本次任务是利用ResNet18网络实践更通用的图像分类任务。
ResNet系列网络,图像分类领域的知名算法,经久不衰,历久弥新,直到今天依旧具有广泛的研究意义和应用场景。被业界各种改进,经常用于图像识别任务。
今天主要介绍一下ResNet-18网络结构的案例,其他深层次网络,可以依次类推。
ResNet-18,数字代表的是网络的深度,也就是说ResNet18 网络就是18层的吗?实则不然,其实这里的18指定的是带有权重的 18层,包括卷积层和全连接层,不包括池化层和BN层。
图像分类(Image Classification)是计算机视觉中的一个基础任务,将图像的语义将不同图像划分到不同类别。很多任务也可以转换为图像分类任务。比如人脸检测就是判断一个区域内是否有人脸,可以看作一个二分类的图像分类任务。
ResNet 网络简介:

CIFAR-10数据集包含了10种不同的类别、共60,000张图像,其中每个类别的图像都是6000张,图像大小均为32×3232×32像素。

在本实验中,将原始训练集拆分成了train_set、dev_set两个部分,分别包括40 000条和10 000条样本。将data_batch_1到data_batch_4作为训练集,data_batch_5作为验证集,test_batch作为测试集。 最终的数据集构成为:
读取一个batch数据的代码如下所示:
import os
import pickle
import numpy as np
def load_cifar10_batch(folder_path, batch_id=1, mode='train'):
if mode == 'test':
file_path = os.path.join(folder_path, 'test_batch')
else:
file_path = os.path.join(folder_path, 'data_batch_'+str(batch_id))
#加载数据集文件
with open(file_path, 'rb') as batch_file:
batch = pickle.load(batch_file, encoding = 'latin1')
imgs = batch['data'].reshape((len(batch['data']),3,32,32)) / 255.
labels = batch['labels']
return np.array(imgs, dtype='float32'), np.array(labels)
imgs_batch, labels_batch = load_cifar10_batch(folder_path='datasets/cifar-10-batches-py',
batch_id=1, mode='train')
查看数据的维度:
#打印一下每个batch中X和y的维度
print ("batch of imgs shape: ",imgs_batch.shape, "batch of labels shape: ", labels_batch.shape)batch of imgs shape: (10000, 3, 32, 32) batch of labels shape: (10000,)
可视化观察其中的一张样本图像和对应的标签,代码如下所示:
%matplotlib inline
import matplotlib.pyplot as plt
image, label = imgs_batch[1], labels_batch[1]
print("The label in the picture is {}".format(label))
plt.figure(figsize=(2, 2))
plt.imshow(image.transpose(1,2,0))
plt.savefig('cnn-car.pdf')
构造一个CIFAR10Dataset类,其将继承自paddle.io.DataSet类,可以逐个数据进行处理。代码实现如下:
import paddle
import paddle.io as io
from paddle.vision.transforms import Normalize
class CIFAR10Dataset(io.Dataset):
def __init__(self, folder_path='/home/aistudio/cifar-10-batches-py', mode='train'):
if mode == 'train':
#加载batch1-batch4作为训练集
self.imgs, self.labels = load_cifar10_batch(folder_path=folder_path, batch_id=1, mode='train')
for i in range(2, 5):
imgs_batch, labels_batch = load_cifar10_batch(folder_path=folder_path, batch_id=i, mode='train')
self.imgs, self.labels = np.concatenate([self.imgs, imgs_batch]), np.concatenate([self.labels, labels_batch])
elif mode == 'dev':
#加载batch5作为验证集
self.imgs, self.labels = load_cifar10_batch(folder_path=folder_path, batch_id=5, mode='dev')
elif mode == 'test':
#加载测试集
self.imgs, self.labels = load_cifar10_batch(folder_path=folder_path, mode='test')
self.transform = Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010], data_format='CHW')
def __getitem__(self, idx):
img, label = self.imgs[idx], self.labels[idx]
img = self.transform(img)
return img, label
def __len__(self):
return len(self.imgs)
paddle.seed(100)
train_dataset = CIFAR10Dataset(folder_path='datasets/cifar-10-batches-py', mode='train')
dev_dataset = CIFAR10Dataset(folder_path='datasets/cifar-10-batches-py', mode='dev')
test_dataset = CIFAR10Dataset(folder_path='datasets/cifar-10-batches-py', mode='test')
使用飞桨高层API中的Resnet18进行图像分类实验。
from paddle.vision.models import resnet18
resnet18_model = resnet18()飞桨高层 API是对飞桨API的进一步封装与升级,提供了更加简洁易用的API,进一步提升了飞桨的易学易用性。其中,飞桨高层API封装了以下模块:
复用RunnerV3类,实例化RunnerV3类,并传入训练配置。 使用训练集和验证集进行模型训练,共训练30个epoch。 在实验中,保存准确率最高的模型作为最佳模型。代码实现如下:
import paddle.nn.functional as F
import paddle.optimizer as opt
from nndl import RunnerV3, Accuracy
#指定运行设备
use_gpu = True if paddle.get_device().startswith("gpu") else False
if use_gpu:
paddle.set_device('gpu:0')
#学习率大小
lr = 0.001
#批次大小
batch_size = 64
#加载数据
train_loader = io.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
dev_loader = io.DataLoader(dev_dataset, batch_size=batch_size)
test_loader = io.DataLoader(test_dataset, batch_size=batch_size)
#定义网络
model = resnet18_model
#定义优化器,这里使用Adam优化器以及l2正则化策略,相关内容在7.3.3.2和7.6.2中会进行详细介绍
optimizer = opt.Adam(learning_rate=lr, parameters=model.parameters(), weight_decay=0.005)
#定义损失函数
loss_fn = F.cross_entropy
#定义评价指标
metric = Accuracy(is_logist=True)
#实例化RunnerV3
runner = RunnerV3(model, optimizer, loss_fn, metric)
#启动训练
log_steps = 3000
eval_steps = 3000
runner.train(train_loader, dev_loader, num_epochs=30, log_steps=log_steps,
eval_steps=eval_steps, save_path="best_model.pdparams")
可视化观察训练集与验证集的准确率及损失变化情况。
from nndl import plot
plot(runner, fig_name='cnn-loss4.pdf')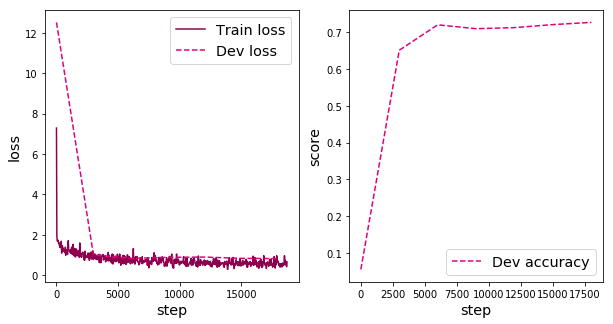
在本实验中,使用了第7章中介绍的Adam优化器进行网络优化,如果使用SGD优化器,会造成过拟合的现象,在验证集上无法得到很好的收敛效果。可以尝试使用第7章中其他优化策略调整训练配置,达到更高的模型精度。
使用测试数据对在训练过程中保存的最佳模型进行评价,观察模型在测试集上的准确率以及损失情况。代码实现如下:
# 加载最优模型
runner.load_model('best_model.pdparams')
# 模型评价
score, loss = runner.evaluate(test_loader)
print("[Test] accuracy/loss: {:.4f}/{:.4f}".format(score, loss))[Test] accuracy/loss: 0.7234/0.8324
同样地,也可以使用保存好的模型,对测试集中的数据进行模型预测,观察模型效果,具体代码实现如下:
#获取测试集中的一个batch的数据
X, label = next(test_loader())
logits = runner.predict(X)
#多分类,使用softmax计算预测概率
pred = F.softmax(logits)
#获取概率最大的类别
pred_class = paddle.argmax(pred[2]).numpy()
label = label[2][0].numpy()
#输出真实类别与预测类别
print("The true category is {} and the predicted category is {}".format(label[0], pred_class[0]))
#可视化图片
plt.figure(figsize=(2, 2))
imgs, labels = load_cifar10_batch(folder_path='/home/aistudio/datasets/cifar-10-batches-py', mode='test')
plt.imshow(imgs[2].transpose(1,2,0))
plt.savefig('cnn-test-vis.pdf')
The true category is 8 and the predicted category is 8
真实是8,预测是8。ship
我正在使用i18n从头开始构建一个多语言网络应用程序,虽然我自己可以处理一大堆yml文件,但我说的语言(非常)有限,最终我想寻求外部帮助帮助。我想知道这里是否有人在使用UI插件/gem(与django上的django-rosetta不同)来处理多个翻译器,其中一些翻译器不愿意或无法处理存储库中的100多个文件,处理语言数据。谢谢&问候,安德拉斯(如果您已经在rubyonrails-talk上遇到了这个问题,我们深表歉意) 最佳答案 有一个rails3branchofthetolkgem在github上。您可以通过在Gemfi
我看到这个错误:translationmissing:da.datetime.distance_in_words.about_x_hours我的语言环境文件:http://pastie.org/2944890我的看法:我已将其添加到我的application.rb中:config.i18n.load_path+=Dir[Rails.root.join('my','locales','*.{rb,yml}').to_s]config.i18n.default_locale=:da如果我删除I18配置,帮助程序会处理英语。更新:我在config/enviorments/devolpment
如果我使用ruby版本2.5.1和Rails版本2.3.18会怎样?我有基于rails2.3.18和ruby1.9.2p320构建的rails应用程序,我只想升级ruby的版本,而不是rails,这可能吗?我必须面对哪些挑战? 最佳答案 GitHub维护apublicfork它有针对旧Rails版本的分支,有各种变化,它们一直在运行。有一段时间,他们在较新的Ruby版本上运行较旧的Rails版本,而不是最初支持的版本,因此您可能会发现一些关于需要向后移植的有用提示。不过,他们现在已经有几年没有使用2.3了,所以充其量只能让更
我有带有Logo图像的公司模型has_attached_file:logo我用他们的Logo创建了许多公司。现在,我需要添加新样式has_attached_file:logo,:styles=>{:small=>"30x15>",:medium=>"155x85>"}我是否应该重新上传所有旧数据以重新生成新样式?我不这么认为……或者有什么rake任务可以重新生成样式吗? 最佳答案 参见Thumbnail-Generation.如果rake任务不适合你,你应该能够在控制台中使用一个片段来调用重新处理!关于相关公司
大家好!我对我的:username字段进行了一个小的验证,它应该是4到30个字符。我写了一个验证::length=>{:within=>4..30,:message=>I18n.t('activerecord.errors.range')-我想显示一个错误各种错误的消息(不像,太长或太短),但这里有一个问题-我可以将最小值和最大值都传递给翻译,以便有类似的东西:用户名应该在4到30个字符之间。目前我有:range:"shouldbebetween%{count}and%{count}characters",这显然不起作用(只是为了检查)。是否可以从范围中获取这些值?谢谢大家的指教!
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal