因为手闲误删了windowsC盘的系统文件导致重装系统,又重装了四五遍Ubuntu和安装hadoop,每次都要查大量资料。这次干脆整合资源至此!(愿天下没有C盘误删)
踩坑用红色
0.终端直接启用root,避免后续权限问题(若root初始化需要添加密码:sudo passwd root)
su root
1.下载JDK1.8安装包(这是最高效的安装方式)
wget https://download.java.net/openjdk/jdk8u41/ri/openjdk-8u41-b04-linux-x64-14_jan_2020.tar.gz
2.解压下载的JDK1.8安装包
tar -zxvf openjdk-8u41-b04-linux-x64-14_jan_2020.tar.gz
3.执行以下命令,移动并重命名JDK包(/usr/java8是可配置路径,可以自行选择路径,自行选择的路径在之后的配置文件时都要跟着走)
mv java-se-8u41-ri/ /usr/java8
4.执行以下命令,配置Java环境变量。
echo 'export JAVA_HOME=/usr/java8' >> /etc/profile
echo 'export PATH=$PATH:$JAVA_HOME/bin' >> /etc/profile
source /etc/profile
5.执行以下命令,查看Java是否成功安装。
java -version
如果返回以下信息,则表示安装成功。
root@tmnk-linux:~$ java -version
openjdk version "1.8.0_41"
OpenJDK Runtime Environment (build 1.8.0_41-b04)
OpenJDK 64-Bit Server VM (build 25.40-b25, mixed mode)
1.下载Hadoop安装包
wget --no-check-certificate https://mirrors.bfsu.edu.cn/apache/hadoop/common/hadoop-2.10.1/hadoop-2.10.1.tar.gz
2.解压Hadoop安装包至/opt/hadoop(同上,/opt/hadoop路径可自由配置,但后续配置也都要跟着走)
tar -zxvf hadoop-2.10.1.tar.gz -C /opt/
mv /opt/hadoop-2.10.1 /opt/hadoop
3.配置Hadoop环境变量
echo 'export HADOOP_HOME=/opt/hadoop/' >> /etc/profile
echo 'export PATH=$PATH:$HADOOP_HOME/bin' >> /etc/profile
echo 'export PATH=$PATH:$HADOOP_HOME/sbin' >> /etc/profile
source /etc/profile
4.修改配置文件yarn-env.sh和hadoop-env.sh
echo "export JAVA_HOME=/usr/java8" >> /opt/hadoop/etc/hadoop/yarn-env.sh
echo "export JAVA_HOME=/usr/java8" >> /opt/hadoop/etc/hadoop/hadoop-env.sh
5.测试Hadoop是否安装成功
hadoop version
如果返回以下信息,则表示安装成功
root@tmnk-linux:~$ hadoop version
Hadoop 2.10.1
Subversion https://github.com/apache/hadoop -r 1827467c9a56f133025f28557bfc2c562d78e816
Compiled by centos on 2020-09-14T13:17Z
Compiled with protoc 2.5.0
From source with checksum 3114edef868f1f3824e7d0f68be03650
This command was run using /opt/hadoop/share/hadoop/common/hadoop-common-2.10.1.jar
此处有天坑:如果关闭终端或重启后发现已经配置好的环境失效了,那么用vim ~/.bashrc 打开.bashrc文件,复制/etc/profile文件里配置好的那堆PATH,粘贴至.bashrc中保存退出,最后命令source /etc/profile生效即可
1.修改Hadoop配置文件 core-site.xml
a. 执行以下命令开始进入编辑页面
vim /opt/hadoop/etc/hadoop/core-site.xml
b. 输入i进入编辑模式
c. 在《configuration》 《/configuration》节点内插入如下内容(注意:tmnk-linux是自个儿的主机名!)
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/hadoop/tmp</value>
<description>location to store temporary files</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://tmnk-linux:9000 </value>
</property>
d. 按Esc键退出编辑模式,输入:wq保存退出
2.修改Hadoop配置文件 hdfs-site.xml
a. 执行以下命令开始进入编辑页面
vim /opt/hadoop/etc/hadoop/hdfs-site.xml
b. 输入i进入编辑模式
c. 在《configuration》《/configuration》节点内插入如下内容(注意:tmnk-linux是自个儿的主机名,0.0.0.0:50070不要动,如果之前更改过hadoop路径这里就要跟着走了)
<property>
<name>dfs.namenode.http.address</name>
<value>tmnk-linux:50070</value>
</property>
<property>
<name>dfs.http.address</name>
<value>0.0.0.0:50070</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop/tmp/dfs/data</value>
</property>
d. 按Esc键退出编辑模式,输入:wq保存退出(修改文件最好用vim,因为遇到读写权限问题时可以直接:wp!强制保存退出)
ssh-keygen -t rsa
演示:
root@tmnk-linux:~$ ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/tmnk/.ssh/id_rsa):
/home/tmnk/.ssh/id_rsa already exists.
Overwrite (y/n)? y
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/tmnk/.ssh/id_rsa
Your public key has been saved in /home/tmnk/.ssh/id_rsa.pub
The key fingerprint is:
SHA256:UlSg3yCrDJX6+jEFLr9C79+kOXAVt6rmfw8L1I2F3Ko tmnk@tmnk-linux
The key's randomart image is:
+---[RSA 3072]----+
| oo. |
| . o...o |
| + o ooo.o |
| + . =.+.= |
| + . +.S.= . |
| .*.o.o.. |
| . .Bo .E . |
| ...++= ..o |
| .+++=oo.... |
+----[SHA256]-----+
cd #先回到无目录
cd .ssh
cat id_rsa.pub >> authorized_keys
1.执行以下命令,初始化namenode (一个y)注意配置好后每次想启动hadoop不必执行此条,容易造成datanode缺失。解决方案
hadoop namenode -format
2.依次执行以下命令,启动Hadoop(三个yes)(配置好hadoop后,每次启动hadoop-hdfs的第一步)
start-dfs.sh
start-yarn.sh
3.启动成功后,执行以下命令,查看已成功启动的进程
jps
如此有了NameNode和DataNode则正常(如果没有也不用紧张,后文还有操作):
root@tmnk-linux:/home/tmnk/.ssh# jps
12547 Jps
11348 SecondaryNameNode
10982 NameNode
11511 ResourceManager
9768 -- process information unavailable
11147 DataNode
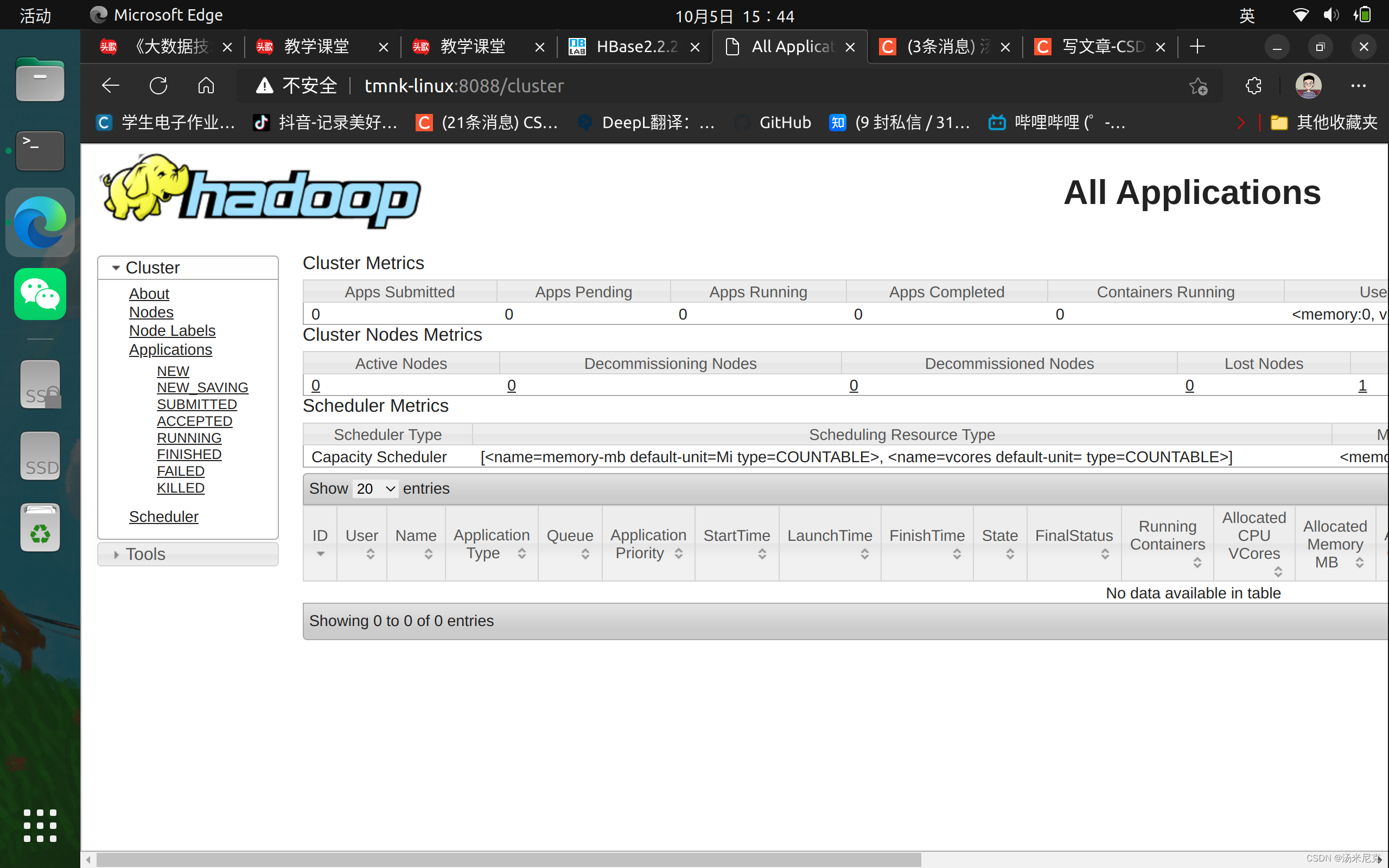
4.打开浏览器访问,显示如下界面则表示Hadoop伪分布式环境搭建完成
主机名:8088
#如我的 tmnk-linux:8088
主机名:50070
#如我的 tmnk-linux:50070
如果8088和50070都成功了,那么恭喜hadoop就安装配置成功了!
但此处有天坑:50070大概率会找不到网页(我们在hdfs-site.xml里添加的节点就是为此),如果确实找不到,那么还有以下操作
首先确保Ubuntu的镜像源的sudo apt-get update可用,然后再用apt-get install ssh openssh-server安装ssh服务,具体操作看我另一篇【Ubuntu22.04 经典问题解决笔记】
以上两步通关后,重启hadoop:
#关闭命令
stop-all.sh
#启动命令
start-all.sh
再重启hadoop集群
hadoop namenode -format
hadoop datanode -format
再开启Hadoop hdfs服务
./start-dfs.sh #若这个显示没有文件则用下面这个
start-dfs.sh
此时再查看已成功的进程:
jps
肯定就有NameNode和DataNode进程了
root@tmnk-linux:/home/tmnk/.ssh# jps
12547 Jps
11348 SecondaryNameNode
10982 NameNode
11511 ResourceManager
9768 -- process information unavailable
11147 DataNode
以上都通关以后刷新一下50070的网页,就没问题了!
番外,安装Hbase以后:
启动HBase:
start-hbase.sh
jps包含:
root@tmnk-linux:/usr/local/hbase# jps
7138 -- process information unavailable
12757 SecondaryNameNode
13333 HQuorumPeer
8870 ResourceManager
12150 NameNode
13991 Jps
13464 HMaster
12556 DataNode
13663 HRegionServer
访问Web页面:
主机名:16010
我的: tmnk-linux:16010

操作HBase:Linux客户端输入
hbase shell
exit退出
停止HBase
stop-hbase.sh
我试过重新启动apache,缓存的页面仍然出现,所以一定有一个文件夹在某个地方。我没有“公共(public)/缓存”,那么我还应该查看哪些其他地方?是否有一个URL标志也可以触发此效果? 最佳答案 您需要触摸一个文件才能清除phusion,例如:touch/webapps/mycook/tmp/restart.txt参见docs 关于ruby-如何在Ubuntu中清除RubyPhusionPassenger的缓存?,我们在StackOverflow上找到一个类似的问题:
之前在培训新生的时候,windows环境下配置opencv环境一直教的都是网上主流的vsstudio配置属性表,但是这个似乎对新生来说难度略高(虽然个人觉得完全是他们自己的问题),加之暑假之后对cmake实在是爱不释手,且这样配置确实十分简单(其实都不需要配置),故斗胆妄言vscode下配置CV之法。其实极为简单,图比较多所以很长。如果你看此文还配不好,你应该思考一下是不是自己的问题。闲话少说,直接开始。0.CMkae简介有的人到大二了都不知道cmake是什么,我不说是谁。CMake是一个开源免费并且跨平台的构建工具,可以用简单的语句来描述所有平台的编译过程。它能够根据当前所在平台输出对应的m
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
我刚刚安装了带有RVM的Ruby2.2.0,并尝试使用它得到了这个:$rvmuse2.2.0--defaultUsing/Users/brandon/.rvm/gems/ruby-2.2.0dyld:Librarynotloaded:/usr/local/lib/libgmp.10.dylibReferencedfrom:/Users/brandon/.rvm/rubies/ruby-2.2.0/bin/rubyReason:Incompatiblelibraryversion:rubyrequiresversion13.0.0orlater,butlibgmp.10.dylibpro
我正在运行Ubuntu11.10并像这样安装Ruby1.9:$sudoapt-getinstallruby1.9rubygems一切都运行良好,但ri似乎有空文档。ri告诉我文档是空的,我必须安装它们。我执行此操作是因为我读到它会有所帮助:$rdoc--all--ri现在,当我尝试打开任何文档时:$riArrayNothingknownaboutArray我搜索的其他所有内容都是一样的。 最佳答案 这个呢?apt-getinstallri1.8编辑或者试试这个:(非rvm)geminstallrdocrdoc-datardoc-da
我已经通过提供MagickWand.h的路径尝试了一切,我安装了命令工具。谁能帮帮我?$geminstallrmagick-v2.13.1Buildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingrmagick:ERROR:Failedtobuildgemnativeextension./Users/ghazanfarali/.rvm/rubies/ruby-1.8.7-p357/bin/rubyextconf.rbcheckingforRubyversion>=1.8.5...yescheckingfor/
我试图在Ubuntu14.04中使用Curl安装RVM。我运行了以下命令:\curl-sSLhttps://get.rvm.io|bash-sstable出现如下错误:curl:(7)Failedtoconnecttoget.rvm.ioport80:Networkisunreachable非常感谢解决此问题的任何帮助。谢谢 最佳答案 在执行curl之前尝试这个:echoipv4>>~/.curlrc 关于ruby-在Ubuntu14.04中使用Curl安装RVM时出错,我们在Stack
我正在使用macos,我想使用ruby驱动程序连接到sqlserver。我想使用tiny_tds,但它给出了缺少free_tds的错误,但它已经安装了。怎么能过这个?~brewinstallfreetdsWarning:freetds-0.91.112alreadyinstalled~sudogeminstalltiny_tdsBuildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingtiny_tds:ERROR:Failedtobuildgemnativeextension.完整日志如下:/System