Github: https://github.com/linkedin/datahub
DataHub的前身是Linkedin为了提高工作效率,开发并开源的WhereHows。同样,WhereHows自身有很大的局限性:
不够重视数据之间的关系:元数据通常传达重要的关系(血统,所有权,依赖性等),这些关系可以提供强大的功能,如影响分析,数据汇总,更好的搜索相关性等。将所有这些关系建模为头等公民和支持对其进行有效的分析查询。
元数据获取倾向于推动,忽略特定域的拉动方式:一般获取元数据是采取拉取的方式,但开发和维护集中的特定域爬网程序中,让各个元数据提供者通过API或消息将信息推送到中央存储库具有更大的可伸缩性,这种基于推送的方法还可以确保更及时地反映新的和更新的元数据。
DataHub是由Linkedin开源的,官方喊出的口号为:The Metadata Platform for the Modern Data Stack 。目的就是为了解决多种多样数据生态系统的元数据管理问题,它提供元数据检索、数据发现、数据监测和数据监管能力,帮助大家解决数据管理的复杂性。常见的元数据管理系统有:Atlas,DataHub,Amundsen等

DataHub与Kafka有良好的融合性,Atlas对Hive有很好的支持性,Amundsen与数据调度平台Airflow有良好结合优势
支持数据源 :
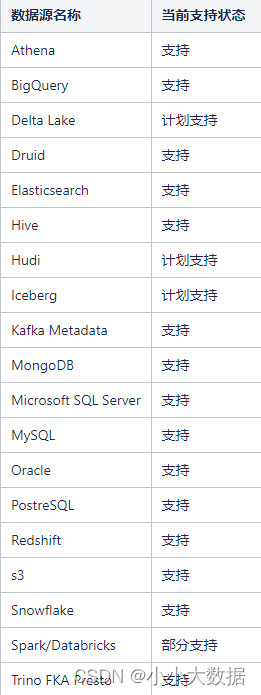
支持的BI工具:
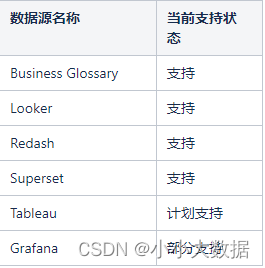
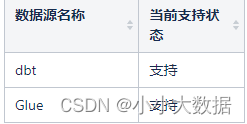
支持的ETL处理工具:
DataHub的WebUI界面可以看做是一系列紧密结合功能的组件形成,以组件和服务为应用程序的核心,该框架使我们能够分解不同的方面并将应用程序中的其他功能组合在一起。
1.搜索
类似于典型的搜索引擎体验,用户可以通过提供关键字列表来搜索一种或多种类型的实体。他们可以通过筛选多个方面来进一步对结果进行切片和切块。高级用户还可以利用运算符(例如OR,NOT和regex)执行复杂的搜索
2.浏览
DataHub中的数据实体可以以树状方式组织和浏览,其中每个实体都可以出现在树中的多个位置。这使用户能够以不同方式浏览同一目录
3.查看/编辑元数据
每个数据实体都有一个“配置文件页面”,其中显示了所有关联的元数据。eg:生成数据集的作业,从该数据集计算出的度量或图表等。对于可编辑的元数据,用户也可以直接通过UI更新。
首先明确:元数据也是数据的一种,也有不同类型,不同的摄取方式,基本信息等
在运行元数据摄入 job 之前,必须保证 DataHub 后台服务正在运行。DataHub提供两种形式的元数据摄取:API调用(离线)或Kafka流(实时)。
DataHub的API基于Rest.li,这是一种可扩展的,强类型的RESTful服务架构,已在LinkedIn上广泛使用。由于Rest.li使用Pegasus作为其接口定义,因此可以逐字使用上一节中定义的所有元数据模型。从API到存储需要多层转换的日子已经一去不复返,API和模型将始终保持同步
元数据摄入使用的是插件架构,摄入源有 32 种你仅需要安装所需的插件。比如:File,Mysql,Oracle,Kafka,Hive等
序号 插件名称 安装命令 提供功能
1 file included by default File source and sink
2 athena pip install 'acryl-datahub[athena]' AWS Athena source
3 bigquery pip install 'acryl-datahub[bigquery]' BigQuery source
4 bigquery-usage pip install 'acryl-datahub[bigquery-usage]' BigQuery usage statistics source
5 datahub-business-glossary no additional dependencies Business Glossary File source
6 dbt no additional dependencies dbt source
7 druid pip install 'acryl-datahub[druid]' Druid Source
8 feast pip install 'acryl-datahub[feast]' Feast source
9 glue pip install 'acryl-datahub[glue]' AWS Glue source
10 hive pip install 'acryl-datahub[hive]' Hive source
11 kafka pip install 'acryl-datahub[kafka]' Kafka source
12 kafka-connect pip install 'acryl-datahub[kafka-connect]' Kafka connect source
13 ldap pip install 'acryl-datahub[ldap]' (extra requirements) LDAP source
14 looker pip install 'acryl-datahub[looker]' Looker source
15 lookml pip install 'acryl-datahub[lookml]' LookML source, requires Python 3.7+
16 mongodb pip install 'acryl-datahub[mongodb]' MongoDB source
17 mssql pip install 'acryl-datahub[mssql]' SQL Server source
18 mysql pip install 'acryl-datahub[mysql]' MySQL source
19 mariadb pip install 'acryl-datahub[mariadb]' MariaDB source
20 openapi pip install 'acryl-datahub[openapi]' OpenApi Source
21 oracle pip install 'acryl-datahub[oracle]' Oracle source
22 postgres pip install 'acryl-datahub[postgres]' Postgres source
23 redash pip install 'acryl-datahub[redash]' Redash source
24 redshift pip install 'acryl-datahub[redshift]' Redshift source
25 sagemaker pip install 'acryl-datahub[sagemaker]' AWS SageMaker source
26 snowflake pip install 'acryl-datahub[snowflake]' Snowflake source
27 snowflake-usage pip install 'acryl-datahub[snowflake-usage]' Snowflake usage statistics source
28 sql-profiles pip install 'acryl-datahub[sql-profiles]' Data profiles for SQL-based systems
29 sqlalchemy pip install 'acryl-datahub[sqlalchemy]' Generic SQLAlchemy source
30 superset pip install 'acryl-datahub[superset]' Superset source
31 trino pip install 'acryl-datahub[trino] Trino source
32 starburst-trino-usage pip install 'acryl-datahub[starburst-trino-usage]' Starburst Trino usage statistics source
序号 插件名称 安装命令 提供功能
1 file included by default File source and sink
2 console included by default Console sink
3 datahub-rest pip install 'acryl-datahub[datahub-rest]' DataHub sink over REST API
4 datahub-kafka pip install 'acryl-datahub[datahub-kafka]' DataHub sink over Kafka
**File:**将元数据输出到文件。使用 File 汇可以将源数据源的处理和推送从 DataHub 解耦。也适合于调试目的
**DataHub Rest:**使用 GMS Rest 接口将元数据推送到 DataHub。
**DataHub Kafka:**通过发布消息到 Kafka 将元数据推送至 DataHub,异步的可以处理更高的流量。
**Console:**将元数据事件输出到标准输出。用于试验和调试。
从 MySQL 获取元数据使用 Rest 接口将数据存储 DataHub
(datahub) [root@home datahub]# cat mysql_to_datahub_rest.yml
# A sample recipe that pulls metadata from MySQL and puts it into DataHub
# using the Rest API.
source:
type: mysql
config:
username: root
password: 123456
database: cnarea20200630
transformers:
- type: "fully-qualified-class-name-of-transformer"
config:
some_property: "some.value"
sink:
type: "datahub-rest"
config:
server: "http://home:8080"
# datahub ingest -c mysql_to_datahub_rest.yml
一旦摄取并存储了元数据,如何有效地处理原始和派生的元数据就很重要。DataHub旨在支持对大量元数据的四种常见查询类型:
面向文档的查询
面向图的查询
涉及联接的复杂查询
全文搜索
综上,对市面上常见的元数据治理工具:Atlas(对hive有非常好的支持,但是部署起来非常的吃力),Amundsen(是一个新兴的框架,还没有release版本,未来可能会发展起来还需要慢慢观察),DataHub是目前我们实时数据治理的最佳选择,虽然目前DataHub的相关的资料还较少,但整体上我个人还是看好DataHub的发展的,毕竟Linkedin的Kafka就是一款 很好的产品哦~~~
#启动Docker
systemctl start docker
#安装DataHub
cd /usr/local
yum -y install git
git --version
git clone git://github.com/linkedin/datahub.git
cd /usr/local/docker
source ./quickstart.sh
#扩展
python3 -m pip install --upgrade pip wheel setuptools
python3 -m pip uninstall datahub acryl-datahub || true
python3 -m pip install --upgrade acryl-datahub
datahub version
datahub docker quickstart
参考文档:
DataHub官方文档
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po
我打算为ruby脚本创建一个安装程序,但我希望能够确保机器安装了RVM。有没有一种方法可以完全离线安装RVM并且不引人注目(通过不引人注目,就像创建一个可以做所有事情的脚本而不是要求用户向他们的bash_profile或bashrc添加一些东西)我不是要脚本本身,只是一个关于如何走这条路的快速指针(如果可能的话)。我们还研究了这个很有帮助的问题:RVM-isthereawayforsimpleofflineinstall?但有点误导,因为答案只向我们展示了如何离线在RVM中安装ruby。我们需要能够离线安装RVM本身,并查看脚本https://raw.github.com/wayn
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我有一个奇怪的问题:我在rvm上安装了rubyonrails。一切正常,我可以创建项目。但是在我输入“railsnew”时重新启动后,我有“程序'rails'当前未安装。”。SystemUbuntu12.04ruby-v"1.9.3p194"gemlistactionmailer(3.2.5)actionpack(3.2.5)activemodel(3.2.5)activerecord(3.2.5)activeresource(3.2.5)activesupport(3.2.5)arel(3.0.2)builder(3.0.0)bundler(1.1.4)coffee-rails(
我刚刚为fedora安装了emacs。我想用emacs编写ruby。为ruby提供代码提示、代码完成类型功能所需的工具、扩展是什么? 最佳答案 ruby-mode已经包含在Emacs23之后的版本中。不过,它也可以通过ELPA获得。您可能感兴趣的其他一些事情是集成RVM、feature-mode(Cucumber)、rspec-mode、ruby-electric、inf-ruby、rinari(用于Rails)等。这是我当前用于Ruby开发的Emacs配置:https://github.com/citizen428/emacs
我有一个围绕一些对象的包装类,我想将这些对象用作散列中的键。包装对象和解包装对象应映射到相同的键。一个简单的例子是这样的:classAattr_reader:xdefinitialize(inner)@inner=innerenddefx;@inner.x;enddef==(other)@inner.x==other.xendenda=A.new(o)#oisjustanyobjectthatallowso.xb=A.new(o)h={a=>5}ph[a]#5ph[b]#nil,shouldbe5ph[o]#nil,shouldbe5我试过==、===、eq?并散列所有无济于事。
我有一些Ruby代码,如下所示:Something.createdo|x|x.foo=barend我想编写一个测试,它使用double代替block参数x,这样我就可以调用:x_double.should_receive(:foo).with("whatever").这可能吗? 最佳答案 specify'something'dox=doublex.should_receive(:foo=).with("whatever")Something.should_receive(:create).and_yield(x)#callthere
我正在尝试在我的centos服务器上安装therubyracer,但遇到了麻烦。$geminstalltherubyracerBuildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingtherubyracer:ERROR:Failedtobuildgemnativeextension./usr/local/rvm/rubies/ruby-1.9.3-p125/bin/rubyextconf.rbcheckingformain()in-lpthread...yescheckingforv8.h...no***e
我的最终目标是安装当前版本的RubyonRails。我在OSXMountainLion上运行。到目前为止,这是我的过程:已安装的RVM$\curl-Lhttps://get.rvm.io|bash-sstable检查已知(我假设已批准)安装$rvmlistknown我看到当前的稳定版本可用[ruby-]2.0.0[-p247]输入命令安装$rvminstall2.0.0-p247注意:我也试过这些安装命令$rvminstallruby-2.0.0-p247$rvminstallruby=2.0.0-p247我很快就无处可去了。结果:$rvminstall2.0.0-p247Search