LDA模型主要用来生成TOPIC
目录
LDA模型需要一定的数学基础去理解,但是理解成黑盒也能一样用。
可以通过以下资料详细了解原理。
【python-sklearn】中文文本 | 主题模型分析-LDA(Latent Dirichlet Allocation)_哔哩哔哩_bilibili
https://www.jianshu.com/p/5c510694c07e
主题模型:LDA原理详解与应用_爱吃腰果的李小明的博客-CSDN博客_lda模型
主题模型-潜在狄利克雷分配-Latent Dirichlet Allocation(LDA)_哔哩哔哩_bilibili
隐含狄利克雷分布(Latent Dirichlet Allocation,LDA),是一种主题模型(topic model),典型的词袋模型,即它认为一篇文档是由一组词构成的一个集合,词与词之间没有顺序以及先后的关系。一篇文档可以包含多个主题,文档中每一个词都由其中的一个主题生成。它可以将文档集中每篇文档的主题按照概率分布的形式给出,对文章进行主题归纳,属于无监督学习。
需要区分的是,另外一种经典的降维方法线性判别分析(Linear Discriminant Analysis, 简称也为LDA)。此LDA在模式识别领域(比如人脸识别,舰艇识别等图形图像识别领域)中有非常广泛的应用
LDA在训练时不需要手工标注的训练集,需要的仅仅是文档集以及指定主题的数量k即可。此外LDA的另一个优点则是,对于每一个主题均可找出一些词语来描述它。选择模型中topic的数量——人为设置参数,之后输入的每篇文章都给一个topic的概率 每个topic再给其下单词概率,topic的具体实现由自己来定

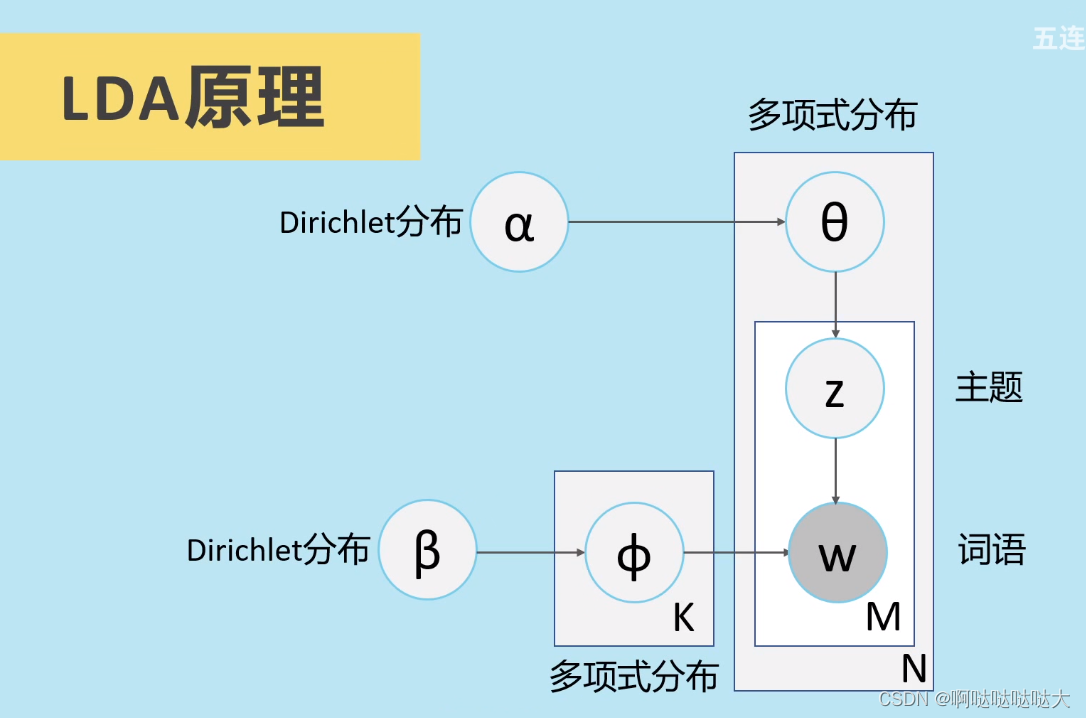
具体的生成模型类比如下图所示:
import os
import pandas as pd
import re
import jieba
import jieba.posseg as psgoutput_path = '../result'
file_path = '../data'
os.chdir(file_path)
data=pd.read_excel("data.xlsx")#content type
os.chdir(output_path)
dic_file = "../stop_dic/dict.txt"
stop_file = "../stop_dic/stopwords.txt"和相同目录下创建三个文件夹:result、data、stop_dic
def chinese_word_cut(mytext):
jieba.load_userdict(dic_file)
jieba.initialize()
try:
stopword_list = open(stop_file,encoding ='utf-8')
except:
stopword_list = []
print("error in stop_file")
stop_list = []
flag_list = ['n','nz','vn']
for line in stopword_list:
line = re.sub(u'\n|\\r', '', line)
stop_list.append(line)
word_list = []
#jieba分词
seg_list = psg.cut(mytext)
for seg_word in seg_list:
word = re.sub(u'[^\u4e00-\u9fa5]','',seg_word.word)
find = 0
for stop_word in stop_list:
if stop_word == word or len(word)<2: #this word is stopword
find = 1
break
if find == 0 and seg_word.flag in flag_list:
word_list.append(word)
return (" ").join(word_list)data["content_cutted"] = data.content.apply(chinese_word_cut)这一步稍微需要一点时间,分词处理
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
from sklearn.decomposition import LatentDirichletAllocation需要sklearn库
def print_top_words(model, feature_names, n_top_words):
tword = []
for topic_idx, topic in enumerate(model.components_):
print("Topic #%d:" % topic_idx)
topic_w = " ".join([feature_names[i] for i in topic.argsort()[:-n_top_words - 1:-1]])
tword.append(topic_w)
print(topic_w)
return tword
n_features = 1000 #提取1000个特征词语
tf_vectorizer = CountVectorizer(strip_accents = 'unicode',
max_features=n_features,
stop_words='english',
max_df = 0.5,
min_df = 10)
tf = tf_vectorizer.fit_transform(data.content_cutted)
n_topics = 8
lda = LatentDirichletAllocation(n_components=n_topics, max_iter=50,
learning_method='batch',
learning_offset=50,
# doc_topic_prior=0.1,
# topic_word_prior=0.01,
random_state=0)
lda.fit(tf)n_top_words = 25
tf_feature_names = tf_vectorizer.get_feature_names()
topic_word = print_top_words(lda, tf_feature_names, n_top_words)import numpy as np
topics=lda.transform(tf)
topic = []
for t in topics:
topic.append(list(t).index(np.max(t)))
data['topic']=topic
data.to_excel("data_topic.xlsx",index=False)
topics[0]#0 1 2 import pyLDAvis
import pyLDAvis.sklearn
pyLDAvis.enable_notebook()
pic = pyLDAvis.sklearn.prepare(lda, tf, tf_vectorizer)
pyLDAvis.save_html(pic, 'lda_pass'+str(n_topics)+'.html')
pyLDAvis.show(pic)import matplotlib.pyplot as plt
plexs = []
scores = []
n_max_topics = 16
for i in range(1,n_max_topics):
print(i)
lda = LatentDirichletAllocation(n_components=i, max_iter=50,
learning_method='batch',
learning_offset=50,random_state=0)
lda.fit(tf)
plexs.append(lda.perplexity(tf))
scores.append(lda.score(tf))
n_t=15#区间最右侧的值。注意:不能大于n_max_topics
x=list(range(1,n_t))
plt.plot(x,plexs[1:n_t])
plt.xlabel("number of topics")
plt.ylabel("perplexity")
plt.show()n_t=15#区间最右侧的值。注意:不能大于n_max_topics
x=list(range(1,n_t))
plt.plot(x,scores[1:n_t])
plt.xlabel("number of topics")
plt.ylabel("score")
plt.show()
运行起来遇到了一些问题,经过查阅搜索都是环境和版本的问题,通过调整版本解决了;建议大家在conda=4.12.0,pandas=1.3.0,pyLDAvis=2.1.2的版本下进行运行,基本不会出现什么问题。
最后的结果如下: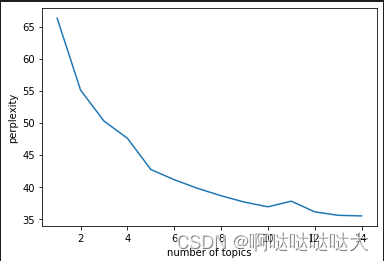
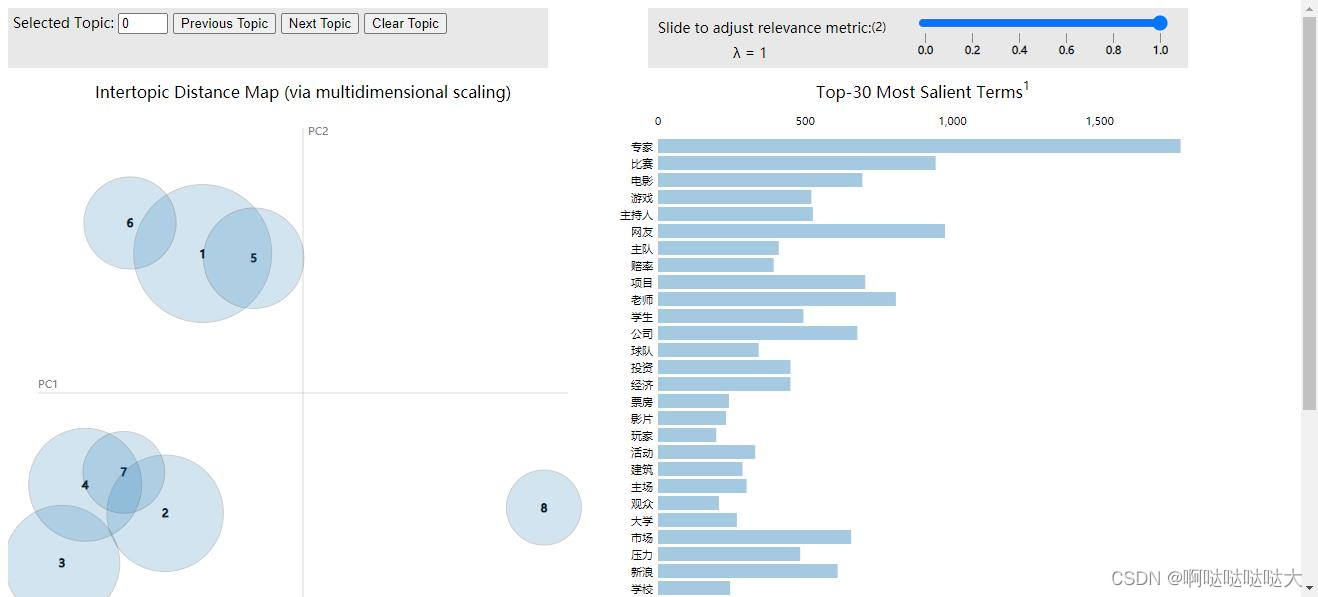
关于LDA模型理解的还不是很透彻,代码的运行中目前用csv文件的话只要改read_csv()就可以,还出了一些编码解码的问题,大家可以尝试换gbk什么的,菜鸡一枚,希望有大佬可以指教。
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我有一个包含模块的模型。我想在模块中覆盖模型的访问器方法。例如:classBlah这显然行不通。有什么想法可以实现吗? 最佳答案 您的代码看起来是正确的。我们正在毫无困难地使用这个确切的模式。如果我没记错的话,Rails使用#method_missing作为属性setter,因此您的模块将优先,阻止ActiveRecord的setter。如果您正在使用ActiveSupport::Concern(参见thisblogpost),那么您的实例方法需要进入一个特殊的模块:classBlah
我有一个表单,其中有很多字段取自数组(而不是模型或对象)。我如何验证这些字段的存在?solve_problem_pathdo|f|%>... 最佳答案 创建一个简单的类来包装请求参数并使用ActiveModel::Validations。#definedsomewhere,atthesimplest:require'ostruct'classSolvetrue#youcouldevencheckthesolutionwithavalidatorvalidatedoerrors.add(:base,"WRONG!!!")unlesss
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
我有一些非常大的模型,我必须将它们迁移到最新版本的Rails。这些模型有相当多的验证(User有大约50个验证)。是否可以将所有这些验证移动到另一个文件中?说app/models/validations/user_validations.rb。如果可以,有人可以提供示例吗? 最佳答案 您可以为此使用关注点:#app/models/validations/user_validations.rbrequire'active_support/concern'moduleUserValidationsextendActiveSupport:
对于Rails模型,是否可以/建议让一个类的成员不持久保存到数据库中?我想将用户最后选择的类型存储在session变量中。由于我无法从我的模型中设置session变量,我想将值存储在一个“虚拟”类成员中,该成员只是将值传递回Controller。你能有这样的类(class)成员吗? 最佳答案 将非持久属性添加到Rails模型就像任何其他Ruby类一样:classUser扩展解释:在Ruby中,所有实例变量都是私有(private)的,不需要在赋值前定义。attr_accessor创建一个setter和getter方法:classUs
我有一个正在构建的应用程序,我需要一个模型来创建另一个模型的实例。我希望每辆车都有4个轮胎。汽车模型classCar轮胎模型classTire但是,在make_tires内部有一个错误,如果我为Tire尝试它,则没有用于创建或新建的activerecord方法。当我检查轮胎时,它没有这些方法。我该如何补救?错误是这样的:未定义的方法'create'forActiveRecord::AttributeMethods::Serialization::Tire::Module我测试了两个环境:测试和开发,它们都因相同的错误而失败。 最佳答案