已收录此专栏。
今天我们会全面学习 DFS 的相关知识,包括理论、模板、真题等。
深度优先搜索(DFS, Depth-First Search)和宽度优先搜索(BFS, Breadth-First Search,或称为广度优先搜索)是基本的暴力技术,常用于解决图、树的遍历问题。
我们以老鼠走迷宫为例说明 BFS 和 DFS 的原理吧。迷宫内的路错综复杂,老鼠从入口进去后,怎么才能找到出口?有两种方案:
1.一只老鼠走迷宫。它在每个路口,都选择先走右边(当然,选择先走左边也可以),能走多远就走多远;直到碰壁无法再继续往前走,然后往回退一步,这一次走左边,然后继续往下走。用这个办法,只要没遇到出口,就会走遍所有的路,而且不会重复(这里规定回退不算重复走)。这个思路就是 DFS。
2.一群老鼠走迷宫。假设老鼠无限多,这群老鼠进去后,在每个路口,都派出部分老鼠探索所有没走过的路。走某条路的老鼠,如果碰壁无法前行,就停下;如果到达的路口已经有别的老鼠探索过了,也停下。很显然,在遇到出口前,所有的道路都会走到,而且不会重复。这个思路就是 BFS。
在具体编程时,一般用队列这种数据结构来实现 BFS ,即 “BFS = 队列”;而 DFS 一般用递归实现,即 “DFS = 递归”。
递归是初学编程时的“第一个拦路虎”,我想很多人理解起来有困难。不过现在从形式上看,递归函数就是“自己调用自己”,是一个不断“重复”的过程。
递归的算法思想,是把大问题逐步缩小,直到变成最小的同类问题的过程,而最后的小问题的解是已知的,一般是给定的初始条件。在递归的过程中,由于大问题和小问题的解决方法完全一样,那么大问题的代码和小问题的代码可以写成一样。
下面我们以斐波那契数列的计算为例,写写代码吧。
首先我们知道它的递推关系式是 f(n) = f(n-1) + f(n-2)。那么要打印第 2020个数,递推代码如下:
fib = [0 for _ in range(25)]
fib[1] = fib[2] = 1
for i in range(3,21):
fib[i] = fib[i-1]+fib[i-2]
print(fib[20])
根据递推式改用递归编码,代码如下:
cnt = 0
def fib(n):
global cnt
cnt += 1
if n == 1 or n==2:
return 1
return fib(n-1) + fib(n-2)
print(fib(20))
print(cnt)
我们来分析一下递归过程吧。以计算第 5 个斐波那契数列为例,递归过程是这样的:
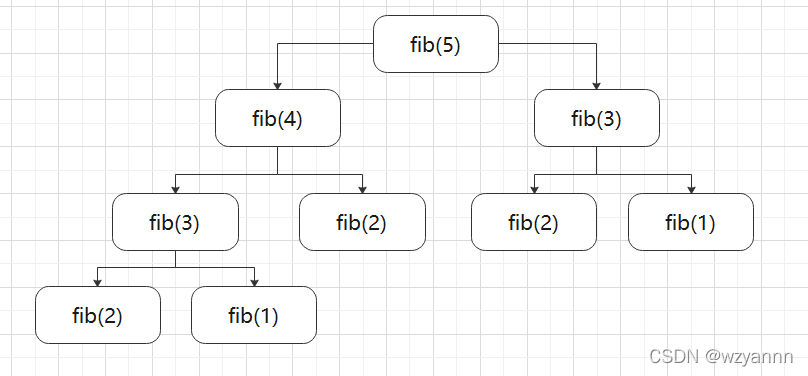
这个递归过程做了很多重复的工作啊,例如 fib(3) 计算了 2 次,但其实只算 1 次就够了。
在 fib(3) 函数中,它调用了自己 2 次。计算 fib(n) 时,计算量十分惊人。我在函数中用 cnt 统计了递归次数,计算第 20个斐波那契数时,cnt=13529。
为避免递归时重复计算子问题,可以在子问题得到解决时,就保存结果,再次需要这个结果时,直接返回保存的结果就行了。这种存储已经解决的子问题结果的技术称为“记忆化(Memoization)”。记忆化是递归的常用优化技术,以下是用“记忆化+递归”重写的斐波那契:
cnt = 0
data = [0 for _ in range(25)]
def fib(n):
global cnt
cnt += 1
if n == 1 or n==2:
data[n] = 1
return data[n]
if data[n] != 0:
return data[n]
data[n] = fib(n-1)+ fib(n-2)
return data[n]
print(fib(20))
print(cnt)
让我们来看看递归是如何解决排列相关问题的。
首先我们需要明确排列相关的是啥问题?
给出一些数,生成它们的排列,这是常见的需求,在蓝桥杯题目中常常出现。我们在“蓝桥杯精选赛题系列——暴力拼数”中给出了求排列的系统函数permutations(),还有印象吧?
系统函数permutations(),虽然好用,但是我们不能完全依赖于它。因为并不是所有需要排列的场景都能直接用 next_permutation(),有时候还是得自己写排列。一会的例题“寒假作业”,如果用 next_permutation() 函数会超时,所以必须得自己写排列算法。下面来分析一下两种自写代码的思路吧!
1.我们设数字是 {1 2 3 4 5…n},那么递归求全排列的思路是:
让第一个数不同,得到 n 个数列。其办法是:把第 1 个和后面每个数交换。
1 2 3 4 5…n
2 1 3 4 5…n
…
n 2 3 4 5…1
以上 n 个数列,只要第一个数不同,不管后面n−1 个数是怎么排列的,这 n 个数列都不同。 这是递归的第一层。
2.继续:在上面的每个数列中,去掉第一个数,对后面的 n-1 个数进行类似的排列。例如从上面第 2 行的{2 1 3 4 5…n}进入第二层(去掉首位 2):
1 3 4 5…n
3 1 4 5…n
…
n 3 4 5…1
以上 n-1 个数列,只要第一个数不同,不管后面 n-2 个数是怎么排列的,这 n-1 个数列都不同。
这是递归的第二层。
3.重复以上步骤,直到用完所有数字。
代码如下:
a = [1,2,3,4,5,6,7,8,9,10,11,12,13]
def dfs(s,t):
if s == t:
for i in range(t+1):
print(a[i],end = '')
print('\n')
return
for i in range(s,t+1):
a[s],a[i] = a[i],a[s]
dfs(s+1,t)
a[s],a[i] = a[i],a[s]
n = 3
dfs(0,n-1)
上面的代码输出的结果为:
1 2 3
1 3 2
2 1 3
2 3 1
3 2 1
3 1 2
但是!这个代码有一个致命缺点:不能按从小到大的顺序打印排列。而我们遇到的题目,常常需要按顺序输出排列。
所有还有另一种自写全排列算法
废话不多说,直接上代码。
a = [1,2,3,4,5,6,7,8,9,10,11,12,13]
vis = [0 for _ in range(20)]
b = [0 for _ in range(20)]
def dfs(s,t):
if s == t:
for i in range(t):
print(b[i],end = '')
print('\n')
return
for i in range(t):
if not vis[i]:
vis[i]=True
b[s]=a[i]
dfs(s+1,t)
vis[i]=False
n = 3
dfs(0,n)
我们来一道题来实战一下:
X 星球的一处迷宫游乐场建在某个小山坡上。它是由 10×10 相互连通的小房间组成的。
房间的地板上写着一个很大的字母。我们假设玩家是面朝上坡的方向站立,则:
L 表示走到左边的房间
R 表示走到右边的房间
U 表示走到上坡方向的房间
D 表示走到下坡方向的房间。
X 星球的居民有点懒,不愿意费力思考。他们更喜欢玩运气类的游戏。这个游戏也是如此!
开始的时候,直升机把 100 名玩家放入一个个小房间内。玩家一定要按照地上的字母移动。
迷宫地图如下:
UDDLUULRUL
UURLLLRRRU
RRUURLDLRD
RUDDDDUUUU
URUDLLRRUU
DURLRLDLRL
ULLURLLRDU
RDLULLRDDD
UUDDUDUDLL
ULRDLUURRR
请你计算一下,最后,有多少玩家会走出迷宫,而不是在里边兜圈子?
如果你还没明白游戏规则,可以参看下面一个简化的 4x4 迷宫的解说图:
无。
无。
move=[['U', 'D', 'D', 'L', 'U', 'U', 'L', 'R', 'U', 'L'], ['U', 'U', 'R', 'L', 'L', 'L', 'R', 'R', 'R', 'U'], ['R', 'R', 'U', 'U', 'R', 'L', 'D', 'L', 'R', 'D'], ['R', 'U', 'D', 'D', 'D', 'D', 'U', 'U', 'U', 'U'], ['U', 'R', 'U', 'D', 'L', 'L', 'R', 'R', 'U', 'U'], ['D', 'U', 'R', 'L', 'R', 'L', 'D', 'L', 'R', 'L'], ['U', 'L', 'L', 'U', 'R', 'L', 'L', 'R', 'D', 'U'], ['R', 'D', 'L', 'U', 'L', 'L', 'R', 'D', 'D', 'D'], ['U', 'U', 'D', 'D', 'U', 'D', 'U', 'D', 'L', 'L'], ['U', 'L', 'R', 'D', 'L', 'U', 'U', 'R', 'R', 'R']]
def tes (y,x,a):
if y<0 or y>9 or x<0 or x>9:
return 1
elif a>100:
return 0
if move[y][x]=='U':
return tes(y-1,x,a+1)
elif move[y][x]=='D':
return tes(y+1,x,a+1)
elif move[y][x]=='R':
return tes(y,x+1,a+1)
else:
return tes(y,x-1,a+1)
res=0
for y in range(10):
for x in range(10):
res+=tes(y,x,0)
print(res)
这就是本次所有内容,下期见。
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
基础版云数据库RDS的产品系列包括基础版、高可用版、集群版、三节点企业版,本文介绍基础版实例的相关信息。RDS基础版实例也称为单机版实例,只有单个数据库节点,计算与存储分离,性价比超高。说明RDS基础版实例只有一个数据库节点,没有备节点作为热备份,因此当该节点意外宕机或者执行重启实例、变更配置、版本升级等任务时,会出现较长时间的不可用。如果业务对数据库的可用性要求较高,不建议使用基础版实例,可选择其他系列(如高可用版),部分基础版实例也支持升级为高可用版。基础版与高可用版的对比拓扑图如下所示。优势 性能由于不提供备节点,主节点不会因为实时的数据库复制而产生额外的性能开销,因此基础版的性能相对于
我使用irb。下面是我写的代码。“斧头”..“bc”我期待"ax""ay""az""ba"bb""bc"但结果只是“斧头”..“bc”我该如何纠正?谢谢。 最佳答案 >puts("ax".."bc").to_aaxayazbabbbc 关于ruby-从结束值创建一系列字符串,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/7617092/
1.问题描述使用Python的turtle(海龟绘图)模块提供的函数绘制直线。2.问题分析一幅复杂的图形通常都可以由点、直线、三角形、矩形、平行四边形、圆、椭圆和圆弧等基本图形组成。其中的三角形、矩形、平行四边形又可以由直线组成,而直线又是由两个点确定的。我们使用Python的turtle模块所提供的函数来绘制直线。在使用之前我们先介绍一下turtle模块的相关知识点。turtle模块提供面向对象和面向过程两种形式的海龟绘图基本组件。面向对象的接口类如下:1)TurtleScreen类:定义图形窗口作为绘图海龟的运动场。它的构造器需要一个tkinter.Canvas或ScrolledCanva
目录前言: 一、ASC分析代码实现二、 卡片分析代码实现三、 直线分析代码实现四、货物摆放分析代码实现小结:前言: 在刷题的过程中,发现蓝桥杯的题目和力扣的差别很大。让人有一种不一样的感觉,蓝桥杯题目偏向对于实际问题用编程去的解决,而力扣给人感觉很锻炼自己的编程思维,逻辑能力。两者结合去刷,相信会有不一样的收获。 一、ASC 已知大写字母A的ASCII码为65,请问大写字母L的ASCII码是多少?分析 这道题目看上去很简单,我们需确定自己计算的准确,所以我建议用编程去解决。代码实现publicclassTest8{publicstaticvoidmain(String[]args){Sy
使用RubyonRails,我使用给定的增量(例如每30分钟)用时间填充“选择”。目前我正在YAML文件中写出所有的可能性,但我觉得有一种更巧妙的方法。我想我想提供一个开始时间、一个结束时间、一个增量,并且目前只提供一个名为“关闭”的选项(想想“business_hours”)。所以,我的选择可能会显示:'Closed'5:00am5:30am6:00am...[allthewayto]...11:30pm谁能想出更好的方法,或者只是将它们全部“拼写”出来的最佳方法? 最佳答案 此答案基于@emh的答案。defcreate_hour
我一直在尝试用Ruby实现Luhn算法。我一直在执行以下步骤:该公式根据其包含的校验位验证数字,该校验位通常附加到部分帐号以生成完整帐号。此帐号必须通过以下测试:从最右边的校验位开始向左移动,每第二个数字的值加倍。将乘积的数字(例如,10=1+0=1、14=1+4=5)与原始数字的未加倍数字相加。如果总模10等于0(如果总和以零结尾),则根据Luhn公式该数字有效;否则无效。http://en.wikipedia.org/wiki/Luhn_algorithm这是我想出的:defvalidCreditCard(cardNumber)sum=0nums=cardNumber.to_s.s