
? 作者:韩信子@ShowMeAI
? 大数据技术◉技能提升系列:https://www.showmeai.tech/tutorials/84
? 数据分析实战系列:https://www.showmeai.tech/tutorials/40
? 本文地址:https://www.showmeai.tech/article-detail/338
? 声明:版权所有,转载请联系平台与作者并注明出处
? 收藏ShowMeAI查看更多精彩内容

Pandas 是每位数据科学家和 Python 数据分析师都熟悉的工具库,它灵活且强大具备丰富的功能,但在处理大型数据集时,它是非常受限的。
这种情况下,我们会过渡到 PySpark,结合 Spark 生态强大的大数据处理能力,充分利用多机器并行的计算能力,可以加速计算。不过 PySpark 的语法和 Pandas 差异也比较大,很多开发人员会感觉这很让人头大。

在本篇内容中, ShowMeAI 将对最核心的数据处理和分析功能,梳理 PySpark 和 Pandas 相对应的代码片段,以便大家可以无痛地完成 Pandas 到大数据 PySpark 的转换?

大数据处理分析及机器学习建模相关知识,ShowMeAI制作了详细的教程与工具速查手册,大家可以通过如下内容展开学习或者回顾相关知识。
在使用具体功能之前,我们需要先导入所需的库:
# pandas vs pyspark,工具库导入
import pandas as pd
import pyspark.sql.functions as F
PySpark 所有功能的入口点是 SparkSession 类。通过 SparkSession 实例,您可以创建spark dataframe、应用各种转换、读取和写入文件等,下面是定义 SparkSession的代码模板:
from pyspark.sql import SparkSession
spark = SparkSession\
.builder\
.appName('SparkByExamples.com')\
.getOrCreate()
在 Pandas 和 PySpark 中,我们最方便的数据承载数据结构都是 dataframe,它们的定义有一些不同,我们来对比一下看看:
columns = ["employee","department","state","salary","age"]
data = [("Alain","Sales","Paris",60000,34),
("Ahmed","Sales","Lyon",80000,45),
("Ines","Sales","Nice",55000,30),
("Fatima","Finance","Paris",90000,28),
("Marie","Finance","Nantes",100000,40)]
创建DataFrame的 Pandas 语法如下:
df = pd.DataFrame(data=data, columns=columns)
# 查看头2行
df.head(2)
创建DataFrame的 PySpark 语法如下:
df = spark.createDataFrame(data).toDF(*columns)
# 查看头2行
df.limit(2).show()
Pandas 指定字段数据类型的方法如下:
types_dict = {
"employee": pd.Series([r[0] for r in data], dtype='str'),
"department": pd.Series([r[1] for r in data], dtype='str'),
"state": pd.Series([r[2] for r in data], dtype='str'),
"salary": pd.Series([r[3] for r in data], dtype='int'),
"age": pd.Series([r[4] for r in data], dtype='int')
}
df = pd.DataFrame(types_dict)
Pandas 可以通过如下代码来检查数据类型:
df.dtypes
PySpark 指定字段数据类型的方法如下:
from pyspark.sql.types import StructType,StructField, StringType, IntegerType
schema = StructType([ \
StructField("employee",StringType(),True), \
StructField("department",StringType(),True), \
StructField("state",StringType(),True), \
StructField("salary", IntegerType(), True), \
StructField("age", IntegerType(), True) \
])
df = spark.createDataFrame(data=data,schema=schema)
PySpark 可以通过如下代码来检查数据类型:
df.dtypes
# 查看数据类型
df.printSchema()
Pandas 和 PySpark 中的读写文件方式非常相似。 具体语法对比如下:
df = pd.read_csv(path, sep=';', header=True)
df.to_csv(path, ';', index=False)
df = spark.read.csv(path, sep=';')
df.coalesce(n).write.mode('overwrite').csv(path, sep=';')
PySpark 中可以指定要分区的列:
df.partitionBy("department","state").write.mode('overwrite').csv(path, sep=';')
可以通过上面所有代码行中的 parquet 更改 CSV 来读取和写入不同的格式,例如 parquet 格式
在 Pandas 中选择某些列是这样完成的:
columns_subset = ['employee', 'salary']
df[columns_subset].head()
df.loc[:, columns_subset].head()
在 PySpark 中,我们需要使用带有列名列表的 select 方法来进行字段选择:
columns_subset = ['employee', 'salary']
df.select(columns_subset).show(5)
Pandas可以使用 iloc对行进行筛选:
# 头2行
df.iloc[:2].head()
在 Spark 中,可以像这样选择前 n 行:
df.take(2).head()
# 或者
df.limit(2).head()
注意:使用 spark 时,数据可能分布在不同的计算节点上,因此“第一行”可能会随着运行而变化。
Pandas 中根据特定条件过滤数据/选择数据的语法如下:
# First method
flt = (df['salary'] >= 90_000) & (df['state'] == 'Paris')
filtered_df = df[flt]
# Second Method: Using query which is generally faster
filtered_df = df.query('(salary >= 90_000) and (state == "Paris")')
# Or
target_state = "Paris"
filtered_df = df.query('(salary >= 90_000) and (state == @target_state)')
在 Spark 中,使用 filter方法或执行 SQL 进行数据选择。 语法如下:
# 方法1:基于filter进行数据选择
filtered_df = df.filter((F.col('salary') >= 90_000) & (F.col('state') == 'Paris'))
