目录

对于SQL和索引的优化问题,我们会使用explain去分析SQL语句。但是真正的企业级项目有成千上万条SQL,我们不可能从头开始一条一条explain去分析。我们从什么地方可以获取那些运行时间长,耗性能的SQL??
当我们去分析项目所涉及的业务的sql效率的时候,应该打开慢查询日志,根据具体的业务、具体的并发量,来预估一个时间上限,整个查询是不能超过这个上限的,设置好后开启业务,压测过程中我们会发现如果哪些sql的查询超过我们预测的时间,那么这些sql都会被记录在慢查询日志当中,然后使用explain分析这些耗时的语句,判断为什么效率低下。就可以知道索引有没有用,或者是没有建索引需要加索引(主键、unique还是二级索引),或者是索引使用到了,但是由于表的数据量太大,花费的时间就是很长,那么此时我们可以把表分成多个小表等,再看有没有分组排序,如果有where又有分组排序,要考虑加联合索引。
慢查询日志相关参数:show variables like '%slow_query%';(MySQL定义的很多的全局的开关,都是在全局变量中存储,可以用show/set variables查看或者设置全局变量的值)
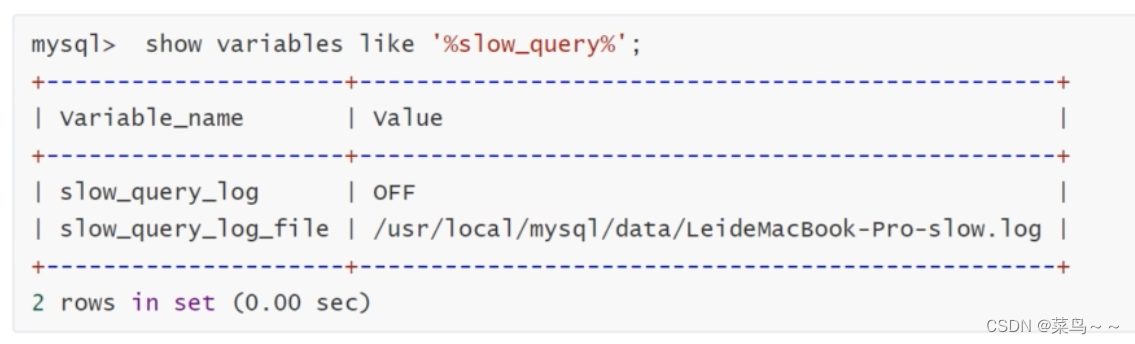
慢查询日志开关默认是关闭的
慢查询日志的路径:默认在/var/lib/mysql/下
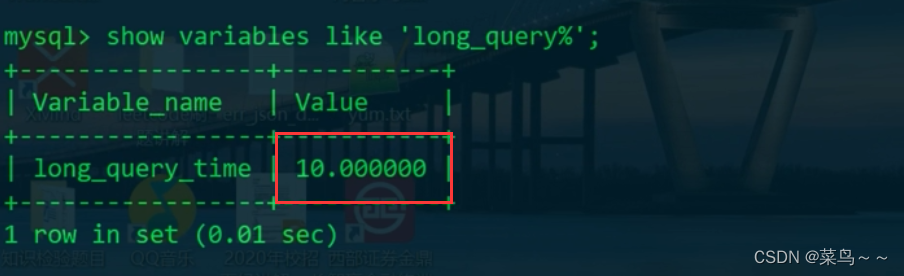
慢查询日志记录了包含所有执行时间超过参数long_query_time(单位:秒)所设置值的SQL语句的日志,在MySQL上用命令可以查看,如下:
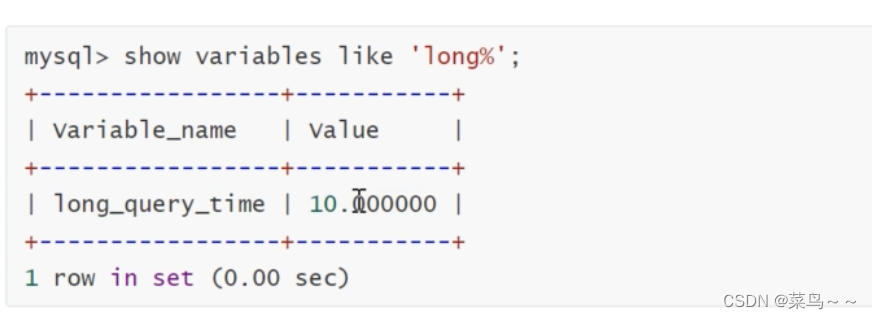
这个值是可以修改的,如下:

现在修改成超过1秒的SQL都会被记录在慢查询日志中!可以设置成0.01秒,表示10毫秒。
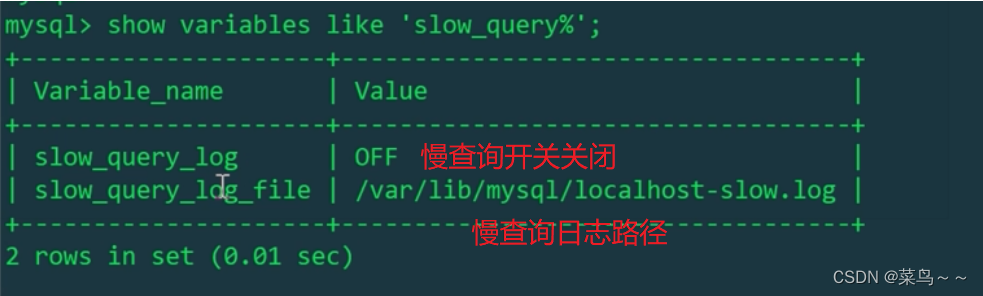

在打开慢查询日志开关的时候,报错表示slow_query_log是一个global的变量(也有只影响当前session的变量,如:long_query_time 、profiling),修改后会影响所有的session,即影响所有正在访问当前MySQL server的客户端。
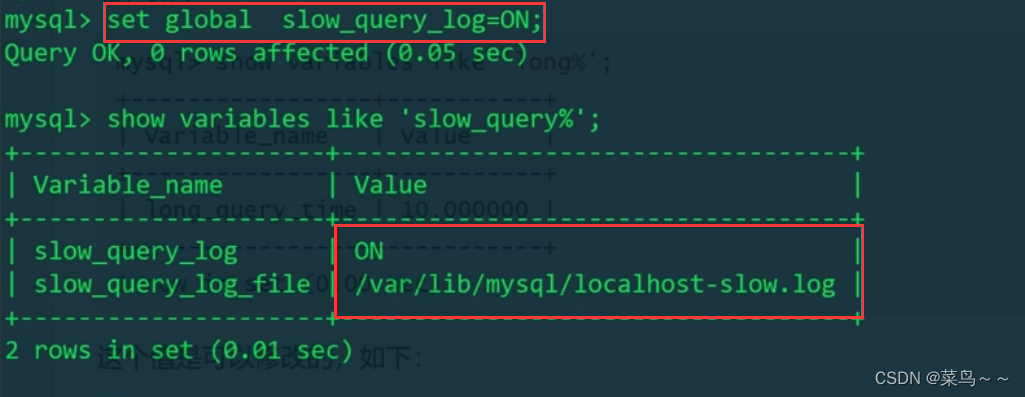
打开慢查询日志开关成功!
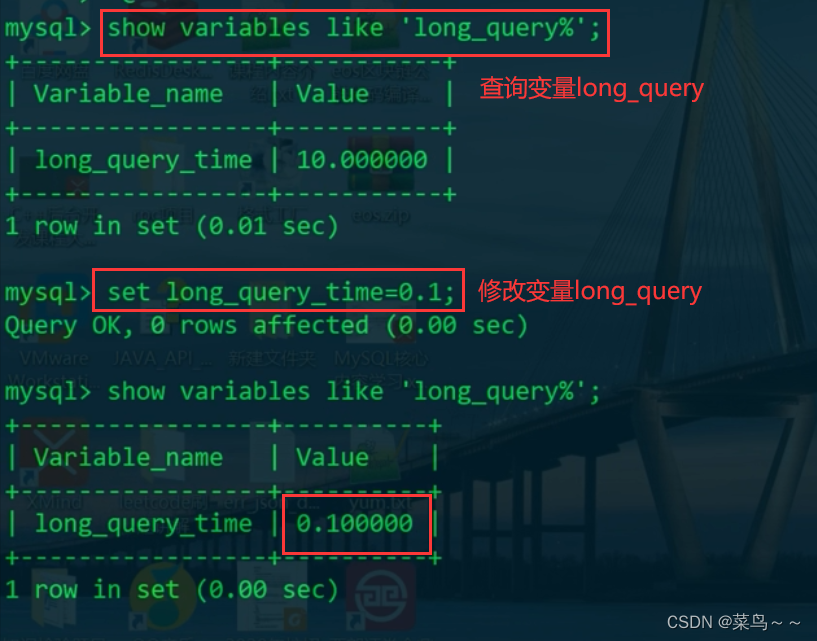
查看另一个session
发现还是默认的10s,故long_query_time只影响当前session
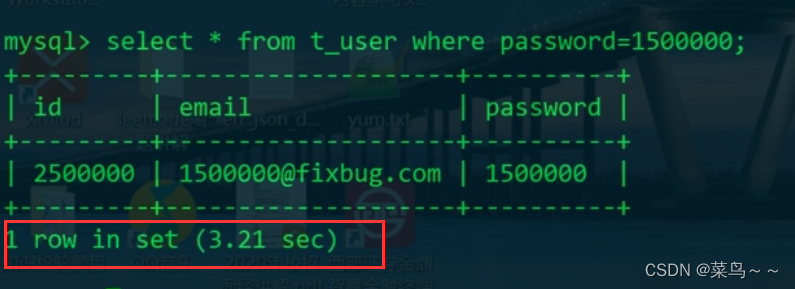
已经超过我们设置的long_query_time=0.1s
慢查询日志路径:/var/lib/mysql/

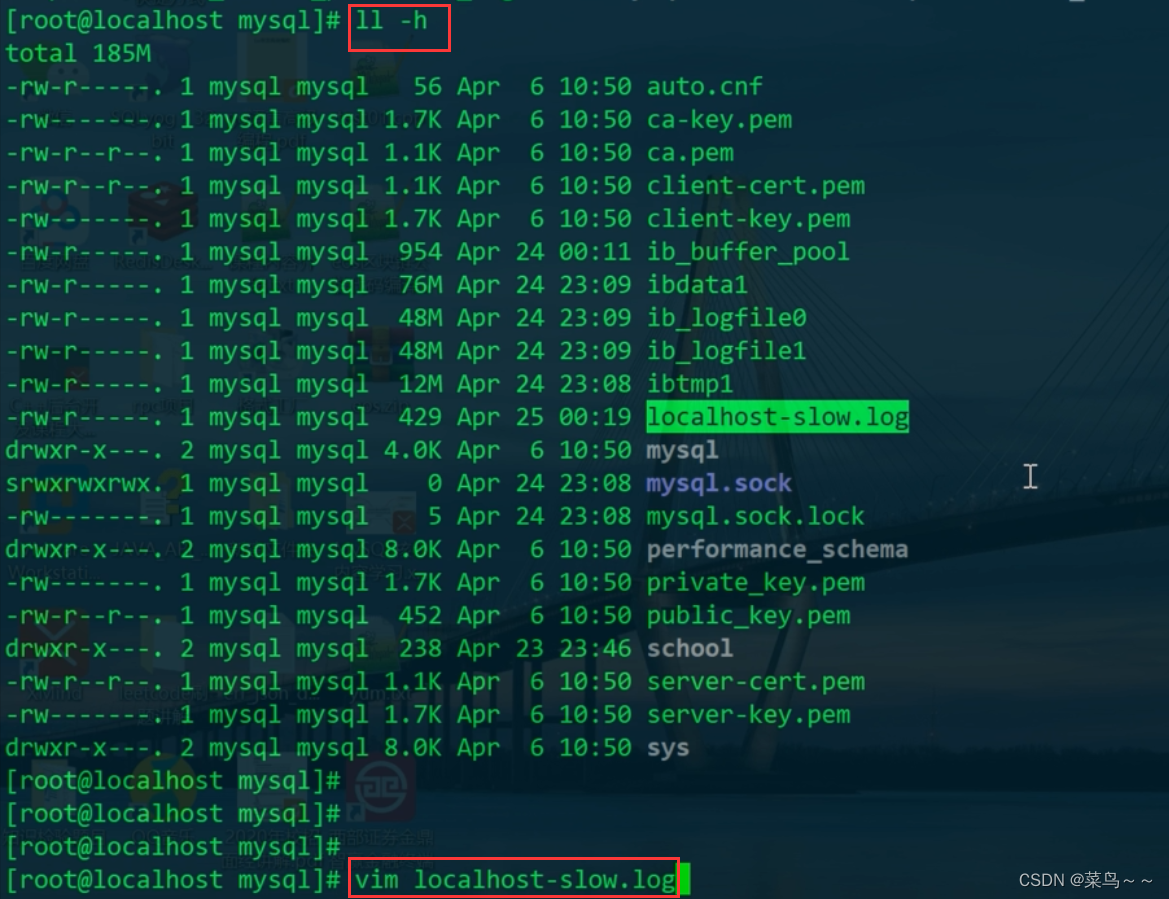
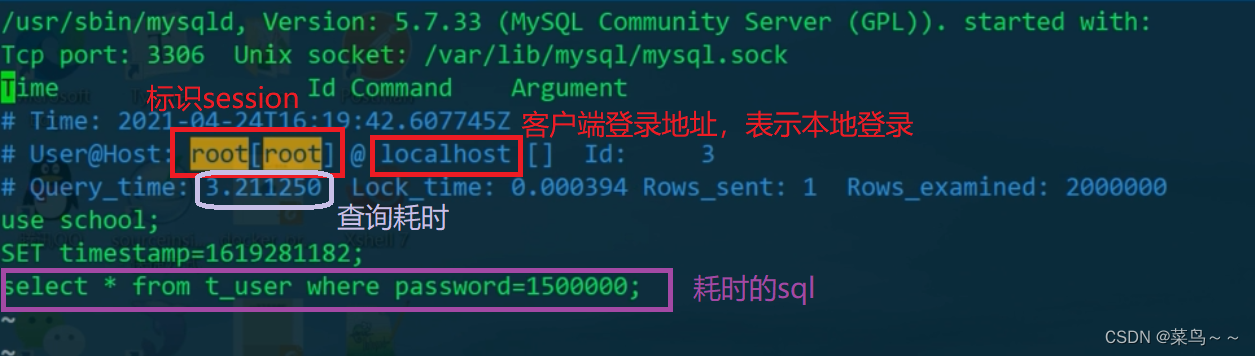

原来是做了整表搜索,把主键索引树整个扫了一遍。然后再一看paswd作为过滤条件,应该设置索引,即使设置索引了再查看还是用不到索引,然后又发现因为passwd是字符串格式涉及了类型转换,所以用不到索引,正确的sql应该是下面这条语句。

再来总结刚开始这个问题


接下来可以举例子,比如我在做一个业务的时候用到了where过滤条件外加order by,然后用explain分析后有using filesort,涉及了外部排序,为什么会涉及外部排序呢?因为我们数据和索引都是在磁盘上放着呢,如果没有建立合适的索引的话,我们要做order by只能进行外部排序了,这就比较耗时了,然后我试着用where的过滤条件和order by排序的字段建立了联合索引。。。
然后再和和前一篇博客所讲的各种各样出问题的索引结合起来回答,比如类型强转、过滤条件用了MySQL的函数都用不到索引,要考虑进去优化等等。参考回答:MySQL索引常见问题
MySQL一般只显示小数点后两位时间
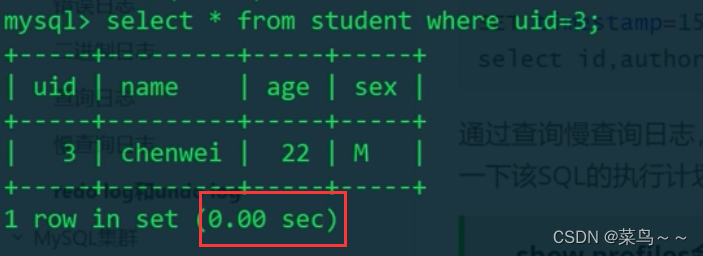
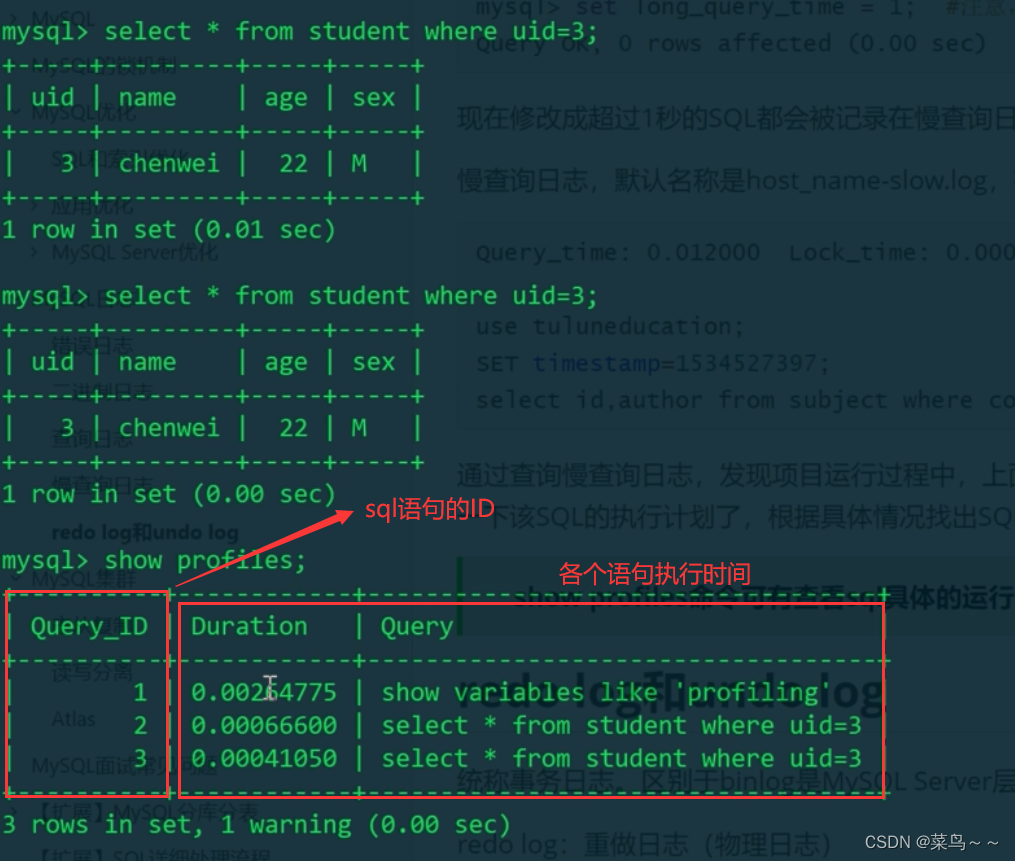
打开profiling开关,可以显示更详细的时间
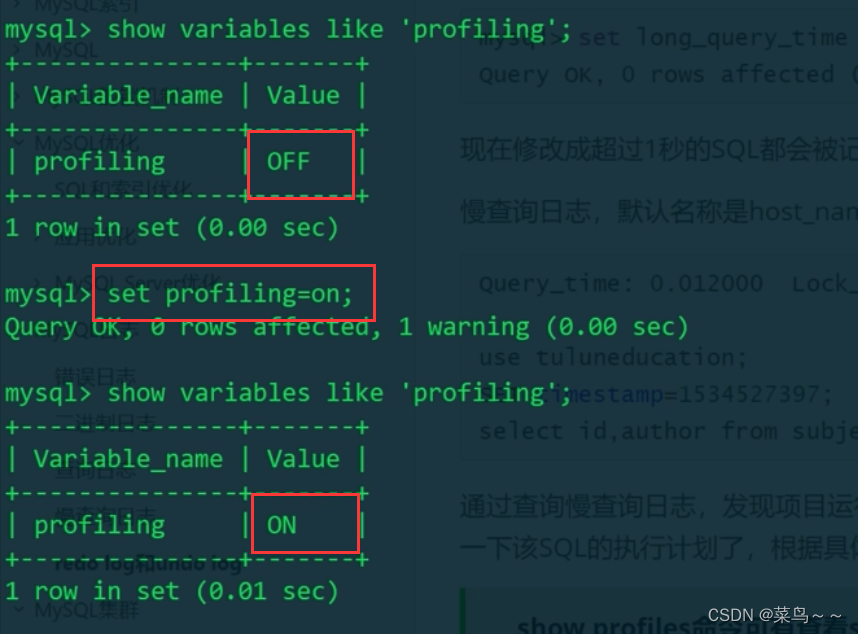
没有报错,说明profiling变量只影响当前session
我正在用Ruby编写一个简单的程序来检查域列表是否被占用。基本上它循环遍历列表,并使用以下函数进行检查。require'rubygems'require'whois'defcheck_domain(domain)c=Whois::Client.newc.query("google.com").available?end程序不断出错(即使我在google.com中进行硬编码),并打印以下消息。鉴于该程序非常简单,我已经没有什么想法了-有什么建议吗?/Library/Ruby/Gems/1.8/gems/whois-2.0.2/lib/whois/server/adapters/base.
我知道我可以指定某些字段来使用pluck查询数据库。ids=Item.where('due_at但是我想知道,是否有一种方法可以指定我想避免从数据库查询的某些字段。某种反拔?posts=Post.where(published:true).do_not_lookup(:enormous_field) 最佳答案 Model#attribute_names应该返回列/属性数组。您可以排除其中一些并传递给pluck或select方法。像这样:posts=Post.where(published:true).select(Post.attr
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
我正在尝试查询我的Rails数据库(Postgres)中的购买表,我想查询时间范围。例如,我想知道在所有日期的下午2点到3点之间进行了多少次购买。此表中有一个created_at列,但我不知道如何在不搜索特定日期的情况下完成此操作。我试过:Purchases.where("created_atBETWEEN?and?",Time.now-1.hour,Time.now)但这最终只会搜索今天与那些时间的日期。 最佳答案 您需要使用PostgreSQL'sdate_part/extractfunction从created_at中提取小时
我看到其他人也遇到过类似的问题,但没有一个解决方案对我有用。0.3.14gem与其他gem文件一起存在。我已经完全按照此处指示完成了所有操作:https://github.com/brianmario/mysql2.我仍然得到以下信息。我不知道为什么安装程序指示它找不到include目录,因为我已经检查过它存在。thread.h文件存在,但不在ruby目录中。相反,它在这里:C:\RailsInstaller\DevKit\lib\perl5\5.8\msys\CORE\我正在运行Windows7并尝试在Aptana3中构建我的Rails项目。我的Ruby是1.9.3。$gemin
我在Rails上使用带有ruby的solr。一切正常,我只需要知道是否有任何现有代码来清理用户输入,比如以?开头的查询。或* 最佳答案 我不知道执行此操作的任何代码,但理论上可以通过查看parsingcodeinLucene来完成并搜索thrownewParseException(只有16个匹配!)。在实践中,我认为您最好只捕获代码中的任何solr异常并显示“无效查询”消息或类似信息。编辑:这里有几个“sanitizer”:http://pivotallabs.com/users/zach/blog/articles/937-s
我正在为锦标赛开发一个Rails应用程序。我在这个查询中使用了三个模型:classPlayertruehas_and_belongs_to_many:tournamentsclassTournament:destroyclassPlayerMatch"Player",:foreign_key=>"player_one"belongs_to:player_two,:class_name=>"Player",:foreign_key=>"player_two"在tournaments_controller的显示操作中,我调用以下查询:Tournament.where(:id=>params
我想用sunspot重现以下原始solr查询q=exact_term_text:fooORterm_textv:foo*ORalternate_text:bar*但我无法通过标准的太阳黑子界面理解这是否可能以及如何实现,因为看起来:fulltext方法似乎不接受多个文本/搜索字段参数我不知道将什么参数作为第一个参数传递给fulltext,就好像我通过了"foo"或"bar"结果不匹配如果我传递一个空参数,我得到一个q=*:*范围过滤器(例如with(:term).starting_with('foo*')(顾名思义)作为过滤器查询应用,因此不参与评分。似乎可以手动编写字符串(或者可能使
如何在出现异常时指定全局救援,如果您将Sinatra用于API或应用程序,您将如何处理日志记录? 最佳答案 404可以在not_found方法的帮助下处理,例如:not_founddo'Sitedoesnotexist.'end500s可以通过调用带有block的错误方法来处理,例如:errordo"Applicationerror.Plstrylater."end错误的详细信息可以通过request.env中的sinatra.error访问,如下所示:errordo'Anerroroccured:'+request.env['si
我已经开始使用mysql2gem。我试图弄清楚一些基本的事情——其中之一是如何明确地执行事务(对于批处理操作,比如多个INSERT/UPDATE查询)。在旧的ruby-mysql中,这是我的方法:client=Mysql.real_connect(...)inserts=["INSERTINTO...","UPDATE..WHEREid=..",#etc]client.autocommit(false)inserts.eachdo|ins|beginclient.query(ins)rescue#handleerrorsorabortentirelyendendclient.commi