目录
Hadoop+Hive+Spark+HBase
启动Hadoop:start-all.sh
启动zookeeper:zkServer.sh start
启动Hive:
nohup hiveserver2 1>/dev/null 2>&1 &
beeline -u jdbc:hive2://192.168.152.192:10000
启动Hbase:
start-hbase.sh
hbase shell
启动Spark:spark-shell
数据描述 UserBehavior 是阿里巴巴提供的一个淘宝用户行为数据集。本数据集包含了 2017-09-11 至 2017-12-03 之间有行为的约 5458 位随机用户的所有行为(行为包括点击、购买、加 购、喜欢)。数据集的每一行表示一条用户行为,由用户 ID、商品 ID、商品类目 ID、 行为类型和时间戳组成,并以逗号分隔。关于数据集中每一列的详细描述如下具体字段 说明如下:

请在 HDFS 中创建目录/data/userbehavior,并将 UserBehavior.csv 文件传到该目录。通过 HDFS 命令查询出文档有多少行数据。
hdfs dfs -mkdir -p /data/userbehavior
hdfs dfs -put ./UserBehavior.csv /data/userbehavior
hdfs dfs -cat /data/userbehavior/UserBehavior.csv | wc -l
①请在 Hive 中创建数据库 exam
create database exam;②请在 exam 数据库中创建外部表 userbehavior,并将 HDFS 数据映射到表中
create external table userbehavior
(
user_id int,
item_id int,
category_id int,
behavior_type string,
`time` bigint
)
row format delimited fields terminated by ',' stored as textfile location '/data/userbehavior/';③请在 HBase 中创建命名空间 exam,并在命名空间 exam 创建 userbehavior 表,包含一个列簇 info
hbase(main):007:0> create_namespace 'exam'
hbase(main):008:0> create 'exam:userbehavior','info'④请在 Hive 中创建外部表 userbehavior_hbase,并映射到 HBase 中,并将数 据加载到 HBase 中
create external table if not exists userbehavior_hbase(
user_id int,
item_id int,
category_id int,
behavior_type string,
time bigint
)
stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
with serdeproperties ("hbase.columns.mapping"=":key,info:item_id,info:category_id,info:behavior_type,info:time")
tblproperties ("hbase.table.name"="exam:userbehavior");
//开始映射
insert into userbehavior_hbase select * from userbehavior;
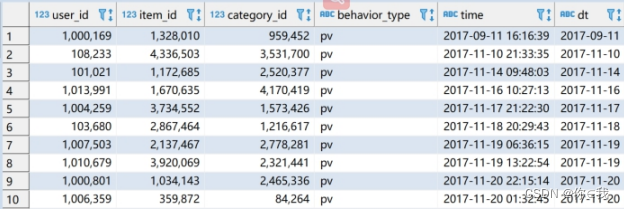
⑤请在 exam 数据库中创建内部分区表 userbehavior_partitioned(按照日期进行分区), 并通过查询 userbehavior 表将时间戳格式化为”年-月-日 时将数据插 入至 userbehavior_partitioned 表中,例如下图
//设置分区
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
//创建分区表
create table userbehavoir_partitioned(
user_id int,
item_id int,
category_id int,
behavior_type string,
time string
)
partitioned by (dt string)stored as orc ;
//按格式插入分区表中
insert into userbehavoir_partitioned partition (dt)
select user_id,item_id,category_id,behavior_type,
from_unixtime(time,"YYYY-MM-dd HH:mm:ss") as time,
from_unixtime(time,"YYYY-MM-dd")as dt
from userbehavior;
show partitions userbehavoir_partitioned;
select * from userbehavoir_partitioned;请使用 Spark,加载 HDFS 文件系统 UserBehavior.csv 文件,并分别使用 RDD 完成以下 分析。 统计 uv 值(一共有多少用户访问淘宝)
scala> val fileRdd=sc.textFile("/data/userbehavior")
//数据进行处理
scala> val userbehaviorRdd=fileRdd.map(x=>x.split(",")).filter(x=>x.length==5)
//统计不重复的个数
scala> userbehaviorRdd.map(x=>x(0)).distinct.count
res8: Long = 5458 分别统计浏览行为为点击,收藏,加入购物车,购买的总数量
scala> userbehaviorRdd.map(x=>(x(3),1)).reduceByKey(_+_).collect.foreach(println)
(cart,30888)
(buy,11508)
(pv,503881)
(fav,15017)使用 SparkSQL 统计用户最近购买时间。以 2017-12-03 为当前日期,计算时间范围 为一个月,计算用户最近购买时间,时间的区间为 0-30 天,将其分为 5 档,0-6 天,7-12 4 天,13-18 天,19-24 天,25-30 天分别对应评分 4 到 0
scala> spark.sql("""
| select
| t1.user_id,
| ( case when t1.diff between 0 and 6 then 4
| when t1.diff between 7 and 12 then 3
| when t1.diff between 13 and 18 then 2
| when t1.diff between 19 and 24 then 1
| when t1.diff between 25 and 30 then 0
| else null end
| ) level
| from
| (select user_id, datediff('2017-12-03',max(dt)) as diff, max(dt) as maxNum
| from exam.userbehavior_partitioned where dt>'2017-11-03' and behavior_type='buy'
| group by user_id) t1
| """).show使用 SparkSQL 统计用户的消费频率。以 2017-12-03 为当前日期,计算时间范围为 一个月,计算用户的消费次数,用户中消费次数从低到高为 1-161 次,将其分为 5 档,1-32,33-64,65-96,97-128,129-161 分别对应评分 0
scala> spark.sql("""
| with
| t1 as (select user_id, count(user_id) num
| from exam.userbehavior_partitioned
| where dt between '2017-11-03' and '2017-12-03'
| and behavior_type='buy'
| group by user_id)
| select t1.user_id,
| (
| case when t1.num between 1 and 32 then 0
| when t1.num between 33 and 64 then 1
| when t1.num between 65 and 96 then 2
| when t1.num between 97 and 128 then 3
| when t1.num between 129 and 161 then 4
| else null end
| ) level
| from t1
| """).show
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我将应用程序升级到Rails4,一切正常。我可以登录并转到我的编辑页面。也更新了观点。使用标准View时,用户会更新。但是当我添加例如字段:name时,它不会在表单中更新。使用devise3.1.1和gem'protected_attributes'我需要在设备或数据库上运行某种更新命令吗?我也搜索过这个地方,找到了许多不同的解决方案,但没有一个会更新我的用户字段。我没有添加任何自定义字段。 最佳答案 如果您想允许额外的参数,您可以在ApplicationController中使用beforefilter,因为Rails4将参数
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
我意识到这可能是一个非常基本的问题,但我现在已经花了几天时间回过头来解决这个问题,但出于某种原因,Google就是没有帮助我。(我认为部分问题在于我是一个初学者,我不知道该问什么......)我也看过O'Reilly的RubyCookbook和RailsAPI,但我仍然停留在这个问题上.我找到了一些关于多态关系的信息,但它似乎不是我需要的(尽管如果我错了请告诉我)。我正在尝试调整MichaelHartl'stutorial创建一个包含用户、文章和评论的博客应用程序(不使用脚手架)。我希望评论既属于用户又属于文章。我的主要问题是:我不知道如何将当前文章的ID放入评论Controller。
我在新的Debian6VirtualBoxVM上安装RVM时遇到问题。我已经安装了所有需要的包并使用下载了安装脚本(curl-shttps://rvm.beginrescueend.com/install/rvm)>rvm,但以单个用户身份运行时bashrvm我收到以下错误消息:ERROR:Unabletocheckoutbranch.安装在这里停止,并且(据我所知)没有安装RVM的任何文件。如果我以root身份运行脚本(对于多用户安装),我会收到另一条消息:Successfullycheckedoutbranch''安装程序继续并指示成功,但未添加.rvm目录,甚至在修改我的.bas
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
本教程将在Unity3D中混合Optitrack与数据手套的数据流,在人体运动的基础上,添加双手手指部分的运动。双手手背的角度仍由Optitrack提供,数据手套提供双手手指的角度。 01 客户端软件分别安装MotiveBody与MotionVenus并校准人体与数据手套。MotiveBodyMotionVenus数据手套使用、校准流程参照:https://gitee.com/foheart_1/foheart-h1-data-summary.git02 数据转发打开MotiveBody软件的Streaming,开始向Unity3D广播数据;MotionVenus中设置->选项选择Unit
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co