# 或者
filtered_df = df.filter(F.expr('(salary >= 90000) and (state == "Paris")'))
# 方法2:基于SQL进行数据选择
df.createOrReplaceTempView("people")
filtered_df = spark.sql("""
SELECT * FROM people
WHERE (salary >= 90000) and (state == "Paris")
""")
在 Pandas 中,有几种添加列的方法:
seniority = [3, 5, 2, 4, 10]
# 方法1
df['seniority'] = seniority
# 方法2
df.insert(2, "seniority", seniority, True)
在 PySpark 中有一个特定的方法withColumn可用于添加列:
seniority = [3, 5, 2, 4, 10]
df = df.withColumn('seniority', seniority)
# pandas拼接2个dataframe
df_to_add = pd.DataFrame(data=[("Robert","Advertisement","Paris",55000,27)], columns=columns)
df = pd.concat([df, df_to_add], ignore_index = True)
# PySpark拼接2个dataframe
df_to_add = spark.createDataFrame([("Robert","Advertisement","Paris",55000,27)]).toDF(*columns)
df = df.union(df_to_add)
# pandas拼接多个dataframe
dfs = [df, df1, df2,...,dfn]
df = pd.concat(dfs, ignore_index = True)
PySpark 中 unionAll 方法只能用来连接两个 dataframe。我们使用 reduce 方法配合unionAll来完成多个 dataframe 拼接:
# pyspark拼接多个dataframe
from functools import reduce
from pyspark.sql import DataFrame
def unionAll(*dfs):
return reduce(DataFrame.unionAll, dfs)
dfs = [df, df1, df2,...,dfn]
df = unionAll(*dfs)
Pandas 和 PySpark 都提供了为 dataframe 中的每一列进行统计计算的方法,可以轻松对下列统计值进行统计计算:
Pandas 和 PySpark 计算这些统计值的方法很类似,如下:
df.summary()
#或者
df.describe()
Pandas 和 PySpark 分组聚合的操作也是非常类似的:
df.groupby('department').agg({'employee': 'count', 'salary':'max', 'age':'mean'})
df.groupBy('department').agg({'employee': 'count', 'salary':'max', 'age':'mean'})
但是,最终显示的结果需要一些调整才能一致。
在 Pandas 中,要分组的列会自动成为索引,如下所示:
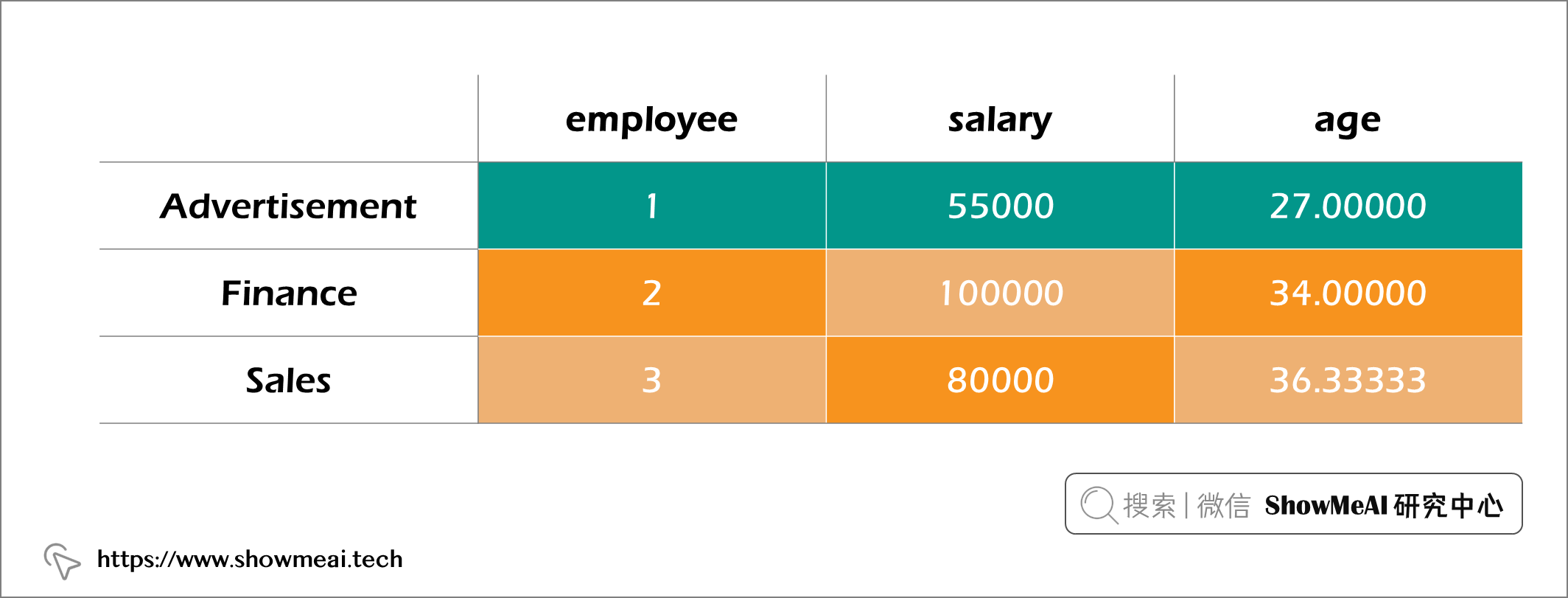
要将其作为列恢复,我们需要应用 reset_index方法:
df.groupby('department').agg({'employee': 'count', 'salary':'max', 'age':'mean'}).reset_index()
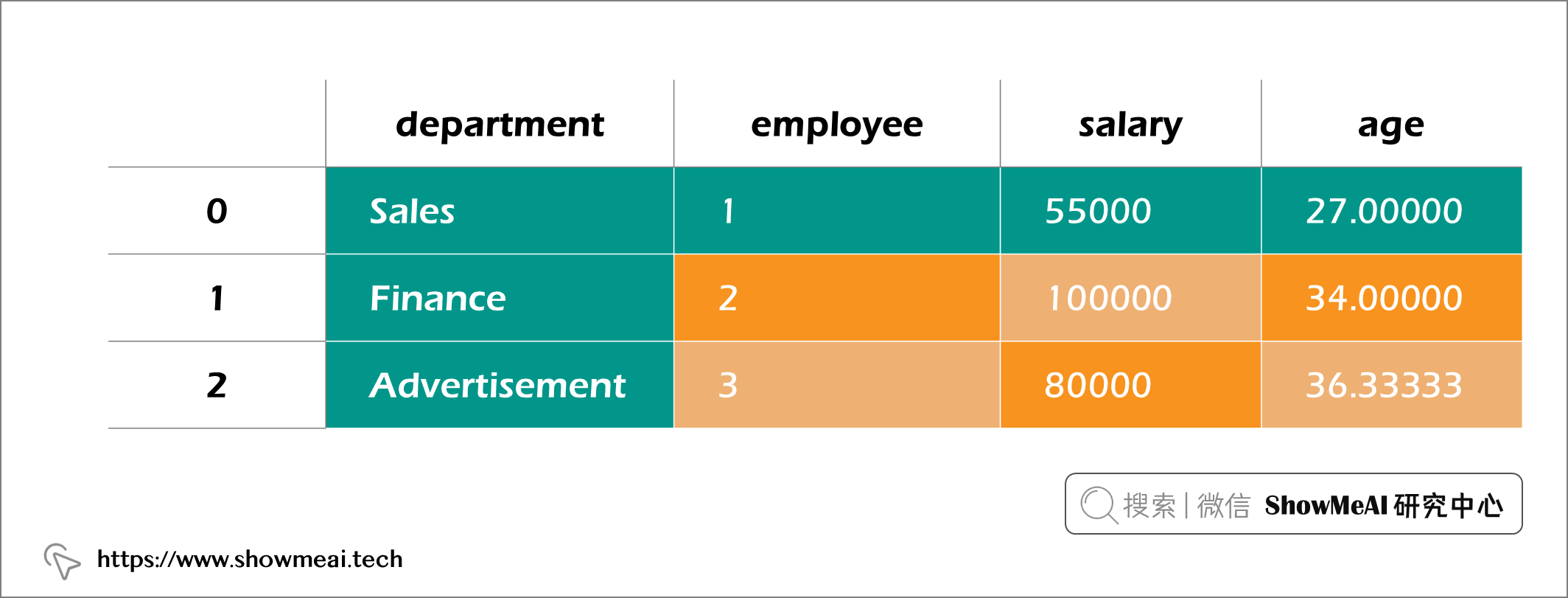
在 PySpark 中,列名会在结果dataframe中被重命名,如下所示:

要恢复列名,可以像下面这样使用别名方法:
df.groupBy('department').agg(F.count('employee').alias('employee'), F.max('salary').alias('salary'), F.mean('age').alias('age'))

在数据处理中,我们经常要进行数据变换,最常见的是要对「字段/列」应用特定转换,在Pandas中我们可以轻松基于apply函数完成,但在PySpark 中我们可以使用udf(用户定义的函数)封装我们需要完成的变换的Python函数。
例如,我们对salary字段进行处理,如果工资低于 60000,我们需要增加工资 15%,如果超过 60000,我们需要增加 5%。
Pandas 中的语法如下:
df['new_salary'] = df['salary'].apply(lambda x: x*1.15 if x<= 60000 else x*1.05)
PySpark 中的等价操作下:
from pyspark.sql.types import FloatType
df.withColumn('new_salary', F.udf(lambda x: x*1.15 if x<= 60000 else x*1.05, FloatType())('salary'))
⚠️ 请注意, udf方法需要明确指定数据类型(在我们的例子中为 FloatType)
本篇内容中, ShowMeAI 给大家总结了Pandas和PySpark对应的功能操作细节,我们可以看到Pandas和PySpark的语法有很多相似之处,但是要注意一些细节差异。
另外,大家还是要基于场景进行合适的工具选择:
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
我们的git存储库中目前有一个Gemfile。但是,有一个gem我只在我的环境中本地使用(我的团队不使用它)。为了使用它,我必须将它添加到我们的Gemfile中,但每次我checkout到我们的master/dev主分支时,由于与跟踪的gemfile冲突,我必须删除它。我想要的是类似Gemfile.local的东西,它将继承从Gemfile导入的gems,但也允许在那里导入新的gems以供使用只有我的机器。此文件将在.gitignore中被忽略。这可能吗? 最佳答案 设置BUNDLE_GEMFILE环境变量:BUNDLE_GEMFI
这似乎非常适得其反,因为太多的gem会在window上破裂。我一直在处理很多mysql和ruby-mysqlgem问题(gem本身发生段错误,一个名为UnixSocket的类显然在Windows机器上不能正常工作,等等)。我只是在浪费时间吗?我应该转向不同的脚本语言吗? 最佳答案 我在Windows上使用Ruby的经验很少,但是当我开始使用Ruby时,我是在Windows上,我的总体印象是它不是Windows原生系统。因此,在主要使用Windows多年之后,开始使用Ruby促使我切换回原来的系统Unix,这次是Linux。Rub
我正在玩HTML5视频并且在ERB中有以下片段:mp4视频从在我的开发环境中运行的服务器很好地流式传输到chrome。然而firefox显示带有海报图像的视频播放器,但带有一个大X。问题似乎是mongrel不确定ogv扩展的mime类型,并且只返回text/plain,如curl所示:$curl-Ihttp://0.0.0.0:3000/pr6.ogvHTTP/1.1200OKConnection:closeDate:Mon,19Apr201012:33:50GMTLast-Modified:Sun,18Apr201012:46:07GMTContent-Type:text/plain
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt