好家伙,发现自己的网络知识十分匮乏,赶紧补一下
这里先举个我生活中的例子
欸,作业不会写了,上网搜一下
用edge浏览器上bing必应搜一下(百度广告太多了,真不想用百度举例子)
1.浏览器向宽带运营商服务器或者域名服务器发起一个 DNS 解析请求,之后浏览器获得了bing首页的 IP 地址。
2.拿到 IP 地址后,浏览器就向该 IP 所在的服务器建立 TCP 连接(即三次握手)。
3.连接建立起来之后,浏览器就可以向服务器发起 HTTP 请求了。

来自小米新域名价格曝光:简直太土豪了-小米,新域名,交易,价格,曝光,土豪, ——快科技(驱动之家旗下媒体)--科技改变未来 (mydrivers.com)
那么域名到IP的解析,就是通过DNS来完成的
超文本传输协议(Hyper Text Transfer Protocol,HTTP)是一个简单的请求-响应协议,它通常运行在TCP之上。
它指定了客户端可能发送给服务器什么样的消息以及得到什么样的响应。请求和响应消息的头以ASCII形式给出;
----百度百科
HTTP,全称为 HyperText Transfer Protocol,即为超文本传输协议。
是互联网应用最为广泛的一种网络协议,所有的 www 文件都必须遵守这个标准。
HTTP 可以分为两个部分,即请求和响应。
HTTP 请求由三个部分构成,分别是:状态行,请求头,请求正文
HTTP 响应由类似的三个部分构成:状态行,响应头,响应正文
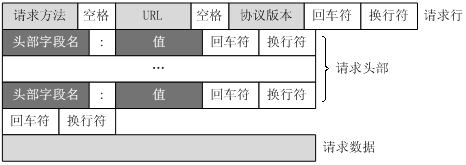
客户端发送一个HTTP请求到服务器的请求消息包括以下格式:请求行(request line)、请求头部(header)、空行和请求数据四个部分组成,下图给出了请求报文的一般格式。

(两张都是在菜鸟偷的图)
HTTP 定义了在与服务器交互的不同方式,最常用的方法有 4 种,分别是 GET,POST,PUT, DELETE。
URL 全称为资源描述符,可以这么认为:一个 URL 地址,对应着一个网络上的资源,而 HTTP 中的 GET,POST,PUT,DELETE 就对应着对这个资源的查询,修改,增添,删除4个操作。
(哦,熟悉的增删查改)
| 应答头 | 说明 |
|---|---|
| Allow |
服务器支持哪些请求方法(如GET、POST等)。 |
| Content-Encoding |
文档的编码(Encode)方法。只有在解码之后才可以得到Content-Type头指定的内容类型。利用gzip压缩文档能够显著地减少HTML文档的下载时间。Java的GZIPOutputStream可以很方便地进行gzip压缩,但只有Unix上的Netscape和Windows上的IE 4、IE 5才支持它。因此,Servlet应该通过查看Accept-Encoding头(即request.getHeader("Accept-Encoding"))检查浏览器是否支持gzip,为支持gzip的浏览器返回经gzip压缩的HTML页面,为其他浏览器返回普通页面。 |
| Content-Length |
表示内容长度。只有当浏览器使用持久HTTP连接时才需要这个数据。如果你想要利用持久连接的优势,可以把输出文档写入 ByteArrayOutputStream,完成后查看其大小,然后把该值放入Content-Length头,最后通过byteArrayStream.writeTo(response.getOutputStream()发送内容。 |
| Content-Type |
表示后面的文档属于什么MIME类型。Servlet默认为text/plain,但通常需要显式地指定为text/html。由于经常要设置Content-Type,因此HttpServletResponse提供了一个专用的方法setContentType。 |
| Date |
当前的GMT时间。你可以用setDateHeader来设置这个头以避免转换时间格式的麻烦。 |
| Expires |
应该在什么时候认为文档已经过期,从而不再缓存它? |
| Last-Modified |
文档的最后改动时间。客户可以通过If-Modified-Since请求头提供一个日期,该请求将被视为一个条件GET,只有改动时间迟于指定时间的文档才会返回,否则返回一个304(Not Modified)状态。Last-Modified也可用setDateHeader方法来设置。 |
| Location |
表示客户应当到哪里去提取文档。Location通常不是直接设置的,而是通过HttpServletResponse的sendRedirect方法,该方法同时设置状态代码为302。 |
| Refresh |
表示浏览器应该在多少时间之后刷新文档,以秒计。除了刷新当前文档之外,你还可以通过setHeader("Refresh", "5; URL=http://host/path")让浏览器读取指定的页面。 |
| Server |
服务器名字。Servlet一般不设置这个值,而是由Web服务器自己设置。 |
| Set-Cookie |
设置和页面关联的Cookie。Servlet不应使用response.setHeader("Set-Cookie", ...),而是应使用HttpServletResponse提供的专用方法addCookie。参见下文有关Cookie设置的讨论。 |
| WWW-Authenticate |
客户应该在Authorization头中提供什么类型的授权信息?在包含401(Unauthorized)状态行的应答中这个头是必需的。例如,response.setHeader("WWW-Authenticate", "BASIC realm=\"executives\"")。 |
