在上篇文章讲到了如何配置单数据源,但是在实际场景中,会有需要配置多个数据源的场景,比如说,我们在支付系统中,单笔操作(包含查询、插入、新增)中需要操作主库,在批量查询或者对账单查询等对实时性要求不高的场景,需要使用读库来操作,依次来减轻数据库的压力。那么我们如何配置多数据源?
这里还是基于springboot应用的情况下,我们看一下怎么配置。
因为SpringBoot会实现自动配置,但是SpringBoot并不知道我们的业务场景分别要使用哪一个数据源,因此我们需要把相关的自动配置关闭。
首先,生成项目骨架,引入相应的依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
```
**然后,在Application排除自动装配类**
```java
@SpringBootApplication(exclude = { DataSourceAutoConfiguration.class,DataSourceTransactionManagerAutoConfiguration.class,JdbcTemplateAutoConfiguration.class})
@Slf4j
public class MultiDataSourceDemoApplication {
}
上面代码中,我们排除了DataSourceAutoConfiguration、DataSourceTransactionManagerAutoConfiguration、JdbcTemplateAutoConfiguration三个类,然后就可以自己定义DataSource了。
配置数据源
//第一个数据源
@Bean
@ConfigurationProperties("first.datasource")
public DataSource firstDataSource() {
return DataSourceBuilder.create().build();
}
@Bean
public JdbcTemplate firstJdbcTemplate() {
return new JdbcTemplate(firstDataSource());
}
@Bean
@Resource
public PlatformTransactionManager firstTxManager(DataSource firstDataSource) {
return new DataSourceTransactionManager(firstDataSource);
}
//第二个数据源
@Bean
@ConfigurationProperties("second.datasource")
public DataSource secondDataSource() {
return DataSourceBuilder.create().build();
}
@Bean
public JdbcTemplate secondJdbcTemplate() {
return new JdbcTemplate(secondDataSource());
}
@Bean
@Resource
public PlatformTransactionManager secondTxManager(DataSource secondDataSource) {
return new DataSourceTransactionManager(secondDataSource);
}
application.properties的配置项信息
management.endpoints.web.exposure.include=*
spring.output.ansi.enabled=ALWAYS
first.datasource.jdbc-url=jdbc:mysql://localhost:3306/first
first.datasource.username=root
first.datasource.password=xxx
second.datasource.jdbc-url=jdbc:mysql://localhost:3306/second
second.datasource.username=root
second.datasource.password=xxx
看一下表结构和数据
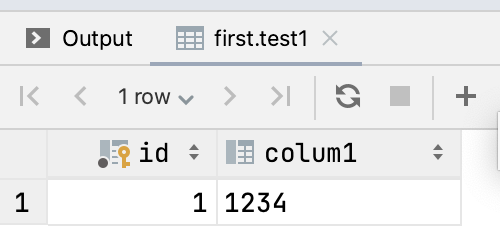
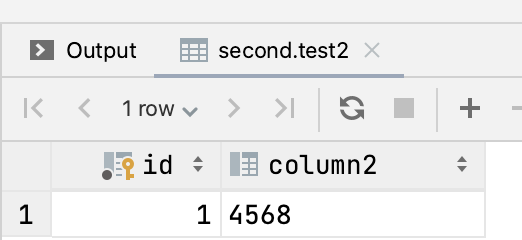
运行测试代码:
@Test
public void testMutilDataSource(){
firstJdbcTemplate.queryForList("SELECT * FROM test1")
.forEach(row -> log.info("记录:"+row.toString()));
secondJdbcTemplate.queryForList("SELECT * FROM test2")
.forEach(row -> log.info("记录:"+row.toString()));
}
我们看一下运行效果:
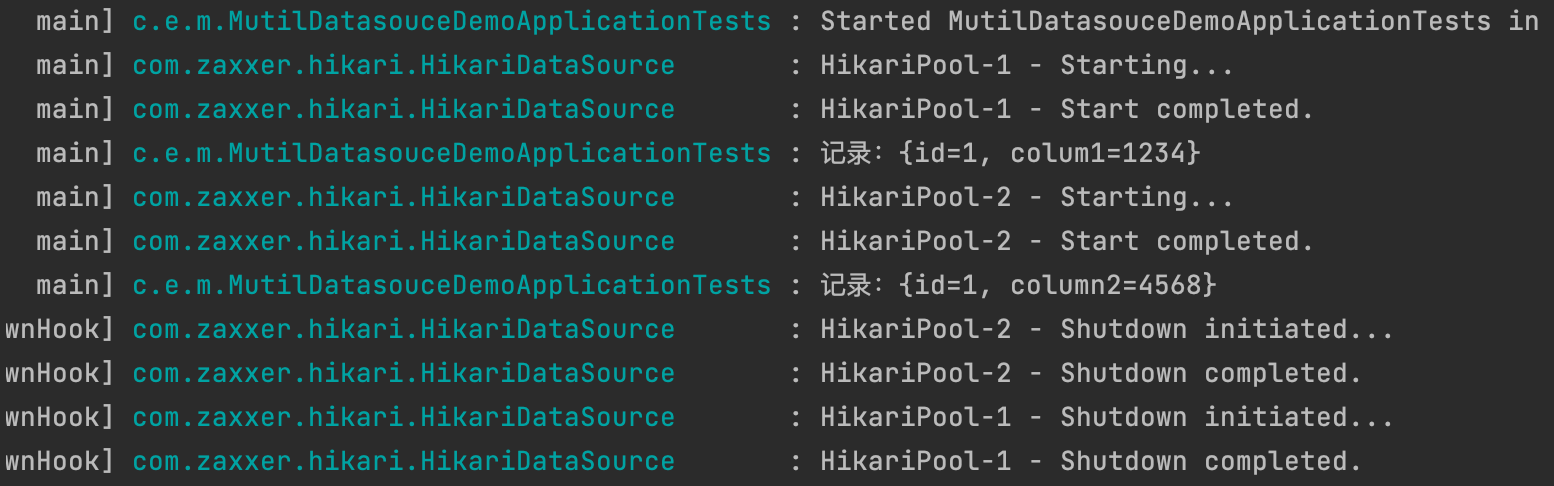
我们可以看到,两个数据源都初始化成功了,并且各自数据源执行的结果准确。
上面的方式没有集成Mybatis,使用的是jdbcTemplate,网络上还有很多配置方式,比如动态选择数据源,大同小异,不过笔者还是建议不同的业务单独指定数据源,容易维护。
我们已经演示了简单的单数据源和多数据源的配置方式,我们下一篇文章将讲一下,SpringBoot默认的连接池HikariCP。
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
我有多个ActiveRecord子类Item的实例数组,我需要根据最早的事件循环打印。在这种情况下,我需要打印付款和维护日期,如下所示:ItemAmaintenancerequiredin5daysItemBpaymentrequiredin6daysItemApaymentrequiredin7daysItemBmaintenancerequiredin8days我目前有两个查询,用于查找maintenance和payment项目(非排他性查询),并输出如下内容:paymentrequiredin...maintenancerequiredin...有什么方法可以改善上述(丑陋的)代
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
我有一个在Linux服务器上运行的ruby脚本。它不使用rails或任何东西。它基本上是一个命令行ruby脚本,可以像这样传递参数:./ruby_script.rbarg1arg2如何将参数抽象到配置文件(例如yaml文件或其他文件)中?您能否举例说明如何做到这一点?提前谢谢你。 最佳答案 首先,您可以运行一个写入YAML配置文件的独立脚本:require"yaml"File.write("path_to_yaml_file",[arg1,arg2].to_yaml)然后,在您的应用中阅读它:require"yaml"arg
我有一个具有一些属性的模型:attr1、attr2和attr3。我需要在不执行回调和验证的情况下更新此属性。我找到了update_column方法,但我想同时更新三个属性。我需要这样的东西:update_columns({attr1:val1,attr2:val2,attr3:val3})代替update_column(attr1,val1)update_column(attr2,val2)update_column(attr3,val3) 最佳答案 您可以使用update_columns(attr1:val1,attr2:val2
我正在使用Ruby2.1.1和Rails4.1.0.rc1。当执行railsc时,它被锁定了。使用Ctrl-C停止,我得到以下错误日志:~/.rvm/gems/ruby-2.1.1/gems/spring-1.1.2/lib/spring/client/run.rb:47:in`gets':Interruptfrom~/.rvm/gems/ruby-2.1.1/gems/spring-1.1.2/lib/spring/client/run.rb:47:in`verify_server_version'from~/.rvm/gems/ruby-2.1.1/gems/spring-1.1.
我正在尝试修改当前依赖于定义为activeresource的gem:s.add_dependency"activeresource","~>3.0"为了让gem与Rails4一起工作,我需要扩展依赖关系以与activeresource的版本3或4一起工作。我不想简单地添加以下内容,因为它可能会在以后引起问题:s.add_dependency"activeresource",">=3.0"有没有办法指定可接受版本的列表?~>3.0还是~>4.0? 最佳答案 根据thedocumentation,如果你想要3到4之间的所有版本,你可以这