需要一个用于在各种页面(主页、创建帖子页面、帖子列表页面、评论列表页面等)上创建帖子的表单——只要说这个表单需要在由各种Controller)。这些页面中的每一个都显示在相应的Controller/操作中检索到的各种其他信息。例如,主页列出了最新的10篇文章、从数据库中提取的内容等。因此,我已将帖子创建表单移动到它自己的部分中,并将该部分包含在所有必要的页面中。请注意,部分POST中的表单到/questions(路由到PostsController::create——这是默认的Rails行为)。我遇到的问题是当Posts表单没有正