HTTP 响应中包含一个状态码,用来表示服务器对客户端响应的结果。
HTTP 状态码由三个十进制数字组成,第一个十进制数字定义了状态码的类型。
响应分为五类:信息响应(100–199),成功响应(200–299),重定向(300–399),客户端错误(400–499)和服务器错误 (500–599):
| 分类 | 分类描述 |
|---|---|
| 1** | 信息,服务器收到请求,需要请求者继续执行操作 |
| 2** | 成功,操作被成功接收并处理 |
| 3** | 重定向,需要进一步的操作以完成请求 |
| 4** | 客户端错误,请求包含语法错误或无法完成请求 |
| 5** | 服务器错误,服务器在处理请求的过程中发生了错误 |
常见状态码:
| 100 | Continue | 继续。客户端应继续其请求 |
| 101 | Switching Protocols | 切换协议。服务器根据客户端的请求切换协议。只能切换到更高级的协议,例如,切换到HTTP的新版本协议 |
| 200 | OK | 请求成功。一般用于GET与POST请求 |
| 201 | Created | 已创建。成功请求并创建了新的资源 |
| 202 | Accepted | 已接受。已经接受请求,但未处理完成 |
| 300 | Multiple Choices | 多种选择。请求的资源可包括多个位置,相应可返回一个资源特征与地址的列表用于用户终端(例如:浏览器)选择 |
| 301 | Moved Permanently | 永久移动。请求的资源已被永久的移动到新URI,返回信息会包括新的URI,浏览器会自动定向到新URI。今后任何新的请求都应使用新的URI代替 |
| 302 | Found | 临时移动。与301类似。但资源只是临时被移动。客户端应继续使用原有URI |
| 400 | Bad Request | 客户端请求的语法错误,服务器无法理解 |
| 401 | Unauthorized | 请求要求用户的身份认证 |
| 402 | Payment Required | 保留,将来使用 |
| 403 | Forbidden | 服务器理解请求客户端的请求,但是拒绝执行此请求 |
| 404 | Not Found | 服务器无法根据客户端的请求找到资源(网页)。通过此代码,网站设计人员可设置"您所请求的资源无法找到"的个性页面 |
| 500 | Internal Server Error | 服务器内部错误,无法完成请求 |
| 501 | Not Implemented | 服务器不支持请求的功能,无法完成请求 |
| 502 | Bad Gateway | 作为网关或者代理工作的服务器尝试执行请求时,从远程服务器接收到了一个无效的响应 |
| 503 | Service Unavailable | 由于超载或系统维护,服务器暂时的无法处理客户端的请求。延时的长度可包含在服务器的Retry-After头信息中 |
| 504 | Gateway Time-out | 充当网关或代理的服务器,未及时从远端服务器获取请求 |
| 505 | HTTP Version not supported | 服务器不支持请求的HTTP协议的版本,无法完成处理 |
(以上表格均来自菜鸟教程HTTP 教程 | 菜鸟教程 (runoob.com))
浏览器与服务器使用 TCP/IP 协议来链接因特网。
浏览器使用 TCP/IP 协议进入服务器,服务器使用 TCP/IP 协议来发送 HTML 到浏览器。
因特网地址比如 "42.120.45.233" 就是一个 TCP/IP 协议。
每个计算机必须有一个 IP 地址才能够连入因特网。
每个 IP 包必须有一个地址才能够发送到另一台计算机。
在本教程下一节,您会学习到更多关于 IP 地址和 IP 名称的知识。
IP 用于计算机之间的通信。
IP 是无连接的通信协议。它不会占用两个正在通信的计算机之间的通信线路。这样,IP 就降低了对网络线路的需求。每条线可以同时满足许多不同的计算机之间的通信需要。
通过 IP,消息(或者其他数据)被分割为小的独立的包,并通过因特网在计算机之间传送。
IP 负责将每个包路由至它的目的地。
3.5.IP 路由器
当一个 IP 包从一台计算机被发送,它会到达一个 IP 路由器。
IP 路由器负责将这个包路由至它的目的地,直接地或者通过其他的路由器。
在一个相同的通信中,一个包所经由的路径可能会和其他的包不同。而路由器负责根据通信量、网络中的错误或者其他参数来进行正确地寻址。
TCP/IP 意味着 TCP 和 IP 在一起协同工作。
TCP 负责应用软件(比如您的浏览器)和网络软件之间的通信。
IP 负责计算机之间的通信。
TCP 负责将数据分割并装入 IP 包,然后在它们到达的时候重新组合它们。
IP 负责将包发送至接受者。
是的,我知道最好使用webmock,但我想知道如何在RSpec中模拟此方法:defmethod_to_testurl=URI.parseurireq=Net::HTTP::Post.newurl.pathres=Net::HTTP.start(url.host,url.port)do|http|http.requestreq,foo:1endresend这是RSpec:let(:uri){'http://example.com'}specify'HTTPcall'dohttp=mock:httpNet::HTTP.stub!(:start).and_yieldhttphttp.shou
我有一个存储主机名的Ruby数组server_names。如果我打印出来,它看起来像这样:["hostname.abc.com","hostname2.abc.com","hostname3.abc.com"]相当标准。我想要做的是获取这些服务器的IP(可能将它们存储在另一个变量中)。看起来IPSocket类可以做到这一点,但我不确定如何使用IPSocket类遍历它。如果它只是尝试像这样打印出IP:server_names.eachdo|name|IPSocket::getaddress(name)pnameend它提示我没有提供服务器名称。这是语法问题还是我没有正确使用类?输出:ge
我目前正在使用以下方法获取页面的源代码:Net::HTTP.get(URI.parse(page.url))我还想获取HTTP状态,而无需发出第二个请求。有没有办法用另一种方法做到这一点?我一直在查看文档,但似乎找不到我要找的东西。 最佳答案 在我看来,除非您需要一些真正的低级访问或控制,否则最好使用Ruby的内置Open::URI模块:require'open-uri'io=open('http://www.example.org/')#=>#body=io.read[0,50]#=>"["200","OK"]io.base_ur
1.错误信息:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:requestcanceledwhilewaitingforconnection(Client.Timeoutexceededwhileawaitingheaders)或者:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:TLShandshaketimeout2.报错原因:docker使用的镜像网址默认为国外,下载容易超时,需要修改成国内镜像地址(首先阿里
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
Rails中有没有一种方法可以提取与路由关联的HTTP动词?例如,给定这样的路线:将“users”匹配到:“users#show”,通过:[:get,:post]我能实现这样的目标吗?users_path.respond_to?(:get)(显然#respond_to不是正确的方法)我最接近的是通过执行以下操作,但它似乎并不令人满意。Rails.application.routes.routes.named_routes["users"].constraints[:request_method]#=>/^GET$/对于上下文,我有一个设置cookie然后执行redirect_to:ba
我正在使用Heroku(heroku.com)来部署我的Rails应用程序,并且正在构建一个iPhone客户端来与之交互。我的目的是将手机的唯一设备标识符作为HTTPheader传递给应用程序以进行身份验证。当我在本地测试时,我的header通过得很好,但在Heroku上它似乎去掉了我的自定义header。我用ruby脚本验证:url=URI.parse('http://#{myapp}.heroku.com/')#url=URI.parse('http://localhost:3000/')req=Net::HTTP::Post.new(url.path)#boguspara
我试图在我的网站上实现使用Facebook登录功能,但在尝试从Facebook取回访问token时遇到障碍。这是我的代码:ifparams[:error_reason]=="user_denied"thenflash[:error]="TologinwithFacebook,youmustclick'Allow'toletthesiteaccessyourinformation"redirect_to:loginelsifparams[:code]thentoken_uri=URI.parse("https://graph.facebook.com/oauth/access_token
我是Ruby的新手。我试过查看在线文档,但没有找到任何有效的方法。我想在以下HTTP请求botget_response()和get()中包含一个用户代理。有人可以指出我正确的方向吗?#PreliminarycheckthatProggitisupcheck=Net::HTTP.get_response(URI.parse(proggit_url))ifcheck.code!="200"puts"ErrorcontactingProggit"returnend#Attempttogetthejsonresponse=Net::HTTP.get(URI.parse(proggit_url)
我经常将预配置的lambda插入可枚举的方法中,例如“map”、“select”等。但是“注入(inject)”的行为似乎有所不同。例如与mult4=lambda{|item|item*4}然后(5..10).map&mult4给我[20,24,28,32,36,40]但是,如果我制作一个2参数lambda用于像这样的注入(inject),multL=lambda{|product,n|product*n}我想说(5..10).inject(2)&multL因为“inject”有一个可选的单个初始值参数,但这给了我......irb(main):027:0>(5..10).inject