文章相关知识点:AI遮天传 DL-回归与分类_老师我作业忘带了的博客-CSDN博客
MNIST数据集
MNIST手写数字数据集是机器学习领域中广泛使用的图像分类数据集。它包含60,000个训练样本和10,000个测试样本。这些数字已进行尺寸规格化,并在固定尺寸的图像中居中。每个样本都是一个784×1的矩阵,是从原始的28×28灰度图像转换而来的。MNIST中的数字范围是0到9。下面显示了一些示例。 注意:在训练期间,切勿以任何形式使用有关测试样本的信息。

代码清单
要求
运行结果如下:
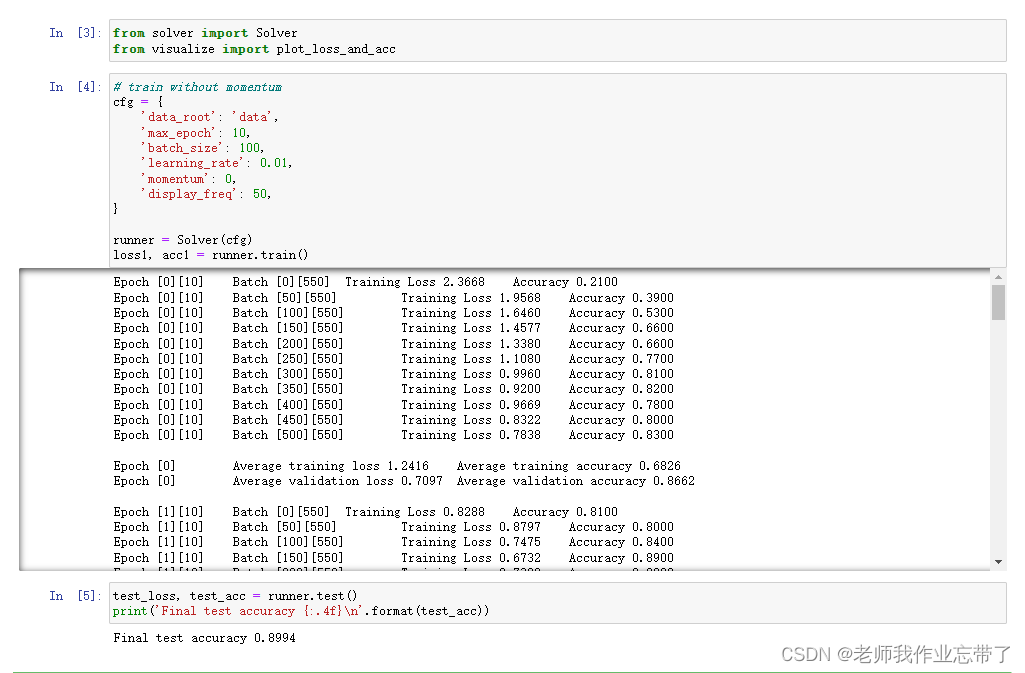
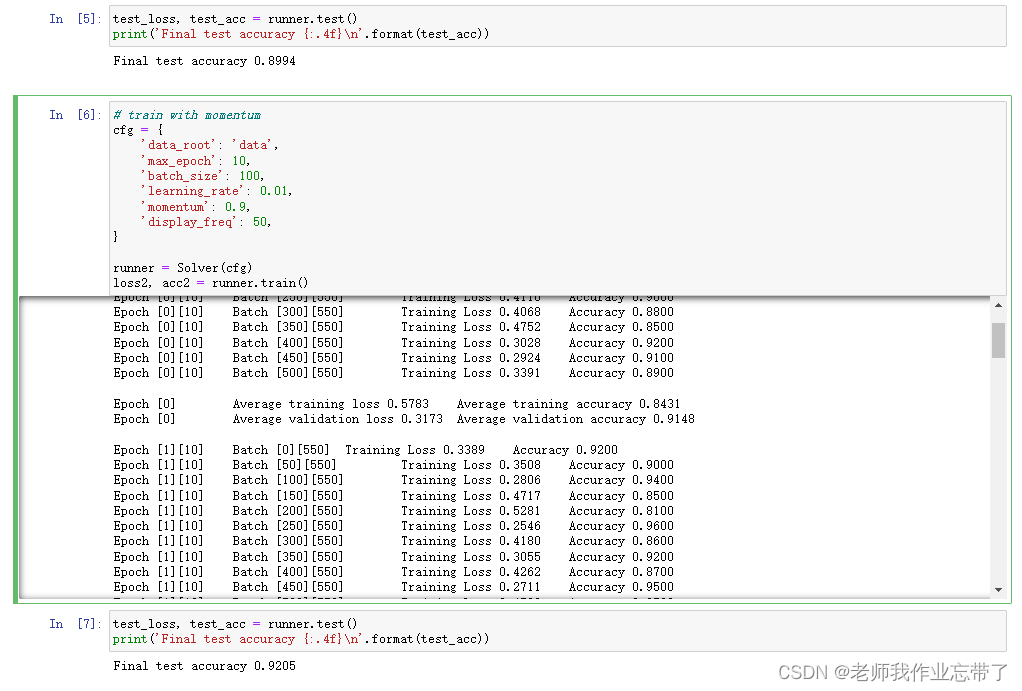
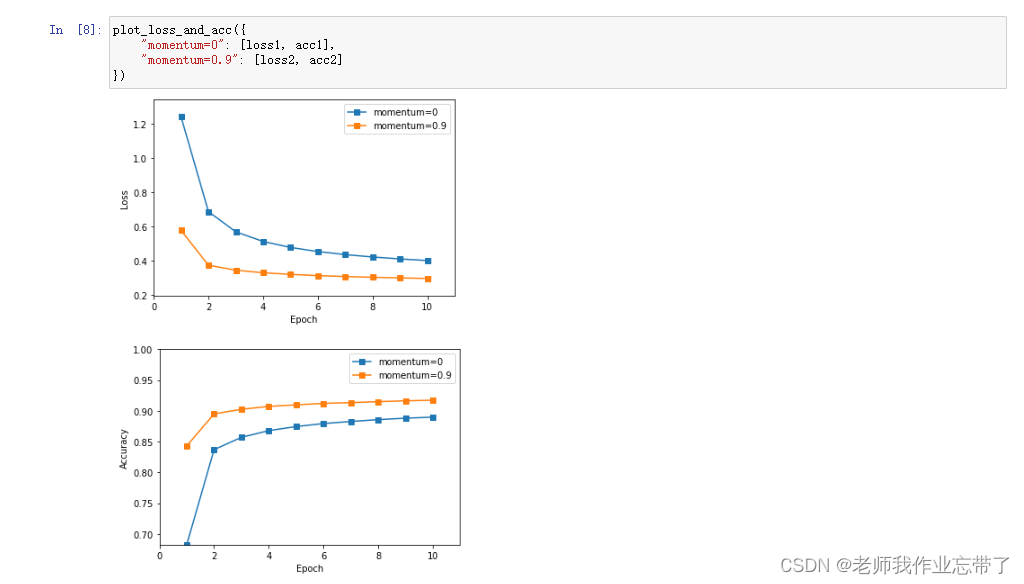
代码如下:
solver.py
import numpy as np
from layers import FCLayer
from dataloader import build_dataloader
from network import Network
from optimizer import SGD
from loss import SoftmaxCrossEntropyLoss
from visualize import plot_loss_and_acc
class Solver(object):
def __init__(self, cfg):
self.cfg = cfg
# build dataloader
train_loader, val_loader, test_loader = self.build_loader(cfg)
self.train_loader = train_loader
self.val_loader = val_loader
self.test_loader = test_loader
# build model
self.model = self.build_model(cfg)
# build optimizer
self.optimizer = self.build_optimizer(self.model, cfg)
# build evaluation criterion
self.criterion = SoftmaxCrossEntropyLoss()
@staticmethod
def build_loader(cfg):
train_loader = build_dataloader(
cfg['data_root'], cfg['max_epoch'], cfg['batch_size'], shuffle=True, mode='train')
val_loader = build_dataloader(
cfg['data_root'], 1, cfg['batch_size'], shuffle=False, mode='val')
test_loader = build_dataloader(
cfg['data_root'], 1, cfg['batch_size'], shuffle=False, mode='test')
return train_loader, val_loader, test_loader
@staticmethod
def build_model(cfg):
model = Network()
model.add(FCLayer(784, 10))
return model
@staticmethod
def build_optimizer(model, cfg):
return SGD(model, cfg['learning_rate'], cfg['momentum'])
def train(self):
max_epoch = self.cfg['max_epoch']
epoch_train_loss, epoch_train_acc = [], []
for epoch in range(max_epoch):
iteration_train_loss, iteration_train_acc = [], []
for iteration, (images, labels) in enumerate(self.train_loader):
# forward pass
logits = self.model.forward(images)
loss, acc = self.criterion.forward(logits, labels)
# backward_pass
delta = self.criterion.backward()
self.model.backward(delta)
# updata the model weights
self.optimizer.step()
# restore loss and accuracy
iteration_train_loss.append(loss)
iteration_train_acc.append(acc)
# display iteration training info
if iteration % self.cfg['display_freq'] == 0:
print("Epoch [{}][{}]\t Batch [{}][{}]\t Training Loss {:.4f}\t Accuracy {:.4f}".format(
epoch, max_epoch, iteration, len(self.train_loader), loss, acc))
avg_train_loss, avg_train_acc = np.mean(iteration_train_loss), np.mean(iteration_train_acc)
epoch_train_loss.append(avg_train_loss)
epoch_train_acc.append(avg_train_acc)
# validate
avg_val_loss, avg_val_acc = self.validate()
# display epoch training info
print('\nEpoch [{}]\t Average training loss {:.4f}\t Average training accuracy {:.4f}'.format(
epoch, avg_train_loss, avg_train_acc))
# display epoch valiation info
print('Epoch [{}]\t Average validation loss {:.4f}\t Average validation accuracy {:.4f}\n'.format(
epoch, avg_val_loss, avg_val_acc))
return epoch_train_loss, epoch_train_acc
def validate(self):
logits_set, labels_set = [], []
for images, labels in self.val_loader:
logits = self.model.forward(images)
logits_set.append(logits)
labels_set.append(labels)
logits = np.concatenate(logits_set)
labels = np.concatenate(labels_set)
loss, acc = self.criterion.forward(logits, labels)
return loss, acc
def test(self):
logits_set, labels_set = [], []
for images, labels in self.test_loader:
logits = self.model.forward(images)
logits_set.append(logits)
labels_set.append(labels)
logits = np.concatenate(logits_set)
labels = np.concatenate(labels_set)
loss, acc = self.criterion.forward(logits, labels)
return loss, acc
if __name__ == '__main__':
# You can modify the hyerparameters by yourself.
relu_cfg = {
'data_root': 'data',
'max_epoch': 10,
'batch_size': 100,
'learning_rate': 0.1,
'momentum': 0.9,
'display_freq': 50,
'activation_function': 'relu',
}
runner = Solver(relu_cfg)
relu_loss, relu_acc = runner.train()
test_loss, test_acc = runner.test()
print('Final test accuracy {:.4f}\n'.format(test_acc))
# You can modify the hyerparameters by yourself.
sigmoid_cfg = {
'data_root': 'data',
'max_epoch': 10,
'batch_size': 100,
'learning_rate': 0.1,
'momentum': 0.9,
'display_freq': 50,
'activation_function': 'sigmoid',
}
runner = Solver(sigmoid_cfg)
sigmoid_loss, sigmoid_acc = runner.train()
test_loss, test_acc = runner.test()
print('Final test accuracy {:.4f}\n'.format(test_acc))
plot_loss_and_acc({
"relu": [relu_loss, relu_acc],
"sigmoid": [sigmoid_loss, sigmoid_acc],
})
dataloader.py
import os
import struct
import numpy as np
class Dataset(object):
def __init__(self, data_root, mode='train', num_classes=10):
assert mode in ['train', 'val', 'test']
# load images and labels
kind = {'train': 'train', 'val': 'train', 'test': 't10k'}[mode]
labels_path = os.path.join(data_root, '{}-labels-idx1-ubyte'.format(kind))
images_path = os.path.join(data_root, '{}-images-idx3-ubyte'.format(kind))
with open(labels_path, 'rb') as lbpath:
magic, n = struct.unpack('>II', lbpath.read(8))
labels = np.fromfile(lbpath, dtype=np.uint8)
with open(images_path, 'rb') as imgpath:
magic, num, rows, cols = struct.unpack('>IIII', imgpath.read(16))
images = np.fromfile(imgpath, dtype=np.uint8).reshape(len(labels), 784)
if mode == 'train':
# training images and labels
self.images = images[:55000] # shape: (55000, 784)
self.labels = labels[:55000] # shape: (55000,)
elif mode == 'val':
# validation images and labels
self.images = images[55000:] # shape: (5000, 784)
self.labels = labels[55000:] # shape: (5000, )
else:
# test data
self.images = images # shape: (10000, 784)
self.labels = labels # shape: (10000, )
self.num_classes = 10
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
image = self.images[idx]
label = self.labels[idx]
# Normalize from [0, 255.] to [0., 1.0], and then subtract by the mean value
image = image / 255.0
image = image - np.mean(image)
return image, label
class IterationBatchSampler(object):
def __init__(self, dataset, max_epoch, batch_size=2, shuffle=True):
self.dataset = dataset
self.batch_size = batch_size
self.shuffle = shuffle
def prepare_epoch_indices(self):
indices = np.arange(len(self.dataset))
if self.shuffle:
np.random.shuffle(indices)
num_iteration = len(indices) // self.batch_size + int(len(indices) % self.batch_size)
self.batch_indices = np.split(indices, num_iteration)
def __iter__(self):
return iter(self.batch_indices)
def __len__(self):
return len(self.batch_indices)
class Dataloader(object):
def __init__(self, dataset, sampler):
self.dataset = dataset
self.sampler = sampler
def __iter__(self):
self.sampler.prepare_epoch_indices()
for batch_indices in self.sampler:
batch_images = []
batch_labels = []
for idx in batch_indices:
img, label = self.dataset[idx]
batch_images.append(img)
batch_labels.append(label)
batch_images = np.stack(batch_images)
batch_labels = np.stack(batch_labels)
yield batch_images, batch_labels
def __len__(self):
return len(self.sampler)
def build_dataloader(data_root, max_epoch, batch_size, shuffle=False, mode='train'):
dataset = Dataset(data_root, mode)
sampler = IterationBatchSampler(dataset, max_epoch, batch_size, shuffle)
data_lodaer = Dataloader(dataset, sampler)
return data_lodaer
loss.py
import numpy as np
# a small number to prevent dividing by zero, maybe useful for you
EPS = 1e-11
class SoftmaxCrossEntropyLoss(object):
def forward(self, logits, labels):
"""
Inputs: (minibatch)
- logits: forward results from the last FCLayer, shape (batch_size, 10)
- labels: the ground truth label, shape (batch_size, )
"""
############################################################################
# TODO: Put your code here
# Calculate the average accuracy and loss over the minibatch
# Return the loss and acc, which will be used in solver.py
# Hint: Maybe you need to save some arrays for backward
self.one_hot_labels = np.zeros_like(logits)
self.one_hot_labels[np.arange(len(logits)), labels] = 1
self.prob = np.exp(logits) / (EPS + np.exp(logits).sum(axis=1, keepdims=True))
# calculate the accuracy
preds = np.argmax(self.prob, axis=1) # self.prob, not logits.
acc = np.mean(preds == labels)
# calculate the loss
loss = np.sum(-self.one_hot_labels * np.log(self.prob + EPS), axis=1)
loss = np.mean(loss)
############################################################################
return loss, acc
def backward(self):
############################################################################
# TODO: Put your code here
# Calculate and return the gradient (have the same shape as logits)
return self.prob - self.one_hot_labels
############################################################################
network.py
class Network(object):
def __init__(self):
self.layerList = []
self.numLayer = 0
def add(self, layer):
self.numLayer += 1
self.layerList.append(layer)
def forward(self, x):
# forward layer by layer
for i in range(self.numLayer):
x = self.layerList[i].forward(x)
return x
def backward(self, delta):
# backward layer by layer
for i in reversed(range(self.numLayer)): # reversed
delta = self.layerList[i].backward(delta)
optimizer.py
import numpy as np
class SGD(object):
def __init__(self, model, learning_rate, momentum=0.0):
self.model = model
self.learning_rate = learning_rate
self.momentum = momentum
def step(self):
"""One backpropagation step, update weights layer by layer"""
layers = self.model.layerList
for layer in layers:
if layer.trainable:
############################################################################
# TODO: Put your code here
# Calculate diff_W and diff_b using layer.grad_W and layer.grad_b.
# You need to add momentum to this.
# Weight update with momentum
if not hasattr(layer, 'diff_W'):
layer.diff_W = 0.0
layer.diff_W = layer.grad_W + self.momentum * layer.diff_W
layer.diff_b = layer.grad_b
layer.W += -self.learning_rate * layer.diff_W
layer.b += -self.learning_rate * layer.diff_b
# # Weight update without momentum
# layer.W += -self.learning_rate * layer.grad_W
# layer.b += -self.learning_rate * layer.grad_b
############################################################################
visualize.py
import matplotlib.pyplot as plt
import numpy as np
def plot_loss_and_acc(loss_and_acc_dict):
# visualize loss curve
plt.figure()
min_loss, max_loss = 100.0, 0.0
for key, (loss_list, acc_list) in loss_and_acc_dict.items():
min_loss = min(loss_list) if min(loss_list) < min_loss else min_loss
max_loss = max(loss_list) if max(loss_list) > max_loss else max_loss
num_epoch = len(loss_list)
plt.plot(range(1, 1 + num_epoch), loss_list, '-s', label=key)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.xticks(range(0, num_epoch + 1, 2))
plt.axis([0, num_epoch + 1, min_loss - 0.1, max_loss + 0.1])
plt.show()
# visualize acc curve
plt.figure()
min_acc, max_acc = 1.0, 0.0
for key, (loss_list, acc_list) in loss_and_acc_dict.items():
min_acc = min(acc_list) if min(acc_list) < min_acc else min_acc
max_acc = max(acc_list) if max(acc_list) > max_acc else max_acc
num_epoch = len(acc_list)
plt.plot(range(1, 1 + num_epoch), acc_list, '-s', label=key)
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.xticks(range(0, num_epoch + 1, 2))
plt.axis([0, num_epoch + 1, min_acc, 1.0])
plt.show()
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
我正在尝试解析一个CSV文件并使用SQL命令自动为其创建一个表。CSV中的第一行给出了列标题。但我需要推断每个列的类型。Ruby中是否有任何函数可以找到每个字段中内容的类型。例如,CSV行:"12012","Test","1233.22","12:21:22","10/10/2009"应该产生像这样的类型['integer','string','float','time','date']谢谢! 最佳答案 require'time'defto_something(str)if(num=Integer(str)rescueFloat(s
导读语言模型给我们的生产生活带来了极大便利,但同时不少人也利用他们从事作弊工作。如何规避这些难辨真伪的文字所产生的负面影响也成为一大难题。在3月9日智源Live第33期活动「DetectGPT:判断文本是否为机器生成的工具」中,主讲人Eric为我们讲解了DetectGPT工作背后的思路——一种基于概率曲率检测的用于检测模型生成文本的工具,它可以帮助我们更好地分辨文章的来源和可信度,对保护信息真实、防止欺诈等方面具有重要意义。本次报告主要围绕其功能,实现和效果等展开。(文末点击“阅读原文”,查看活动回放。)Ericmitchell斯坦福大学计算机系四年级博士生,由ChelseaFinn和Chri
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
之前说过10之后的版本没有3dScan了,所以还是9.8的版本或者之前更早的版本。 3d物体扫描需要先下载扫描的APK进行扫面。首先要在手机上装一个扫描程序,扫描现实中的三维物体,然后上传高通官网,在下载成UnityPackage类型让Unity能够使用这个扫描程序可以从高通官网上进行下载,是一个安卓程序。点到Tools往下滑,找到VuforiaObjectScanner下载后解压数据线连接手机,将apk文件拷入手机安装然后刚才解压文件中的Media文件夹打开,两个PDF图打印第一张A4-ObjectScanningTarget.pdf,主要是用来辅助扫描的。好了,接下来就是扫描三维物体。将瓶
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO