文章目录
🔥 Hi,大家好,这里是丹成学长的毕设系列文章!
🔥 对毕设有任何疑问都可以问学长哦!
这两年开始,各个学校对毕设的要求越来越高,难度也越来越大… 毕业设计耗费时间,耗费精力,甚至有些题目即使是专业的老师或者硕士生也需要很长时间,所以一旦发现问题,一定要提前准备,避免到后面措手不及,草草了事。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的新项目是
🚩 基于深度学习的水果识别
🥇学长这里给一个题目综合评分(每项满分5分)
🧿 选题指导, 项目分享:
https://gitee.com/yaa-dc/BJH/blob/master/gg/cc/README.md
深度学习作为机器学习领域内新兴并且蓬勃发展的一门学科, 它不仅改变着传统的机器学习方法, 也影响着我们对人类感知的理解, 已经在图像识别和语音识别等领域取得广泛的应用。 因此, 本文在深入研究深度学习理论的基础上, 将深度学习应用到水果图像识别中, 以此来提高了水果图像的识别性能。
传统的水果图像识别系统的一般过程如下图所示,主要工作集中在图像预处理和特征提取阶段。
在大多数的识别任务中, 实验所用图像往往是在严格限定的环境中采集的, 消除了外界环境对图像的影响。 但是实际环境中图像易受到光照变化、 水果反光、 遮挡等因素的影响, 这在不同程度上影响着水果图像的识别准确率。
在传统的水果图像识别系统中, 通常是对水果的纹理、 颜色、 形状等特征进行提取和识别。

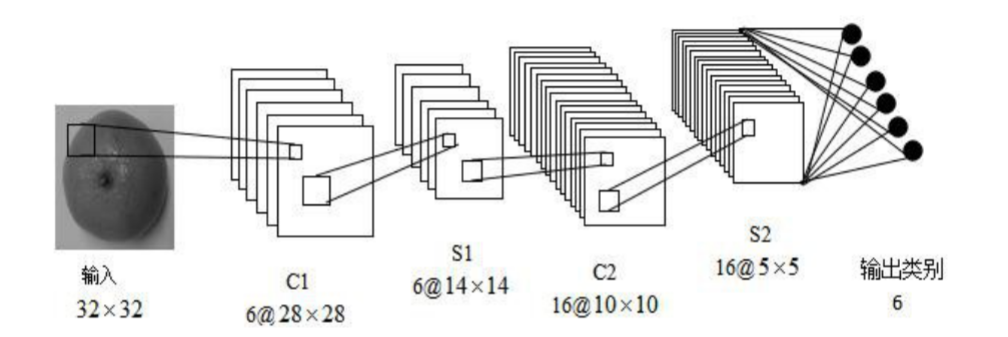
CNN 是一种专门为识别二维特征而设计的多层神经网络, 它的结构如下图所示,这种结构对平移、 缩放、 旋转等变形具有高度的不变性。
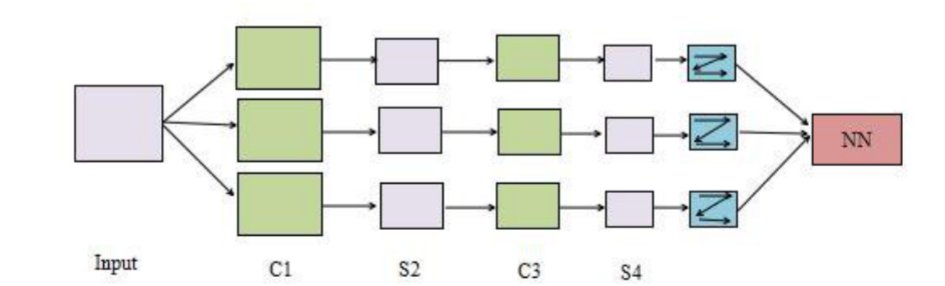
学长本次采用的 CNN 架构如图:
数据库分为训练集(train)和测试集(test)两部分
训练集包含四类apple,orange,banana,mixed(多种水果混合)四类237张图片;测试集包含每类图片各两张。图片集如下图所示。
图片类别可由图片名称中提取。
训练集图片预览
测试集预览

数据集目录结构
import os
import pandas as pd
train_dir = './Training/'
test_dir = './Test/'
fruits = []
fruits_image = []
for i in os.listdir(train_dir):
for image_filename in os.listdir(train_dir + i):
fruits.append(i) # name of the fruit
fruits_image.append(i + '/' + image_filename)
train_fruits = pd.DataFrame(fruits, columns=["Fruits"])
train_fruits["Fruits Image"] = fruits_image
print(train_fruits)
import matplotlib.pyplot as plt
import seaborn as sns
from keras.preprocessing.image import ImageDataGenerator, img_to_array, load_img
from glob import glob
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Activation, Dropout, Flatten, Dense
img = load_img(train_dir + "Cantaloupe 1/r_234_100.jpg")
plt.imshow(img)
plt.axis("off")
plt.show()
array_image = img_to_array(img)
# shape (100,100)
print("Image Shape --> ", array_image.shape)
# 131个类目
fruitCountUnique = glob(train_dir + '/*' )
numberOfClass = len(fruitCountUnique)
print("How many different fruits are there --> ",numberOfClass)
# 构建模型
model = Sequential()
model.add(Conv2D(32,(3,3),input_shape = array_image.shape))
model.add(Activation("relu"))
model.add(MaxPooling2D())
model.add(Conv2D(32,(3,3)))
model.add(Activation("relu"))
model.add(MaxPooling2D())
model.add(Conv2D(64,(3,3)))
model.add(Activation("relu"))
model.add(MaxPooling2D())
model.add(Flatten())
model.add(Dense(1024))
model.add(Activation("relu"))
model.add(Dropout(0.5))
# 区分131类
model.add(Dense(numberOfClass)) # output
model.add(Activation("softmax"))
model.compile(loss = "categorical_crossentropy",
optimizer = "rmsprop",
metrics = ["accuracy"])
print("Target Size --> ", array_image.shape[:2])
train_datagen = ImageDataGenerator(rescale= 1./255,
shear_range = 0.3,
horizontal_flip=True,
zoom_range = 0.3)
test_datagen = ImageDataGenerator(rescale= 1./255)
epochs = 100
batch_size = 32
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size= array_image.shape[:2],
batch_size = batch_size,
color_mode= "rgb",
class_mode= "categorical")
test_generator = test_datagen.flow_from_directory(
test_dir,
target_size= array_image.shape[:2],
batch_size = batch_size,
color_mode= "rgb",
class_mode= "categorical")
for data_batch, labels_batch in train_generator:
print("data_batch shape --> ",data_batch.shape)
print("labels_batch shape --> ",labels_batch.shape)
break
hist = model.fit_generator(
generator = train_generator,
steps_per_epoch = 1600 // batch_size,
epochs=epochs,
validation_data = test_generator,
validation_steps = 800 // batch_size)
#保存模型 model_fruits.h5
model.save('model_fruits.h5')
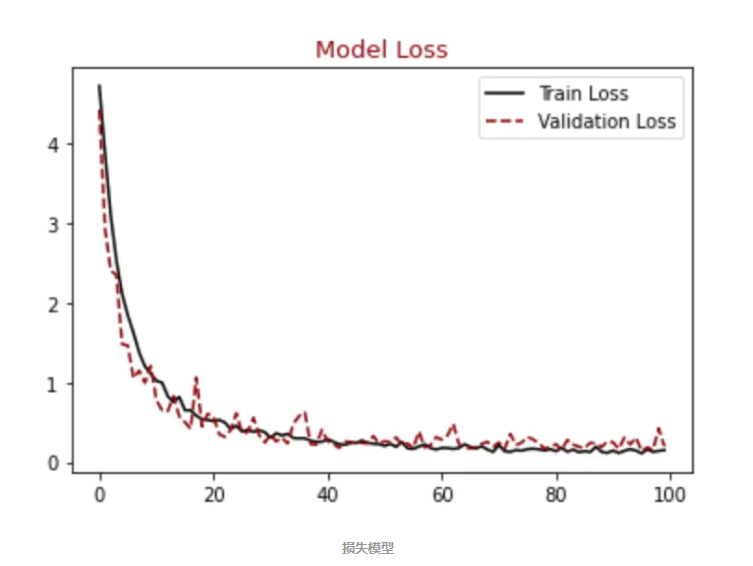
顺便输出训练曲线
#展示损失模型结果
plt.figure()
plt.plot(hist.history["loss"],label = "Train Loss", color = "black")
plt.plot(hist.history["val_loss"],label = "Validation Loss", color = "darkred", linestyle="dashed",markeredgecolor = "purple", markeredgewidth = 2)
plt.title("Model Loss", color = "darkred", size = 13)
plt.legend()
plt.show()
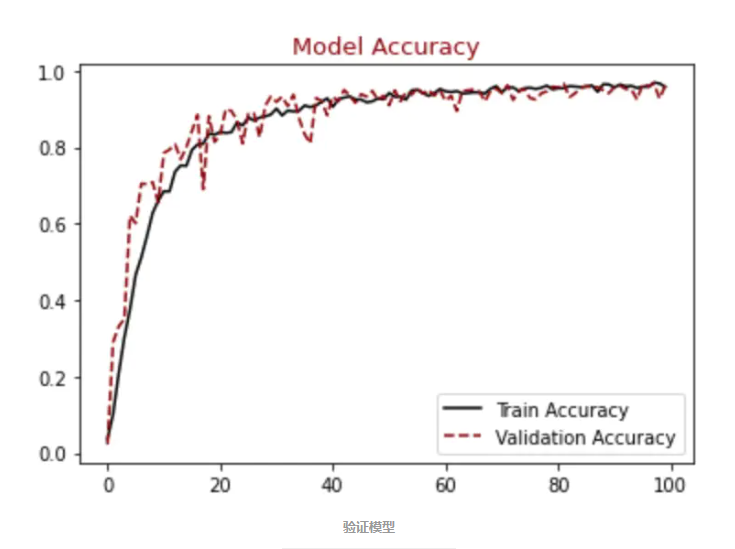
#展示精确模型结果
plt.figure()
plt.plot(hist.history["accuracy"],label = "Train Accuracy", color = "black")
plt.plot(hist.history["val_accuracy"],label = "Validation Accuracy", color = "darkred", linestyle="dashed",markeredgecolor = "purple", markeredgewidth = 2)
plt.title("Model Accuracy", color = "darkred", size = 13)
plt.legend()
plt.show()
from tensorflow.keras.models import load_model
import os
import pandas as pd
from keras.preprocessing.image import ImageDataGenerator,img_to_array, load_img
import cv2,matplotlib.pyplot as plt,numpy as np
from keras.preprocessing import image
train_datagen = ImageDataGenerator(rescale= 1./255,
shear_range = 0.3,
horizontal_flip=True,
zoom_range = 0.3)
model = load_model('model_fruits.h5')
batch_size = 32
img = load_img("./Test/Apricot/3_100.jpg",target_size=(100,100))
plt.imshow(img)
plt.show()
array_image = img_to_array(img)
array_image = array_image * 1./255
x = np.expand_dims(array_image, axis=0)
images = np.vstack([x])
classes = model.predict_classes(images, batch_size=10)
print(classes)
train_dir = './Training/'
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size= array_image.shape[:2],
batch_size = batch_size,
color_mode= "rgb",
class_mode= "categorical”)
print(train_generator.class_indices)

fig = plt.figure(figsize=(16, 16))
axes = []
files = []
predictions = []
true_labels = []
rows = 5
cols = 2
# 随机选择几个图片
def getRandomImage(path, img_width, img_height):
"""function loads a random image from a random folder in our test path"""
folders = list(filter(lambda x: os.path.isdir(os.path.join(path, x)), os.listdir(path)))
random_directory = np.random.randint(0, len(folders))
path_class = folders[random_directory]
file_path = os.path.join(path, path_class)
file_names = [f for f in os.listdir(file_path) if os.path.isfile(os.path.join(file_path, f))]
random_file_index = np.random.randint(0, len(file_names))
image_name = file_names[random_file_index]
final_path = os.path.join(file_path, image_name)
return image.load_img(final_path, target_size = (img_width, img_height)), final_path, path_class
def draw_test(name, pred, im, true_label):
BLACK = [0, 0, 0]
expanded_image = cv2.copyMakeBorder(im, 160, 0, 0, 300, cv2.BORDER_CONSTANT, value=BLACK)
cv2.putText(expanded_image, "predicted: " + pred, (20, 60), cv2.FONT_HERSHEY_SIMPLEX,
0.85, (255, 0, 0), 2)
cv2.putText(expanded_image, "true: " + true_label, (20, 120), cv2.FONT_HERSHEY_SIMPLEX,
0.85, (0, 255, 0), 2)
return expanded_image
IMG_ROWS, IMG_COLS = 100, 100
# predicting images
for i in range(0, 10):
path = "./Test"
img, final_path, true_label = getRandomImage(path, IMG_ROWS, IMG_COLS)
files.append(final_path)
true_labels.append(true_label)
x = image.img_to_array(img)
x = x * 1./255
x = np.expand_dims(x, axis=0)
