
在本教程中,我们将部署一个 metricbeat 来监控正在运行的容器的健康状况和系统指标。
一个常见的问题,但很少有人回答。 首先,无论我们部署的是 docker 容器还是老式的金属箱(即物理服务器),监控它们的健康状况至关重要。 最大的问题是,当我们在现场运行多台服务器时,识别哪台服务器出现问题的效率如何? 或者确定特定服务器何时崩溃有多容易? 答案可以在监控数据中找到(如果我们一开始就收集过)。
基于经验和团队文化,管理员通常编写自己的脚本或程序来收集服务器指标。 事实上,这是一种相当直接的方法,通常效果很好……直到部署了许多服务器实例。 脚本和程序是否可扩展以处理多服务器监控? 有多少定制以及监控不同系统(例如操作系统、数据库、应用程序服务器等)的难易程度。 如果以上问题的答案不是很确定,我们可能需要更好的解决方案。
来自 Elastic(该公司)的 Metricbeat 提供了一个单一的可执行文件,它有助于获取最常见的服务器/服务指标,包括主机(即操作系统级别)、数据库(mySQL、postgreSQL)、消息队列(kafka、rabbitMQ)等等。 与其它解决方案不同,Metricbeat 得到维护并积极开发以支持度量消费; 现在我们需要做的就是维护配置文件而不是我们脚本/程序中的逻辑。
我们首先来仿照之前的文章 “Elasticsearch:如何在 Docker 上运行 Elasticsearch 8.x 进行本地开发” 来创建我们的 docker-compose.yml 文件:
docker-compose.yml
version: "3.9"
services:
elasticsearch:
image: elasticsearch:8.6.2
container_name: elasticsearch
environment:
- discovery.type=single-node
- ES_JAVA_OPTS=-Xms1g -Xmx1g
- xpack.security.enabled=false
volumes:
- type: volume
source: es_data
target: /usr/share/elasticsearch/data
ports:
- target: 9200
published: 9200
networks:
- elastic
kibana:
image: kibana:8.6.2
container_name: kibana
ports:
- target: 5601
published: 5601
depends_on:
- elasticsearch
networks:
- elastic
metricbeat:
image: docker.elastic.co/beats/metricbeat:8.6.2
container_name: metricbeat
environment:
ELASTICSEARCH_HOSTS: http://elasticsearch:9200
volumes:
- metricbeat-data01:/usr/share/metricbeat/data
networks:
- elastic
depends_on:
- elasticsearch
volumes:
es_data:
driver: local
metricbeat-data01:
driver: local
networks:
elastic:
name: elastic
driver: bridge我们添加了一个名为 metricbeat 的服务,并通过环境变量 (ELASTICSEARCH_HOSTS) 声明了目标 elasticsearch 主机。 还为此服务 (metricbeat-data01) 添加了一个新卷(用于数据存储)。 该服务的网络应设置为 elastic,原因是该服务应与我们的目标 elasticsearch 主机/节点位于同一网络上。
让我们通过发出以下命令来启动服务:
docker-compose up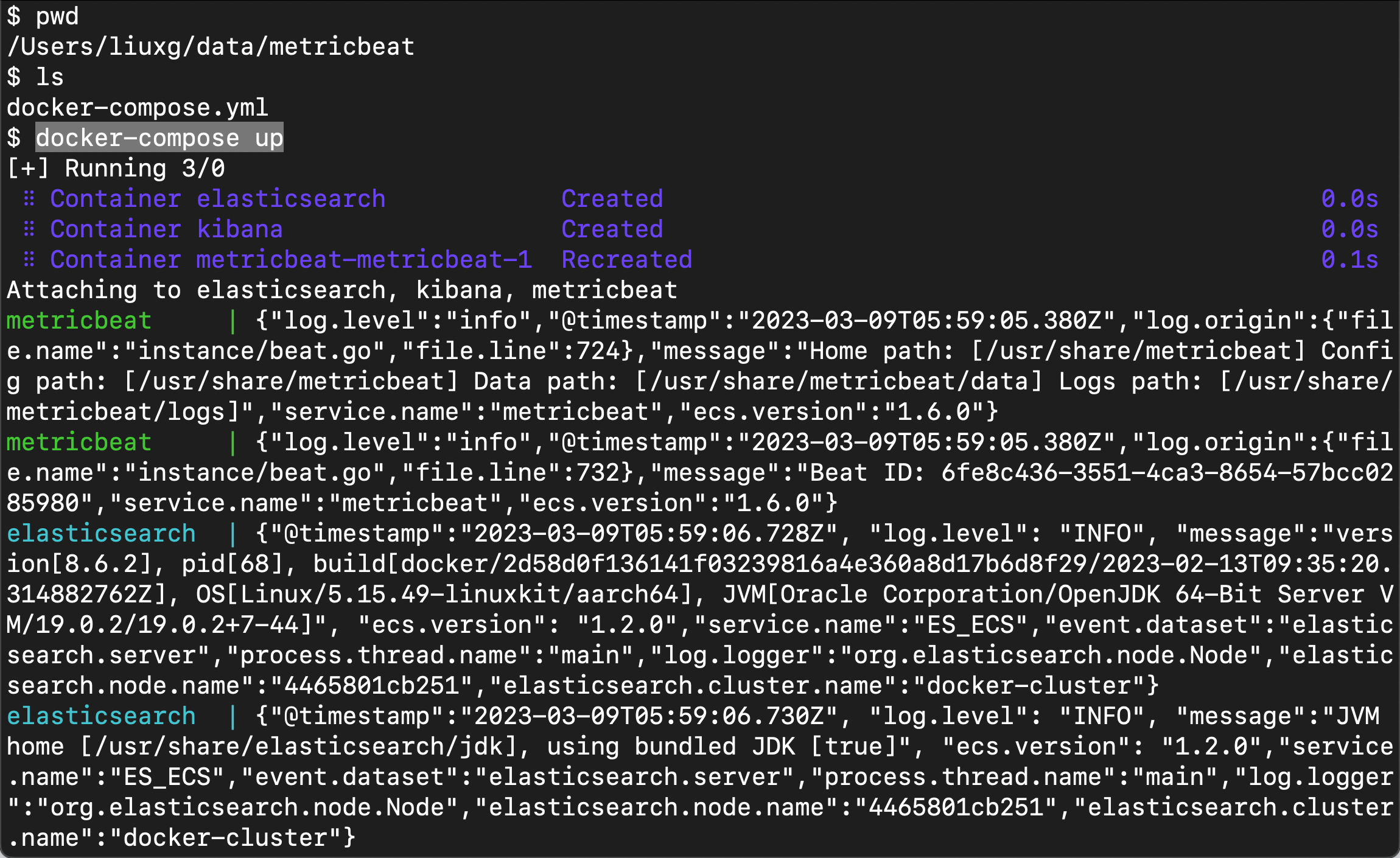
等所有的容器都启动后,我们可以使用如下的命令来进行查看:
docker ps$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
52072cc96dfc docker.elastic.co/beats/metricbeat:8.6.2 "/usr/bin/tini -- /u…" About a minute ago Up About a minute metricbeat
2511ea046940 kibana:8.6.2 "/bin/tini -- /usr/l…" 2 minutes ago Up About a minute 0.0.0.0:5601->5601/tcp kibana
4465801cb251 elasticsearch:8.6.2 "/bin/tini -- /usr/l…" 2 minutes ago Up About a minute 0.0.0.0:9200->9200/tcp, 9300/tcp elasticsearch从上面,我们可以看出来正在运行的容器: elasticsearch,kibana 及 metricbeat。
我们可以到 Kibana 中进行查看:
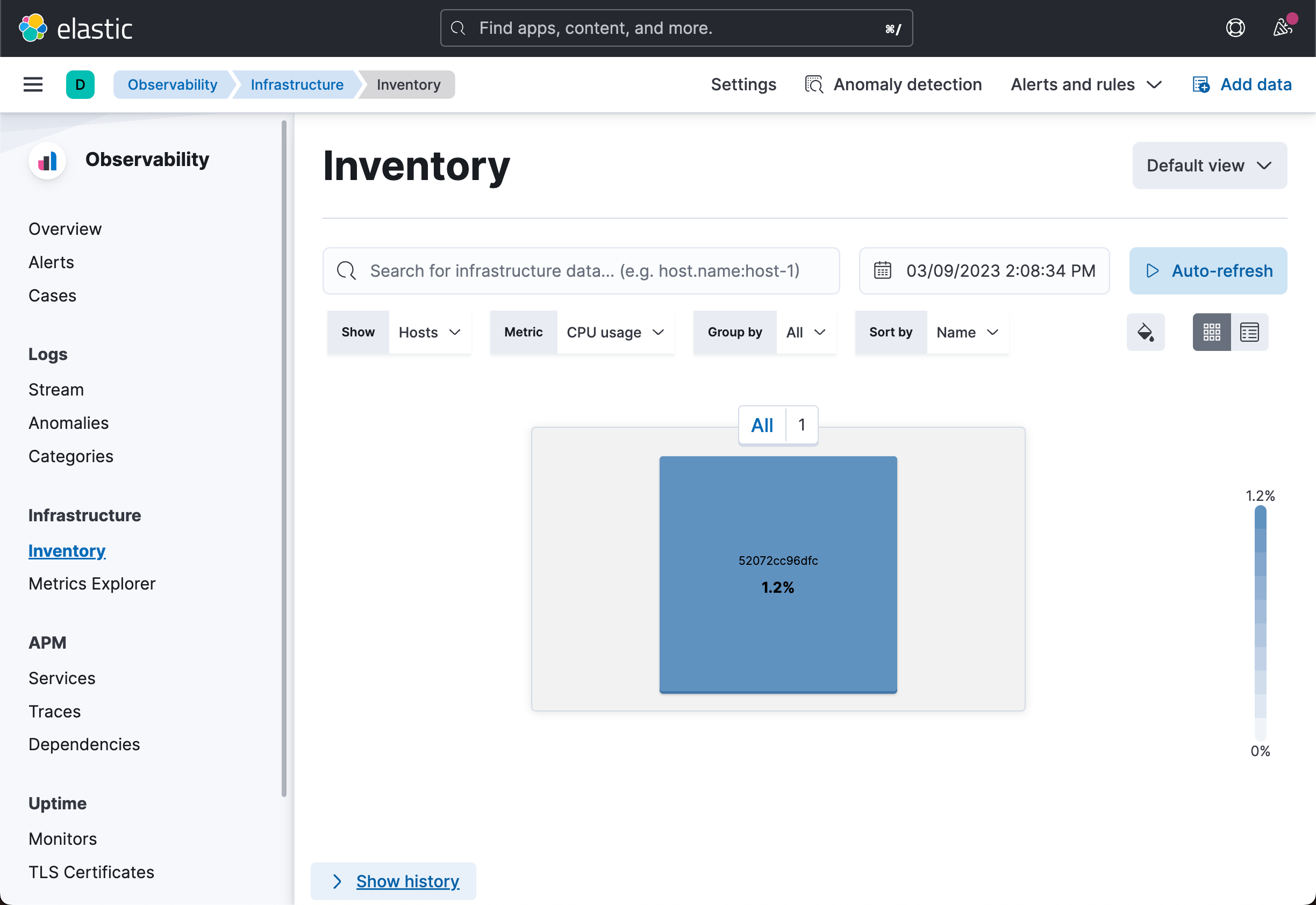
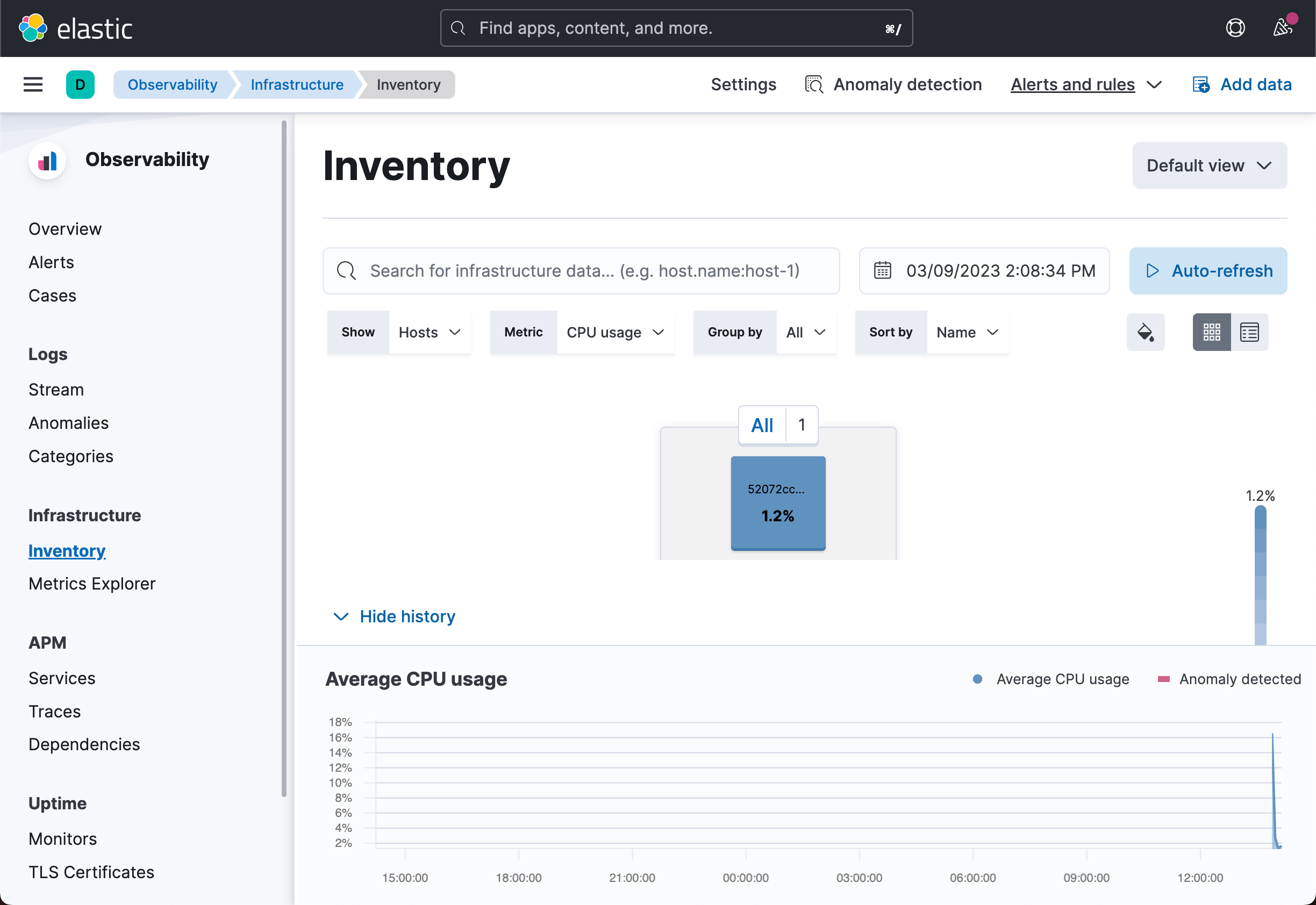
从上面,我们可以看出来被收集进来的指标信息。

从上面显示的信息中,我们可以看出来它收集的正是运行 Metricbeat 容器的指标。在默认的情况下,system 模块是被启动的。它会自动帮我们收集系统指标。有关 Metricbeat 的使用请阅读之前的文章 “Beats:Beats 入门教程 (二)”。
恭喜我们已经成功地在我们的集群上添加了 metricbeat 监控! 收集的数据可以显示在反映操作系统/主机指标的指标应用程序上,包括 CPU、内存、负载、网络、进程等。
显示操作系统/主机指标非常有用,但有时我们可能也想知道服务器/服务的行为方式。 举个例子,我们可以监控我们的 elasticsearch 节点的健康状况吗? 如果您现在点击 “Stack Monitoring” 应用程序,将显示此页面:



简单的意思是……没有可用的 Elasticsearch 监控数据 :(
对于现代版本的弹性堆栈,弹性搜索节点的监控建议启用名为“elasticsearch-xpack”的 metricbeat 模块。 那么什么是 metricbeat 模块??? 一个简单的句子——模块包含与目标服务器/服务对话的逻辑,并维护一组用于收集的指标的逻辑分组; 因此它就像一个配置管理器。
模块在 yml 文件中声明并存储在 {metricbeat_root}/modules.d 文件夹下。 elasticsearch-xpack.yml 示例如下:
elasticsearch-xpack.yml
# Module: elasticsearch
# Docs: https://www.elastic.co/guide/en/beats/metricbeat/main/metricbeat-module-elasticsearch.html
- module: elasticsearch
xpack.enabled: true
period: 10s
hosts: ["http://localhost:9200"]
#username: "user"
#password: "secret"对于大多数情况,我们会修改要收集的指标集(即指标集设置)、监控主机(例如 localhost:9200 或 node01:9200)并激活 xpack 监控功能(即 xpack.enabled)。
现在摆在我们面前的挑战是……如何更新 elasticsearch-xpack.yml 文件? 好吧……一种方法是我们启动服务,然后通过 telnet / ssh 进入 metricbeat 容器并更新配置文件。例如,我们可以这样来进入到容器中:
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
52072cc96dfc docker.elastic.co/beats/metricbeat:8.6.2 "/usr/bin/tini -- /u…" About an hour ago Up About an hour metricbeat
2511ea046940 kibana:8.6.2 "/bin/tini -- /usr/l…" About an hour ago Up About an hour 0.0.0.0:5601->5601/tcp kibana
4465801cb251 elasticsearch:8.6.2 "/bin/tini -- /usr/l…" About an hour ago Up About an hour 0.0.0.0:9200->9200/tcp, 9300/tcp elasticsearch
$ docker exec -it metricbeat /bin/bash
metricbeat@52072cc96dfc:~$ 这种方式可能是最简单的,但它根本不可扩展,并且引入了最终难以维护的手动操作。 一个不太脏的解决方案肯定是值得的。
就像我们之前讨论的那样,我们试图只维护配置文件而不是脚本/程序逻辑(也是手动操作)。 因此,针对上述挑战的更简洁的解决方案是使用更新的 metricbeat.yml 构建自定义 docker 镜像。
创建 metricbeat.yml 如下:
metricbeat.yml
metricbeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
processors:
- add_cloud_metadata: ~
- add_docker_metadata: ~
output.elasticsearch:
hosts: '${ELASTICSEARCH_HOSTS:elasticsearch:9200}'
username: '${ELASTICSEARCH_USERNAME:}'
password: '${ELASTICSEARCH_PASSWORD:}'
# enabled modules for monitoring (e.g. elasticsearch-xpack)
metricbeat.modules:
- module: elasticsearch
xpack.enabled: true
period: 10s
hosts: ["http://node01:9200"]$ pwd
/Users/liuxg/data/metricbeat
$ ls
docker-compose.yml metricbeat.yml我们声明要启用 elasticsearch 模块,目标主机是 elasticsearch:9200。 由于 hosts 配置是一个数组,因此可以仅设置 1 个 metricbeat 实例并使用多节点的指标。
接下来,让我们更新 docker-compose.yml 如下:
docker-compose.yml
version: "3.9"
services:
elasticsearch:
image: elasticsearch:8.6.2
container_name: elasticsearch
environment:
- discovery.type=single-node
- ES_JAVA_OPTS=-Xms1g -Xmx1g
- xpack.security.enabled=false
volumes:
- type: volume
source: es_data
target: /usr/share/elasticsearch/data
ports:
- target: 9200
published: 9200
networks:
- elastic
kibana:
image: kibana:8.6.2
container_name: kibana
ports:
- target: 5601
published: 5601
depends_on:
- elasticsearch
networks:
- elastic
metricbeat:
build: .
# image: docker.elastic.co/beats/metricbeat:8.6.2
container_name: metricbeat
environment:
ELASTICSEARCH_HOSTS: http://elasticsearch:9200
volumes:
- metricbeat-data01:/usr/share/metricbeat/data
networks:
- elastic
depends_on:
- elasticsearch
volumes:
es_data:
driver: local
metricbeat-data01:
driver: local
networks:
elastic:
name: elastic
driver: bridge配置文件的唯一变化是用 build 配置替换 image 配置。 build 只是意味着我们正在从本地 Dockerfile 配置构建自定义镜像。 Dockerfile 包含构建自定义镜像的步骤和我们的版本如下:
FROM docker.elastic.co/beats/metricbeat:8.6.2
COPY metricbeat.yml /usr/share/metricbeat/metricbeat.yml
USER root
RUN chown root /usr/share/metricbeat/metricbeat.yml$ pwd
/Users/liuxg/data/metricbeat
$ ls
Dockerfile docker-compose.yml metricbeat.yml这很简单,我们将基础 docker 镜像设置为 docker.elastic.co/beats/metricbeat:8.6.2。 然后我们将自定义的 metricbeat.yml 复制到镜像的 /usr/share/metricbeat 路径下。 最后使用 root 用户更改 metricbeat.yml 的访问权限并完成。
接下来是构建镜像,但是发出如下的命令:
如果一切顺利,我们的镜像很快就会建立起来了。
是时候启动服务并验证结果了:
docker-compose up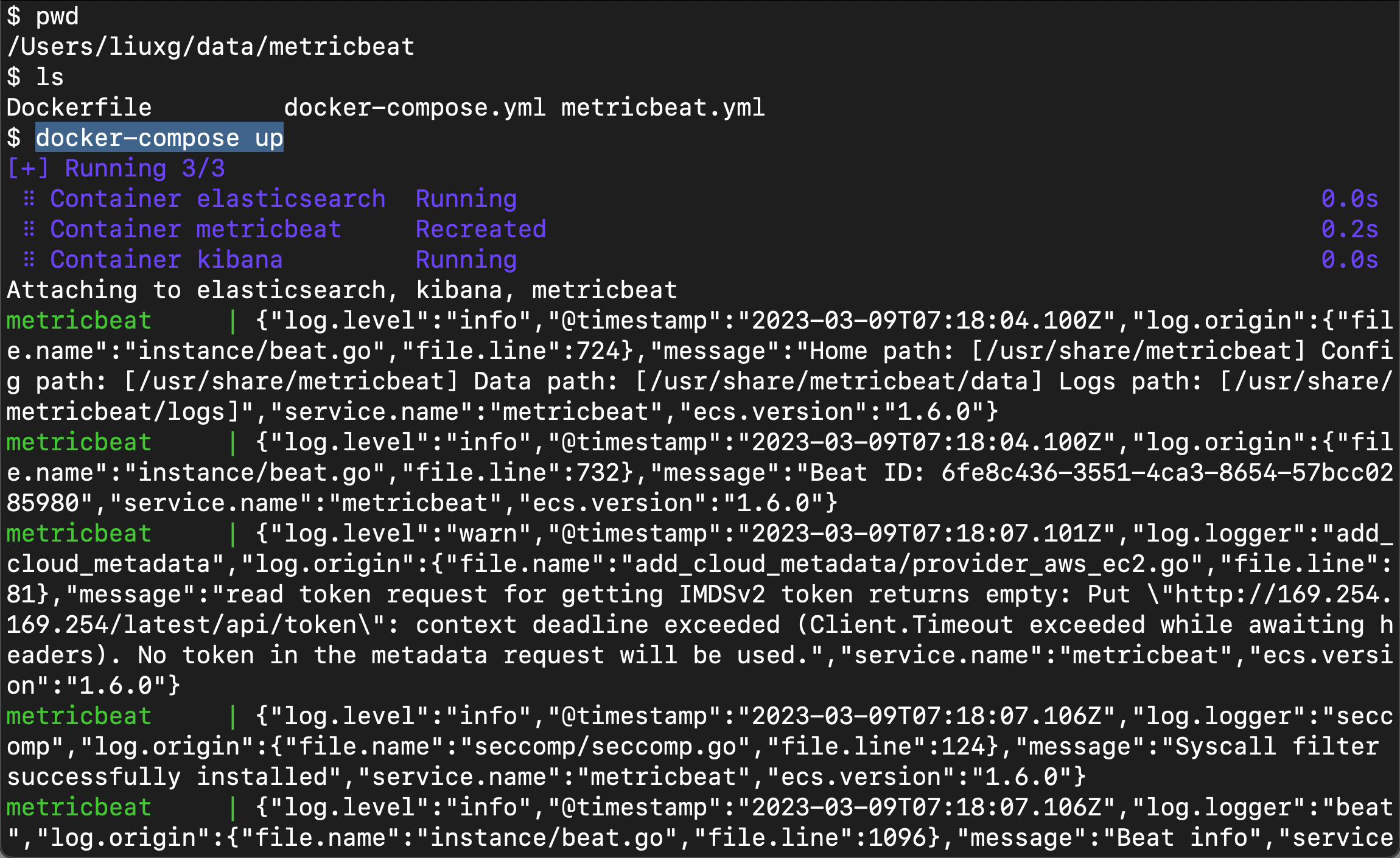
接下来,我们到 Kibana 中去查看:
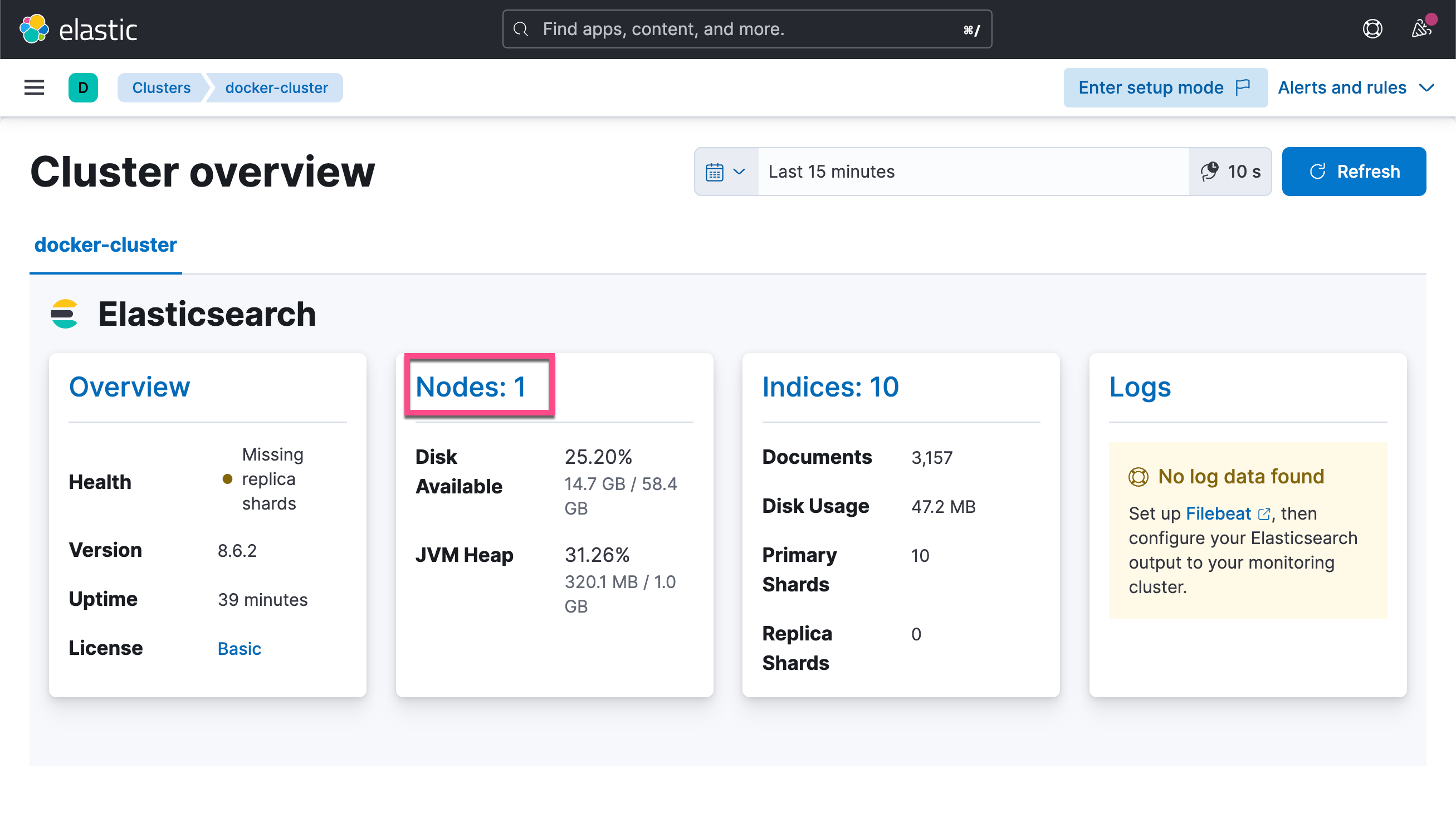
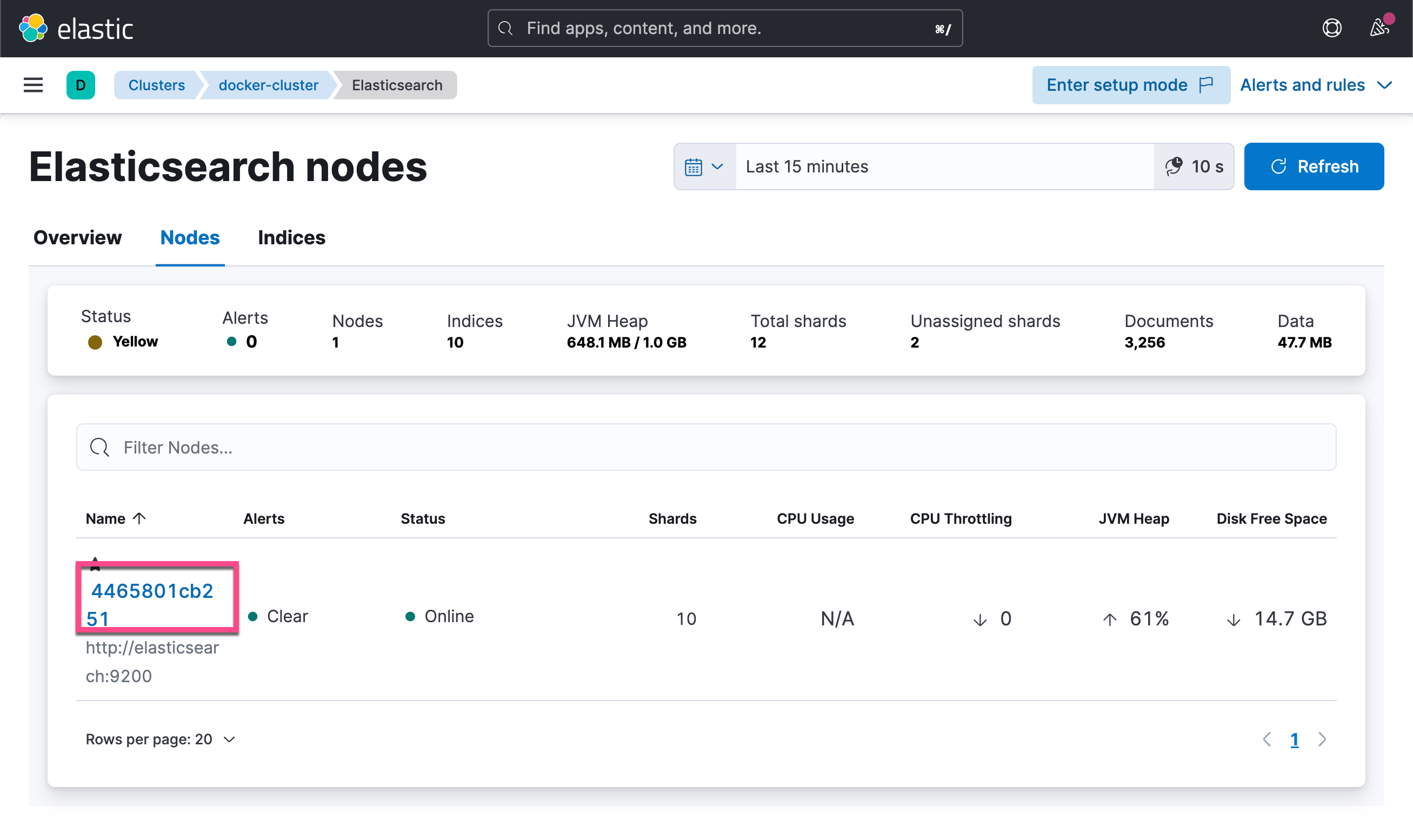 很显然,这次我们看到了不一样的结果。
很显然,这次我们看到了不一样的结果。
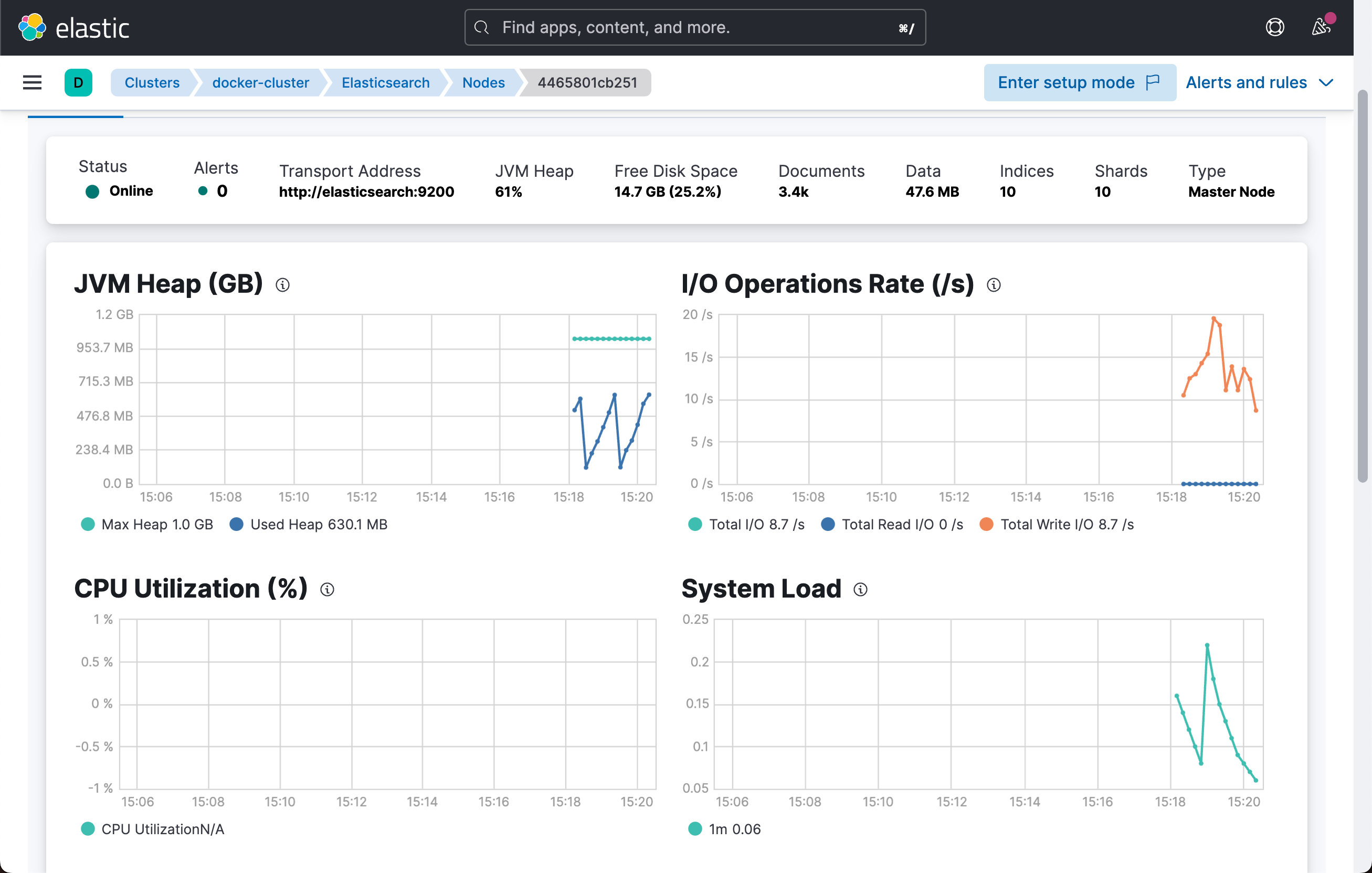
我们可以看到想要的指标信息。
Horray ~ 我们做到了,metricbeat 正在收集 elasticsearch 节点的指标。
我是Google云的新手,我正在尝试对其进行首次部署。我的第一个部署是RubyonRails项目。我基本上是在关注thisguideinthegoogleclouddocumentation.唯一的区别是我使用的是我自己的项目,而不是他们提供的“helloworld”项目。这是我的app.yaml文件runtime:customvm:trueentrypoint:bundleexecrackup-p8080-Eproductionconfig.ruresources:cpu:0.5memory_gb:1.3disk_size_gb:10当我转到我的项目目录并运行gcloudprevie
我可以在Azure网站上部署RubyonRails吗? 最佳答案 还没有。目前仅支持.NET和PHP。 关于ruby-on-rails-RubyonRails可以部署在Azure网站上吗?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/12964010/
1.错误信息:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:requestcanceledwhilewaitingforconnection(Client.Timeoutexceededwhileawaitingheaders)或者:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:TLShandshaketimeout2.报错原因:docker使用的镜像网址默认为国外,下载容易超时,需要修改成国内镜像地址(首先阿里
前置步骤我们都操作完了,这篇开始介绍jenkins的集成。话不多说,看操作1、登录进入jenkins后会让你选择安装插件,选择第一个默认的就行。安装完成后设置账号密码,重新登录。2、配置JDK和Git都需要执行路径,所以需要先把执行路径找到,先进入服务器的docker容器,2.1JDK的路径root@69eef9ee86cf:/usr/bin#echo$JAVA_HOME/usr/local/openjdk-82.2Git的路径root@69eef9ee86cf:/#whichgit/usr/bin/git3、先配置JDK和Git。点击:ManageJenkins>>GlobalToolCon
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
我认为我的问题最好用一个例子来描述。假设我有一个名为“Thing”的简单模型,它有一些简单数据类型的属性。像...Thing-foo:string-goo:string-bar:int这并不难。数据库表将包含具有这三个属性的三列,我可以使用@thing.foo或@thing.bar之类的东西访问它们。但我要解决的问题是当“foo”或“goo”不再包含在简单数据类型中时会发生什么?假设foo和goo代表相同类型的对象。也就是说,它们都是“Whazit”的实例,只是数据不同。所以现在事情可能看起来像这样......Thing-bar:int但是现在有一个新的模型叫做“Whazit”,看起来
Ocra无法处理需要“tk”的应用程序require'tk'puts'nope'用奥克拉http://github.com/larsch/ocra不起作用(如链接中的一个问题所述)问题:https://github.com/larsch/ocra/issues/29(Ocra是1.9的"new"rubyscript2exe,本质上它用于将rb脚本部署为可执行文件)唯一的问题似乎是缺少tcl的DLL文件我不认为这是一个问题据我所知,问题是缺少tk的DLL文件如果它们是已知的,则可以在执行ocra时将它们包括在内有没有办法知道tk工作所需的DLL依赖项? 最佳答
我有一个类unzipper.rb,它使用Rubyzip解压文件。在我的本地环境中,我可以成功解压缩文件,而无需使用require'zip'明确包含依赖项但是在Heroku上,我得到一个NameError(uninitializedconstantUnzipper::Zip)我只能通过使用明确的require来解决问题:为什么这在Heroku环境中是必需的,但在本地主机上却不是?我的印象是Rails自动需要所有gem。app/services/unzipper.rbrequire'zip'#OnlyrequiredforHeroku.Workslocallywithout!class
出于某种原因,heroku尝试要求dm-sqlite-adapter,即使它应该在这里使用Postgres。请注意,这发生在我打开任何URL时-而不是在gitpush本身期间。我构建了一个默认的Facebook应用程序。gem文件:source:gemcuttergem"foreman"gem"sinatra"gem"mogli"gem"json"gem"httparty"gem"thin"gem"data_mapper"gem"heroku"group:productiondogem"pg"gem"dm-postgres-adapter"endgroup:development,:t
不知何故,我似乎无法获得包含我的聚合的响应...使用curl它按预期工作:HBZUMB01$curl-XPOST"http://localhost:9200/contents/_search"-d'{"size":0,"aggs":{"sport_count":{"value_count":{"field":"dwid"}}}}'我收到回复:{"took":4,"timed_out":false,"_shards":{"total":5,"successful":5,"failed":0},"hits":{"total":90,"max_score":0.0,"hits":[]},"a