整理 | 彭慧中 责编 | 屠敏
出品 | CSDN(ID:CSDNnews)
如今,人工智能已经逐渐习惯充当人类生活中“副驾驶”位置上的角色。它帮助我们打扫卫生、撰写文稿、回复消息、路线导航…但在此之前,人工智能在改进代码方面还止步不前,以至于多少人还在为绞尽脑汁写代码而“秃头”?
现在,交给这个 AI 吧!
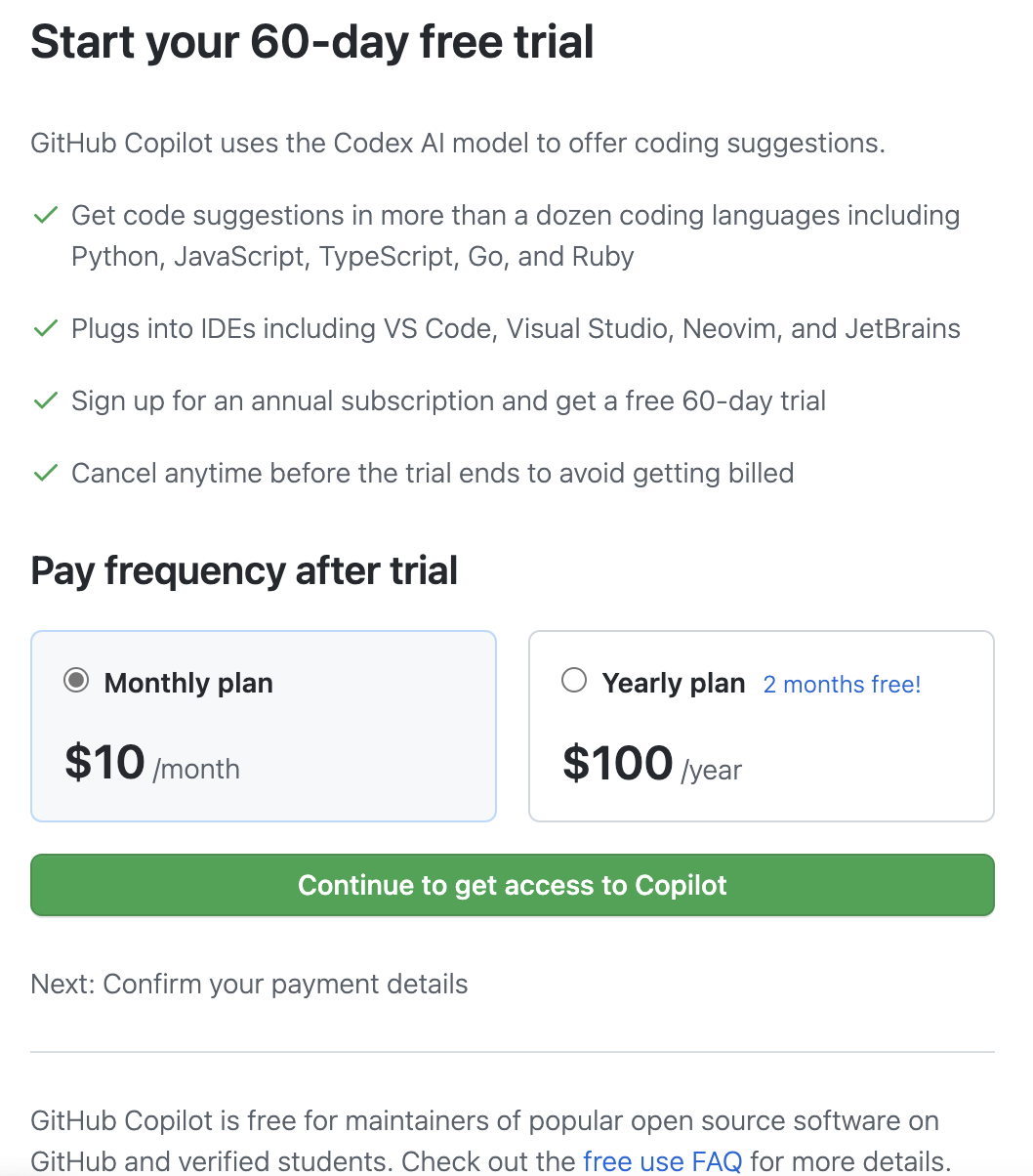
GitHub 于今天重磅宣布,其与 OpenAI 联合构建的 AI 自动编程工具 Copilot 正式发布,现以每月 10 美元(人民币约 67 元)或每年 100 美元(人民币约 669 元)的价格出售,并提供 60 天的免费试用期。
不过值得注意的是,收费群体也是有限制的,其中通过身份验证的学生和热门开源项目维护者可以免费使用。

GitHub Copilot 的到来,微软在背后立下了汗马之劳。它曾向研究公司 OpenAI 投资 10 亿美元,也推动了 GitHub 与 OpenAI 的合作,最终历经多年研发,GitHub Copilot 成功落地。
Copilot 建立在 OpenAI Codex 之上,也就是 OpenAI 的旗舰 GPT-3 语言生成算法的后代。它创造了历史上第一次人工智能可以被开发者充分地利用来完成代码。
GitHub 首席执行官托马斯·多姆克(Thomas Dohmke)表示:“就像编译器和开源的兴起一样,我们相信人工智能辅助编码将从根本上改变软件开发,为开发人员提供一种新工具,让他们更轻松、更快地编写代码,让他们的生活更快乐。”
在开发者圈中,其实很多人对于 GitHub Copilot 也并不陌生。
早在 2021 年 6 月,GitHub 便首次推出了测试版 Copilot,并将该工具描述为“AI配对程序员”。Copilot 可以为开发人员在 JetBrains IDE、Neovim 或 Microsoft Visual Studio Code 等集成开发环境 (IDE) 中编程时提供下一行的代码建议。除了提供代码建议外,它还可以在有需要时提出完整的方法和更复杂的算法。
众所周知,程序员的时薪很高,一般在 10 美元到 150 美元之间,只要能节省几个小时的编程时间或稍稍提高一些开发速度,就能产生不低的效益。尤其是对于一些有着丰富经验的程序员来说,Copilot 意味着更加容易的跨界,在它的加持下,开发者学习 Rust 时往往不会再被劝退,用起 C++ 也不会再那么令人爱恨交加。

那么,正式向开发者们提供的 Copilot 究竟有哪些必杀技?
GitHub 官方发布了以下三点介绍:
官方代码示例:
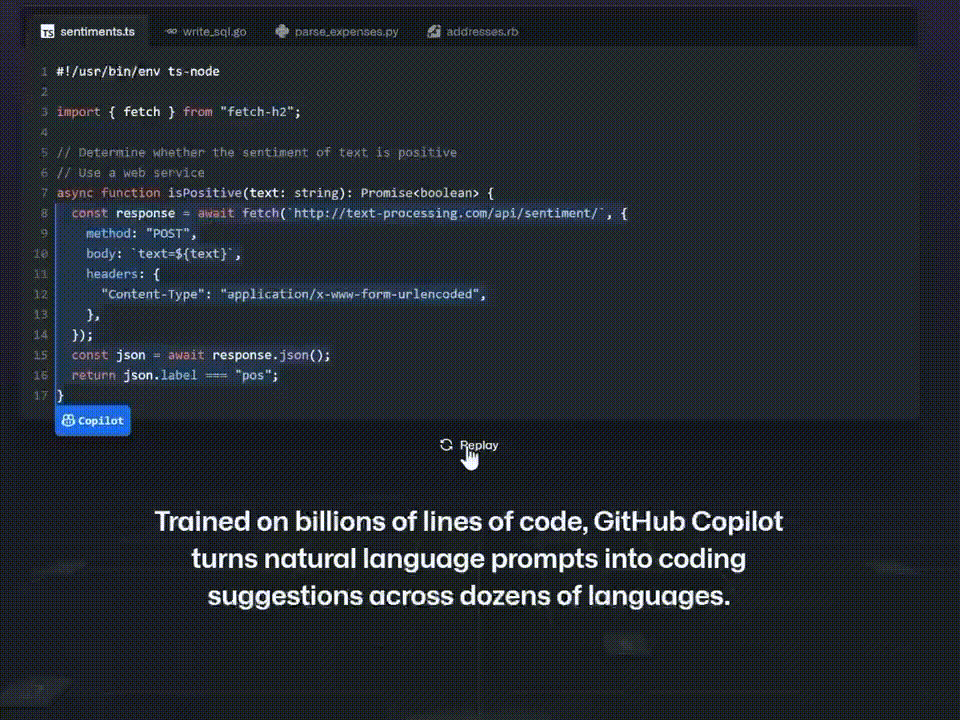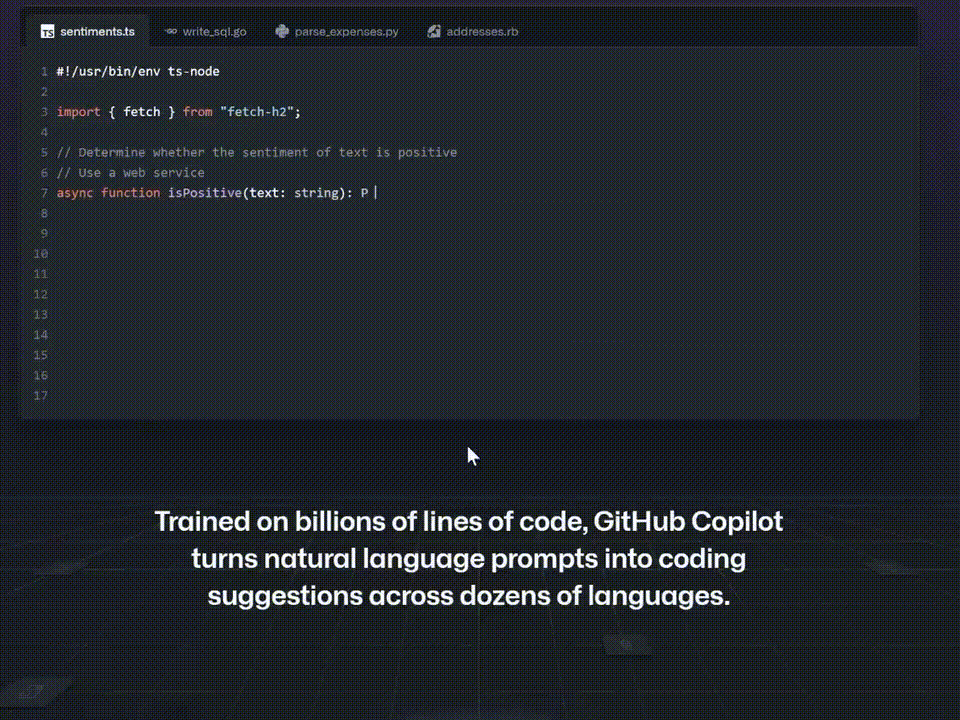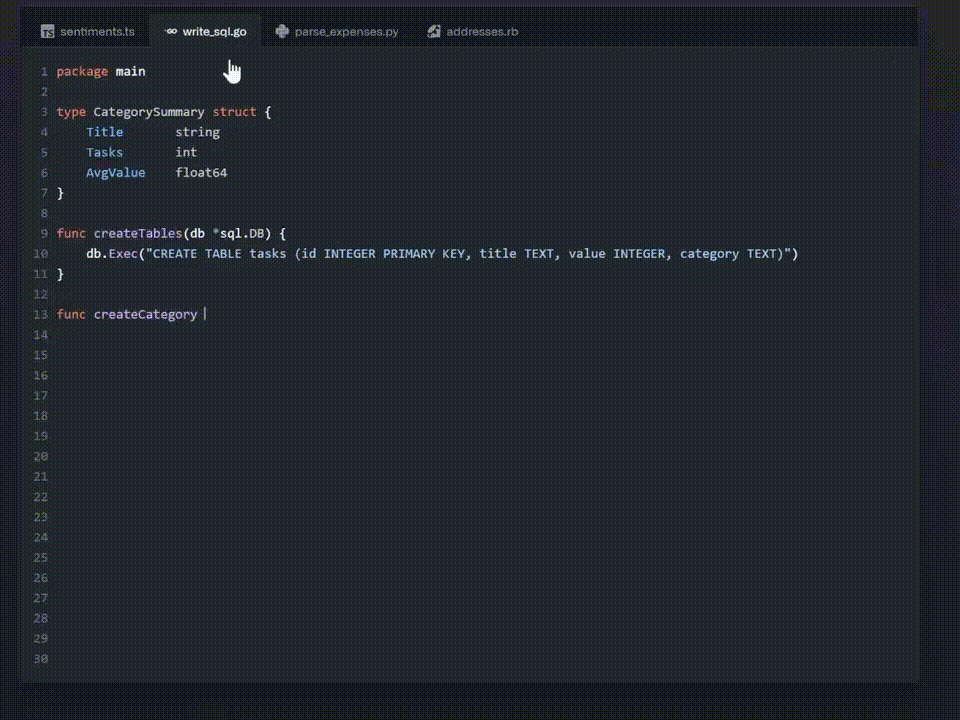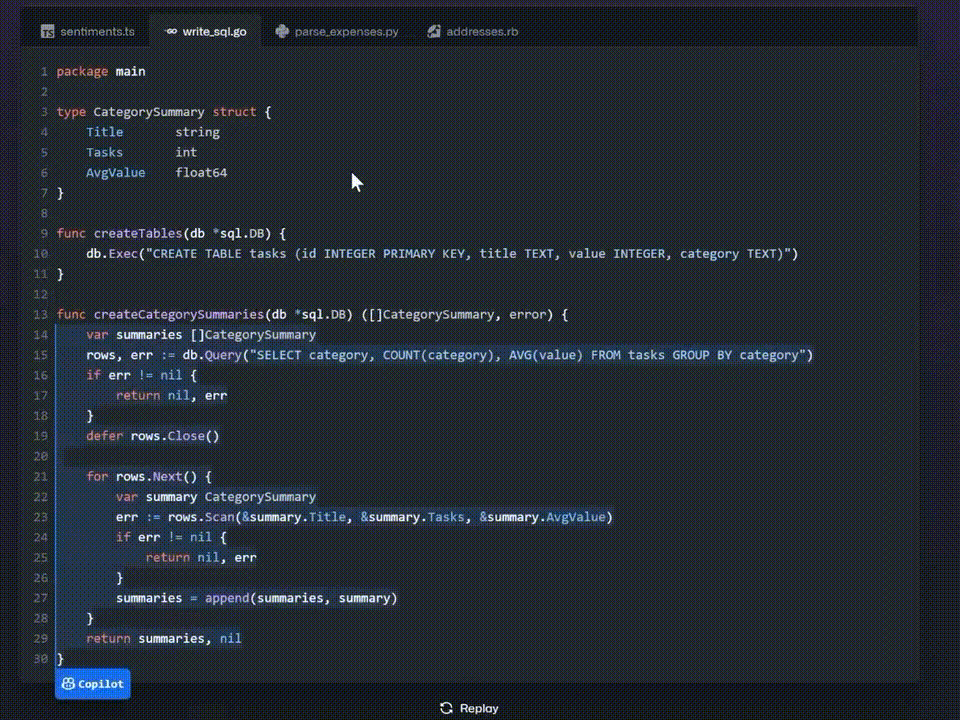
根据 GitHub 官方统计数据显示,在过去的 12 个月中,已有超过 120 万开发人员注册使用 GitHub Copilot 预览版。在启用 GitHub Copilot 的文件中,GitHub 表示现在近 40% 的代码是由 Copilot 编写的。

在宣布付费之后,Copilot 的最新声明也在 HN(https://news.ycombinator.com/item?id=31825742)上引来了六百多位开发者的热评,针对官方说得天花乱坠的功能,在开发者来看,是否真的好用?

一位开发者表示:“Copilot 对于快速编写脚本是非常有价值的,尤其是面对不太懂的语言时,能更快地拼凑出一些能用的东西。但是在写更复杂的代码时,如果不注意的话,它容易产生一些小的 Bug,让人非常抓狂。单纯从节省的时间来看,我认为对于我的雇主来说,10 美元/月是非常值得的(每天只需要节省几分钟就值得了)。我很高兴看到 Copilot 在未来的改进。”

另一位已经使用 Copilot 几个月了开发者也表示,尽管 Copilot 会犯很多错误,但总的来说它一直都很好!绝对值得每个月花 10 美元(特别是相对开发人员的工资来说)。
“如果没有它,我肯定不会想回去写代码。**Copilot 为你处理了大部分枯燥、普通、具有重复性的代码,所以你可以有更多时间来编写有趣的部分。**就像你雇来了一个“书呆子实习生”作为助理。他有时甚至还会为你提出出乎意料的好建议。”

对于一位每隔 3-6 个月就要用 4-5 种不同语言工作的多面手开发者来说,Copilot 同样非常有价值。
这位开发者表示:“我容易忘记很多事情,甚至是一些很简单的蠢事,如类型转换或特定的关键词拼写。而 Copilot 可以解决 99% 的问题,这样我就可以专注于我的高级规格。”

然而也有个别网友则表示:自己浪费在调试 Copilot 写的错误代码上所花的时间和使用它所节省的时间一样多。

总体来说,Copilot 简直是秃头程序员们救赎!但值得注意的是,新的编程工具必然带来新的编程风险。此前,GitHub Copilot 一直是有争议的。就在其预览版发布后的几天,有人质疑 Copilot 在 GitHub 上发布的公开代码上进行训练的合法性。除了版权问题外,一项研究还发现,Copilot 的输出中约有 40% 包含安全漏洞。而不知道此次商业版的发布是否能规避其中的问题。
但现在,我们依然庆幸有了这样一项技术的革新。
GitHub 表示,Copilot 是 GitHub 为开发者提供人工智能的第一步。从今天开始,所有开发者都可以使用它,而在今年晚些时候也将开始向企业提供 Copilot 的服务。
对此,你是否已经用上了 Copilot?这个价格你会付费吗?
参考资料:https://github.blog/2022-06-21-github-copilot-is-generally-available-to-all-develope rs/
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
鉴于我有以下迁移:Sequel.migrationdoupdoalter_table:usersdoadd_column:is_admin,:default=>falseend#SequelrunsaDESCRIBEtablestatement,whenthemodelisloaded.#Atthispoint,itdoesnotknowthatusershaveais_adminflag.#Soitfails.@user=User.find(:email=>"admin@fancy-startup.example")@user.is_admin=true@user.save!ende
我的主要目标是能够完全理解我正在使用的库/gem。我尝试在Github上从头到尾阅读源代码,但这真的很难。我认为更有趣、更温和的踏脚石就是在使用时阅读每个库/gem方法的源代码。例如,我想知道RubyonRails中的redirect_to方法是如何工作的:如何查找redirect_to方法的源代码?我知道在pry中我可以执行类似show-methodmethod的操作,但我如何才能对Rails框架中的方法执行此操作?您对我如何更好地理解Gem及其API有什么建议吗?仅仅阅读源代码似乎真的很难,尤其是对于框架。谢谢! 最佳答案 Ru
我的假设是moduleAmoduleBendend和moduleA::Bend是一样的。我能够从thisblog找到解决方案,thisSOthread和andthisSOthread.为什么以及什么时候应该更喜欢紧凑语法A::B而不是另一个,因为它显然有一个缺点?我有一种直觉,它可能与性能有关,因为在更多命名空间中查找常量需要更多计算。但是我无法通过对普通类进行基准测试来验证这一点。 最佳答案 这两种写作方法经常被混淆。首先要说的是,据我所知,没有可衡量的性能差异。(在下面的书面示例中不断查找)最明显的区别,可能也是最著名的,是你的
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
我目前正在使用以下方法获取页面的源代码:Net::HTTP.get(URI.parse(page.url))我还想获取HTTP状态,而无需发出第二个请求。有没有办法用另一种方法做到这一点?我一直在查看文档,但似乎找不到我要找的东西。 最佳答案 在我看来,除非您需要一些真正的低级访问或控制,否则最好使用Ruby的内置Open::URI模块:require'open-uri'io=open('http://www.example.org/')#=>#body=io.read[0,50]#=>"["200","OK"]io.base_ur
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最