目录
前一篇,我们学习了Kafka的基本使用,这一篇,我们来学习RabbitMQ。他们作为消息队列本身都具有很强大的功能,博主写完后的感受是:这也只能算是初体验了。毕竟师父领进门,修行靠个人,但是博主怎么会做这种师傅呢?一定要手把手教会各位童鞋,暂时不去深入的讲解了,这一块内容,等博主研究准备好之后,会在后续的系列中对消息队列来一个进阶的教程,大家先入个门,慢慢学习,微服务的东西很多,先学会才是正道。
RabbitMQ多用于Java,和Kafka多用于大数据不同,RabbitMQ更偏向于功能,性能一般,所以在Java开发中,比较受欢迎。那么下面,我们就来了解一下RabbitMQ及其特点。
RabbitMQ是使用Erlang语言开发的开源消息队列系统,基于AMQP协议来实现。AMQP的主要特征是面向消息、队列、路由(包括点对点和发布/订阅)、可靠性、安全。AMQP协议更多用在企业系统内,对数据一致性、稳定性和可靠性要求很高的场景,对性能和吞吐量的要求还在其次。所以在Java业务中使用很多,目前我所知道的很多都是用的此消息队列,只不过大家评价都是:功能强,性能一般。与其相反的,就是Kafka了:性能强,功能弱。
这是因为他们设计的目的不一样,RabbitMQ 在有大量消息堆积的情况下性能会下降,其优势体现在功能上。而Kafka一开始是用来处理海量日志的,所以体现出来就是性能强,功能弱。
所谓,尺有所短,寸有所长,正是这个道理。全都兼顾的几乎是不存在的。
本想去百科里复制出来,哈哈,结果百科写的太简单了:
真是想偷懒都没办法。
RabbitMQ拥有数以万计的用户,是最受欢迎的开源消息代理之一。从T-Mobile到Runtastic,RabbitMQ在全球范围内用于小型初创企业和大型企业。
RabbitMQ体量轻,易于在本地和云端部署。它支持多种消息协议。RabbitMQ可以部署在分布式和联合配置中,以满足大规模、高可用性的要求。
RabbitMQ可在许多操作系统和云环境中运行,并为大多数流行的语言提供大量的开发工具。
官网地址:RabbitMQ Tutorials — RabbitMQ
RabbitMQ的可靠性:体现在持久化、传输确认和发布确认上。
Flexible Routing:灵活路由,消息进入队列之前,通过RabbitMQ内置的Exchange来路由消息 ,针对一些复杂路由,还能将多个Exchange绑定在一起,通过插件实现自己的Exchange。
集群:这个是很多微服务软件都有的功能,比如Redis,ES等,通过此功能,可以实现高可用性的能力,在一个节点发生故障时,其他节点能快速使用。
多协议:RabbitMQ支持多种协议,具体看这里:Which protocols does RabbitMQ support? — RabbitMQ
多语言客户端:RabbitMQ 几乎支持所有常用语言,具体可查看这里:Clients Libraries and Developer Tools — RabbitMQ
管理监控:这个我们在下面安装的时候会提到此后台页面,还会登录上去给大家看,类似于nacos的管理页面,通过此界面,可以管理和监控RabbitMQ。
插件:RabbitMQ 提供了许多插件,可多方面扩展,也可以自定义插件,详情可看这里:Plugins — RabbitMQ
以上,可通过访问此链接查看详细内容:Messaging that just works — RabbitMQ
这也是本篇内容最痛苦的一个地方,因为RabbitMQ是Erlang语言开发的,所以要先安装Erlang语言的运行环境,为了不去分别讲解Mac和Windows的安装方式,博主准备偷个懒,让大家也偷个懒。
首先,看到这里,足以说明是至少是一名初级Java工程师,你至少开发过一个项目,那么你一定知道Docker,所以,下面,让我们愉快的使用Docker来安装RabbitMQ吧。
在Docker中搜索RabbitMQ,下载rabbitmq:management:
你下载上面的那个也是可以的,都没关系。
接着打开终端,在里面直接输入,记住,是直接输入,不用进任何目录:
docker run -d --hostname localhost --name rabbitmq -p 15672:15672 -p 5672:5672 rabbitmq:management
这个命令输入完成,你的 rabbitmq容器就已经跑起来了:

此时,为了测试rabbitmq是否启动成功,我们需要在浏览器输入:http://localhost:15672
打开后是一个登录页面:
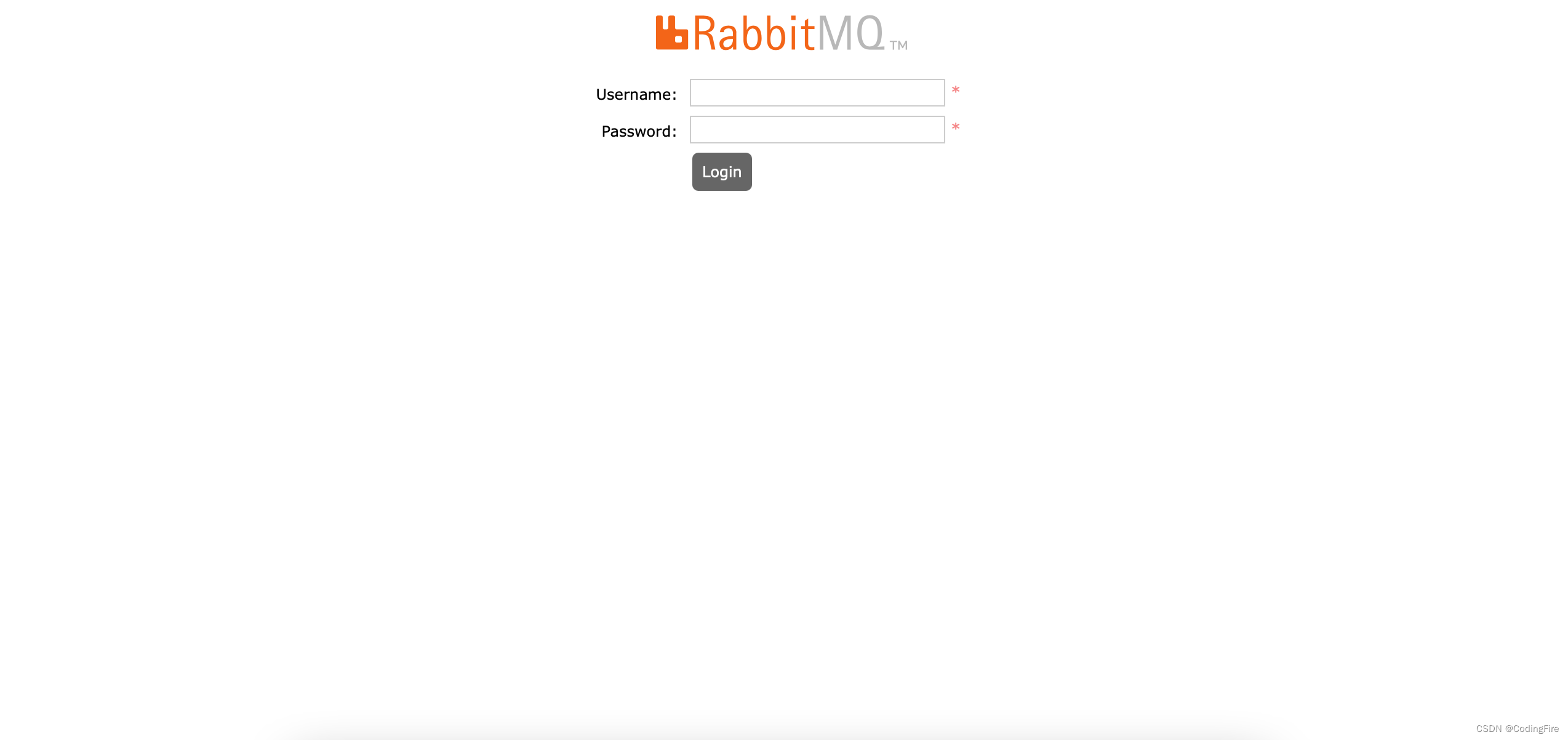
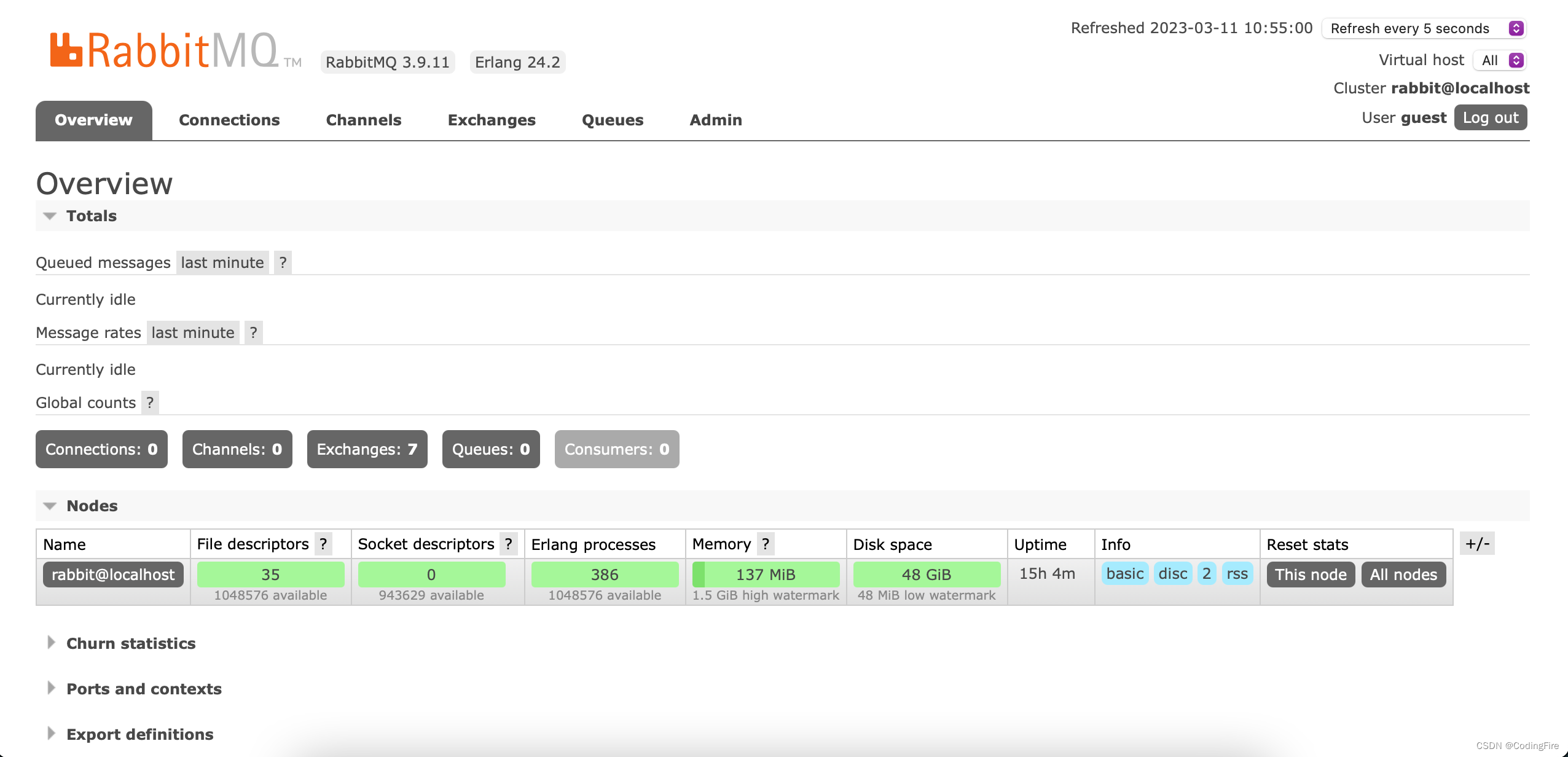
因为没有设置登录的账户名和密码,所以我们采用默认的账户密码guest来登录,输入账户密码都为guest即可登录:
如果你想添加用户密码,那就来这里:
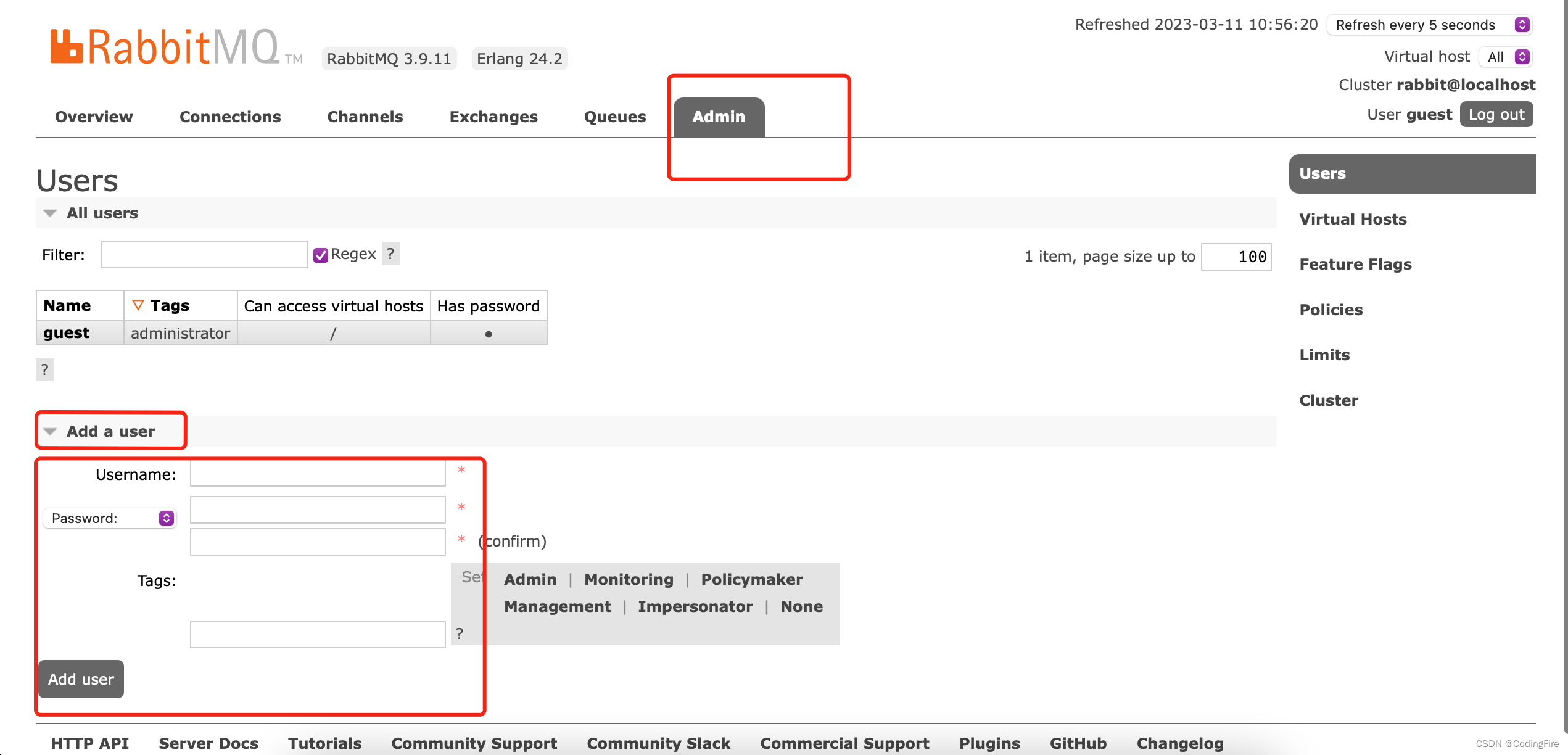
如果你想修改当前用户密码,你可点击此处:
有个Update this user,输入新密码即可:

如果你不想使用当前用户名,那就新增一个用户,再删除原来的用户。到这里,安装启动这一环节就结束了,你说,博主是不是偷了个大懒呢?
Kafka使用话题名称来收发信息,同一个话题,一个发,可多个收,使用起来结构简单易懂。
RabbitMQ则要略复杂些,它是通过交换机和路由key来指定要发送的消息队列,生产者发送消息时指定交换机和路由key,这样一个确定的消息队列就产生了,而消费者只需要指定这个产生的消息队列就可以接收到消息。
所以在编写代码时,RabbitMQ会比Kafka多一个配置类,确切的说,是每个业务都要有一个配置类,这个配置类坐的就是指定交换机和路由key,再由路由key指定队列的工作。
此处,我们依然采用前面的微服务项目作为基础,在stock模块来完成RabbitMQ的简单使用。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
spring:
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
virtual-host: /
用户名和密码要用你上面管理页面添加的 有效用户名密码,不添加,默认guest。
上面提到过,交换机,路由key,队列,这三者的指定需要在配置类中完成,具体要怎么做,我们来看看,stock模块之前写过quartz,我们就把config类建在quartz包下:
package com.codingfire.cloud.stock.quartz;
import org.springframework.amqp.core.Binding;
import org.springframework.amqp.core.BindingBuilder;
import org.springframework.amqp.core.DirectExchange;
import org.springframework.amqp.core.Queue;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
// SpringBoot整合RabbitMQ之后
// 这些配置信息要保存在Spring容器中,所以这些配置也要交给SpringBoot管理
@Configuration
public class RabbitMQConfig {
// 声明需要使用的交换机\路由Key\队列的名称
public static final String STOCK_EX="stock_ex";
public static final String STOCK_ROUT="stock_rout";
public static final String STOCK_QUEUE="stock_queue";
// 声明交换机,需要几个声明几个,这里就一个
// 方法中实例化交换机对象,确定名称,保存到Spring容器
@Bean
public DirectExchange stockDirectExchange(){
return new DirectExchange(STOCK_EX);
}
// 声明队列,需要几个声明几个,这里就一个
// 方法中实例化队列对象,确定名称,保存到Spring容器
@Bean
public Queue stockQueue(){
return new Queue(STOCK_QUEUE);
}
// 声明路由Key(交换机和队列的关系),需要几个声明几个,这里就一个
// 方法中实例化路由Key对象,确定名称,保存到Spring容器
@Bean
public Binding stockBinding(){
return BindingBuilder.bind(stockQueue()).to(stockDirectExchange())
.with(STOCK_ROUT);
}
}
都是比较固定的模版,直接用就行。
发送消息,我们可以在QuartzJob类中进行:
package com.codingfire.cloud.stock.quartz;
import org.quartz.Job;
import org.quartz.JobExecutionContext;
import org.quartz.JobExecutionException;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import java.time.LocalDateTime;
public class QuartzJob implements Job {
// RabbitTemplate就是amqp框架提供的发送消息的对象
@Autowired
private RabbitTemplate rabbitTemplate;
@Override
public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {
//输出当前时间
System.out.println("--------------"+ LocalDateTime.now() +"---------------");
// 先简单的发送一串文字
rabbitTemplate.convertAndSend(RabbitMQConfig.STOCK_EX,
RabbitMQConfig.STOCK_ROUT,"黄河之水天上来,奔流到海不复还。");
}
}
我们在讲解Quartz时只用这个类每隔10s打印出当前时间,现在我们在打印时间的同时,再用RabbitMQ发送一串文字,rabbitTemplate和使用redi很像,不同的是,这里是通过template指定发送的交换机和路由。
我们在quartz包下再建一个用于接收消息的类:
package com.codingfire.cloud.stock.quartz;
import org.springframework.amqp.rabbit.annotation.RabbitHandler;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.stereotype.Component;
// 这个对象也是需要交由Spring容器管理的,才能实现监听Spring容器中保存的队列的效果
@Component
// 和Kafka不同的是Kafka在一个方法上声明监听器
// 而RabbitMQ是在类上声明,监听具体的队列名称
@RabbitListener(queues = {RabbitMQConfig.STOCK_QUEUE})
public class RabbitMQConsumer {
// 监听了类,但是运行代码的一定是个方法
// 框架要求这个类中只允许一个方法包含下面这个注解
// 表示这个方法是处理消息的方法
// 方法的参数就是消息的值
@RabbitHandler
public void process(String str){
System.out.println("接收到的消息为:"+str);
}
}
里面的方法名可以是自定义的,只要类上指定队列名称就可以接收,类中注释认真看,要记住。
做完这些,下面就是启动并测试的环节,由于此微服务模块配置了nacos和seata,所以这两个服务是要起的,接着就是RabbitMQ,上面已经教大家启动过了,保证是运行状态: 然后运行stock的启动文件,在控制台查看消息发送接收的情况,由于博主还依赖了数据库,此处还需要启动mysql服务,大家根据自身情况启动服务,然后再次运行:
然后运行stock的启动文件,在控制台查看消息发送接收的情况,由于博主还依赖了数据库,此处还需要启动mysql服务,大家根据自身情况启动服务,然后再次运行:

可以看到我们的消息收发是正常的,测试成功,同时能看到我们做Quartz时,减少库存的操作也在运行。这就是 RabbitMQ的基本使用。
在RabbitMQ后台,也能看到我们注册的交换机和消息队列等信息:

感兴趣的可以去看看。
又到了说再见的时候,RabbitMQ和Kafka一样博大精深,这里只是基本的使用,你只要知道,他们是用来收发消息的,且不需要关心什么时候完成,你可以认为他们是在系统不忙的时候才去做,这样可以降低服务器压力,另外还能实时监控:

是不是很方便呢?赶快到自己的项目中使用吧。
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
我是rails的新手,想在form字段上应用验证。myviewsnew.html.erb.....模拟.rbclassSimulation{:in=>1..25,:message=>'Therowmustbebetween1and25'}end模拟Controller.rbclassSimulationsController我想检查模型类中row字段的整数范围,如果不在范围内则返回错误信息。我可以检查上面代码的范围,但无法返回错误消息提前致谢 最佳答案 关键是您使用的是模型表单,一种显示ActiveRecord模型实例属性的表单。c
我们的git存储库中目前有一个Gemfile。但是,有一个gem我只在我的环境中本地使用(我的团队不使用它)。为了使用它,我必须将它添加到我们的Gemfile中,但每次我checkout到我们的master/dev主分支时,由于与跟踪的gemfile冲突,我必须删除它。我想要的是类似Gemfile.local的东西,它将继承从Gemfile导入的gems,但也允许在那里导入新的gems以供使用只有我的机器。此文件将在.gitignore中被忽略。这可能吗? 最佳答案 设置BUNDLE_GEMFILE环境变量:BUNDLE_GEMFI
这似乎非常适得其反,因为太多的gem会在window上破裂。我一直在处理很多mysql和ruby-mysqlgem问题(gem本身发生段错误,一个名为UnixSocket的类显然在Windows机器上不能正常工作,等等)。我只是在浪费时间吗?我应该转向不同的脚本语言吗? 最佳答案 我在Windows上使用Ruby的经验很少,但是当我开始使用Ruby时,我是在Windows上,我的总体印象是它不是Windows原生系统。因此,在主要使用Windows多年之后,开始使用Ruby促使我切换回原来的系统Unix,这次是Linux。Rub
我正在玩HTML5视频并且在ERB中有以下片段:mp4视频从在我的开发环境中运行的服务器很好地流式传输到chrome。然而firefox显示带有海报图像的视频播放器,但带有一个大X。问题似乎是mongrel不确定ogv扩展的mime类型,并且只返回text/plain,如curl所示:$curl-Ihttp://0.0.0.0:3000/pr6.ogvHTTP/1.1200OKConnection:closeDate:Mon,19Apr201012:33:50GMTLast-Modified:Sun,18Apr201012:46:07GMTContent-Type:text/plain
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我有一个涉及多台机器、消息队列和事务的问题。因此,例如用户点击网页,点击将消息发送到另一台机器,该机器将付款添加到用户的帐户。每秒可能有数千次点击。事务的所有方面都应该是容错的。我以前从未遇到过这样的事情,但一些阅读表明这是一个众所周知的问题。所以我的问题。我假设安全的方法是使用两阶段提交,但协议(protocol)是阻塞的,所以我不会获得所需的性能,我是否正确?我通常写Ruby,但似乎Redis之类的数据库和Rescue、RabbitMQ等消息队列系统对我的帮助不大——即使我实现某种两阶段提交,如果Redis崩溃,数据也会丢失,因为它本质上只是内存。所有这些让我开始关注erlang和
我只想对我一直在思考的这个问题有其他意见,例如我有classuser_controller和classuserclassUserattr_accessor:name,:usernameendclassUserController//dosomethingaboutanythingaboutusersend问题是我的User类中是否应该有逻辑user=User.newuser.do_something(user1)oritshouldbeuser_controller=UserController.newuser_controller.do_something(user1,user2)我