 记得那会公司还是用Nagios(估计新人已经没多少人知道了),不过监控的维护工作着实费劲。后面我就开始研究zabbix,最大的好处就是它可以discovery&自动添加监控。后面我又搭了一套ELK,把业务日志都收集到一起,监控就齐活了。
记得那会公司还是用Nagios(估计新人已经没多少人知道了),不过监控的维护工作着实费劲。后面我就开始研究zabbix,最大的好处就是它可以discovery&自动添加监控。后面我又搭了一套ELK,把业务日志都收集到一起,监控就齐活了。  由于没有添加太多告警,那会的每个告警基本都得处理,最常见的问题就是百度来爬数据,我有一套屡试不爽的处理流程:
由于没有添加太多告警,那会的每个告警基本都得处理,最常见的问题就是百度来爬数据,我有一套屡试不爽的处理流程:  结果也可想而知,由于告警实在太多,运维直接屏蔽了公司的告警短信。大部分情况下都是靠业务侧发现问题,运维再介入排查。 2)好看而没用的仪表盘 由于收集的指标数据实在太多,为了可以给业务侧输出,运维就搞起了grafana仪表盘。不过由于grafana仪表盘上的指标实在太多,页面还会经常卡住,业务研发看着一个页面上几十个指标,也不知道哪个有用,最终还是得来找运维。
结果也可想而知,由于告警实在太多,运维直接屏蔽了公司的告警短信。大部分情况下都是靠业务侧发现问题,运维再介入排查。 2)好看而没用的仪表盘 由于收集的指标数据实在太多,为了可以给业务侧输出,运维就搞起了grafana仪表盘。不过由于grafana仪表盘上的指标实在太多,页面还会经常卡住,业务研发看着一个页面上几十个指标,也不知道哪个有用,最终还是得来找运维。  为了方便研发查看日志,运维也搞了ELK,将各种日志全部收集进去,然后将kibana丢给了业务研发。结果也可想而知,除了少数几个爱折腾的,kibana上的dashboard也没有太多人看。 我一直相信运维的初衷都是好的,但从结果上来看,嗨的只有运维,毕竟运维很少看自己做的仪表盘……
为了方便研发查看日志,运维也搞了ELK,将各种日志全部收集进去,然后将kibana丢给了业务研发。结果也可想而知,除了少数几个爱折腾的,kibana上的dashboard也没有太多人看。 我一直相信运维的初衷都是好的,但从结果上来看,嗨的只有运维,毕竟运维很少看自己做的仪表盘……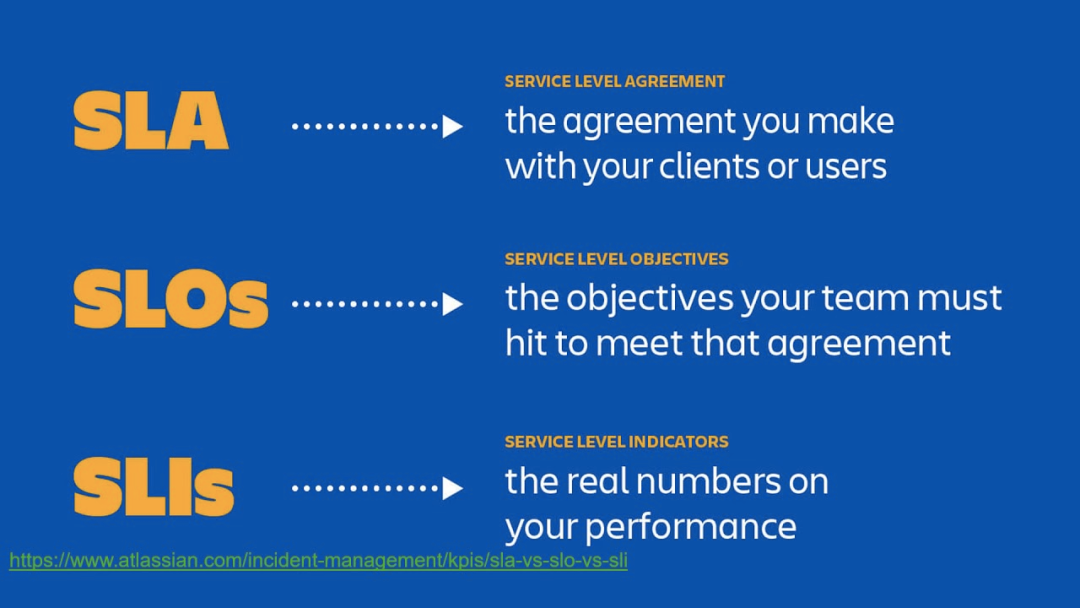 但是由于业务架构微服务化,并且采用敏捷开发的模式,实际上业务的迭代速度非常快。大部分sre本身并不是做开发出身,同时严重的配比不足(研发和运维比例),导致各种指标随着时间快速失效。其结果就是告警依旧没用,每次复盘就是再加一条告警,当然这条告警也几乎不会被触发。 这就是我经历的监控故事,你有哪些故事呢?
但是由于业务架构微服务化,并且采用敏捷开发的模式,实际上业务的迭代速度非常快。大部分sre本身并不是做开发出身,同时严重的配比不足(研发和运维比例),导致各种指标随着时间快速失效。其结果就是告警依旧没用,每次复盘就是再加一条告警,当然这条告警也几乎不会被触发。 这就是我经历的监控故事,你有哪些故事呢?  我一直没想明白一个问题: 运维自己都不一定能排查出问题原因,为什么会指望机器能实现这个事情。
我一直没想明白一个问题: 运维自己都不一定能排查出问题原因,为什么会指望机器能实现这个事情。  人和机器相比,机器更擅长于做海量数据的分析,而人则更擅长做决策。所以相比aiops我认为人机交互可能更靠谱一些。机器对海量数据进行全面分析,由运维对分析结果进行人脑决策。不过感觉这事也并不容易,因为现在的sre痴迷开发的程度已经顾不上做这些事情了。决策本身也需要对数据有一定的敏感性。
人和机器相比,机器更擅长于做海量数据的分析,而人则更擅长做决策。所以相比aiops我认为人机交互可能更靠谱一些。机器对海量数据进行全面分析,由运维对分析结果进行人脑决策。不过感觉这事也并不容易,因为现在的sre痴迷开发的程度已经顾不上做这些事情了。决策本身也需要对数据有一定的敏感性。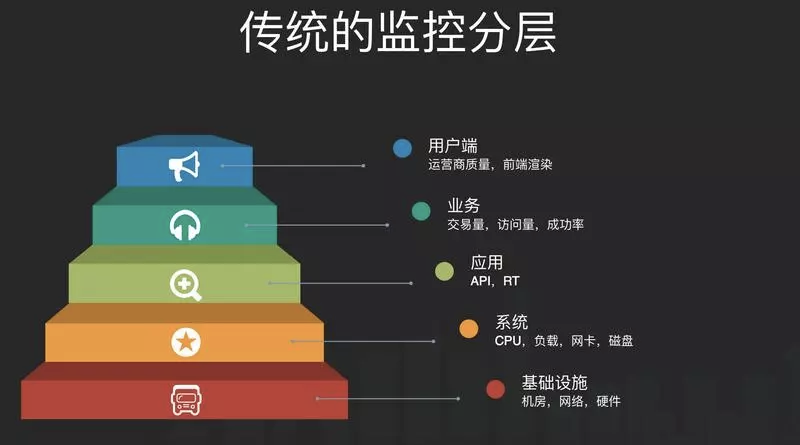 我认为产生这种分层的主要原因是:组织架构(康威定律)和职责分离。在这种分层下,运维通常就只负责下面两层,对于上层问题的处理,可能定位到某个具体的URL就结束了,剩下的就是研发的事情了。 如果要解决当前这个困境,我认为应该摒弃过去按照职责进行系统建设的方式,比如做个基础监控系统、网络监控系统、业务监控系统,而是转向围绕业务价值分阶段进行能力建设,比如基础的数据采集、传输、分析、存储、展示等能力。转型成为提供海量数据收集和中央化规则计算、统一分析和报警能力的现代化监控系统【google sre】
我认为产生这种分层的主要原因是:组织架构(康威定律)和职责分离。在这种分层下,运维通常就只负责下面两层,对于上层问题的处理,可能定位到某个具体的URL就结束了,剩下的就是研发的事情了。 如果要解决当前这个困境,我认为应该摒弃过去按照职责进行系统建设的方式,比如做个基础监控系统、网络监控系统、业务监控系统,而是转向围绕业务价值分阶段进行能力建设,比如基础的数据采集、传输、分析、存储、展示等能力。转型成为提供海量数据收集和中央化规则计算、统一分析和报警能力的现代化监控系统【google sre】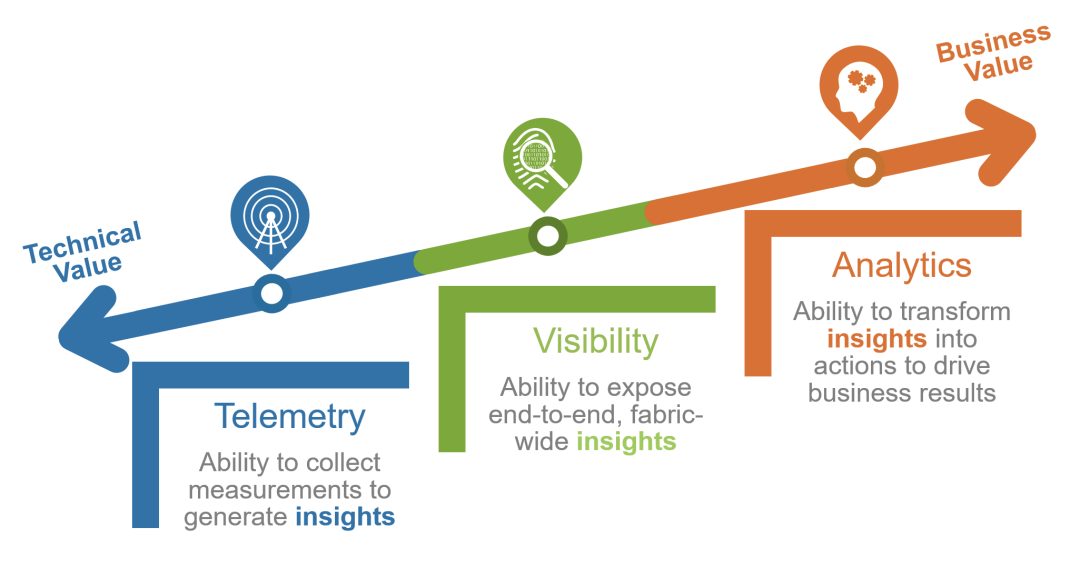 在能力建设过程中,平台团队应该以真实需求为目标,搭建最小可用平台(Thinnesr Viable Platform, TVP),并在团队中分享最佳实践和主动赋能用户,逐步成就卓越用户。同时要避免分享的都是没落地的方法论,毕竟大家都很忙。
在能力建设过程中,平台团队应该以真实需求为目标,搭建最小可用平台(Thinnesr Viable Platform, TVP),并在团队中分享最佳实践和主动赋能用户,逐步成就卓越用户。同时要避免分享的都是没落地的方法论,毕竟大家都很忙。 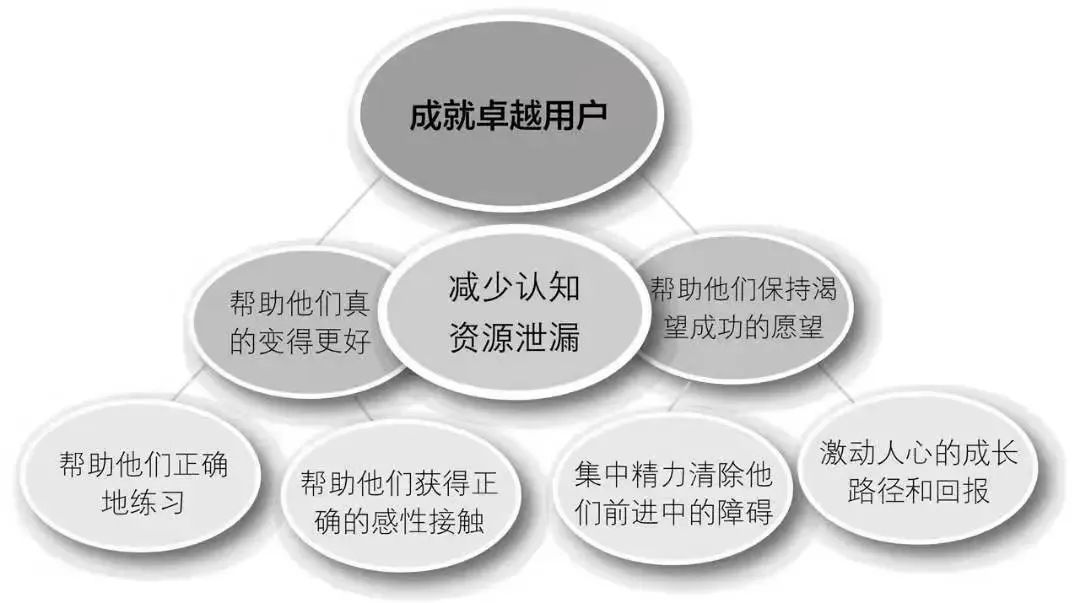
 不过这事真的有意义嘛?对于这种基础的数据的采集、分析和存储其实已经有很多商业化的方案,为什么会觉得自己几个人的小团队,配合一堆开源软件,可以做的比一个几十人的专业团队做的更好呢,而且这事离业务那么远,除了能让自己的kpi更好看,可能也并没有带来什么别的改变。 随着造的轮子越多,也慢慢发现自己变得越无效,一直在基础问题上徘徊。通常越基础的问题,解决方案也越通用,同时解决这类问题的ROI也越低,所做的工作也越无效。也不要过分强调自己场景的特殊性,除非只是想搞一些虚荣指标,而不解决本质问题。 那什么是有效的呢?我认为核心就是: 关注用户、关注业务,放弃过去通过经验的归纳来解决普遍问题,尝试利用数据分析的人机交互聚焦于核心业务,并通过AI/自动化处理支撑业务和通用业务。不过这事很难,好在我不做监控。
不过这事真的有意义嘛?对于这种基础的数据的采集、分析和存储其实已经有很多商业化的方案,为什么会觉得自己几个人的小团队,配合一堆开源软件,可以做的比一个几十人的专业团队做的更好呢,而且这事离业务那么远,除了能让自己的kpi更好看,可能也并没有带来什么别的改变。 随着造的轮子越多,也慢慢发现自己变得越无效,一直在基础问题上徘徊。通常越基础的问题,解决方案也越通用,同时解决这类问题的ROI也越低,所做的工作也越无效。也不要过分强调自己场景的特殊性,除非只是想搞一些虚荣指标,而不解决本质问题。 那什么是有效的呢?我认为核心就是: 关注用户、关注业务,放弃过去通过经验的归纳来解决普遍问题,尝试利用数据分析的人机交互聚焦于核心业务,并通过AI/自动化处理支撑业务和通用业务。不过这事很难,好在我不做监控。 去年有一个跟监控相关的很火的方向:可观测性。我对可观测性并没有太多的实践,不过在跟朋友聊可观测性时发现一些问题,这里更多的是想写下自己的困惑: 1)可观测性解决什么问题 每当聊可观测性时,我就发现大家一致认为可观测性可以解决所有的问题,就好比一把屠龙刀,所过之处寸草不生。可你要是详细问问用可观测性做了什么的时候,就会有点时光倒流的感觉,又回到各种仪表盘,满屏指标的时代。你有可观测性的故事嘛? 2)数据收集全面开花 可观测性技术发展速度感觉非常快,相关开源项目也越来越多,不过在数据收集上有个令我诧异的问题:有一天别人跟我说,可以在生产环境收集profiling做可观测性定位业务代码问题。诧异的点并不是技术实现,而是在于什么样的业务需要这种级别的可观测性,这种可观测性面向的用户又是谁,要解决的问题是什么?你有答案嘛?3)新瓶装旧酒 如果你跟同事介绍可观测性由metric、log、tracing三部分组成的时候,很容易被老运维diss,他会告诉你我们现在都已经有了,只是不太好用,丰富下就可以了,这没什么新技术,不过是新瓶装旧酒而已。这时候我通常就会提出google之前发的关于<<有意义的可用性>>里面提到的问题,如何衡量用户级别的有意义的可用性,虽然我也没有答案,不过我只想启发下对问题的思考。你是怎么理解这个问题的呢? 传统监控已死,可观测性已来。我的监控故事就到这里,可以在评论里聊聊你的故事。
去年有一个跟监控相关的很火的方向:可观测性。我对可观测性并没有太多的实践,不过在跟朋友聊可观测性时发现一些问题,这里更多的是想写下自己的困惑: 1)可观测性解决什么问题 每当聊可观测性时,我就发现大家一致认为可观测性可以解决所有的问题,就好比一把屠龙刀,所过之处寸草不生。可你要是详细问问用可观测性做了什么的时候,就会有点时光倒流的感觉,又回到各种仪表盘,满屏指标的时代。你有可观测性的故事嘛? 2)数据收集全面开花 可观测性技术发展速度感觉非常快,相关开源项目也越来越多,不过在数据收集上有个令我诧异的问题:有一天别人跟我说,可以在生产环境收集profiling做可观测性定位业务代码问题。诧异的点并不是技术实现,而是在于什么样的业务需要这种级别的可观测性,这种可观测性面向的用户又是谁,要解决的问题是什么?你有答案嘛?3)新瓶装旧酒 如果你跟同事介绍可观测性由metric、log、tracing三部分组成的时候,很容易被老运维diss,他会告诉你我们现在都已经有了,只是不太好用,丰富下就可以了,这没什么新技术,不过是新瓶装旧酒而已。这时候我通常就会提出google之前发的关于<<有意义的可用性>>里面提到的问题,如何衡量用户级别的有意义的可用性,虽然我也没有答案,不过我只想启发下对问题的思考。你是怎么理解这个问题的呢? 传统监控已死,可观测性已来。我的监控故事就到这里,可以在评论里聊聊你的故事。 我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
我们的git存储库中目前有一个Gemfile。但是,有一个gem我只在我的环境中本地使用(我的团队不使用它)。为了使用它,我必须将它添加到我们的Gemfile中,但每次我checkout到我们的master/dev主分支时,由于与跟踪的gemfile冲突,我必须删除它。我想要的是类似Gemfile.local的东西,它将继承从Gemfile导入的gems,但也允许在那里导入新的gems以供使用只有我的机器。此文件将在.gitignore中被忽略。这可能吗? 最佳答案 设置BUNDLE_GEMFILE环境变量:BUNDLE_GEMFI
这似乎非常适得其反,因为太多的gem会在window上破裂。我一直在处理很多mysql和ruby-mysqlgem问题(gem本身发生段错误,一个名为UnixSocket的类显然在Windows机器上不能正常工作,等等)。我只是在浪费时间吗?我应该转向不同的脚本语言吗? 最佳答案 我在Windows上使用Ruby的经验很少,但是当我开始使用Ruby时,我是在Windows上,我的总体印象是它不是Windows原生系统。因此,在主要使用Windows多年之后,开始使用Ruby促使我切换回原来的系统Unix,这次是Linux。Rub
我正在玩HTML5视频并且在ERB中有以下片段:mp4视频从在我的开发环境中运行的服务器很好地流式传输到chrome。然而firefox显示带有海报图像的视频播放器,但带有一个大X。问题似乎是mongrel不确定ogv扩展的mime类型,并且只返回text/plain,如curl所示:$curl-Ihttp://0.0.0.0:3000/pr6.ogvHTTP/1.1200OKConnection:closeDate:Mon,19Apr201012:33:50GMTLast-Modified:Sun,18Apr201012:46:07GMTContent-Type:text/plain
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
@作者:SYFStrive @博客首页:HomePage📜:微信小程序📌:个人社区(欢迎大佬们加入)👉:社区链接🔗📌:觉得文章不错可以点点关注👉:专栏连接🔗💃:感谢支持,学累了可以先看小段由小胖给大家带来的街舞👉微信小程序(🔥)目录自定义组件-behaviors 1、什么是behaviors 2、behaviors的工作方式 3、创建behavior 4、导入并使用behavior 5、behavior中所有可用的节点 6、同名字段的覆盖和组合规则总结最后自定义组件-behaviors 1、什么是behaviorsbehaviors是小程序中,用于实现
了解Rails缓存如何工作的人可以真正帮助我。这是嵌套在Rails::Initializer.runblock中的代码:config.after_initializedoSomeClass.const_set'SOME_CONST','SOME_VAL'end现在,如果我运行script/server并发出请求,一切都很好。然而,在我的Rails应用程序的第二个请求中,一切都因单元化常量错误而变得糟糕。在生产模式下,我可以成功发出第二个请求,这意味着常量仍然存在。我已通过将以上内容更改为以下内容来解决问题:config.after_initializedorequire'some_cl
我有一个使用PDFKit呈现网页的pdf版本的Rails应用程序。我使用Thin作为开发服务器。问题是当我处于开发模式时。当我使用“bundleexecrailss”启动我的服务器并尝试呈现任何PDF时,整个过程会陷入僵局,因为当您呈现PDF时,会向服务器请求一些额外的资源,如图像和css,看起来只有一个线程.如何配置Rails开发服务器以运行多个工作线程?非常感谢。 最佳答案 我找到的最简单的解决方案是unicorn.geminstallunicorn创建一个unicorn.conf:worker_processes3然后使用它: