首先将跑在本地版本的项目,上传至远端(gitee、github上)
重新复制一份项目的配置文件,可以命名为pro.py(dev为开发阶段的配置文件,pro为上线的配置文件)
在pro文件内,修改以下配置项:
# 将调式模式改为false
DEBUG = False
# 运行的host地址,正常就是写服务端的ip地址,不知道可以先写*
ALLOWED_HOSTS = ['*']
# 数据库的配置
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'luffy',
'USER':'luffyapi',
'PASSWORD':'Luffy123?',
'HOST':'127.0.0.1', # 如果这里上线时,数据库没有和项目装在同一台服务器上,就需要配置装数据库服务器的ip地址
'PORT':3306
}
}
# redis配置
CACHES = {
"default": {
"BACKEND": "django_redis.cache.RedisCache", #以后cache还是原来的方式使用,只不过不是存在浏览器了而是存在了redis里
"LOCATION": "redis://127.0.0.1:6379", # 和上面数据库一样,装在一台机器就不用配了
"OPTIONS": {
"CLIENT_CLASS": "django_redis.client.DefaultClient",
"CONNECTION_POOL_KWARGS": {"max_connections": 100} # 连接池的最大是100
# "PASSWORD": "123", # 有密码就先密码,没有就不用写
}
}
}
# 支付相关的配置,上线改为公网ip
# 后台基URL
BASE_URL = 'http://106.15.104.37:8000' #这里买好服务器之后,需要配置好自己服务器的ip地址并指定8000端口
# 前台基URL
LUFFY_URL = 'http://106.15.104.37' # 这个也是,端口前台采用默认的80端口
# 支付宝同步异步回调接口配置
# 后台异步回调接口
NOTIFY_URL = BASE_URL + "/order/success/"
# 前台同步回调接口,没有 / 结尾
RETURN_URL = LUFFY_URL + "/pay/success"
# 将这里改成settings里的pro配置文件启动
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'luffyapi.settings.pro')
# 修改一下配置文件为pro的那个
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'luffyapi.settings.pro')
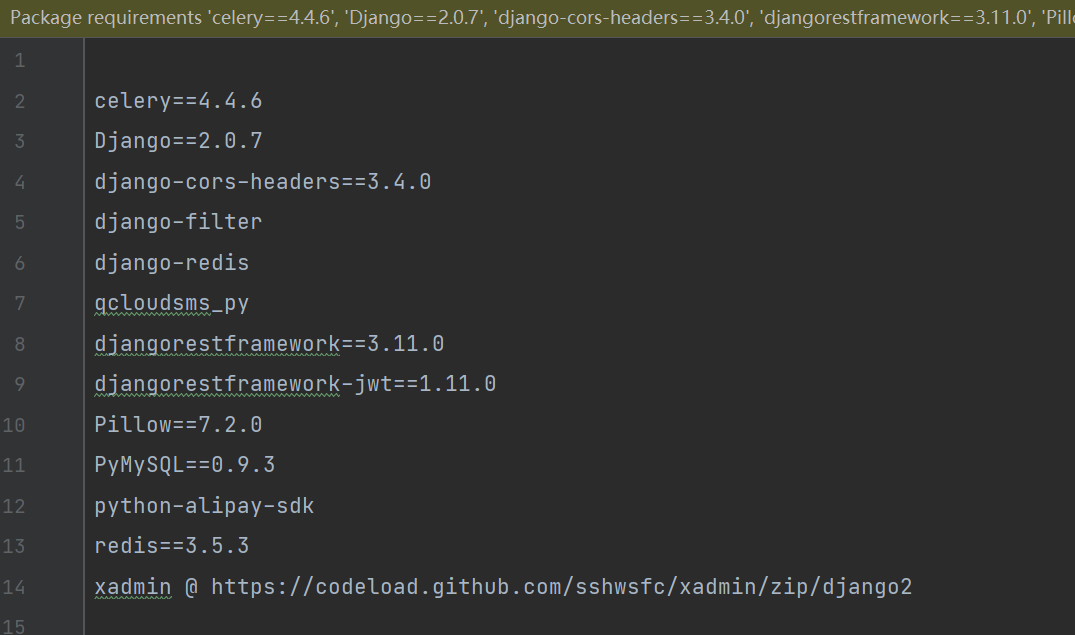
后面在服务器上只需要pip install -r requirement.txt就可以一次性下载完项目所需要的包
买完之后,在安全设置里,释放自己需要的端口!!!
远程链接阿里云服务器的软件有:finalshell、xshell等
finalshell 下载安装地址:http://www.hostbuf.com/c/131.html
finalshell安装之后,打开使用ssh输入密码和ip连接远程服务器
yum update -y
yum install openssl-devel bzip2-devel expat-devel gdbm-devel readline-devel sqlite-devel psmisc libffi-devel
yum -y groupinstall "Development tools"
在终端输入git,看是否成功安装
cd ~
wget https://repo.mysql.com//mysql80-community-release-el7-1.noarch.rpm
rpm -ivh mysql80-community-release-el7-1.noarch.rpm
yum -y install mysql-community-server
如果报密钥已安装,但不适用该软件包的错误,可以使用sudo yum install mysql-server --nogpgcheck方式重新安装
5. 启动mysql57并查看启动状态
systemctl start mysqld.service
systemctl status mysqld.service
grep "password" /var/log/mysqld.log
mysql -uroot -p
ALTER USER 'root'@'localhost' IDENTIFIED BY 'new password';
ALTER USER 'root'@'localhost' IDENTIFIED BY 'Site123?';
cd ~
wget http://download.redis.io/releases/redis-5.0.5.tar.gz
tar -xf redis-5.0.5.tar.gz
cd redis-5.0.5
make
cp -r ~/redis-5.0.5 /usr/local/redis
ln -s /usr/local/redis/src/redis-server /usr/bin/redis-server
ln -s /usr/local/redis/src/redis-cli /usr/bin/redis-cli
cd /usr/local/redis # cd到redis文件夹里执行下面的命令
redis-server & # 加个&表示后台启动redis
pkill -f redis -9
cd ~
wget https://www.python.org/ftp/python/3.6.7/Python-3.6.7.tar.xz
tar -xf Python-3.6.7.tar.xz
cd Python-3.6.7
./configure --prefix=/usr/local/python3
make && sudo make install
ln -s /usr/local/python3/bin/python3.6 /usr/bin/python3
ln -s /usr/local/python3/bin/pip3.6 /usr/bin/pip3
cd ~
wget http://nginx.org/download/nginx-1.13.7.tar.gz
tar -xf nginx-1.13.7.tar.gz
cd nginx-1.13.7
./configure --prefix=/usr/local/nginx
make && sudo make install
ln -s /usr/local/nginx/sbin/nginx /usr/bin/nginx
nginx
服务器绑定的域名 或 ip:80
nginx #启动nginx命令
nginx -s reload # 重启nginx
nginx -s stop # 结束nginx
pip3 install virtualenv
pip3 install virtualenvwrapper
ln -s /usr/local/python3/bin/virtualenv /usr/bin/virtualenv
vim ~/.bash_profile # 打开该文件添加以下内容
VIRTUALENVWRAPPER_PYTHON=/usr/bin/python3
source /usr/local/python3/bin/virtualenvwrapper.sh
source ~/.bash_profile
# 创建虚拟环境
mkvirtualenv luffy
# 进入虚拟环境
workon luffy
# 退出虚拟环境
deactivate
base_url: 'http://39.99.192.127:8000', // 真实环境:django项目就是跑在8000端口上的
cnpm run build
scp -r dist root@39.99.192.127:~
-r表示文件夹一起传 root为服务器用户名,@后面为服务器ip,~表示传到根目录下
在服务端,将dist文件夹从~根目录下移动到home文件夹下,并将dist文件夹重命名为html
mv ~/dist /home/html
去向Nginx配置目录,备份配置,完全更新配置:填入下方内容
cd /usr/local/nginx/conf # 进入nginx的配置文件目录
mv nginx.conf nginx.conf.bak # 将nginx原本的配置文件重新移到一个新的文件nginx.conf.bak里
vim nginx.conf # 新建一个nginx.conf文件配置以下内容
# events表示最大连接数
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
server {
# 监听的80端口
listen 80;
server_name 127.0.0.1; # 改为自己的域名,没域名修改为127.0.0.1:80
charset utf-8;
location / {
# 访问根路径时去root里找html文件夹里的index.html
root /home/html; # html访问路径
index index.html; # html文件名称
try_files $uri $uri/ /index.html; # 解决单页面应用刷新404问题
}
}
}
此时,在访问服务端的ip地址,默认就会显示前台项目的页面
mkdir /home/project
cd /home/project
# 从gitee或者github上拉下项目
git clone https://gitee.com/doctor_owen/luffyapi.git(项目地址)
mkvirtualenv luffy
workon luffy
# 在虚拟环境中安装项目所需要的包
pip install -r requirement.txt
1)管理员连接数据库
mysql -uroot -p
2)创建项目对应数据库
create database luffy default charset=utf8;
3)设置权限账号密码:账号密码要与项目中配置的一致
create user 'username'@'%' identified by 'password';
grant all privileges on 库名.* to 'username'@'%' with grant option;
flush privileges;
4)退出mysql
quit;
搞完,本地的navicat就可以连接到服务端的数据库了(注意需要服务器开放3306端口)
删除,项目文件里的迁移文件,再执行数据库迁移命令
迁移完执行创建超级管理员命令,创建超级管理员!!
# 1)在真实环境和虚拟环境都要安装uwsgi
pip3 install uwsgi
uwsgi的基础命令:
uwsgi -x /home/project/siteapi/site.xml # 启动uwsgi
pkill -f uwsgi -9 # 关闭uwsgi
ps -aux|grep uwsgi # 查看uwsgi进程
# 2)建立软连接
ln -s /usr/local/python3/bin/uwsgi /usr/bin/uwsgi
# 3) 进行uwsgi服务配置,内容如下
vim /home/project/luffyapi/luffyapi.xml # 创建一个xml文件并配置以下内容
<uwsgi>
<socket>127.0.0.1:8808</socket> <!-- 内部端口,自定义-->
<chdir>/home/project/siteapi/</chdir> <!-- 项目路径 -->
<module>siteapi.wsgi</module> <!-- luffyapi为wsgi.py所在目录名-->
<processes>6</processes> <!-- 进程数 -->
<daemonize>uwsgi.log</daemonize> <!-- 日志文件 -->
</uwsgi>
# 4)去向Nginx配置目录,填入以下内容
vim /usr/local/nginx/conf/nginx.conf
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
server {
listen 80;
server_name 127.0.0.1; # 改为自己的域名,没域名修改为127.0.0.1:80
charset utf-8;
location / {
root /home/html; # html访问路径
index index.html; # html文件名称
try_files $uri $uri/ /index.html; # 解决单页面应用刷新404问题
}
}
# 新增的server
server {
listen 8000;
server_name 127.0.0.1; # 改为自己的域名,没域名修改为127.0.0.1:80
charset utf-8;
location / {
include uwsgi_params;
uwsgi_pass 127.0.0.1:8808; # 端口要和uwsgi里配置的一样
uwsgi_param UWSGI_SCRIPT siteapi.wsgi; #wsgi.py所在的目录名+.wsgi
uwsgi_param UWSGI_CHDIR /home/project/siteapi/; # 项目路径
}
}
}
此时,重启nginx,在访问ip:8000端口,会经由nginx转发,交给uwsgi处理启动项目,但是还需要收集一下静态文件
1)项目目录下没有 static 文件夹需要新建
mkdir /home/project/luffyapi/luffyapi/static
2) 编辑线上配置文件
# 打开配置文件
vim /home/project/luffyapi/luffyapi/settings/prod.py
# 修改static配置,新增STATIC_ROOT、STATICFILES_DIRS
STATIC_URL = '/static/'
STATIC_ROOT = '/home/project/luffyapi/luffyapi/static'
STATICFILES_DIRS = (os.path.join(BASE_DIR, "static"),)
(如果报错,则修改STATICFILES_DIRS 为(os.path.join(BASE_DIR, "images"),))
3)完成静态文件迁移
python /home/project/luffyapi/manage_pro.py collectstatic
1)修改nginx配置
vim /usr/local/nginx/conf/nginx.conf
# 新增的配置静态文件
location /static {
# alias 后面是静态文件路径
alias /home/project/luffyapi/luffyapi/static;
}
重启nginx和uwsgi就可以访问到页面了
访问ip:8000/admin路径可以查看后台管理页面
一、系统定级信息系统运营使用单位按照等级保护管理办法和定级指南,自主确定信息系统的安全保护等级。有上级主管部门的,应当经上级主管部门审批。跨省或全国统一联网运行的信息系统可以由其主管部门统一确定安全保护等级。定级需要根据信息系统的实际情况合理定级。二、系统备案第二级以上信息系统定级单位到所在地设区的市级以上公安机关办理备案手续。省级单位到省公安厅网安总队备案,各地市单位一般直接到市级网安支队备案,也有部分地市区县单位的定级备案资料是先交到区县公安网监大队的,具体根据各地市要求来。信息系统运营、使用单位或者其主管部门应当在信息系统安全保护等级确定后30日内,到公安机关办理备案手续。三、初次测评信
目录1. 研究范围定义2. 流程中台市场分析3. 厂商评估:微宏科技4. 入选证书 1. 研究范围定义近年来,随着外部市场环境快速变化、客户需求愈发多样,企业逐渐意识到,自身业务需要更加敏捷、高效,具备根据市场需求快速迭代的能力。业务流程的自动化能够帮助企业实现业务的敏捷高效,因此受到越来越多企业的关注。企业的“自动化武器库”品类丰富,包括低/零代码平台、RPA、BPM、AI等。企业可以使用多项自动化工具,但结果往往是各项自动化工具处于各自的“自动化烟囱”之中,仅能实现碎片式自动化。例如,某企业的IT团队可能在使用低代码平台、财务团队可能在使用RPA、呼叫中心则可能在使用聊天机器人。自动
我想了解使用rspec测试多步骤工作流的习惯用法或最佳实践。我们以“购物车”系统为例,其中的购买流程可能是当用户提交购物篮并且我们没有使用https时,重定向到https当用户提交购物篮并且我们使用https并且没有cookie时,创建并显示一个新的购物篮并发回cookie当用户提交到购物车并且我们使用https并且有一个有效的cookie并且新商品与第一个商品用于不同的产品时,向购物车添加一行并显示这两行当用户提交到购物篮并且我们使用https并且有一个有效的cookie并且新商品与之前的商品相同时,增加该购物篮行的数量并显示这两条线当用户点击购物车页面上的“结帐”并使用https并
我问了一个关于目录监视的不同问题,有人回答了这个问题,但问题的另一半是如何最好地在ruby中创建一个永无止境的进程来做到这一点。以下是要求:永远奔跑可监控(即知道它是在运行还是在运行)有某种方法可以重新启动它并确保它正常运行(上帝?)开始/停止使用Capistrano(会很好!)我们看过BackgroundRb,但它似乎有点过时而且老实说不可靠!我们查看了DelayedJob,但这似乎适合一次性工作(因为永无止境的工作似乎会阻止任何其他工作完成,因为工作是按顺序完成的)。我们正在运行构成我们环境的一堆Ubuntu服务器。有什么想法吗? 最佳答案
BigData/CloudComputing:基于阿里云技术产品的人工智能与大数据/云计算/分布式引擎的综合应用案例目录来理解技术交互流程目录一、云计算网站建设:部署与发布网站建设:简单动态网站搭建云服务器管理维护云数据库管理与数据迁移云存储:对象存储管理与安全超大流量网站的负载均衡二、大数据MOOC网站日志分析搭建企业级数据分析平台基于LBS的热点店铺搜索基于机器学习PAI实现精细化营销基于机器学习的客户流失预警分析使用DataV制作实时销售数据可视化大屏使用MaxCompute进行数据质量核查使用Quick BI制作图形化报表使用时间序列分解模型预测商品销量三、云安全云平台使用安全云上服务
基于ffmpeg的视频处理与MPEG的压缩试验ffmpeg介绍与基础知识对提取到的图像进行处理RGB并转化为YUV对YUV进行DCT变换对每个8*8的图像块进行进行量化操作ffmpeg介绍与基础知识ffmpeg是视频和图像处理的工具包,它的下载网址是https://ffmpeg.org/download.html。页面都是英文且下载正确的包的路径笔者找的时候还费点劲,这里记录一下也方便读者。选中这个Windows下的下午files,选择第一个这里有essential和full版本的,大家根据需要自行选择版本包下载下载好之后,在官网上下载ffmpeg的full包,一共300+MB解压,然后安装b
ElasticSearch——刷盘原理流程刷盘原理流程名词和操作解释相关设置刷盘原理流程整个过程会分成几步:数据会同时写入buffer缓冲区和translog日志文件buffer缓冲区满了或者到时间了(默认1s),就会将其中的数据转换成新的segment并写入系统文件缓存,这一步叫refresh其中后台会自动合并小的segment成大的segment;这一步叫段合并当translog达到大小的阈值(默认512M)或者flush默认时长(30m),则会执行flush操作:内存中数据写入新的segment放入缓存(清空内存区)一个commitpoint写入磁盘,表示哪些segment已写入磁盘将缓
尤其是在考虑新的Rails项目时,您的版本控制和部署工作流程是什么样的?你使用什么工具?我对Mac、*nix和Windows工作机器的答案很感兴趣。假设一个*nix服务器。如果需要,我会为清楚起见进行编辑。 最佳答案 使用预装的插件和卡住的gem创建我的个人Rails2.1.1模板的副本。更改数据库密码、session密码/名称和deploy.rb。根据需要在GitHub上创建私有(private)或公共(public)存储库。将空的Rails项目推送到GitHub。SSH到服务器并配置apache(从旧项目复制虚拟主机文件和mon
我正在尝试了解如何监控travis-ci的resqueworker|与god以这样一种方式停止resquewatchviagod不会留下陈旧的工作进程。在下文中,我谈论的是工作进程,而不是fork作业子进程(即队列一直是空的)。当我像这样手动启动resqueworker时:$QUEUE=buildsrakeresque:work我会得到一个进程:$psx|grepresque7041s001S+0:05.04resque-1.13.0:Waitingforbuilds一旦我停止工作任务,这个过程就会消失。但是当我开始与上帝(exactconfigurationishere,基本上与re
是否有一种标准(ish)POSIX方法来确定我的进程(我现在正在将其编写为Ruby脚本;但我对多种环境感到好奇,包括Node.js和ISOC命令行应用程序)正在交互式终端中运行,而不是cron,或者从其他工具执行,或者……等等。具体来说,我需要在某些情况下获取用户输入,如果确定不可能(即由cron运行),我需要致命失败。我可以使用环境变量来做到这一点,但如果可以的话,我更喜欢更标准的东西。 最佳答案 我一直使用$stdout.isatty来检查这一点。其他方法可能包括检查ENV['TERM']的值或利用ruby-terminfoge