images = np.vstack([x])
classes = model.predict_classes(images, batch_size=10)
predictions.append(classes)
class_labels = train_generator.class_indices
class_labels = {v: k for k, v in class_labels.items()}
class_list = list(class_labels.values())
for i in range(0, len(files)):
image = cv2.imread(files[i])
image = draw_test("Prediction", class_labels[predictions[i][0]], image, true_labels[i])
axes.append(fig.add_subplot(rows, cols, i+1))
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
plt.grid(False)
plt.axis('off')
plt.show()

我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我将应用程序升级到Rails4,一切正常。我可以登录并转到我的编辑页面。也更新了观点。使用标准View时,用户会更新。但是当我添加例如字段:name时,它不会在表单中更新。使用devise3.1.1和gem'protected_attributes'我需要在设备或数据库上运行某种更新命令吗?我也搜索过这个地方,找到了许多不同的解决方案,但没有一个会更新我的用户字段。我没有添加任何自定义字段。 最佳答案 如果您想允许额外的参数,您可以在ApplicationController中使用beforefilter,因为Rails4将参数
导读语言模型给我们的生产生活带来了极大便利,但同时不少人也利用他们从事作弊工作。如何规避这些难辨真伪的文字所产生的负面影响也成为一大难题。在3月9日智源Live第33期活动「DetectGPT:判断文本是否为机器生成的工具」中,主讲人Eric为我们讲解了DetectGPT工作背后的思路——一种基于概率曲率检测的用于检测模型生成文本的工具,它可以帮助我们更好地分辨文章的来源和可信度,对保护信息真实、防止欺诈等方面具有重要意义。本次报告主要围绕其功能,实现和效果等展开。(文末点击“阅读原文”,查看活动回放。)Ericmitchell斯坦福大学计算机系四年级博士生,由ChelseaFinn和Chri
电脑0x0000001A蓝屏错误怎么U盘重装系统教学分享。有用户电脑开机之后遇到了系统蓝屏的情况。系统蓝屏问题很多时候都是系统bug,只有通过重装系统来进行解决。那么蓝屏问题如何通过U盘重装新系统来解决呢?来看看以下的详细操作方法教学吧。 准备工作: 1、U盘一个(尽量使用8G以上的U盘)。 2、一台正常联网可使用的电脑。 3、ghost或ISO系统镜像文件(Win10系统下载_Win10专业版_windows10正式版下载-系统之家)。 4、在本页面下载U盘启动盘制作工具:系统之家U盘启动工具。 U盘启动盘制作步骤: 注意:制作期间,U盘会被格式化,因此U盘中的重要文件请注
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
之前说过10之后的版本没有3dScan了,所以还是9.8的版本或者之前更早的版本。 3d物体扫描需要先下载扫描的APK进行扫面。首先要在手机上装一个扫描程序,扫描现实中的三维物体,然后上传高通官网,在下载成UnityPackage类型让Unity能够使用这个扫描程序可以从高通官网上进行下载,是一个安卓程序。点到Tools往下滑,找到VuforiaObjectScanner下载后解压数据线连接手机,将apk文件拷入手机安装然后刚才解压文件中的Media文件夹打开,两个PDF图打印第一张A4-ObjectScanningTarget.pdf,主要是用来辅助扫描的。好了,接下来就是扫描三维物体。将瓶
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
Heroku支持人员告诉我,为了在我的Web应用程序中使用自定义字体(未安装在系统中,您可以在bash控制台中使用fc-list查看已安装的字体)我必须部署一个包含所有字体的.fonts文件夹里面的字体。问题是我不知道该怎么做。我的意思是,我不知道文件名是否必须遵循heroku的任何特殊模式,或者我必须在我的代码中做一些事情来考虑这种字体,或者如果我将它包含在文件夹中它是自动的......事实是,我尝试以不同的方式更改字体的文件名,但根本没有使用该字体。为了提供更多详细信息,我们使用字体的过程是将PDF转换为图像,更具体地说,使用rghostgem。并且最终图像根本不使用自定义字体。在
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal