本题为3月20日23上半学期集训每日一题中B题的题解
给你一个序列 \(A[1],A[2],...,A[n]\) .( \(|A[i]| \leq 15007, 1 \leq N \leq 50,000\) ).
M( \(1 \leq M \leq 500,000\) ) 次询问,每次询问 \(Query(x, y) = Max{A[i] + A[i+1] +...+ A[j]; x \leq i \leq j \leq y}\) .
第一行输入一个数N。
第二行输入N个数 \(A[1],A[2],...,A[n]\) .
第三行输入一个数M
以下M行,每行输入x , y.
M行,每行输出查询的答案。
3
-1 2 3
1
1 2
2
本题需要用到名为线段树的高级数据结构,如果你还不会,可以只阅读基础模型部分,掌握此类题运用分治法的解题思路.等日后你学会了线段树之后,再来研究如何进行本题所需要的区间查询.
此题是分治法中非常经典的区间最大连续子段和问题.想要解决这个问题,首先你需要会解决最基础的模型.这个问题最基础的模型,是对于给出的数组,求其整段上的最大连续子段和.对于这个最基础的模型,其实还有另一种更优的动态规划的做法(一种说法是这种方法其实是贪心),但由于此题只能用分治法,所以这里只介绍分治法的做法.关于这个模型的三种做法(还有一种是暴力),可以在《数据结构与算法分析》一书的第2.4.3章中查阅到详细介绍.
首先我们来考虑一下,对全段如何求它的最大连续子段和.
显然,最大连续子段和只会出现在全段的三个地方,左半段,右半段,或者是横跨中间.这咋一看是一句废话,但这句废话就是确立此题的分治策略的关键.
如果最大连续子段和出现在左半段,那么也就是说左半段的最大连续子段和就是当前的最大连续子段和,我们只需要求左半段的即可.那如何求左半段呢?显然,此时我们需要解决的问题是一个缩小了规模的相同问题,我可以递归地用分治法去解决.出现在右半段同理.
如果出现在中间呢?所谓出现在中间,就是横跨了左右两端,所以此时的答案一定是左半段的最大后缀和加上右半段的最大前缀和.初读这段话,你可能还没法马上理解.这边简单解释一下:

(这里补充一下,如果你做的就是基础模型,那么你还可以采用从中间向两边扩散的方法来求横跨中间情况的和.但是毕竟此处我们最终并不是去做基础模型,这种扩散法是不适合线段树的,所以这里我们不介绍这种做法)
所以我们只需要递归地用分治法求出左半段的最大连续子段和,右半段的最大连续子段和,以及左半段的最大后缀和加上右半段的最大前缀和的和,然后取它们中最大的那个就行了.
但是,如何求左半段的最大前缀和,以及右半段的最大后缀和呢?这里我们一样需要分治地去求.显然,左半段的最大前缀和会有两种情况,一种是其左半段的最大前缀和,另一种是其左半段的和加上其右半段的前缀和(即跨越中间),这里的分析和上面是同理的,可以直接看下面这张图:
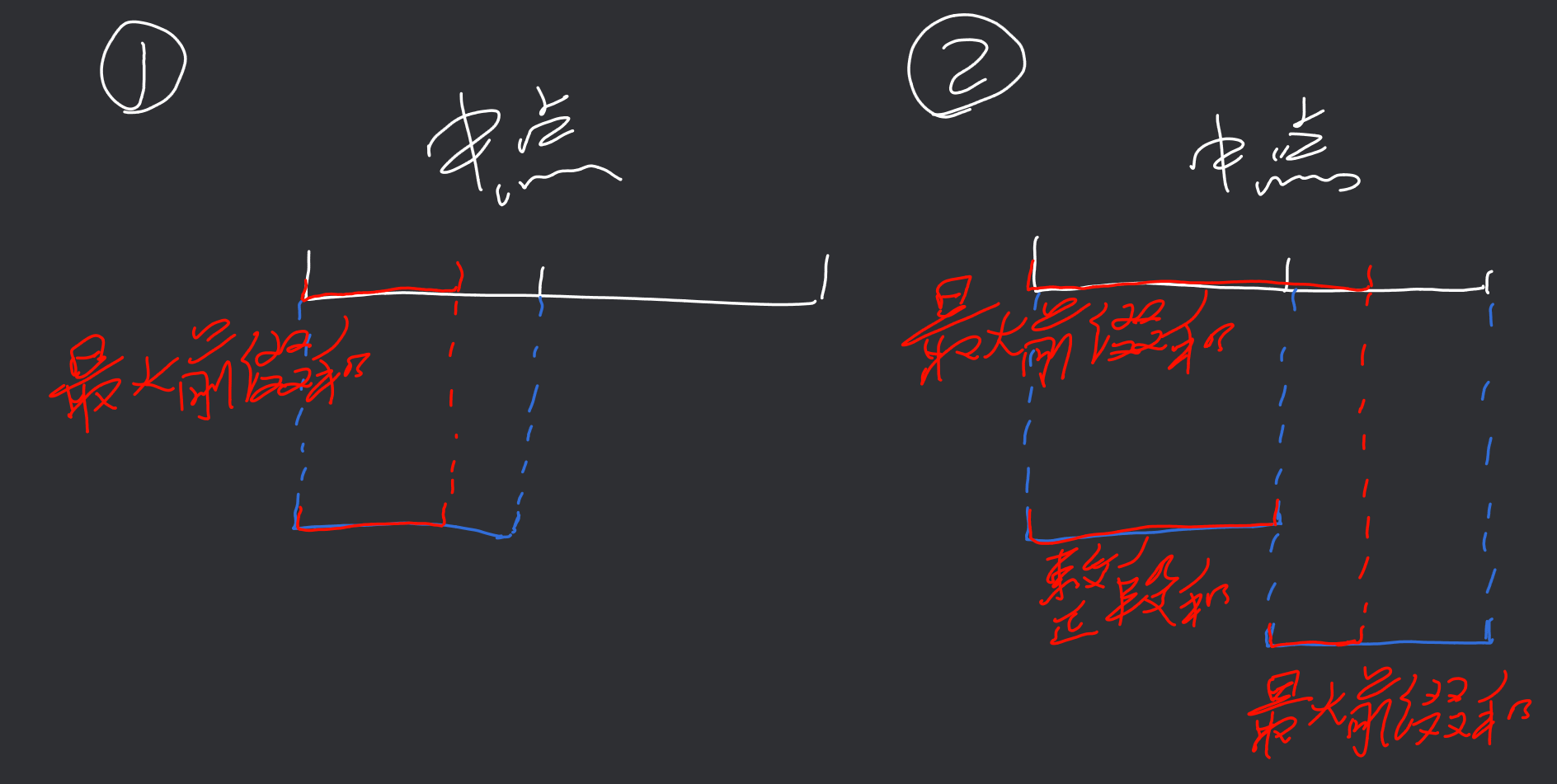
对于右半段是同理的.
所以这个基础模型的解决思路就很清晰了,我们不断地递归当前段的左右半段,分治地去求它们的整段和、最大前缀和、最大后缀和、最大连续子段和,然后按照上面所说的方式,用这些信息去计算当前段的同种信息即可.递归的基线条件就是区间只有一个数,此时上面的这些信息都是这个数本身,直接返回即可.实现起来的代码类似树形dp(实际上树形dp也可以理解成是一种分治法).
可以先尝试在力扣上用上面所说的分治法AC这个基础模型的板子题,然后再继续阅读.注意一下力扣写代码的方式和普通oj不同,它是用类似ACWing上交互题的方式编写代码的,如果你不会在力扣上做题,那还是直接继续读下去吧.
这里给出上面所说的板子题的参考代码:
时间复杂度: \(O(NlogN)\)
空间复杂度: \(O(logN)\) (不计入输入数据所用空间,计入递归栈所使用空间)
class Solution
{
public:
int maxSubArray(vector<int> &nums)
{
this->nums = nums;
return solve(0, nums.size() - 1).maxSum;
}
private:
// 输入的数组
vector<int> nums;
// 每一段上维护的信息
struct Node
{
int sum; // 全段和
int lSum; // 最大前缀和
int rSum; // 最大后缀和
int maxSum; // 最大连续字段和
};
// 分治递归函数
Node solve(int l, int r)
{
// 基线条件,当前区间只有一个点,每一个信息都是数组中的这个数,直接返回
if (l == r)
{
return {nums[l], nums[l], nums[l], nums[l]};
}
int mid = l + r >> 1; // 中点
auto left = solve(l, mid); // 分治递归左半段
auto right = solve(mid + 1, r); // 分治递归右半段
// 计算当前段结果
Node res;
res.sum = left.sum + right.sum; // 总和直接加
res.lSum = max(left.sum + right.lSum, left.lSum); // 最大前缀和是左段的最大前缀和,或左段的总和加上右段的最大前缀和
res.rSum = max(left.rSum + right.sum, right.rSum); // 最大后缀和是右段的最大后缀和,或右段的总和加上左段的最大后缀和
res.maxSum = max({left.maxSum, right.maxSum, left.rSum + right.lSum}); // 最大连续子段和,是左段最大连续子段和、右段最大连续子段和,以及左段最大前缀和与右段最大后缀和的和,这三者中的最大值
return res;
}
};
解决了基础模型,接下来我们来解决这道题目.此题和基础模型唯一的区别在于,基础模型是求整段的最大连续子段和,而此题是求任意一个区间的最大连续子段和,即,需要实现区间查询.提到区间查询,我们一般都会立刻想到线段树,这个可以看作是分治法具象化所形成的高级数据结构,可以很轻松地解决区间查询.而巧的是,我们前面解决基础模型的思路,正好就是完完全全的分治法,而且此题没有修改(如果有,就是按照线段树正常的修改法),所以我们直接把上面的分治法的思路改成线段树即可.
这里唯一要注意的是查询的时候,如果只有一个子区间,缺少另一个区间,那么显然当前段的各个需要维护的数据就是这个唯一的子区间的相应数据,我们直接把它返回即可.
另外,这道题题目存在问题,实际测试出来此题是多组输入(多组n),但是题目完全没有给出相应的信息.如果你不写多组输入,那么只能通过50%的测试点.
时间复杂度: \(O(MlogN)\)
空间复杂度: \(O(N)\)
#pragma GCC optimize(1)
#pragma GCC optimize(2)
#pragma GCC optimize(3, "Ofast", "inline")
#include <bits/stdc++.h>
using namespace std;
using i64 = long long;
//////线段树开始////////
namespace std {
class SegmentTree {
public:
/*
节点信息
*/
struct Node {
int l, r; // 当前结点区间范围
int sum, lSum, rSum, maxSum; // 维护信息,分别为全段和、最大前缀和、最大后缀和、最大连续字段和
};
/*
原始数组
*/
int *a;
/*
数据长度
*/
int n;
/*
线段树
*/
Node *tr;
/*
初始化线段树
*/
SegmentTree(int n, int *&a) {
this->a = a;
tr = new Node[n + 1 << 2];
build(1, 1, n);
}
/*
析构线段树
*/
~SegmentTree() { delete[] tr; }
/*
更新父节点信息
*/
void pushUp(int u) {
tr[u].sum = tr[u << 1].sum + tr[u << 1 | 1].sum;// 总和直接加
tr[u].lSum = max(tr[u << 1].lSum, tr[u << 1].sum + tr[u << 1 | 1].lSum);// 最大前缀和是左段的最大前缀和,或左段的总和加上右段的最大前缀和
tr[u].rSum = max(tr[u << 1 | 1].rSum, tr[u << 1 | 1].sum + tr[u << 1].rSum);// 最大后缀和是右段的最大后缀和,或右段的总和加上左段的最大后缀和
tr[u].maxSum = max({tr[u << 1].maxSum, tr[u << 1 | 1].maxSum, tr[u << 1].rSum + tr[u << 1 | 1].lSum});// 最大连续子段和,是左段最大连续子段和、右段最大连续子段和,以及左段最大前缀和与右段最大后缀和的和,这三者中的最大值
}
/*
建树
*/
void build(int u, int l, int r) {
tr[u] = {l, r};
if (l == r) {
tr[u].sum = a[l];
tr[u].lSum = a[l];
tr[u].rSum = a[l];
tr[u].maxSum = a[l];
return;
}
int mid = l + r >> 1;
build(u << 1, l, mid);
build(u << 1 | 1, mid + 1, r);
pushUp(u);
}
/*
查询
*/
Node query(int u, int l, int r) {
// 区间完全包含,直接返回
if (tr[u].l >= l && tr[u].r <= r) {
return tr[u];
}
int mid = tr[u].l + tr[u].r >> 1; // 中点
if (r <= mid) { // 不存在右区间,直接返回左区间
return query(u << 1, l, r);
}
if (l > mid) { // 不存在左区间,直接返回右区间
return query(u << 1 | 1, l, r);
}
Node left = query(u << 1, l, r); // 查询左半段相应信息
Node right = query(u << 1 | 1, l, r); // 查询右半段相应信息
// 计算当前段结果(与pushUp相同,这里不重复注释了,其实也可以改造一下pushUp函数,然后这里也调用它)
Node res;
res.sum = left.sum + right.sum;
res.lSum = max(left.lSum, left.sum + right.lSum);
res.rSum = max(right.rSum, right.sum + left.rSum);
res.maxSum = max({left.maxSum, right.maxSum, left.rSum + right.lSum});
return res;
}
/*
查询调用入口
*/
Node query(int l, int r) { return query(1, l, r); }
};
} // namespace std
//////线段树结束////////
int main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);
cout.tie(nullptr);
int n;
while (cin >> n) { // 注意题目有误,需要多组输入
int *a = new int[n + 1];
for (int i = 1; i <= n; i++) {
cin >> a[i];
}
SegmentTree st(n, a); // 构建线段树
int m;
cin >> m;
while (m--) {
int x, y;
cin >> x >> y;
if (x > y) { // 以防万一
swap(x, y);
}
cout << st.query(x, y).maxSum << "\n";
}
delete[] a;
}
return 0;
}
"正是我们每天反复做的事情,最终造就了我们,优秀不是一种行为,而是一种习惯" ---亚里士多德
有没有办法在这个简单的get方法中添加超时选项?我正在使用法拉第3.3。Faraday.get(url)四处寻找,我只能先发起连接后应用超时选项,然后应用超时选项。或者有什么简单的方法?这就是我现在正在做的:conn=Faraday.newresponse=conn.getdo|req|req.urlurlreq.options.timeout=2#2secondsend 最佳答案 试试这个:conn=Faraday.newdo|conn|conn.options.timeout=20endresponse=conn.get(url
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
我意识到这可能是一个非常基本的问题,但我现在已经花了几天时间回过头来解决这个问题,但出于某种原因,Google就是没有帮助我。(我认为部分问题在于我是一个初学者,我不知道该问什么......)我也看过O'Reilly的RubyCookbook和RailsAPI,但我仍然停留在这个问题上.我找到了一些关于多态关系的信息,但它似乎不是我需要的(尽管如果我错了请告诉我)。我正在尝试调整MichaelHartl'stutorial创建一个包含用户、文章和评论的博客应用程序(不使用脚手架)。我希望评论既属于用户又属于文章。我的主要问题是:我不知道如何将当前文章的ID放入评论Controller。
我的工作要求我为某些测试自动生成电子邮件。我一直在四处寻找,但未能找到可以快速实现的合理解决方案。它需要在outlook而不是其他邮件服务器中,因为我们有一些奇怪的身份验证规则,我们需要保存草稿而不是仅仅发送邮件的选项。显然win32ole可以做到这一点,但我找不到任何相当简单的例子。 最佳答案 假设存储了Outlook凭据并且您设置为自动登录到Outlook,WIN32OLE可以很好地完成此操作:require'win32ole'outlook=WIN32OLE.new('Outlook.Application')message=
//1.验证返回状态码是否是200pm.test("Statuscodeis200",function(){pm.response.to.have.status(200);});//2.验证返回body内是否含有某个值pm.test("Bodymatchesstring",function(){pm.expect(pm.response.text()).to.include("string_you_want_to_search");});//3.验证某个返回值是否是100pm.test("Yourtestname",function(){varjsonData=pm.response.json
在前面两节的例子中,主界面窗口的尺寸和标签控件显示的矩形区域等,都是用C++代码编写的。窗口和控件的尺寸都是预估的,控件如果多起来,那就不好估计每个控件合适的位置和大小了。用C++代码编写图形界面的问题就是不直观,因此Qt项目开发了专门的可视化图形界面编辑器——QtDesigner(Qt设计师)。通过QtDesigner就可以很方便地创建图形界面文件*.ui,然后将ui文件应用到源代码里面,做到“所见即所得”,大大方便了图形界面的设计。本节就演示一下QtDesigner的简单使用,学习拖拽控件和设置控件属性,并将ui文件应用到Qt程序代码里。使用QtDesigner设计界面在开始菜单中找到「Q
给定一个nxmbool数组:[[true,true,false],[false,true,true],[false,true,true]]有什么简单的方法可以返回“该列中有多少个true?”结果应该是[1,3,2] 最佳答案 使用转置得到一个数组,其中每个子数组代表一列,然后将每一列映射到其中的true数:arr.transpose.map{|subarr|subarr.count(true)}这是一个带有inject的版本,应该在1.8.6上运行,没有任何依赖:arr.transpose.map{|subarr|subarr.in
我正在编写一个简单的日志嗅探器,它将在日志中搜索表明我支持的软件存在问题的特定错误。它允许用户指定日志路径并指定他们想要搜索多少天前。如果用户关闭日志滚动,日志文件有时会变得非常大。目前我正在做以下事情(虽然还没有完成):File.open(@log_file,"r")do|file_handle|file_handle.eachdo|line|ifline.match(/\d+++-\d+-\d+/)etc...line.match显然会查找我们在日志中使用的日期格式,其余逻辑将在下面。但是,有没有更好的方法来搜索没有.each_line的文件?如果没有,我完全同意。我只是想确保我使
我有一个这样的哈希{55=>{:value=>61,:rating=>-147},89=>{:value=>72,:rating=>-175},78=>{:value=>64,:rating=>-155},84=>{:value=>90,:rating=>-220},95=>{:value=>39,:rating=>-92},46=>{:value=>97,:rating=>-237},52=>{:value=>73,:rating=>-177},64=>{:value=>69,:rating=>-167},86=>{:value=>68,:rating=>-165},53=>{:va
我需要做的就是从CSV文件中获取header。file.csv是:"A","B","C""1","2","3"我的代码是:table=CSV.open("file.csv",:headers=>true)putstable.headerstable.eachdo|row|putsrowend这给了我:true"1","2","3"我已经查看RubyCSV文档几个小时了,这让我发疯。我确信必须有一个简单的单行代码可以将header返回给我。有什么想法吗? 最佳答案 看起来CSV.read会让您访问headers方法:headers=C